들어가며
Reading Note 시리즈는 제 기준 흥미로운 내용을 담고 있는 아티클에 대해 소개하는 것을 목적으로 작성된 글입니다.
최근 RAG를 통한 F1 규정 챗봇을 만들다가 LLM의 출력물에 대한 평가에서 의문이 생겨 이 글을 작성합니다.
"그때 그때 출력물이 다른게 당연한 LLM은 어떻게 평가될까?"
Paper Information
Title: Non-Determinism of “Deterministic” LLM Settings
Authors: Berk Atil, Sarp Aykent, Alexa Chittams, Lisheng Fu, Rebecca J. Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, Tomasz Tudrej, Ferhan Ture, Zhe Wu, Lixinyu Xu, Breck Baldwin
Journal: NFI
arXiv ID: arXiv:2408.04667v5
Ⅰ. Introduction
"신은 주사위를 던지지 않는다. 하지만 GPT는 일상이 주사위 굴리기이다."


같은 프롬프트를 입력했음에도 다른 답변을 하는 모습을 볼 수 있다.
ChatGPT를 활용하다 보면 우리는 같은 질문을 했음에도 다른 대답을 해오는 GPT를 일상적으로 보게 됩니다. 이는 GPT의 자연스러운 특성이며 우리는 이것에 놀라지 않습니다. 하지만 우리가 Machine Learning을 배우다 보면, 조금 새롭게 보일때도 있습니다.
역사적으로 ML은 추론을 통해 "답"을 찾아내는 과정이 곧 구현 목표였습니다. "같은 입력이 주어지면 같은 출력을 내뱉는다" 이것을 전제로 했기에 RMSE (Root Mean Squared Error, 평균 제곱근 오차)와 같이 Answer에 대한 error를 평가한다던가 (예측 모델), Confusion Matrix를 통한 분류의 범주에 대한 정확성을 평가한다던가 (분류 모델)하는 방식으로 말입니다.
그런데 이런 맥락에서 LLM은 조금 유별납니다. 애초에 LLM은 동일 입력에도 결과가 달라지는 특성이 있어, 기존 평가 지표가 이를 반영하기에는 어려움이 존재합니다. 다시 말해 출력 간 변동 자체를 측정할 수 없기 때문에 우리의 고전적인 평가 지표로는 당연히 담을 수가 없게 됩니다.
이 논문에서 또한 이러한 LLM의 변동성 (Variance)에 대해 지적합니다.
“One aspect of reliability that has not to our knowledge been addressed sufficiently in the literature is lack of user control over variance in LLM output across LLMs and platforms under settings that are assumed to be deterministic.” (Atil et al., 2025, p. 1)
우리는 보통 이 출력의 일관성을 temperature와 같은 인자값을 이용해 조절하지만, temperature=0 (deterministic)으로 최대한 변동성을 억누른다한들 결국 다른 출력물이 나오는건 매한가지이게 됩니다. 우리는 이런 LLM을 어떻게 평가할 수 있을까요?
