1 - 클러스터링 개념
클러스터링 (Clustering)
- 비지도 학습 기법 중 하나로 유사한 데이터 포인트를 그룹으로 묶는 방법
- 데이터의 패턴을 분석하고 구조를 발견하는 데 사용됨
- 대표적인 알고리즘으로 K-Means - K-Medoids - GMM 등이 존재함
K-Medoids
- K-Means와 유사하지만 중심을 데이터 포인트 중 하나로 선택하는 방식
- 이상치(outlier)에 강함
- 다양한 거리(metric)를 적용할 수 있음 (유클리드 - 맨해튼 - 코사인 유사도 등)
Gaussian Mixture Model (GMM)
- 데이터가 여러 개의 정규 분포(Gaussian Distribution)로 구성되어 있다고 가정
- 클러스터 간 겹침이 가능함
- 타원형 클러스터에도 적합
K-Means
- 클러스터의 중심을 평균값(mean)으로 설정하여 데이터를 K개의 그룹으로 나누는 알고리즘
- 계산 속도가 빠름
- 원형 클러스터에 적합하지만 이상치에 약함
2 - 거리(metric)의 개념
- 유클리드 거리 (Euclidean Distance) : 두 점 사이의 직선 거리
- 맨해튼 거리 (Manhattan Distance) : 축을 따라 이동한 거리 (택시 거리)
- 코사인 유사도 (Cosine Similarity) : 두 벡터 간의 각도로 유사성을 측정 (문서 군집화 등에 사용됨)
3 - 최적의 클러스터 개수 결정
- Elbow Method : 비용 함수(Within-Cluster Sum of Squares - WCSS) 감소율을 분석하여 최적의 K를 찾음
- Silhouette Score : 클러스터링 품질을 평가하는 방법 중 하나
4 - 코드 예제 및 결과
K-Medoids 클러스터링
import numpy as np
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
from sklearn.datasets import make_blobs
X, _ = make_blobs(n_samples=500, random_state=0, centers=3, n_features=2, cluster_std=0.9)
model = KMedoids(metric="euclidean", n_clusters=3)
