이번 블로그에서는 cs182 1강을 정리할 예정이다. 1강은 머신러닝과 딥러닝에 대한 정의를 하고 어떤식으로 표기하는지까지 설명한다.
해당 강의의 유튜브목록은 링크이며 해당 강의 사이트는 여기에서 찾을 수 있다.
1강
1.1 번역모델에 대한 개요
이 세상엔 6000개가 넘는 언어가 있다. 기존 자동번역같은 경우에는 한쌍의 데이터가 필요로 한다. (En-Fr, En-Gr과 같은 데이터셋) 문제는 6000개의 언어마다 한쌍의 데이터셋을 만든다고 가정하면 약 1800만개의 쌍이 필요하다. 또한 각 데이터셋에 따른 번역모델을 만들어줘야 하고 반대 상황에서도 만들어야하기 때문에 모든 언어를 번역하는 모델도 약 36000만개가 필요하게 되어 많은 리소스를 낭비할 우려가 있다.
그래서 기존 기계번역에서 벗어나 Multilingual 기계번역으로 방향성을 잡게된다. Multilingual같은 경우 각 언어에 대한 한쌍의 데이터셋이 필요하지만 하나의 모델로 학습하게 만들어 원하는 언어를 넣게 되면 그에 맞춰서 번역해주는 방식이다. Multilingual방식은 사람들이 많이 사용하지 않는 언어들을 다른언어로 번역을 하게 될때 더 좋은 성능을 낼 수 있고 zero-shot 기계번역을 가능하게 만들어 어떤 언어를 번역하는데 있어 해당언어 데이터셋이 반드시 필요하지 않다. 예를 들어 한국어-영어, 영어-한국어, 영어-스리랑카어 데이터셋이 있을 경우 우리는 한국어-스리랑카어로 번역이 가능해진다.
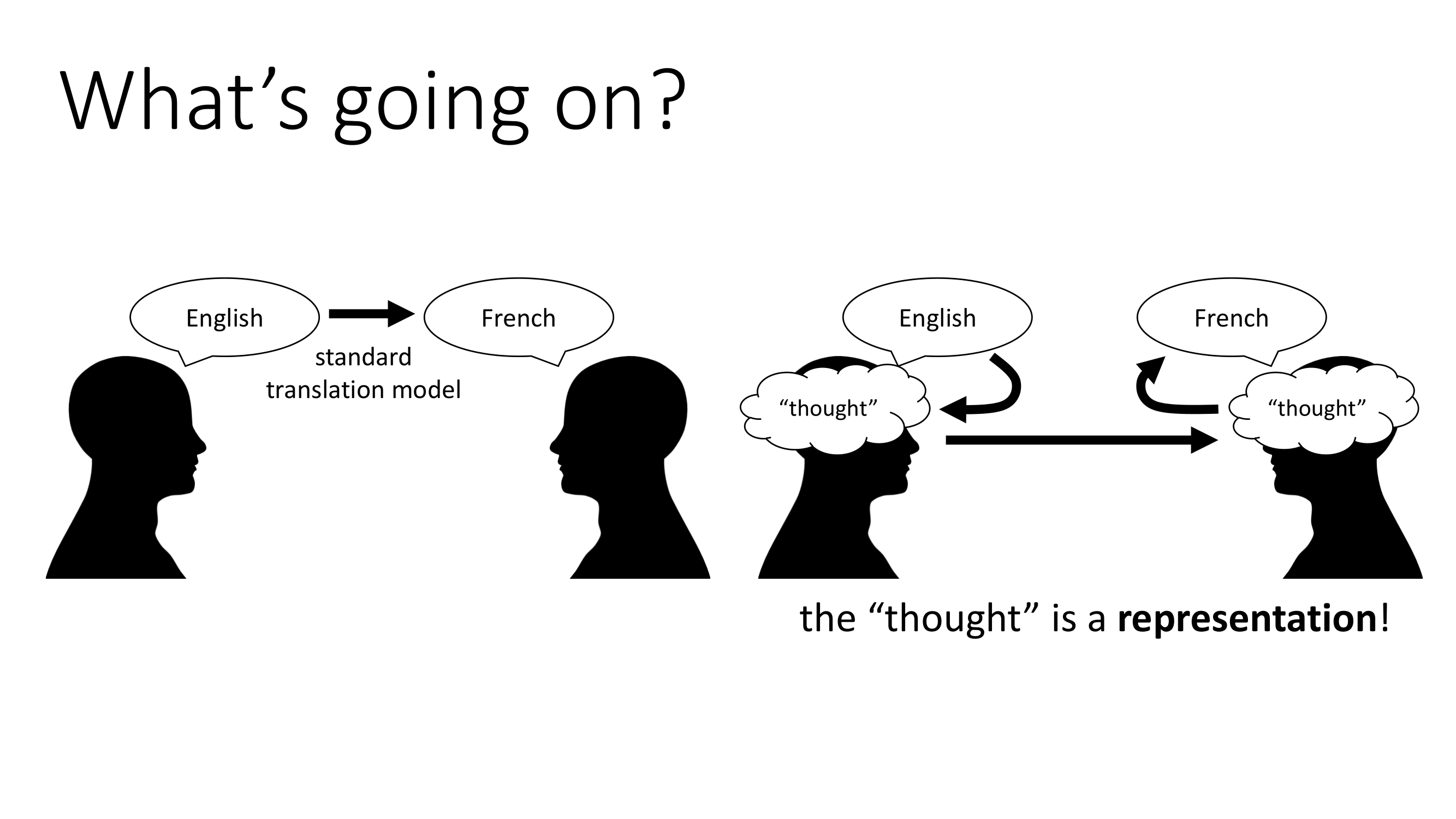
기존 번역모델에서 Multilingual 기계번역으로 바뀌었을때 가장 많이 바뀐 점은 번역에서의 방식에 있다고 판단된다. 