
1. 라이브러리 임포트하기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os, shutil
import warnings
warnings.filterwarnings('ignore')
from tensorflow import keras
from keras import layers, optimizers
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from keras.applications import DenseNet121GPU 사용
print(device_lib.list_local_devices())os.environ['CUDA_VISIBLE_DEVICES'] = '0'2. 데이터 읽기 & 전처리하기
- 이미지 데이터 읽어오기
학습과 검증에 사용되는 데이터만 생각해봐도 이걸 다 읽어서 numpy array로 변환시키고 가지고 있는 건 옳지 않은 것 같다. 필요한 만큼만 읽어오는 방법이 필요하다.
- 전처리하기: data augmentation
신경망을 학습시키기에는 데이터의 수가 적다. 따라서 회전, 픽셀 이동, 뒤집기 등의 처리를 통해서 데이터의 수를 늘려줄 필요가 있다.
- 케라스에서 위 두 작업을 동시에 도와주는 클래스가
keras.preprocessing.image.ImageDataGenerator이다.
추가로flow_from_directory()메소드를 이용하면 폴더의 이름을 레이블로 지정해서 레이블링까지 해주는 기능이 있다. - 모델을 학습하는 과정에서도 이 data generator를 이용하게 되며, 학습/검증/테스트 모두 이용하기 때문에 각각 맞는 객체를 만들어주어야 한다.
2.1 데이터 경로(상대 경로) 지정하기 & 검증 데이터(validation data) 분리하기
train_path = '../dataset/training_set'
val_path = '../dataset/validation_set'
test_path = '../dataset/test_set'if not os.path.isdir(val_path):
# make validation data directory
val_dogs_dir= os.path.join(val_path, 'dogs')
val_cats_dir = os.path.join(val_path, 'cats')
os.mkdir(val_path)
os.mkdir(val_dogs_dir)
os.mkdir(val_cats_dir)
# seperate dataset
train_dogs_dir = os.path.join(train_path, 'dogs')
train_cats_dir = os.path.join(train_path, 'cats')
len_train_dogs = len(os.listdir(train_dogs_dir))
len_train_cats = len(os.listdir(train_cats_dir))
for i in range(1, int(len_train_dogs*0.2) + 1):
filename = f'dog.{i}.jpg'
src = os.path.join(train_dogs_dir, filename)
dst = os.path.join(val_dogs_dir, filename)
# dst = val_dog_dir
shutil.move(src=src, dst=dst)
for i in range(1, int(len_train_cats*0.2) + 1):
filename = f'cat.{i}.jpg'
src = os.path.join(train_cats_dir, filename)
dst = os.path.join(val_cats_dir, filename)
# dst = val_cat_dir
shutil.move(src=src, dst=dst)2.2 ImageDataGenerator 객체 만들기
- 객체를 생성하는 과정에서 값의 범위를 재조정(rescale)하는 정도와 augmentation을 하는 방식과 정도를 지정하게 된다.
# flow_from_directory() 함수에서 읽어오는 이미지의 규격(size_images)와 배치의 크기(batch_size)를 정하는 변수
size_images = 200
batch_size = 642.2.1 train_generator 정의하기
# ImageDataGenerator: 이미지 전처리 / data augmentation을 해서 배치로 반환해주는 클래스
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=.2,
height_shift_range=.2,
horizontal_flip=True,
fill_mode='nearest'
)
