서브워드 토크나이저 개발 및 비교 분석
1. 스터디 개요 (Introduction)
본 과제의 목적은 자연어처리(NLP)에서 널리 사용되는 세 가지 서브워드 토크나이저(BPE, WordPiece, Unigram)를 직접 학습하고 비교 분석하는 것이다. 각 모델을 동일한 학습 데이터로 훈련시키고, 토큰화 결과를 비교하여 장단점과 차이점을 도출하였다.
- 스터디 주제: 서브워드 토크나이저 개발 (BPE, WordPiece, Unigram)
- 학습 데이터: 음식 리뷰 데이터(review_clean_text_half.txt, 전체 데이터의 1/2 사용)
- Vocab Size: 1000개로 통일 (3000개 정도는 되어야 하지만, 빠른 결과를 위해 1000으로 제한)
- 프로그래밍 환경: Python + HuggingFace Tokenizers 라이브러리 + 직접 구현(BPE/Unigram)
2. 데이터 전처리 과정 (Preprocessing)
- 데이터 출처: Amazon Fine Food Reviews https://www.kaggle.com/datasets/snap/amazon-fine-food-reviews
- 전처리 방법:
- 특수문자 제거 (정규표현식 사용):
re.sub(r'[^a-zA-Z0-9\s]', '', text) - 모든 문자를 소문자로 변환:
text.lower() - 전체 데이터가 너무 많아 50%만 사용하여
review_clean_text_half.txt파일 생성
- 특수문자 제거 (정규표현식 사용):
데이터는 라인 단위로 학습 및 테스트에 사용하였다. 라인 단위 처리는 리뷰 간 의미 단위 경계를 보존하고, 데이터가 너무 길어지는 것을 방지하여 학습 속도 및 토큰 품질에 긍정적 영향을 주었다.
3. 모델 별 서브워드 토크나이저 개발 및 학습
3-1. BPE (Byte Pair Encoding)
- 알고리즘 개념: 자주 등장하는 문자쌍을 반복적으로 병합하여 서브워드를 구성
- 구현 방식: 직접 구현하여
merges딕셔너리와vocab생성 - 학습 데이터: review_clean_text_half.txt
- Vocab Size: 1000
- 특징:
Ġ기호로 공백을 구분하여 GPT-2 스타일로 구현- 글자 단위 병합이 주로 발생하여 시퀀스가 길어지는 경향
BPE Vocab 일부 예시:
vocab = ['<PAD>', '<UNK>', 'Ġ', 'a', 'b', 'c', 'Ġt', 'th', 'er', ...]3-2. WordPiece
- 알고리즘 개념: 확률 기반 병합 (접두/접미사 개념 활용)
- 구현 방식: HuggingFace Tokenizers + 직접 구현 병행
- 학습 데이터: review_clean_text_half.txt
- Vocab Size: 1000
- 특징:
- 접두사: 토큰 그대로 사용
- 접미사:
##기호를 붙여 중간 이후를 나타냄
WordPiece Vocab 일부 예시:
vocab = ['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[MASK]', 'a', 'b', '##tion', '##ed', ...]3-3. Unigram
- 알고리즘 개념: 확률 기반 서브워드 조합, 비효율적인 토큰을 삭제하여 최적화
3-3-1. HuggingFace Tokenizers 기반 Unigram
- 구현 방식: HuggingFace Tokenizers 라이브러리 사용
- 학습 데이터: review_clean_text_half.txt
- Vocab Size: 1000
- 특징:
- 서브워드 후보 리스트에서 확률이 가장 높은 조합 선택 (Viterbi 알고리즘)
- 접두사/접미사 구분 없이 자유로운 토큰화
3-3-2. 직접 구현한 Unigram
- 구현 방식: Python으로 직접 구현 (삭제 기반 알고리즘)
- 학습 데이터: review_clean_text_half.txt
- Vocab Size: 1000
- 특징:
- 확률 기반으로 비효율적인 토큰을 삭제하며 vocab을 최적화
- Greedy 토큰화 방식으로 서브워드를 선택하여 세분화가 과도하게 일어날 수 있음
Unigram Vocab 일부 예시 (직접 구현):
vocab = ['a', 'b', 't', 'ing', 'tion', 'ed', 'ly', ...]4. 테스트 문장 토큰화 및 결과 비교