과거의 번역 모델은 용어를 단순하게 바뀌는 점에 있었다. 그러나 번역은 단순히 용어를 바꾸는 것이 아닌 해당 내용에 대한 사고과정이 들어가야 한다. 이때의 사고과정은 딥러닝에서 'represenatation'이라고 부르고 이는 딥러닝에서 가장 중요한 키워드이다.
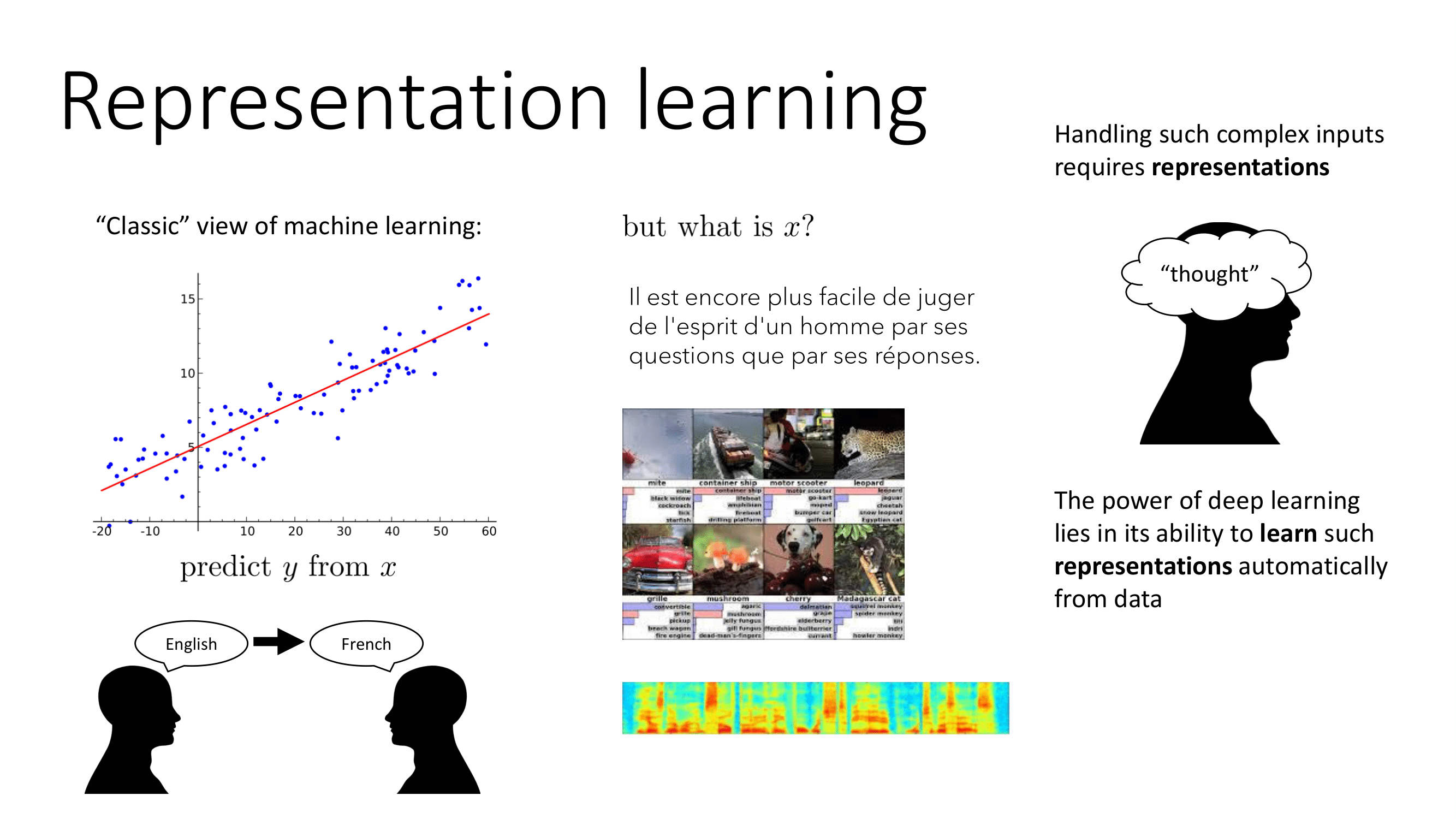
전통적인 머신러닝의 최종 목표는 x로부터 y를 예측하는 것이다. x가 비정형데이터인 경우 정형데이터보다 훨씬 복잡하고 이를 조절하는 것이 representation이다. 결론적으로 딥러닝의 힘은 데이터로부터 자동적으로 representation을 배우는 능력에 있다고 볼 수 있다.
1.2 딥러닝의 변천과정
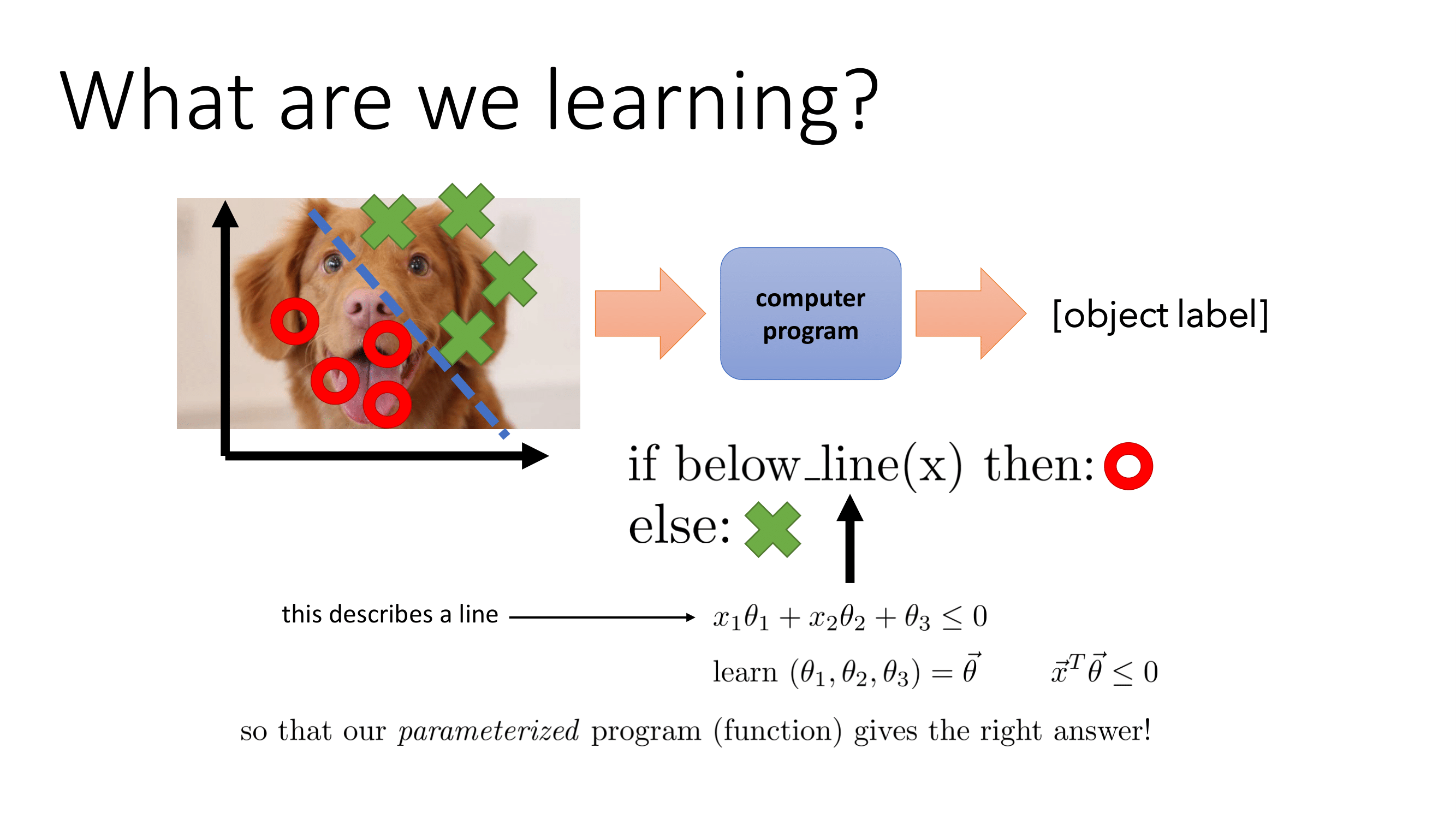
강아지와 고양이를 분류하는 프로그램이 있다고 가정하자. 기존 프로그래밍에서는 어떤 사진에 대해 고양이인지 강아지인지 구분할 수 있는 규칙을 정하고 이를 대입한다. 그러나 우리는 강아지인지 고양이인지 구분하는 규칙을 모른다. 또한 설사 만들려고 시도한다고 해도 규칙은 매우 복잡하고 많은 예외와 특수케이스가 존재할 가능성이 높다. 예를 들면 우리는 '고양이는 수염을 갖고 있다'라는 규칙을 내세웠다고 가정하자. 그런데 수염이 모종의 이유로 잘린 고양이가 있을 수 있고 수염이 짙게 보이는 강아지가 있을 수 있다. 또한 해당 규칙은 고양이의 뒷모습이 찍혔을때는 확인 불가능하다. 이런 경우에는 우리는 input-> output 관계를 직접 손으로 정의하기보다 데이터간의 관계를 얻을 수 있는 프로그램을 정의하는 편이 빠르다. 이를 도식화하면 밑의 그림처럼 나타낼 수 있다.