Ⅱ. Concepts of Controlling LLM Determinism
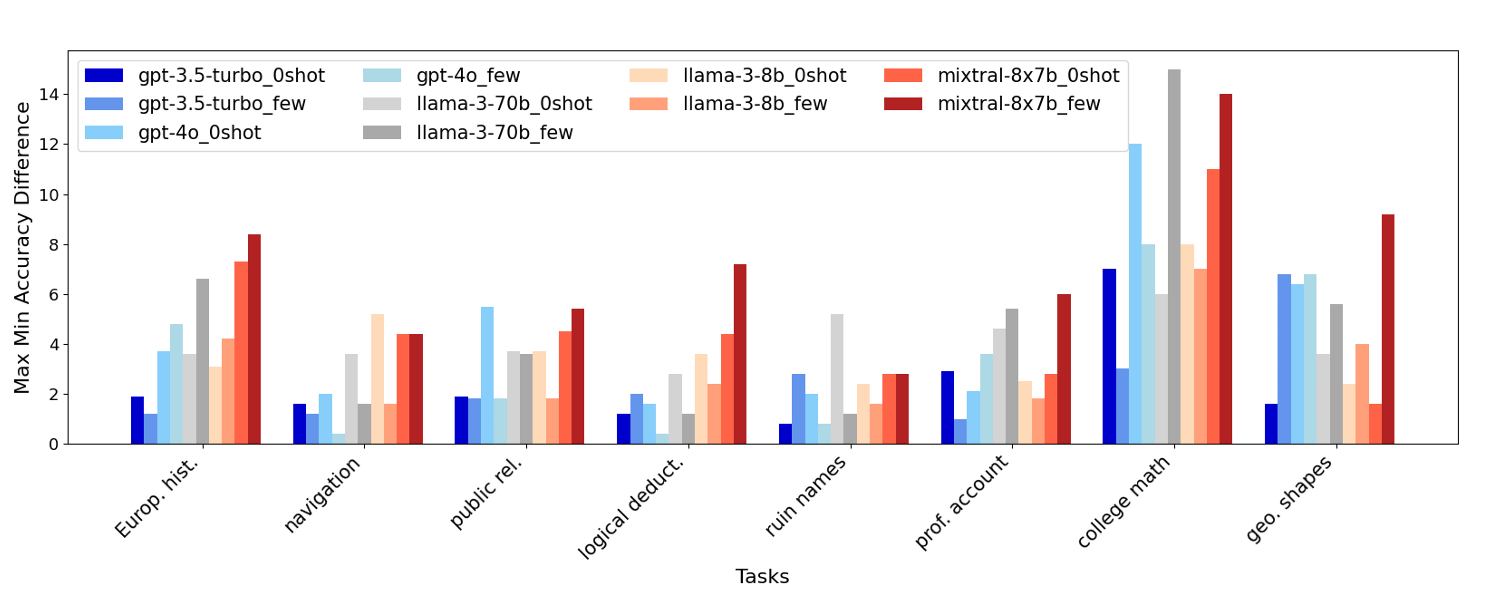
Figure 1.은 우리가 LLM의 성능 비교를 위해 많이 사용하는 벤치마크들에 관한 실험으로 deterministic을 보장해야하는 환경 하에서 10번 반복을 통해 실행된 Accuracy의 최대값 최소값의 차이를 보여주고 있습니다. 보면 Task마다 편차는 존재하지만 최소 2%p만큼 차이가 나는 모습을 볼 수 있습니다. 이를 통해 우리는 아무리 deterministic한 설정을 하더라도 존재하는 출력물의 non-deterministic에 대해 고민하게 됩니다.
과연 이렇게 변동성이 있는 벤치마크가 의미가 있을까요?
이 아티클의 저자 또한 이런 의문을 가지고 연구를 진행했다고 합니다.
참고로 Figure 1. 에서의 deterministic setting이란 아래와 같습니다
“We set the temperature at 0, top-p at 1, and fix the seed. We use the same compute infrastructure, inputs, and configurations.” (Atil et al., 2025, p. 3)
Ⅱ. 1. Non-determinism in LLMs and its Impact on Evaluation
LLM의 non-deterministic은 성능 평가에 어떤 영향을 주는가?
Introduction에서도 이미 언급했지만 LLM의 변덕스러운 출력은 우리에게는 익숙한 일입니다. 우리가 마치 말을 할 때 항상 동일한 주제에 동일하게 말하지 않듯이 이러한 LLM의 변동성은 오히려 모델이 인간적이게 보이기도 합니다.
하지만 이 아티클에서는 단순하게 출력의 변동성이 문제이다라고 하는건 아닙니다. 동일한 모델, 동일한 데이터, 동일한 설정을 사용했음에도 실행에 따라 정오가 달라지는 것, 이 현상에서 사용자가 의도적으로 조절할 수 있는 하이퍼파라미터 범위를 넘는다는 것이 문제가 됩니다.
다시 말해 non-determinism은 단순히 LLM의 출력 특성에만 머무르는게 아니라 평가에서의 문제로 전환되므로, 우리는 이 현상의 원인을 변동 자체가 아닌 이러한 변동성을 고려하지 못하는 평가로 시선을 옮겨야하는 것입니다.
같은 모델과 같은 설정이라면, 성능 지표는 하나의 고정된 값으로 측정될 수 있다.
