[Reading Note] Inside Session-Based Recommendation: Category Filtering for Smarter Predictions
Reading Note
들어가며
Reading Note 시리즈는 제 기준 흥미로운 내용을 담고 있는 아티클에 대해 소개하는 것을 목적으로 작성된 글입니다. 세션 기반 추천에서 카테고리 기반 데이터 필터링 기법에 대해 다룹니다.
Paper Information
Title: 세션 기반 추천에서의 예측 향상을 위한 카테고리 기반 데이터 필터링 기법
Authors: 탁승연, 김경옥
Journal: 한국경영과학회 학술대회논문집 (2025.6.)
arXiv ID: 해당없음
DBpia URL
Ⅰ. Introduction
웹사이트는 어떻게 처음 보는 사용자를 인식하고 개인화된 경험을 제공할 수 있는가.
우리는 종종 물건 구매를 위해 새로운 웹사이트를 방문해 우리가 찾던 물건을 탐색하곤 합니다. 그러던 와중 어느샌가 웹사이트는 내가 찾던 물건, 같이 사용할 수 있는 물건, 이 물건을 산 사람이 구매한 다른 물건 등을 추천하기 시작합니다. 우리는 이 웹사이트에 로그인도 하지 않았고 그렇게 오랜 시간이 지난 것 같지도 않은데 웹사이트는 우리에 대해 이미 오래 전부터 알고 지내던 사람처럼 대합니다.
그렇다면 어떻게 웹사이트는 우리의 취향과 정보에 대해 인식하고 추천할 수 있을까? 이에 대한 방법론 중 하나가 바로 이 글에서 다룰 세션 기반 추천 시스템 (Session-Based Recommenders, SBRs)입니다.
Ⅰ. 1. Concept of SBRs
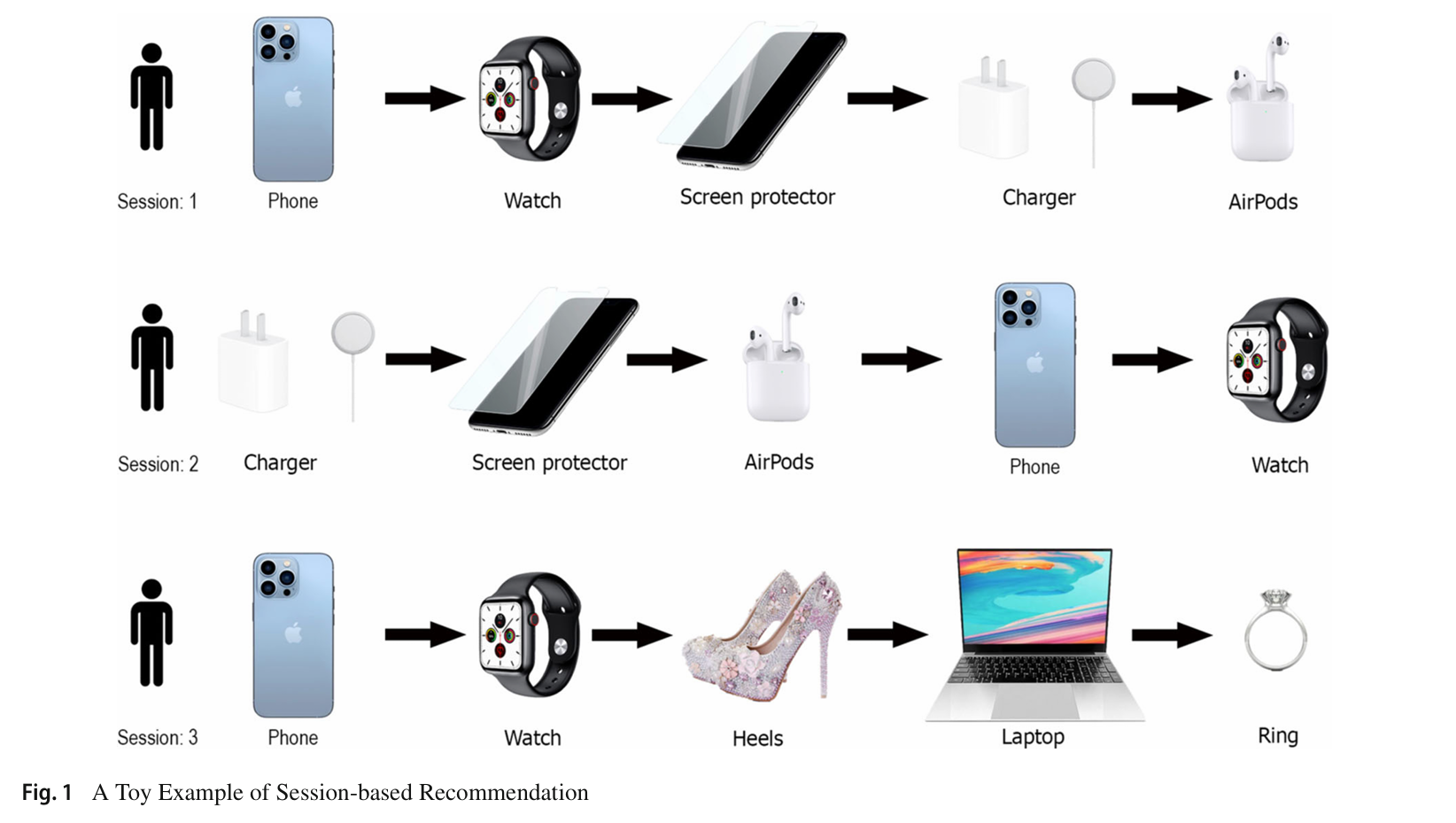
세션 기반 추천 시스템을 알기에 앞서 세션 (Session)이란 HTTP 통신에서 클라이언트가 서버와 소통을 할 때 생성되는 일시적인 정보 묶음으로, 이 아티클에서는 (비)식별 사용자가 웹 사이트를 방문하였을 때 기록되는 일련의 정보들 (Sequence)이라고 설명하고 있습니다.
세션은 서버 측에서 클라이언트에 대한 정보를 저장하고 이를 세선 ID를 통해 다루는 방식으로 분석될 수 있으며, 서버 측에서 정보를 관리하기에 탈취될 가능성이 적고 보안성이 어느정도 보장됩니다. 또한 서버와 클라이언트 간의 통신이 종료된다면 해당 세션 ID가 사라지게 된다는 특징이 있습니다.