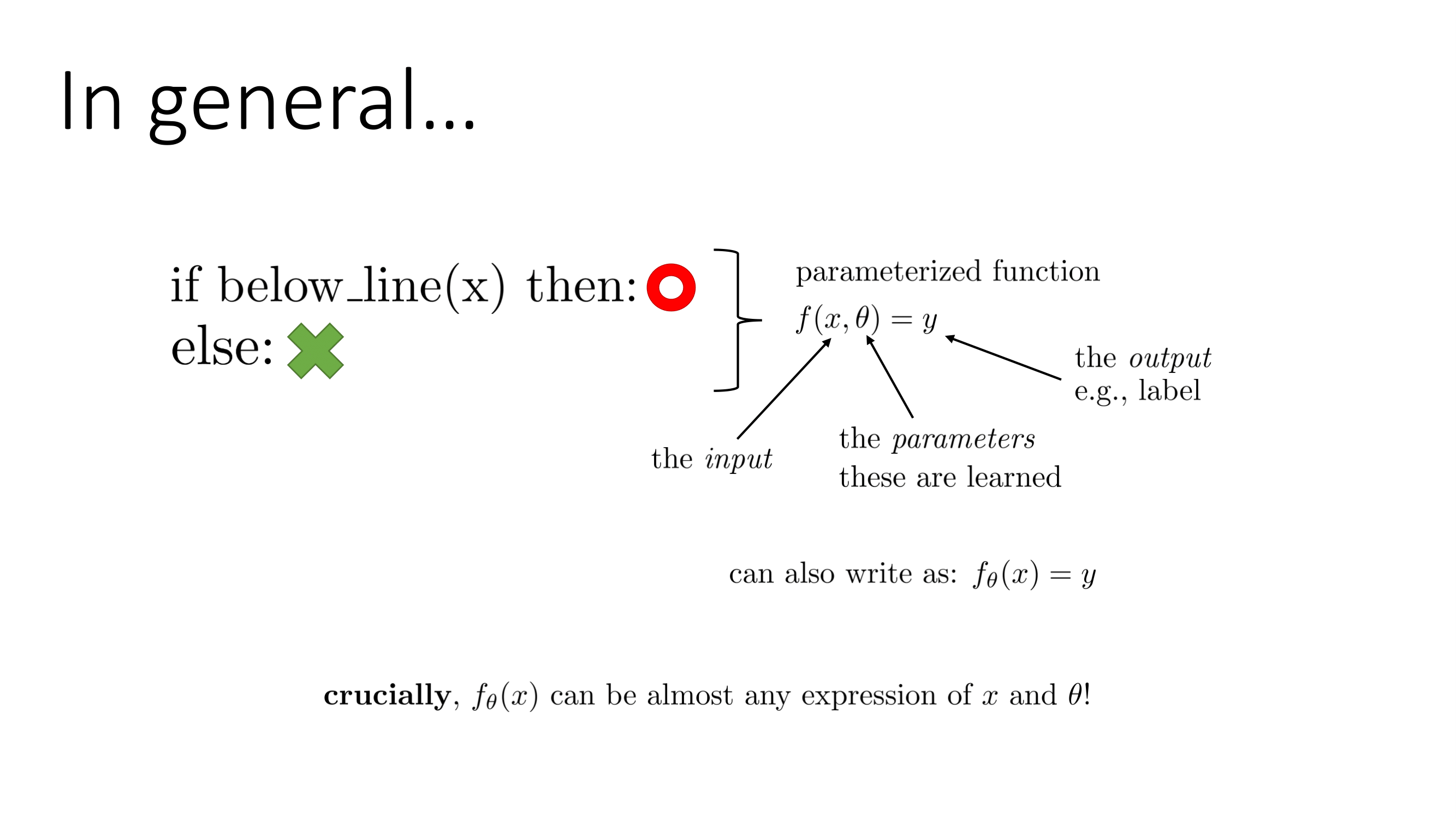
여기에서 에서 x는 input, y는 output을 의미하며 는 학습할 파라미터를 의미한다. 이를 줄여쓰게 되면 로 쓸 수 있다. 이 방식같은 경우 데이터간의 규칙을 파악해 분류기를 만들 수 있다. 하지만 이 방식은 치명적인 문제를 내포하고 있다. 이 방식에서 는 x로부터 feature를 뽑아낸 고정된 함수이다. 즉 함수 는 feature를 뽑을때는 edge를 사용해 규칙을 만드는 것이다. 이러한 방식은 규칙을 직접 만들지는 않지만 feature를 직접 프로그래밍해야 한다. 그렇기에 좋은 feature를 뽑아내는 것이 중요하지만 이는 상당히 어렵다. 그래서 우리는 단순히 규칙만 만드는 shallow learning에서 탈피해서 feature까지 학습시키는 딥러닝으로 발전하게 된다.