Introduction에서도 언급했지만 기존의 Machine Learning 평가 시스템은 위와 같은 전제하에 작동합니다. Accuracy, RMSE, F1-score 모두 이 전제를 바탕으로 존재하는 평가 지표이며 point로써 작용합니다. 하지만 이런 평가지표를 그대로 LLM에 가져오게 된다면 이는 조금 문제가 됩니다.
결국 LLM은 하나의 point가 아니라 결과의 분포, 즉 range로 이해되어야 하는 모델입니다. 그렇다면 우리는 단일 수치로 요약된 성능이 아니라, 이러한 range를 어떻게 평가하고 해석해야 하는지에 대한 고민을 하게 됩니다.
Ⅱ. 2. Stability as an Evaluation Criterion
그래서 우리는 어떤 평가 지표를 활용해야할까?
range 로 이해되어야 하는 LLM을 평가하기 위해서는 단순히 단일 시행에서 정답을 얼마나 잘 맞추는가가 아닌 얼마니 일관된 출력을 생성하는가를 또한 고려해야합니다. 그렇기에 저자는 TARr@N과 TARa@N으로 구성된 TAR@N을 제시하고 있습니다.
Total agreement rate@N (TAR@N)
: the percentage of test set questions across N runs where generated answers are all identical, regardless of whether the answer was correct.We have two variants of TAR@N:
- TARr@N (TAR@N for the raw model response)
: The LLM responses are string equivalent.- TARa@N(TAR@N for the answer)
: The parsed answers are the same, e.g., “The answer is a)” is the same as “a) is the answer”.
TARr@N은 TARa@N보다 더 엄격한 지표로 단순히 답이 동일한 내용을 담고 있는가 뿐만 아니라 출력된 String이 일치하는가 또한 평가합니다. 즉 TARr@N은 문자열 수준의 불안정성을 드러내며, 시스템 구현 난이도와 오류 가능성을 직접 증가시킬 수 있는 위험성을 드러내는 지표로 작동합니다.
이 아티클에서 사용된 벤치마크는 Beyond the Imitation Game Benchmark Hard (BBH)와 Measuring Massive Multitask Language Understanding (MMLU)로, 이제 TARa@N와 TARr@N이 어떻게 작용하는지 살펴보겠습니다.

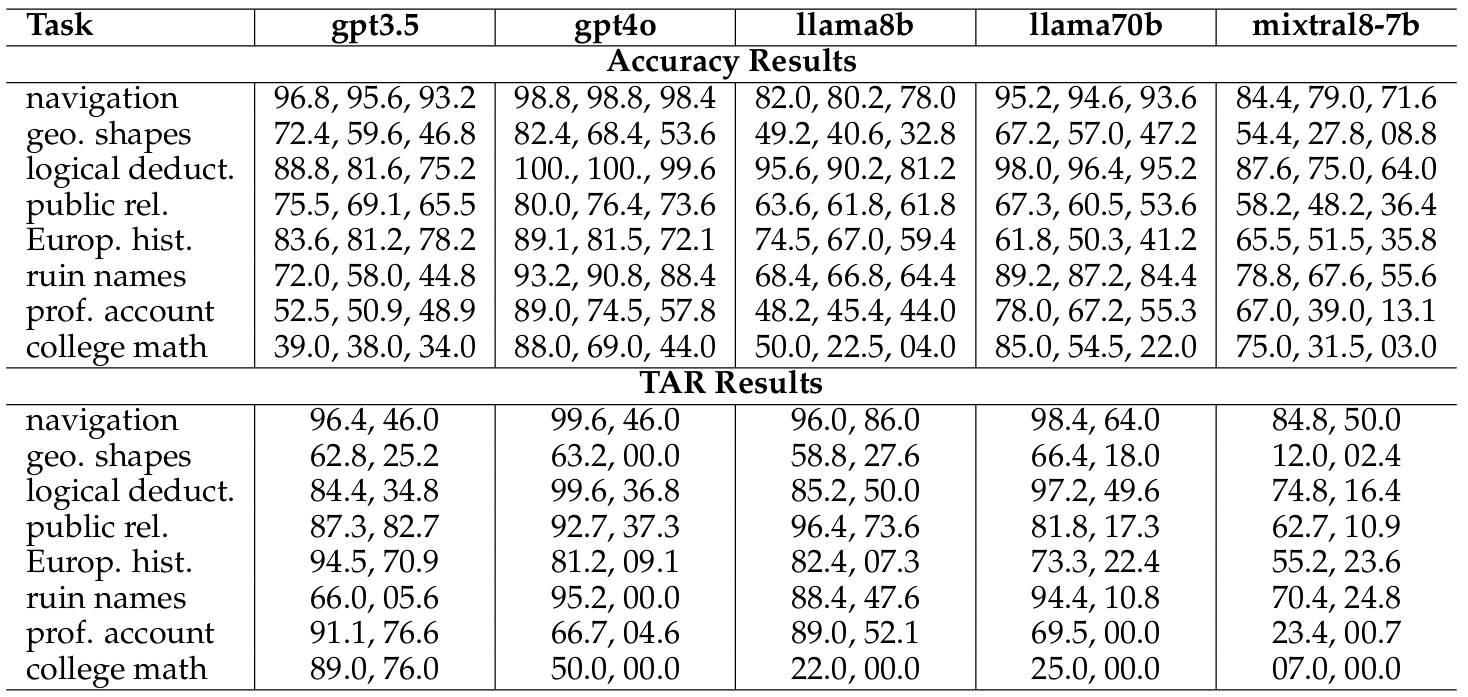