# flow_from_directory(): 디렉토리에의 경로를 전달받아 증강된 데이터의 배치를 생성합니다.
# 반환하는 결과물은 batch data와 label이 튜플 형태로 들어가 있다. batch data와 labels는 모두 numpy array이다.
# labels는 one hot 형태로 반환되며, 정확한 라벨은 반환된 객체의 class_indices 속성을 통해서 딕셔너리로 확인 가능하다.
train_generator = train_datagen.flow_from_directory(
train_path,
target_size=(size_images, size_images),
batch_size=batch_size,
seed=32,
shuffle=True,
class_mode='categorical'
)# train_generator가 만들어 내는 데이터 수 시각화하기
labels = list(train_generator.class_indices.keys())
counts = {label: 0 for label in labels}
for i in range(len(train_generator)):
batch_data, batch_labels = train_generator[i]
for j in range(len(batch_labels)):
class_idx = int(batch_labels[j].argmax())
class_label = labels[class_idx]
counts[class_label] += 1
plt.figure(figsize=(9, 5))
plt.title('# Images per class')
plt.xlabel('Class')
plt.xticks(rotation=45)
plt.ylabel("Count")
plt.bar(counts.keys(), counts.values(), color=plt.cm.tab20(np.linspace(0, 1, len(labels))))
plt.show()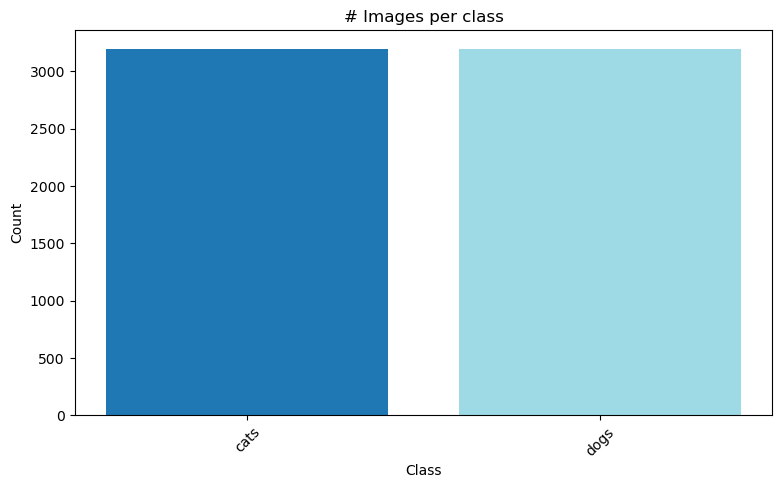
2.2.2 val_generator 정의하기
val_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=.2,
height_shift_range=.2,
horizontal_flip=True,
fill_mode='nearest'
)
val_generator = val_datagen.flow_from_directory(
val_path,
target_size=(size_images, size_images),
batch_size=batch_size,
seed=42,
shuffle=True,
class_mode='categorical'
)Found 1600 images belonging to 2 classes.2.2.3 test_generator 정의하기
- test dataset은 data augmentation을 할 필요가 없기 때문에 ImageDataGenerator객체를 정의할 때 rescale의 값만 정해준다.
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_path,
target_size=(size_images, size_images),
batch_size=batch_size,
class_mode='categorical'
)Found 2000 images belonging to 2 classes.# test dataset의 데이터 비율 시각화하기
labels = list(test_generator.class_indices.keys())
counts = {label: 0 for label in labels}
for i in range(len(test_generator)):
batch_data, batch_labels = test_generator[i]
for j in range(len(batch_labels)):
class_idx = int(batch_labels[j].argmax())
class_label = labels[class_idx]
counts[class_label] += 1
plt.figure(figsize=(9, 5))
plt.title('# Images per class')
plt.xlabel('Class')
plt.xticks(rotation=45)
plt.ylabel("Count")
plt.bar(counts.keys(), counts.values(), color=plt.cm.tab20(np.linspace(0, 1, len(labels))))
plt.show()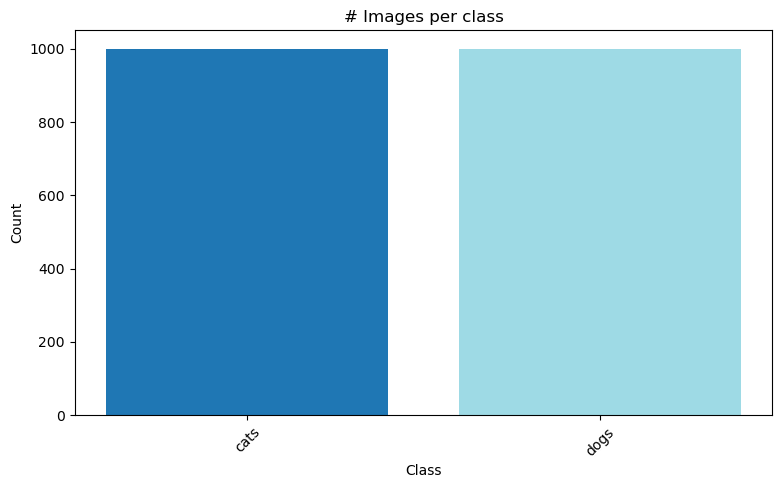
2.3 data generator로 읽어온 데이터 시각화하기
- 시각화하는 양은 1개의 배치(64개)를 전부 시각화한다.