model.fit(X)
b_pred = model.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=b_pred, cmap='viridis')
plt.scatter(model.cluster_centers_[:, 0], model.cluster_centers_[:, 1], marker='X', s=125, c='red')
plt.grid()
plt.show()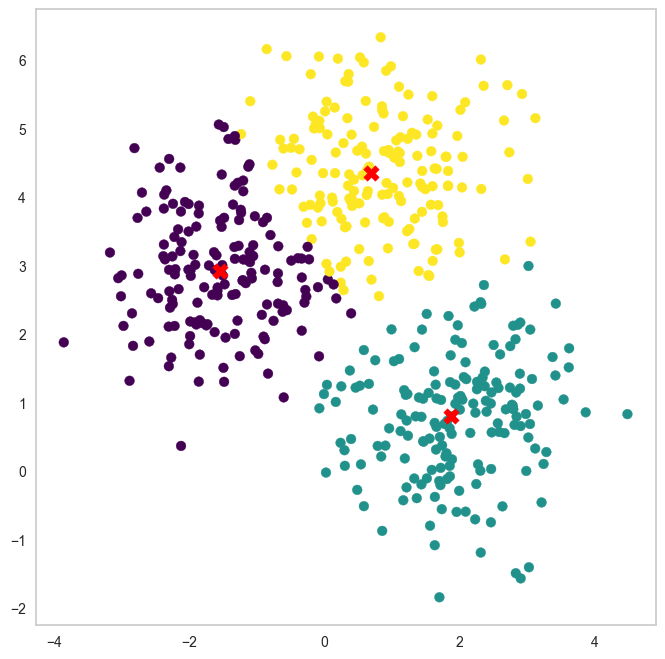
GMM 클러스터링
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=3, random_state=42)
gmm.fit(X)
labels = gmm.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(gmm.means_[:, 0], gmm.means_[:, 1], c='red', marker='X', s=200)
plt.grid()
plt.show()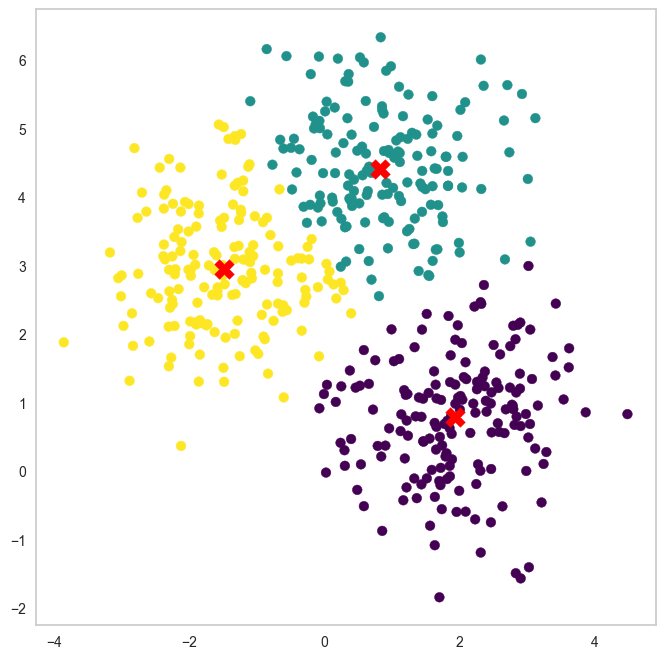
K-Means - GMM - K-Medoids 비교
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
model = KMeans(random_state=42)
visualizer = KElbowVisualizer(model, k=(1,10))
visualizer.fit(X)
visualizer.show()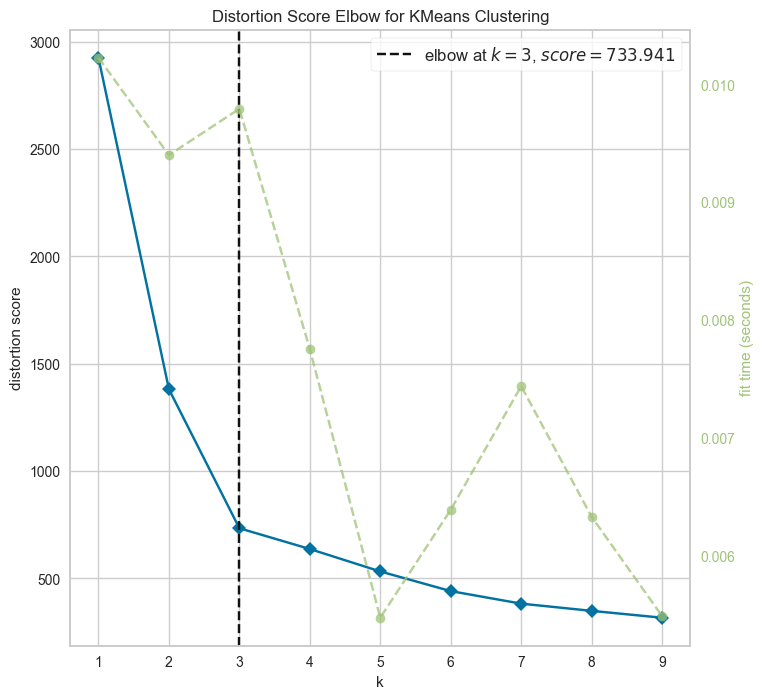
극단적인 형태의 데이터에서 비교
original data
np.random.seed(42)
cov = [[10,8], [8,10]]
ellipse_cluster = np.random.multivariate_normal([0,0], cov,size=200)
circle_cluster = np.random.normal([25,0],0.5,size=(200,2))
outlier_cluster = np.random.normal([10,5],0.5,size=(10,2))