그렇기 때문에 우리는 세션을 통해 사용자가 선호하는 상품 묶음 (Bundle)을 쉽게 알 수 있지만 정보가 충분히 모이지 않았을 때 사용자가 방문을 종료하게 된다면 그대로 수집을 종료해야한다는 한계점도 존재합니다.
이러한 한계점을 극복하기 위한 모델이 바로 SBRs입니다. 아래 이미지는 SBRs의 데이터 예시로 우리는 각 세션 ID 별로 정보 탐색 경로를 통해 사용자에 대한 추천 데이터를 수집할 있습니다. [1]
Ⅱ. Category-based Data Filtering Method
기존의 SBRs은 크게 두가지 전략으로 발전해왔습니다. 모델의 구조를 개선함으로써 세션 내 순서를 다음 행동을 예측하는 전략과, 모델 구조보다는 학습 데이터를 늘리고 다양화 함으로써 데이터의 풍부화를 통한 모델의 일반화 성능을 향상시키는 전략입니다.
첫번째 전략의 예시로는 순환신경망 (RNN) 중 하나인 Gated Recurrent Unit에 세션 시퀸스 정보를 활용하는 GRU4Rec, GRU 뿐만 아니라 attention 매커니즘도 동시에 활용하는 NARM 등이 있고,
두번째 전략의 예시로는 Rule-based 전략을 활용하여 데이터를 증강시킨 Data Augmentation (DA) Strategies in Sequential Recommenders (SR), Counterfactual 추론을 확률 모델링한 CASR, Long Tail 아이템을 포함한 세션 증강을 통해 샘플 수가 적을때의 예측 향상 목적으로 한 LOAM 등이 있습니다.
그리고 이 아티클은 두가지 전략 중 데이터 증강 연구의 개선을 시도합니다.
Ⅱ. 1. Limitations of Current Data Augmentation Strategy
이 아티클에서는 현재 DA Strategy의 한계점으로 다음과 같이 분석하고 있습니다.
- 증강 데이터셋의 낮은 품질
- 불필요한 모델 학습시간 증가
- 부수 정보(auxiliary information) 적용 방법론 부재
Crop 기법
: 기존 세션에서 일부분만 삭제하거나 생략하는 방식
예: 사용자의 클릭 순서가 [A, B, C, D, E]라면, Crop 기법은 이 중 일부만 남겨 [B, C, D]처럼 세션을 축약하는 것을 의미한다.
Injection 기법
: 세션에 새로운 행동 아이템을 삽입하거나, 기존 세션에 유사하거나 가공된 아이템을 추가하는 방식
예: 세션 [A → B → C]가 있을 때, Injection을 통해 [A → B → X → C] 또는 [A → Y → B → C → Z]와 같이 새로운 ‘X’, ‘Y’, ‘Z’ 아이템을 삽입하는 것을 의미한다.