# generator에서 64개의 이미지를 그리는 함수 정의
def show_images(generator):
batch_data, batch_labels = next(generator)
plt.figure(figsize=(20, 20))
for i in range(64):
plt.subplot(8, 8, i+1)
plt.title(labels[batch_labels[i].argmax()])
plt.imshow(batch_data[i])
plt.axis('off')
plt.show()# training dataset 일부 확인
show_images(train_generator)
# test dataset 일부 확인
show_images(test_generator)
3. 전이 학습(Transfer Learning)
- 기존에 잘 학습된 모델을 가져와서 핵심 기능을 수행하게 하는 방법이 전이 학습(Transfer learning)이다.
- 참고한 노트북에서는
DenseNet121이라는 모델을 이용해서 학습을 진행하였다.
3.1 DenseNet121 모델 가져오기
- 케라스에서는
keras.applications에서 모델을 가져올 수 있다. 1. 라이브러리 임포트하기 부분에서 정의해준 것을 확인할 수 있다.
# include_top: 신경망의 마지막에 있는 FC layer를 포함할 것인지 설정
# weights
# 'imagenet': 사전 학습된 가중치를 이용하는 설정.
# None: random initialization. 모델 구조만 이용하고 처음부터 학습시킬 때 사용하는 설정.
# path: 가중치 파일 경로. 직접 학습시킨 가중치가 있다면 그 파일을 읽어오는 설정.
# input_shape: 이미지의 규격을 알려주는 설정.
base_model = DenseNet121(
include_top=True,
weights='imagenet',
input_shape=(size_images, size_images, 3)
)3.2 DenseNet121의 layer freeze시키기
- 가져온 모델의 모든 계층에서 학습이 이루어지지 않도록 설정하는 것이다. 기존에 학습된 모델을 이용할 때 이용하는 옵션이며 가져온 모델 뒤에 추가로 붙인 계층에 대해서만 학습시키기 위한 설정이다.
for layer in base_model.layers:
layer.trainable = False4. 모델 만들기
4.1 구조 정의하기
가져온 DenseNet121 위에 강아지와 고양이를 구분할 수 있는 MLP를 추가해준다.
model = keras.models.Sequential([
base_model,
layers.Flatten(),
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dropout(0.5),
layers.Dense(2, activation='softmax')
])
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
densenet121 (Functional) (None, 6, 6, 1024) 7037504
flatten_1 (Flatten) (None, 36864) 0
dense_4 (Dense) (None, 256) 9437440
dense_5 (Dense) (None, 128) 32896
dense_6 (Dense) (None, 64) 8256
dropout_1 (Dropout) (None, 64) 0
dense_7 (Dense) (None, 2) 130
=================================================================
Total params: 16,516,226
Trainable params: 9,478,722
Non-trainable params: 7,037,504
_________________________________________________________________4.2 컴파일하기
compile()메소드의optimizer파라미터는 디폴트로 RMSprop을 이용한다. 다른 optimizer를 이용하고 싶다면 따로 지정해주어야 한다.- 여기서는 Adam을 이용했는데
optimizer파라미터에 문자열로 'adam'을 전달해도 가능하고, 세부적으로 learning rate를 지정하거나 스케줄링하고 싶다면optimizers.Adam()` 클래스의 객체를 직접 만들어서 전달해야 한다.
4.2.1 Learning rate decay
-
학습을 진행하면서 learning rate를 줄이는 것을 말한다.
-
학습 초반에는 0에 가까운 무작위 값으로 초기화가 되어 있어서 loss가 큰 상태이고, 따라서 비교적 큰 값으로 가중치를 갱신해주는 것이 효과적이다. 그러나 후반에는 어느 정도 local minimum이 있는 골에 들어가 있는 상태일 것이고 그 안에서 더 낮은 지점을 찾기 위해서 LR을 줄여서 조금씩 움직이는 것이 효과적일 것이다. 따라서 학습이 진행됨에 따라서 LR을 줄이게 됐다.
-
LR Decay 종류로는 다음과 같은 것들이 있다.
1. step decay
2. linear decay
3. cosine decay
4. inverse sqrt decay
5. exponential decay -
LR를 조절하면 loss를 줄이는데 도움이 되지만 근본적으로 모델의 아키텍쳐나 다른 하이퍼파라미터를 통해 조절을 한 후에 추가적으로 LR Decay를 해서 올리는 것이 좋다.
-
LR decay를 한다고 무조건 성능이 향상되는 것은 아니다. 어떤 SGD를 쓰냐에 따라서 잘 되는 것도, 아닌 것도 있다.