X = np.vstack([ellipse_cluster, circle_cluster, outlier_cluster])
plt.scatter(ellipse_cluster[:,0], ellipse_cluster[:,1], s=20, color='blue', label = 'ellipse_cluster')
plt.scatter(circle_cluster[:,0], circle_cluster[:,1], s=20, color='green', label = 'circle_cluster')
plt.scatter(outlier_cluster[:,0], outlier_cluster[:,1], s=20, color='red',marker='X', label = 'outlier_cluster')
plt.title('Original Data')
plt.legend()
plt.grid(True)
plt.show()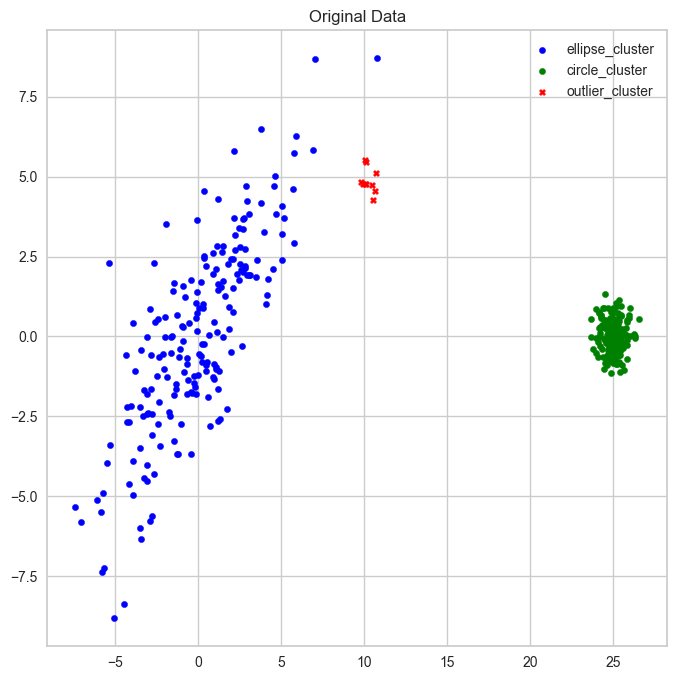
비교
k = 3 #2가 맞는데 3으로 하라심
kmeans = KMeans(n_clusters= k, random_state=42).fit(X)
kmeans_labels = kmeans.labels_
kmedoids = KMedoids(n_clusters= k, random_state=42).fit(X)
kmedoids_labels = kmedoids.labels_
gmm = GaussianMixture(n_components=k, random_state=42)
gmm.fit(X)
gmm_labels = gmm.predict(X)
# 결과 시각화
fig,axes=plt.subplots(1,3,figsize=(18,5))
axes[0].scatter(X[:,0],X[:,1], c=kmeans_labels, cmap='viridis',s=20)
axes[0].scatter(kmeans.cluster_centers_[:,0],kmeans.cluster_centers_[:,1], c='red',marker='X',s=150,label='Centers')
axes[0].legend()
axes[0].set_title('k-means')
axes[0].grid(True)
