
✔ 디바이스 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')#if gpu 사용 가능{ gpu 사용 }
#else{cpu 사용}
✔ Hyperparameter Settting
머신러닝에서 하이퍼파라미터는 최적의 훈련 모델을 구현하기 위해 "사용자가" 모델에 설정하는 변수
⭐하이퍼파라미터의 예
- 학습률(LEARNING_RATE) # 기계 학습 및 통계학에서 손실 함수의 최소값을 향해 이동하면서 각 반복에서 단계 크기를 결정하는 최적화 알고리즘의 하이퍼 파라미터
- 손실 함수 (Loss Function)
- 일반화 파라미터 (Generalization)
- 미니배치 크기 (BATCH_SIZE) # 전체 데이터 셋을 또다른 소그룹으로 나눈 것.
ex) Datasize: 2000 BATCH_SIZE: 400 - 400 데이터씩 5 Iteration - 에포크 수 (EPOCHS) # 전체 데이터 셋에 대해 N 번 학습
- 가중치 초기화
- 은닉층의 개수
- k-NN의 k값
- 리사이징할 이미지 크기(IMG_SIZE)
- SEED(고정할 SEED값)
✔ Fixed RandomSeed
시드 고정은 랜덤성을 고정한다는 뜻으로, 시드값을 고정하는 이유는 다시 실행해도 같은 결과를 얻기 위함이다. 모델 안정성이나 재현성 그리고 하이퍼 파라미터 튜닝을 위해서는 시드(Seed)를 고정해주어야 한다.
def seed_everything(seed):
random.seed(seed) ##random module의 시드 고정
os.environ['PYTHONHASHSEED'] = str(seed) #해시 함수의 랜덤성 제어, 자료구조 실행할 때 동일한 순서 고정
np.random.seed(seed) #numpy 랜덤 숫자 일정
torch.manual_seed(seed) # torch라이브러리에서 cpu 텐서 생성 랜덤 시드 고정
torch.cuda.manual_seed(seed) # cuda의 gpu텐서에 대한 시드 고정
torch.backends.cudnn.deterministic = True # 백엔드가 결정적 알고리즘만 사용하도록 고정
torch.backends.cudnn.benchmark = True # CuDNN이 여러 내부 휴리스틱을 사용하여 가장 빠른 알고리즘 동적으로 찾도록 설정cudnn random seed를 고정하게 될 경우 학습 속도가 느려진다는 단점이 있다. 나의 경우는 정확한 모델 성능 재현이 필요한 상황이 아니면 cudnn은 제외하는 것이 좋다.
✔ Train & Validation Split
df = pd.read_csv('./train.csv')
train, val, _, _ = train_test_split(df, df['label'], test_size=0.3, stratify=df['label'], random_state=CFG['SEED'])⭐train_test_split
from sklearn.model_selection import train_test_split
train_test_split(arrays, test_size, train_size, random_state, shuffle, stratify)(1) Parameter
- arrays : 분할시킬 데이터를 입력 (Python list, Numpy array, Pandas dataframe 등..)
- test_size : 테스트 데이터셋의 비율(float)이나 갯수(int) (default = 0.25)
- train_size : 학습 데이터셋의 비율(float)이나 갯수(int) (default = test_size의 나머지)
- random_state : 데이터 분할시 셔플이 이루어지는데 이를 위한 시드값 (int나 RandomState로 입력)
- shuffle : 셔플여부설정 (default = True)
- stratify : 지정한 Data의 비율을 유지한다. 예를 들어, Label Set인 Y가 25%의 0과 75%의 1로 이루어진 Binary Set일 때, stratify=Y로 설정하면 나누어진 데이터셋들도 0과 1을 각각 25%, 75%로 유지한 채 분할된다.
(2) Return
- X_train, X_test, Y_train, Y_test : arrays에 데이터와 레이블을 둘 다 넣었을 경우의 반환이며, 데이터와 레이블의 순서쌍은 유지된다.
- X_train, X_test : arrays에 레이블 없이 데이터만 넣었을 경우의 반환
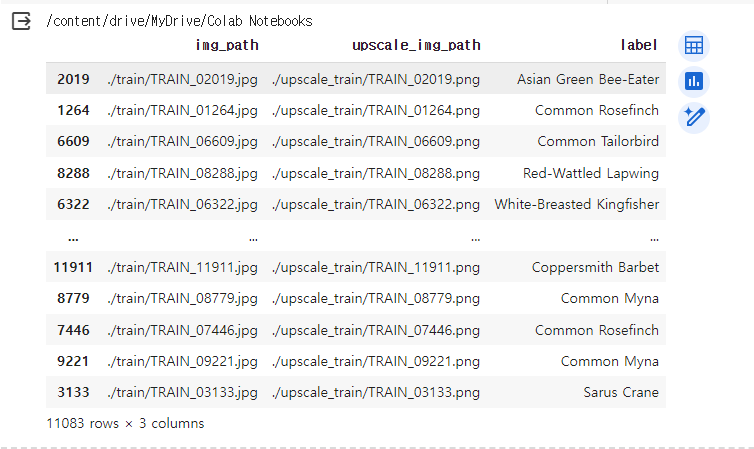
⭐Label-Encoding
n개의 범주형 데이터를 0부터 n-1까지의 연속적 수치 데이터로 표현하는 것이다. 인코딩 결과가 수치적인 차이를 의미하진 않는다.
