목표 | BPE, WordPiece, Unigram 토크나이저를 만들어보고, 세가지가 어떻게 다른지 비교해본다.
즉, 테스트 텍스트를 서브워드 토큰화 후, 각 모델 별 결과를 확인해본다.
이번 페이지에서는 먼저 주요 내용을 학습한다.
서브워드 기반 토크나이저 개발에 활용할 대표 모델
BPE 모델 (Byte Pair Encoding), WordPiece 모델, Unigram 모델
서브워드 토크나이저란 단어보다 더 작은 단위로 텍스트를 쪼개는 방법
서브워드 사용 이유
1)완벽하게 단어를 나누면 OOV(Out-of-Vocabulary,사전에 없는 단어) 이슈 생김.
2)글자 단위로 하면 정보가 너무 작아져 의미가 약해짐
3)서브워드는 그 중간인 희귀한 단어도 다룰 수 있고, 그 의미도 유지가능.
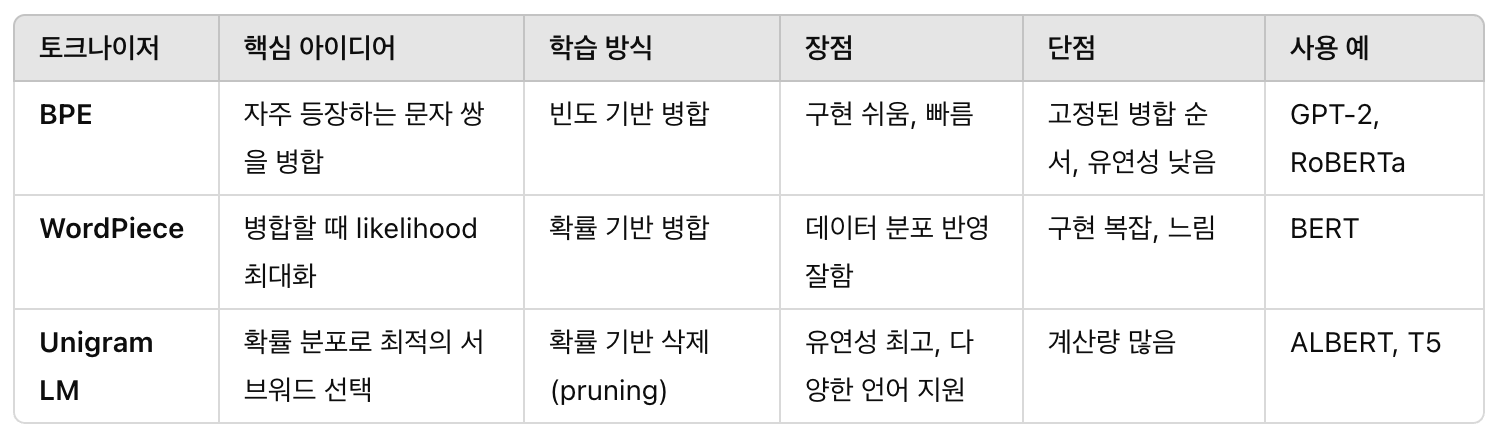
BPE(Byte Pair Encoding)
핵심 아이디어
자주 등장하는 문자 쌍을 합쳐서 단위를 키워나가는 방식
처음에는 글자 단위로 시작해서 많이 나타나는 쌍을 계속 합쳐서 새로운 토큰을 만들어냄.
학습 방식
1.글자 단위로 분할해서 데이터에서 가장 많이 등장하는 pair 찾는다.
2.그 쌍을 새로운 토큰으로 병합함.
3.1~2를 반복함.
4.위 과정을 vocab size 가 될때까지 반복하다가 멈춤.
특징
속도가 빠르고 구현이 쉬움.
희귀 단어도 부분적으로 인코딩 가능.
고정된 병합 순서로, 유연성이 떨어짐.
WordPiece
핵심 아이디어
BPE와 비슷하지만, 병합기준은 확률기반.
단어가 생성될 확률이 높아지게 토큰을 합치는 방식.
구글 BERT에서 사용한 방법.
학습 방식
1.단어를 글자 단위로 쪼갬.
2.합칠 후보 정하고, 해당 후보 추가되었을때 likelihood 계산.
3.확률이 가장 증가하는 토큰 병합을 선택.
4.위 과정을 vocab size 까지 반복하다가 멈춤.
특징
BPE보다 조금 더 정교한 병합 기준
확률 기반이라 좀 더 데이터 분포 잘 반영
희귀 단어에 대해 서브워드 처리가 유연함
구현이 약간 더 까다롭지만 huggingface가 도와줄 수 있음
Unigram Language Model
핵심 아이디어
모든 서브워드 토큰이 독립적(unigram)이라 가정하고 확률분포 이용해 가장 좋은 분할 찾는 방식.
병합 반복이 아닌, 최적의 단더 집합을 선택. = 삭제(감소)기반 pruning 방식.
학습 방식
1.초기에 가능한 모든 서브워드 조합을 만들어 큰 vocabulary를 만듦
2.학습 데이터에 대해 각 서브워드의 출현 확률을 계산함
3.확률이 낮은 토큰은 제거하고, 모델을 다시 최적화홤
4.위 과정을 vocab size 까지 반복하다가 멈춤.
특징
병합 방식(BPE, WordPiece)보다 더 유연하게 단어를 분할할 수 있음
서브워드가 겹치는 경우가 많아져서 다양한 토큰화 결과를 제공함
일본어, 한국어처럼 형태소가 복잡한 언어에 강력함
SentencePiece 라이브러리에서 주로 사용됨(구글의 T5, ALBERT가 사용)
기본 용어
Voacab : 모델이 학습하고 기억하고 있는 모든 토큰의 집합. 서브워드 단위의 사전.
Vocab size : 사전에 들어있는 토큰의 갯수. 사용할 토큰(서브워드)의 갯수
Vocab size 조절하는 이유
L작으면? : 희귀한 단어를 더 잘 쪼개야 해서 긴 토큰 시퀀스가 나옴. 처리속도가 느려지고, 문맥파악 힘들 수 있음.
L크면? : 더 많은 토큰이 한번에 다뤄지니 효율적이나, 모델 크기가 커지고, 메모리/학습 자원 소모가 큼.
Step
각 토크나이저 모델 학습
어떤 단위를 자를지 결정한다.
L Output: 학습 코드, 서브워드 사전 파일
테스트 텍스트 토큰화
예를 들어 "나는 데이터사이언티스트로 일하고 있다." 라는 문장을 BPE, WordPiece, Unigram으로 각각 어떻게 나눠지는지 보여줘야한다.
L Output: 토큰화 코드, 테스트 결과 파일
프로그램 코드
BPE가 제일 쉽고 직관적임.
WordPiece랑 Unigram은 HuggingFace나 SentencePiece 활용 가능.