axes[1].scatter(X[:,0],X[:,1], c=kmedoids_labels, cmap='viridis',s=20)
axes[1].scatter(kmedoids.cluster_centers_[:,0],kmedoids.cluster_centers_[:,1], c='red',marker='X',s=150,label='Centers')
axes[1].set_title('k-medodis')
axes[1].grid(True)
axes[1].legend()
axes[2].scatter(X[:,0],X[:,1], c=gmm_labels, cmap='viridis',s=20)
axes[2].scatter(gmm.means_[:,0],gmm.means_[:,1], c='red',marker='X',s=150,label='Centers')
axes[2].set_title('Guassian Mixture Model(GMM)')
axes[2].grid(True)
axes[2].legend()
plt.suptitle('clustering Algorithm Comparison',fontsize=16)
plt.show()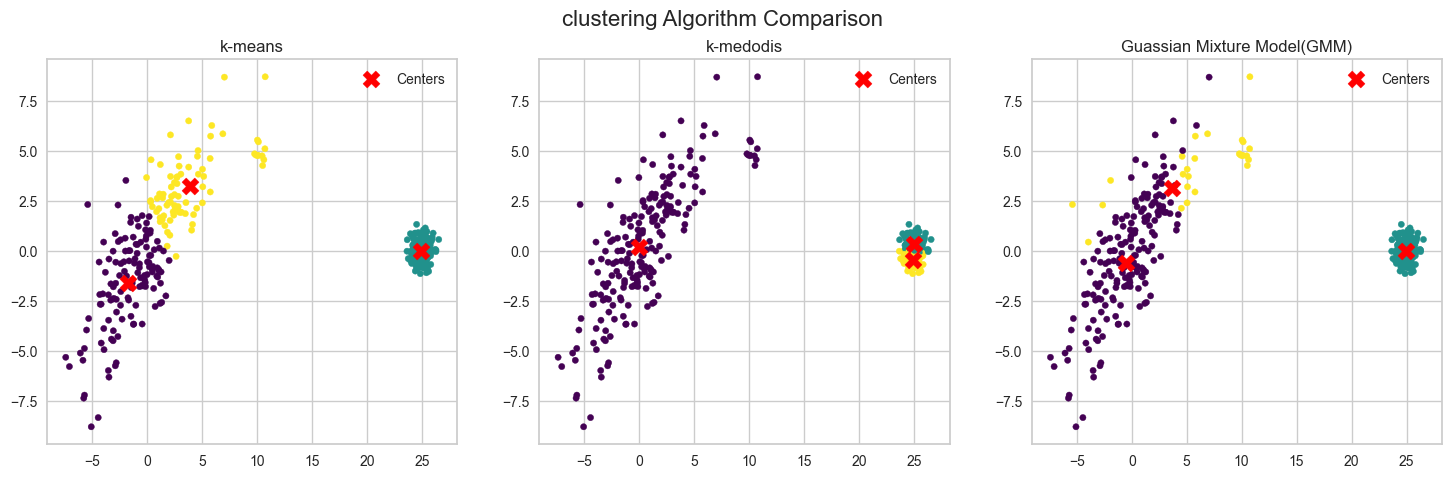
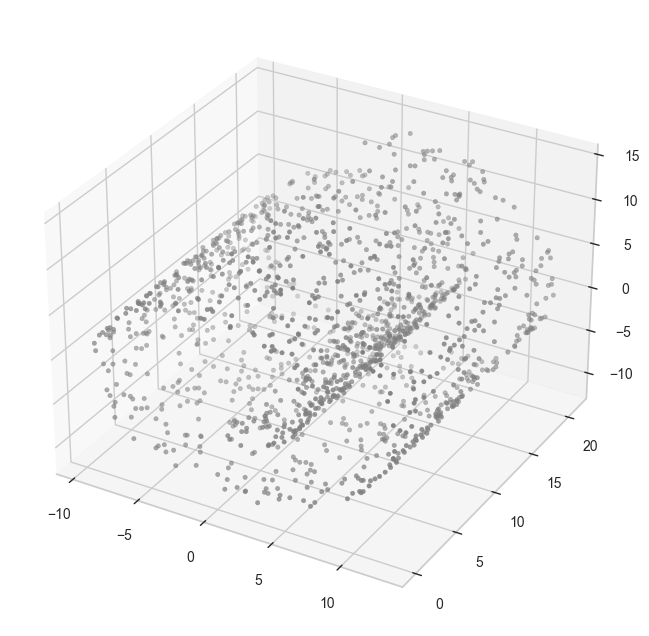
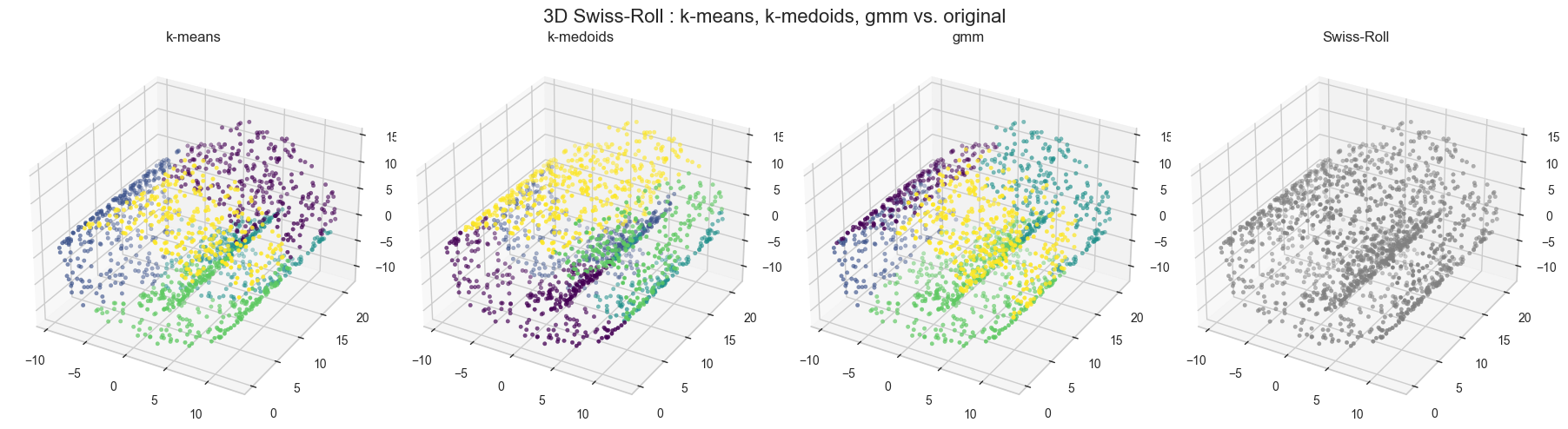
Swiss Roll 데이터에서의 비교
# generate swiss roll data
np.random.seed(42)
X, _ =make_swiss_roll(n_samples=1500, noise=0.1)
# original data - visualization
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], s=10, color='gray')
plt.show()
# initial k setting
k = 5
# kmeans
kmeans = KMeans(n_clusters=k, random_state=42).fit(X)
kmeans_labels = kmeans.labels_
# kmedoids
kmedoids = KMedoids(n_clusters=k, random_state=42).fit(X)