이 아티클의 실험 결과를 보면 당연하게도 TARa@10은 TARr@10보다 높은 것을 볼 수 있습니다. 그리고 비슷한 정확도를 보이더라도 TAR@10을 통해 답의 일관성을 확인해볼 수 있습니다.
한가지 예시로 navigation task에서 llama8b와 mixtral8-7b를 보면 Accuracy result 부문에서는 Worst Accuracy가 6.4%p로 다소 큰 차이를 보이지만 Best/Median Accuracy에서는 2.4%p와 0.8%p로 상대적으로 큰 차이를 보이지는 않습니다. 하지만 TAR Results 부문에서는 10%p가 넘는 차이를 보이며 llama8b가 훨씬 안정적인 출력을 보이게 됩니다.
즉, accuracy만 보면 두 모델이 비슷해 보이지만, TAR@10을 보면 실제 사용 시 llama8b가 훨씬 예측 가능한 모델임을 알 수 있습니다.
그렇기에 우리는 기존의 Accuracy 기반 평가지표에서는 얻을 수 없는 모델의 안정성에 대한 정보를 TAR@N 지표를 통해 얻을 수 있음을 확인하게 됩니다.
따라서 Benchmark 모델의 평가 과정에서는 단일 accuracy가 아닌, range와 stability를 함께 보지 않는 한 LLM 성능 평가는 언제든지 오해를 낳을 수 있다라고 볼 수 있습니다.
Ⅲ. Limitations & Conclusion
그래서 TAR@N이면 만사 오케이일까? 그리고 모든 LLM에 적용될 수 있는 논리인걸까?
이 아티클은 결국 non-deterministic한 LLM을 어떻게 통제하고 관리하는가가 아닌 이러한 non-deterministic을 어떻게 성능 평가에서 반영할 수 있을까에 대한 고민에 가깝습니다.
물론 이 연구도 실험은 temperature=0이라는 특정한 환경에 초점을 맞추었으며 일부 모델은 오직 closed-source API 환경에서 실행되었습니다.
closed-source API란?
모델의 내부 구현과 실행 방식이 공개되어 있지 않고, API를 통해서만 모델을 호출할 수 있는 환경을 의미합니다.
- GPT-3.5, GPT-4o (OpenAI)
- Claude, Gemini 등 상용 LLM API
객관식 벤치마크를 기반으로 한 분석이기 때문에, 자유 생성 과제에 동일한 평가 방식을 그대로 적용하기에는 추가적인 논의가 필요합니다. 그럼에도 불구하고, 이 논문의 핵심 주장인 단일 accuracy 기반 평가는 LLM의 실제 동작을 충분히 설명하지 못한다가 설득력이 있는 것에는 영향이 없습니다.
이번 글은 LLM을 어떻게 평가할까에 대한 궁금증으로 출발한 글이며, LLM의 변동성에 대한 평가요소로 TAR@N을 보았습니다. 이번 긴 글도 읽어주셔서 감사드리며, 의견이 있다면 자유롭게 댓글로 남겨주시면 감사하겠습니다.