-
모델과 SGD의 여러 조합을 시도할 때는 decay를 넣지 말고 constant decay(decay 안하는 거)를 해서 빠르게 테스트를 거치는 것이 좋다.
lr_schedule = optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.01,
decay_steps=1_000,
decay_rate=0.5
)optimizer = optimizers.Adam(learning_rate=lr_schedule)
model.compile(
optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['accuracy']
)4.3 콜백 정의하기
4.3.1 조기 종료(Early stopping)
- 모델의 구조가 적절하고 충분히 복잡하다면, 학습을 거듭할 수록(에포크가 늘어날 수록) train loss는 줄어들지만 validation loss는 어느 순간 늘어나는 과대적합(overfitting)이 일어난다. 과대적합을 피하는 여러 방법 중 하나가 조기 종료(Early stopping) 이다.
- 조기 종료는 일정 시점이 되면 학습을 중지하는 방법이고, 일정 시점은 검증 데이터의 손실(validation loss)가 내려가다가 다시 증가하는 시점이다.
- 학습 과정에서 loss가 매순간 순조롭게 줄어드는 것이 아니라 조금씩 늘어나고 줄어드는 모습(진동)을 반복하기 때문에, 추가적으로 몇회 더 학습을 진행하고 학습 종료 시점을 정하게 된다.
# monitor="val_loss":
# 어떤 값을 지표로 볼 지를 지정한다.
# min_delta=0:
# 변화 최소 수준. 이 값 이상으로 변화하지 않으면 patience에 설정된 횟수만큼만 수행하고 학습을 종료한다.
# patience=0:
# 성능 개선이 없을 때 반복 횟수.
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=.001,
patience=5,
restore_best_weights=True
)4.3.2 모델 저장하기 (model checkpoint)
- 매 순간 모델을 학습할 수 없기 때문에 학습이 진행되거나 끝남과 동시에 성능이 괜찮았던 모델을
.h5파일로 저장하는 콜백이다.
# monitor="val_loss":
# 어떤 값을 지표로 볼 지 지정한다.
# save_best_only=False:
# 학습이 이루어지는 동안 성능이 가장 잘 나온 결과만 저장한다.
# save_weights_only=False:
# 모델 구조가 아닌 가중치의 값만 저장한다.
checkpoint = ModelCheckpoint(
'../models/best_model.h5',
monitor='val_loss',
save_best_only=True,
)4.4 학습하기
- 여기서는
fit_generator()메소드를 이용한다.fit()메소드와는 다르게, 데이터와 레이블을 전달하는 것이 아니라 앞서 정의한flow_from_directory()메소드의 반환값인 generator 객체를 전달하여 학습 및 검증 데이터를 모델에 전달한다.
# steps_per_epoch=None
# 한 에포크 동안 가중치(weight)를 몇 번 갱신(update)할 것인지를 지정하는 값이다.
# mini batch SGD의 경우 하나의 batch 당 한 번의 업데이트가 이루어지는 게 일반적?이기 때문에 (배치 개수) = (전체 샘플 수) / (배치 크기)로 배치 개수를 넣어준다.
history = model.fit_generator(
train_generator,
epochs=30,
steps_per_epoch=train_generator.samples // batch_size,
validation_data=val_generator,
validation_steps=val_generator.samples // batch_size,
callbacks=[checkpoint, early_stopping]
)Epoch 1/30