1. 증강 데이터셋의 낮은 품질
- 기존의 rule-based 전략 (e.g. Crop, Injection,...)은 세션의 데이터의 수를 늘려 학습에서의 다양성을 확보할 수는 있지만 정작 세션의 아이템에 대한 중요도를 고려하지 않아 실제 행동 맥락을 분석하기에는 오히려 방해가 됩니다.
2. 불필요한 모델 학습시간 증가
- 특히 Injection 기법의 경우 다른 세션에서 유사하거나 가공된 데이터를 가져온 뒤 섞으므로 원래의 증간 전보다 오히려 사이즈도 불필요하게 커지고 학습 시간 역시 늘어나는 역효과를 가져올 수도 있습니다.
3. 부수 정보 적용 방법론 부재
- 세션 데이터는 사용자의 클릭 기록만 포함하기 때문에, 장기적인 취향이나 구매 의도를 충분히 파악하기 어렵다는 한계점이 있습니다. 이런 한계를 보완하기 위해 부가 정보(예: 카테고리, 시간대 등)를 함께 활용할 필요가 있지만 현재 증강 기법은 이런 사항에 대한 고려를 하지 않습니다.
예: 사용자가 노트북 가방을 사기 위해 "노트북 ⇾ 휴대폰 ⇾ 가방"이라는 세션 정보를 남긴다 하더라도 이 정보만을 보고 사용자가 무엇을 사고자 하는지 한눈에 알기란 어렵다.
이러한 한계점을 개선하기 위해 이 아티클의 저자는 다음과 같이 해결책을 제시합니다.
1. 증강 데이터셋의 낮은 품질
➡ 아이템 관계를 그래프로 모델링한 후 아이템 유사도를 구하여 세션 내 인접 아이템 관계가 유의미한지 판별2. 불필요한 모델 학습시간 증가
➡ 아이템 유사도 기반의 필터링 룰을 만들어 불필요한 아이템은 제거하는 방식 제안3. 부수 정보(auxiliary information) 적용 방법론 부재
➡ 부족한 아이템 정보를 포괄적 단계 수준의 카테고리 정보로 보완하여 아이템 표현력을 강화
Ⅱ. 2. Category-based Data Filtering Method
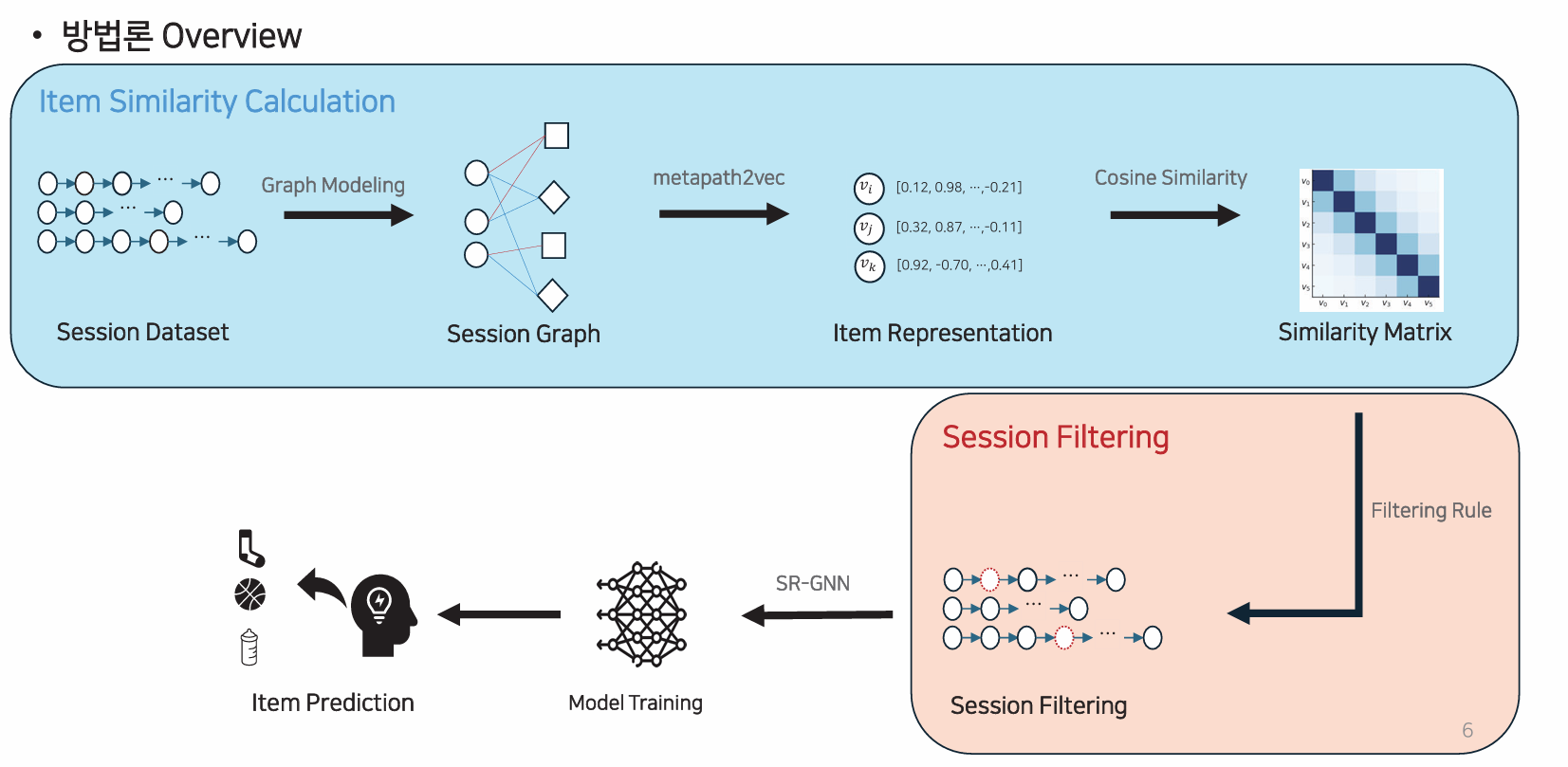