kmedoids_labels = kmedoids.labels_
# gmm
gmm = GaussianMixture(n_components=k, random_state=42)
gmm.fit(X)
gmm_labels = gmm.predict(X)
# visualization
fig = plt.figure(figsize=(18,5))
ax = fig.add_subplot(141,projection='3d')
ax.scatter(X[:,0], X[:,1], X[:,2], c=kmeans_labels, cmap='viridis', s=10)
ax.set_title('k-means')
ax = fig.add_subplot(142,projection='3d')
ax.scatter(X[:,0], X[:,1], X[:,2], c=kmedoids_labels, cmap='viridis', s=10)
ax.set_title('k-medoids')
ax = fig.add_subplot(143,projection='3d')
ax.scatter(X[:,0], X[:,1], X[:,2], c=gmm_labels, cmap='viridis', s=10)
ax.set_title('gmm')
ax = fig.add_subplot(144,projection='3d')
ax.scatter(X[:,0], X[:,1], X[:,2], s=10, color='gray')
ax.set_title('Swiss-Roll')
plt.suptitle('3D Swiss-Roll : k-means, k-medoids, gmm vs. original', fontsize=16)
plt.tight_layout()
plt.show()
5 - 결론
- K-Medoids는 이상치(outlier)에 강하고 다양한 거리(metric)를 적용할 수 있음
- GMM은 타원형 클러스터에도 강하고 클러스터 간 겹침을 잘 표현할 수 있음
- K-Means는 빠르게 동작하지만 원형 클러스터에 적합하고 이상치에 약함
위의 알고리즘들을 비교하여 데이터의 특성에 맞는 클러스터링 기법을 선택하는 것이 중요함

gpt로 다시 배우는 개발