le = preprocessing.LabelEncoder() # 라벨인코딩 /라벨(목표 변수)를 정수로 인코딩
# train, label의 라벨인코딩 과정 진행
train['label'] = le.fit_transform(train['label'])
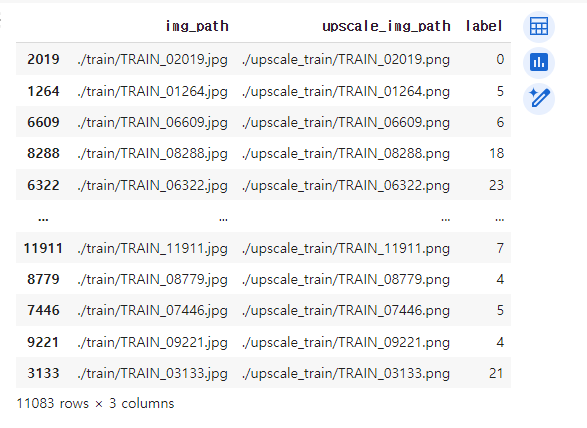
val['label'] = le.transform(val['label'])Label-Encoding 전
Label-Encoding 후
✔ CustomDataset
class CustomDataset(Dataset):
## 파일 경로와 라벨을 받아, 데이터를 로드하고 전처리하는 데이터셋 생성성
def __init__(self, img_path_list, label_list, transforms=None):
self.img_path_list = img_path_list
self.label_list = label_list
self.transforms = transforms
def __getitem__(self, index):
img_path = self.img_path_list[index]
# 이미지 읽어오기
image = cv2.imread(img_path)
if self.transforms is not None:
image = self.transforms(image = image)['image']
# 라벨이 있다면 이미지와 함께 반환
if self.label_list is not None:
label = self.label_list[index]
return image, label
# 라벨이 없다면 이미지만 반환환
else:
return image
def __len__(self):
return len(self.img_path_list)
# Compose는 여러 변환을 연속적으로적용할 수 있게 해주는 함수. (IMG 사이즈 224로 설정되어 있음)
# 이미지 크기조정, 정규화, 텐서로 변환 포함.
'''
Normalize(mean=0.485, 0.456, 0.406값은 각 채널별 평균)
std=(0.229, 0.224, 0.225 값은 각 채널별 표준편차)
max_pixel_value: 이미지의 최대 픽셀 값 (8비트의 경우 255가 최대값)
always_apply= Ture: 변환이 데이터셋의 모든 이미지에 대해 항상 적용.
p: 변환이 적용될 확률: (0~1 사이)
대부분의 경우 always_apply=True로 하고 p를 조절해서 사용
'''
train_transform = A.Compose([
A.Resize(CFG['IMG_SIZE'], CFG['IMG_SIZE']),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, always_apply=False, p=1.0),
ToTensorV2()])
test_transform = A.Compose([
A.Resize(CFG['IMG_SIZE'], CFG['IMG_SIZE']),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, always_apply=False, p=1.0),
ToTensorV2()])
## train데이터셋 설정 및 불러오기
train_dataset = CustomDataset(train['img_path'].values, train['label'].values, train_transform)
train_loader = DataLoader(train_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=False, num_workers=0)
## val 데이터셋 설정 및 불러오기
val_dataset = CustomDataset(val['img_path'].values, val['label'].values, test_transform)
val_loader = DataLoader(val_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=False, num_workers=0)⭐Albmentations.Compose
Albumentations는 이미지를 손쉽게 augmentation 해주는 python 라이브러리이다.
A.Compose() 안에 augmentation하고 싶은 함수가 들어있는 리스트를 입력하면 된다.
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]??
결론적으로 보자면 위의 평균과 표준편차는 ImageNet 데이터셋의 통계치이다. ImageNet과 같은 방식으로 촬영된 사진들(자연물이며, RGB 3원광으로 표현되고 그 밖의 요소로 인해 편향되지 않은 사진)의 경우 위의 수치를 따르는 것이 권고된다.
그러나 위성사진, 방사선(X선, 감마선 등)으로 촬영된 사진, 흑백사진 등은 데이터셋에 맞게 평균과 표준편차 값을 새로 구하는 것이 좋은 판단이라 생각된다.