Feature까지 학습시키기 위해서는 input을 간단한 parameterized 변환으로 바꾸는 방식으로 한다. 이러한 representation은 더 추상적이고 느낌적인 면을 더 불편하지 않게 하고 label을 예측하는데 훨씬 쉬워지는 장점을 갖고 있다. 우리는 이러한 학습을 딥러닝이라고 부른다.
결과적으로 딥러닝은 학습된 representation의 다양한 layer를 쌓는 머신러닝이라 볼 수 있다. 즉 input에서 내부 representation을 지나 output으로 나오는 것을 represent하는 함수를 NN(Neural Network)라고 부르며 모든 layer의 파라미터들은 종종 모든 task 목적에 대해 학습된다.
1.3 딥러닝이 태동한 이유와 쟁점

딥러닝이 태동한 이유에는 크게 3가지가 있다. 우선 다층의 layer를 쌓은 Big model이 등장했다. 기존 LeNet의 경우 7개, AlexNet은 8개인 반면에 AlexNet이후 layer들이 급속하게 늘어나기 시작했고 2015년에 나온 ResNet의 경우 152개의 layer로 이루어져있다. 두번째로 다양한 예시가 들어있는 거대한 데이터셋의 등장이다.

1990년대에는 MNIST 데이터셋 60000개의 흑백이미지였다면 2009년에 나온 CIFAR 10은 60000개의 색이 들어간 이미지고 같은 해에 나온 ImageNet은 150만개의 컬러 이미지의 데이터셋이다. 거대한 데이터셋이 나오기 시작하면서 딥러닝을 사용하기에 적합한 환경이 제공되었다고 본다.
마지막으로 컴퓨터 HW발전이 있다. GPU를 그래픽 향상 이외에 딥러닝 연산에서도 탁월한 성능을 보였고 GPU가 발전하는 만큼 딥러닝 연산속도와 처리용량이 늘어나 더 깊고 복잡한 모델을 만들 수 있게 되었다.
이러한 딥러닝은 몇가지 이슈를 갖고 있다. 우선 딥러닝 학습에 대한 비용이 있다. Big model을 만들어서 사용하게 되면 비용이 많이 들기 때문에 딥러닝은 비싼 학습이다라고 생각할 수 있지만 또 다른 한편에서는 딥러닝 모델을 만들게 되면 학습 비용자체는 비싸지만 얻을 수 있는 편익이 많기 때문에 학습이 비싸지 않다고 볼 수도 있다. 또 다른 이슈는 큰 모델을 만들어서 사용하기 때문에 좋은 feature가 어떤건지 알 필요는 없고 데이터를 통한 결과가 중요하다는 관점과 현재보다 더 나은 task에 강건하기 위해서는 feature가 어떤게 좋은지 알아야 한다는 관점도 있다. 마지막으로 model은 모델 설계자의 의도보다 데이터로 부터 그들의 성능이 나온다고 생각하는 관점(Learning)과 효율적으로 학습시킬때 이미 모델 설계자의 의도가 들어갔다고 생각하는 관점(inductive bias)이 있다.
정리
이번 강의를 정리하면서 제일 좋았던 점은 shallow learning에서 deep learning으로 바뀌는 지점에서 인사이트를 도출할 수 있었다. 그리고 딥러닝에 대한 이슈에서도 고민해볼 여지가 충분히 있고 딥러닝이라는 방법론에서 관점에 따라 자신의 연구가 달라지고 결과도 달라지겠다는 생각이 들었다.