한국경영과학회 학술대회논문집, 2025.6, Fig. 1
이 아티클에서는 결국 아이템 하나하나의 유사도를 따진다기 보다는 먼저 아이템간의 관계성을 부여하고 비슷한 것을 묶음으로써, 다시 말해 카테고리 단위의 관계를 활용해 데이터 증강의 품질을 높이려 시도합니다.
즉, 세션 내 아이템이 서로 연관된 카테고리에 속하는지를 판단해 의미 있는 데이터만 남기고 불필요한 변형을 줄이는 방식입니다. 이런 필터링을 통해 데이터를 증강한다면 앞서 말한 세가지 한계점에 대해 대처할 수 있게 됩니다.
이러한 방식은 단순히 데이터의 양을 늘리는 것이 아니라, 데이터의 질적 일관성을 확보한다는 점에서 의미가 있습니다.
카테고리 단위로 유사도를 고려함으로써, 사용자의 실제 탐색 맥락과 유사한 세션을 만들어낼 수 있고, 결과적으로 모델이 불필요한 학습을 줄이면서도 일반화 성능을 높일 수 있게 됩니다.
저자들은 이를 통해 기존 rule-based 증강 방식보다 SR-GNN 모델에서 효과가 있음을 입증하였습니다. 하지만 데이터셋의 특성 등을 고려한 최적의 필터링률에 대한 후속 연구가 필요하다고 언급하고 있듯이 아직은 일반화하기 어려운 단계입니다.
Ⅲ. Conclusion
또한 이러한 접근에는 앞서 언급한 점 말고도 한계점이 몇 가지 존재합니다.
-
카테고리의 정의 자체가 도메인에 따라 달라질 수 있다는 점입니다.
예를 들어 ‘가전’과 ‘전자기기’가 동일한 수준의 카테고리로 취급되지 않는 경우, 모델이 일관된 유사도를 학습하기 어렵습니다. -
카테고리 분류 체계에 지나치게 의존할 경우, 실제 사용자 행동 패턴과 어긋날 수 있습니다. 사용자가 ‘노트북 가방’을 찾더라도 ‘패션’ 카테고리로 묶인다면 추천의 맥락이 왜곡될 수 있습니다.
-
제안된 필터링 규칙은 정적인 구조로 설계되어 있어, 새로운 아이템이나 트렌드 변화에 즉각적으로 대응하기 어렵다는 한계도 있습니다.
-
데이터셋의 분포 특성에 따라 필터링 효과가 달라질 수 있습니다.