- 테스트 데이터: review_clean_text_half.txt의 1/40 사용
테스트 문장 및 결과 예시
예시 문장 1
i have bought several of the vitality canned dog food products and have found them all to be of good quality the product looks more like a stew than a processed meat and it smells better my labrador is finicky and she appreciates this product better than most| 모델 | 토큰화 결과 | 토큰 수 |
|---|---|---|
| BPE | i Ġ h a v e Ġ b o u g h t Ġ s e v e r a l... | 59 |
| WordPiece | i have bought several of the v ##it ##ality can ##ned... | 44 |
| Unigram (HuggingFace) | i have bought several of the vitality canned dog food... | 48 |
| Unigram (직접 구현) | i have bought several of the v it a l it y canned... | 60 |
예시 문장 2
product arrived labeled as jumbo salted peanutsthe peanuts were actually small sized unsalted not sure if this was an error or if the vendor intended to represent the product as jumbo| 모델 | 토큰화 결과 | 토큰 수 |
|---|---|---|
| BPE | p r o d u c t Ġ a r r i v e d Ġ l a b e l e d... | 60 |
| WordPiece | product arr ##ived l ##abel ##ed as ju ##m ##bo... | 41 |
| Unigram (HuggingFace) | product arrived labeled as jumbo salted peanuts the peanuts were... | 50 |
| Unigram (직접 구현) | product arrived label e d as j u m b o salt e d peanut s... | 62 |
5. 모델별 분석 및 비교
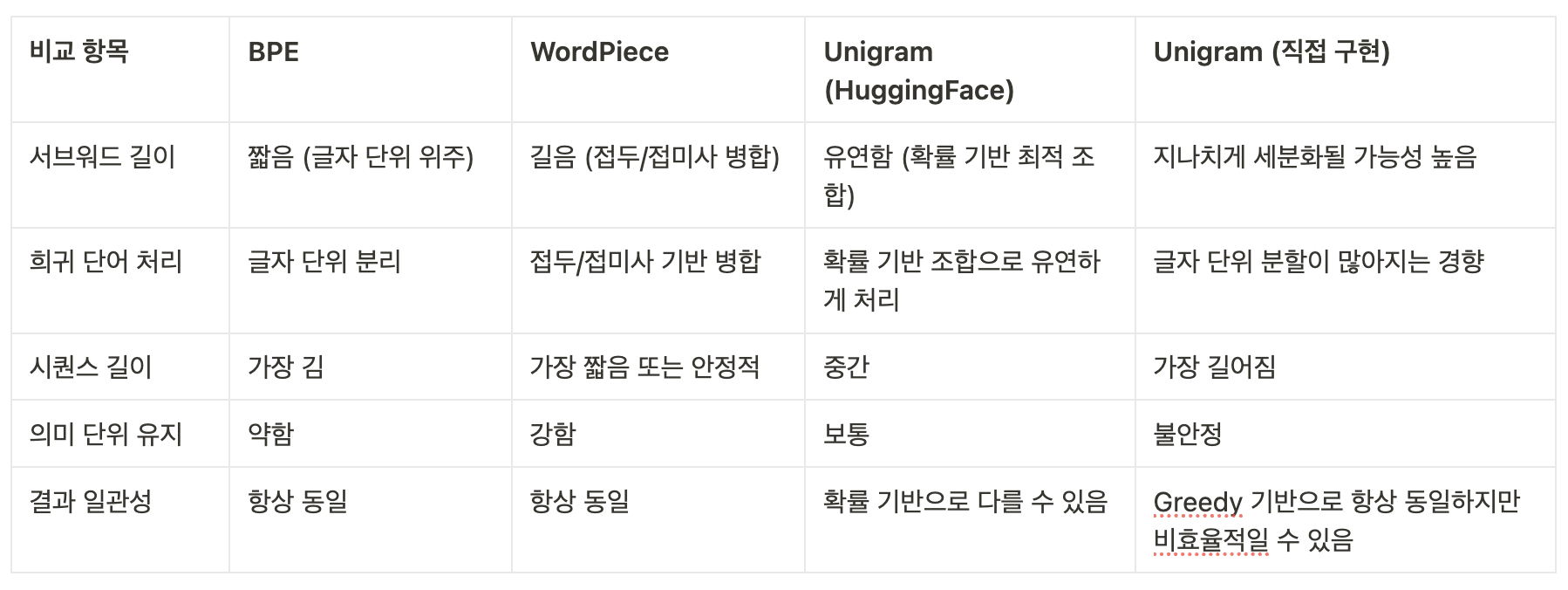
추가 분석 포인트
- Unigram 두 가지 버전의 차이:
- HuggingFace 버전은 Viterbi 알고리즘을 통해 최적의 서브워드 분할을 선택하여 더 긴 서브워드를 유지하고 효율적인 토큰화를 보장함.
- 직접 구현 버전은 Greedy 알고리즘을 사용하여 서브워드가 과도하게 잘게 분할되며, 결과적으로 시퀀스가 길어지고 토큰 수가 증가함.
- 학습 데이터가 같고 vocab size가 동일해도, 최적화 전략의 차이로 인해 실제 토큰화 결과에서 차이를 보임.
6. 결론
본 실습을 통해 BPE, WordPiece, Unigram 토크나이저를 동일한 데이터와 환경에서 학습하고 테스트하였다.
- WordPiece는 서브워드 병합이 안정적이고, 시퀀스 길이도 짧아서 학습 및 추론 효율이 높았다.
- Unigram은 희귀 단어 처리에서 유연성이 뛰어났지만, 직접 구현 방식에서는 지나친 분할로 인한 비효율성을 확인하였다. 반면, HuggingFace 버전은 최적 분할을 통해 효율성과 의미 보존이 우수하였다.
- BPE는 구현이 직관적이지만 시퀀스가 지나치게 길어지며, 희귀 단어 처리에 약점을 보였다.
간단한 스터디 결과, WordPiece 모델을 추천하며, 특히 영어와 같은 언어에서는 효율적인 학습이 가능할 것으로 판단된다. 다만, 한국어와 같은 형태소 중심 언어에서는 Unigram(HuggingFace 버전)의 장점이 부각될 수 있으므로 추가 실험이 필요하다.

Transitioning from UX to data science, I explore the intersection of service & data to unlock hidden value and make meaningful predictions.