100/100 [==============================] - 64s 642ms/step - loss: 0.1095 - accuracy: 0.9525 - val_loss: 0.1279 - val_accuracy: 0.9712
Epoch 2/30
100/100 [==============================] - 65s 649ms/step - loss: 0.1314 - accuracy: 0.9466 - val_loss: 0.0807 - val_accuracy: 0.9681
Epoch 3/30
100/100 [==============================] - 64s 641ms/step - loss: 0.1370 - accuracy: 0.9306 - val_loss: 0.0957 - val_accuracy: 0.9481
Epoch 4/30
100/100 [==============================] - 63s 634ms/step - loss: 0.1174 - accuracy: 0.9388 - val_loss: 0.0873 - val_accuracy: 0.9719
Epoch 5/30
100/100 [==============================] - 63s 635ms/step - loss: 0.1001 - accuracy: 0.9467 - val_loss: 0.0899 - val_accuracy: 0.9737
Epoch 6/30
100/100 [==============================] - 65s 649ms/step - loss: 0.0755 - accuracy: 0.9659 - val_loss: 0.0981 - val_accuracy: 0.9706
Epoch 7/30
100/100 [==============================] - 64s 636ms/step - loss: 0.0710 - accuracy: 0.9648 - val_loss: 0.0965 - val_accuracy: 0.97625. 학습 결과 확인하기
history_df = pd.DataFrame(history.history)
epoch = history.epochplt.figure(figsize=(20, 8))
plt.subplot(121)
plt.xlabel('Epoch')
plt.ylabel("loss")
sns.lineplot(epoch[1:], history_df['loss'][1:], label='loss')
sns.lineplot(epoch[1:], history_df['val_loss'][1:], label='val_loss')
plt.subplot(122)
plt.xlabel('Epoch')
plt.ylabel("Accuracy")
sns.lineplot(epoch[1:], history_df['accuracy'][1:], label='accuracy')
sns.lineplot(epoch[1:], history_df['val_accuracy'][1:], label='val_accuracy')
plt.show()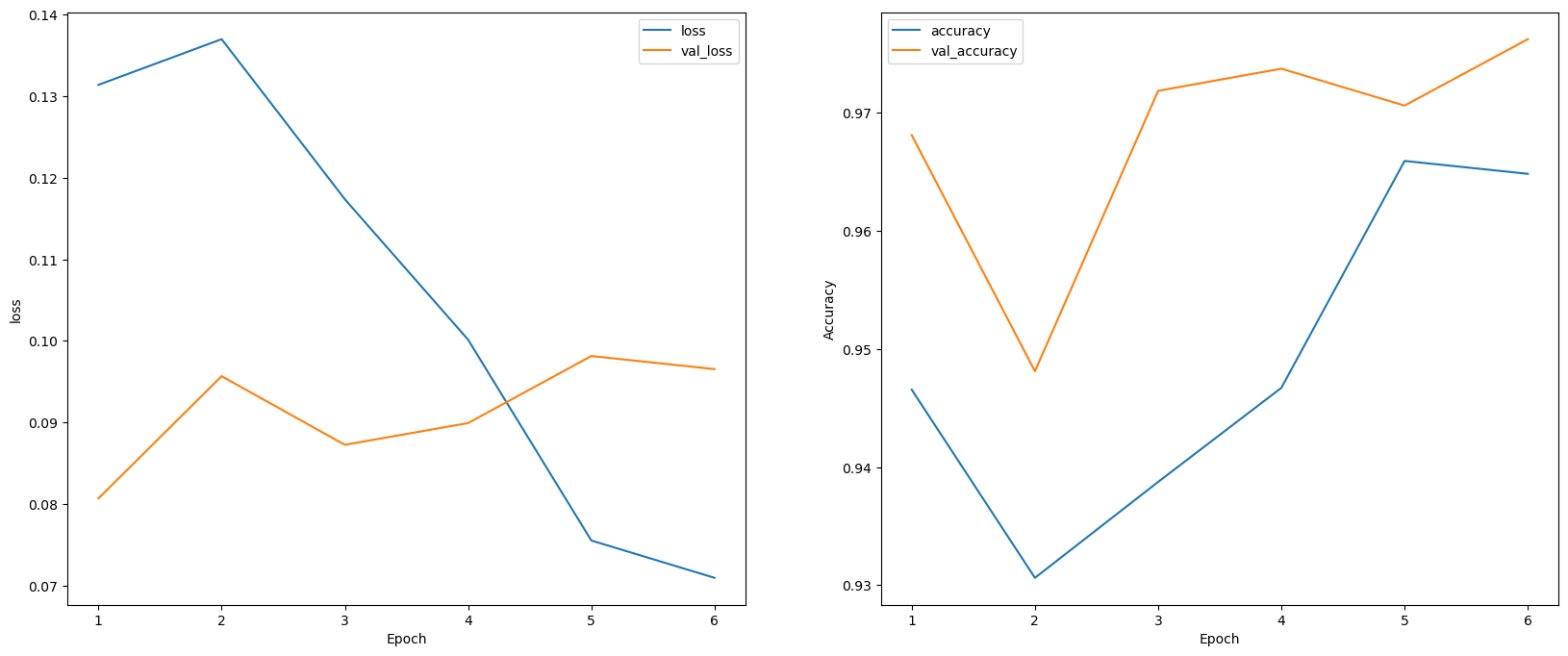
6. 모델 평가하기
scores = model.evaluate_generator(
test_generator,
steps=5
)
scores[0.11922425031661987, 0.987500011920929]
pred = model.predict_generator(test_generator)
labels = list(test_generator.class_indices.keys())
plt.figure(figsize=(12, 12))
for i in range(9):
img = test_generator[0][0][i]
label = labels[pred[i].argmax()]
# prediction result
plt.subplot(3, 3, i+1)
plt.title(f'Prediction: {label}')
plt.imshow(img)
plt.axis('off')
plt.show()

🤨 내가 한 거