탁승연, 김경옥, 「세션 기반 추천에서의 예측 향상을 위한 카테고리 기반 데이터 필터링 기법」, 한국경영과학회 학술대회논문집, 2025.6, 출처: https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE12294174
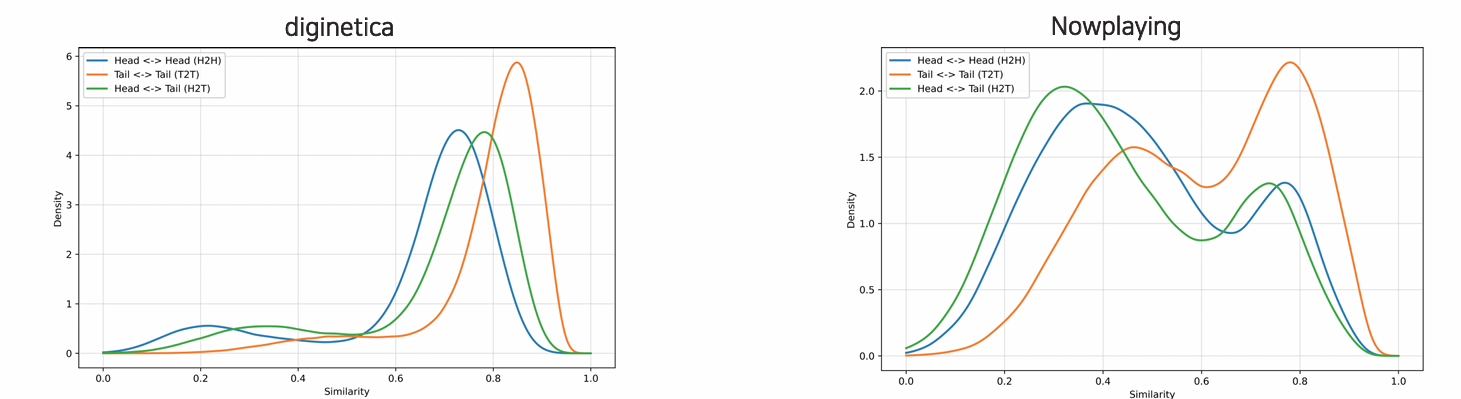
실제 실험에서도 Head 아이템 (인기 상품)과 Tail 아이템 (비인기 상품) 간 성능 차이가 데이터셋마다 상이하게 나타난다.
1. Diginetica (온라인 쇼핑몰 데이터셋)
즉, Tail 쪽은 비슷한 상품들이 몰려 있고, Head 쪽은 다양한 상품이 섞여 있으며 이는 곧 데이터가 불균형적이며, Tail 쪽 증강 시 과적합 위험이 있음을 나타낸다.2. Nowplaying (음악 스트리밍 플랫폼 데이터)
여기서는 반대로 H2H(파란색)가 높고, T2T(주황색)는 낮은 유사도 구간에 퍼져 있어
인기 아이템들 간의 유사도가 높고 비인기 아이템은 서로 다른 방향으로 다양하게 퍼져 있다.➡ 데이터셋 특성에 따라 Head/Tail 간 유사도 구조가 완전히 다르게 나타남을 보여준다.
따라서 카테고리 정보를 동적으로 재구성하거나, 사용자 행동 기반의 가중치 학습 및 Head/Tail 균형 조정 전략과 결합하는 방향으로 접근을 해보는 방법도 있을 수 있습니다.
References
1. Gwadabe, T. R., Al-Hababi, M. A. M., & Liu, Y. (2023). SimGNN: simplified graph neural networks for session-based recommendation. Applied Intelligence, 53(19), 22789–22802. https://link.springer.com/article/10.1007/s10489-023-04719-w
2. 탁승연, & 김경옥. (2025. 6). 세션 기반 추천에서의 예측 향상을 위한 카테고리 기반 데이터 필터링 기법. 한국경영과학회 학술대회논문집, 144–146.
https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE12294174
마무리하며
이번에는 올해 (2025년) 6월에 주최된 한국경영과학회 2025년 춘계 공동학술대회 논문집 중 한 발표에 대해 다루어 보았습니다. 추천 알고리즘은 저도 높은 이해를 가지고 있지는 않은터라 제대로 다루지 못하고 개괄적인 흐름만 정리했으니, 만약 이 주제에 대해 관심이 있으시다면 12페이지이니 한번 슥 보는 것도 추천드립니다.
이 아티클의 실험에서 활용된 데이터셋은 세션 기반 추천 연구에서 매우 자주 사용되는 대표적인 벤치마크 데이터셋이라고 하니 흥미가 있으시다면 한번 데이터셋을 가지고 놀아보시는 것도 좋다고 생각합니다. (일단 저는 중간고사가 지나면 한번 만지작해볼 예정입니다.)
이번의 긴 글도 읽어주셔서 감사합니다. 이 주제에 대해 의견이 있다면 자유롭게 작성해주시면 감사하겠습니다.
