-
풀고자 하는 문제
그림에서 위에 있는 Atari 게임을 A, 밑에 있는 게임을 B라고 하자. 지금 우리가 가진건 오랜 시간 학습을 통해 A 게임을 어느정도 잘 수행하는 policy야. 이제 B를 잘 플레이하는 policy 또한 학습하고 싶은데, 처음부터 생짜로 학습한다면 수많은 환경과의 interaction이 필요하여 또다시 오랜 시간이 걸릴거야. 그렇담 A 게임을 잘 플레이하는 이미 학습된 policy의 정보를 어느정도 활용하여 B 게임에 대한 policy를 빠르게 학습할 수 있을까? 이는 transfer learning (domain adaptation) 문제로 귀결된다.
자 그럼 두 가지 상황을 생각해보자.- 게임 A(source)와 B(target)가 비슷할 때
이 경우는 target 도메인의 state representation을 그냥 source 도메인의 state representation에 최대한 가깝도록(모방하도록) 만들면 된다 AADA (Adversarial Discriminative Domain Adaptation) - 게임 A(source)와 B(target)가 매우 매우 다를 때
하지만 게임의 특징이 많이 다른 경우라면, target 도메인의 state representation을 source와 완전 비슷하게 만들어 버릴 때 target 도메인이 갖고 있는 고유한 state 특성을 잃을 가능성이 크다. 따라서 target 도메인의 고유한 state 특성은 살리면서, 최대한 source 도메인의 state representation을 모방하도록 만들어야 한다 AAE (Adversarial Autoencoder)- AAE란?
- AE + GAN
- Its encodings are trained to mimic the imposed prior distribution (GAN objective; source encoding) and to encode the essential domain information (AE objective; reconstruction of target domain)
- This architecture allows us to learn a feature space that captures the target domain while aligning it with the source domain
- AAE란?
- 게임 A(source)와 B(target)가 비슷할 때
-
Main contributions
- Observation으로부터 좋은 state representation 뽑기 (exploration을 줄이고 학습 수렴 속도를 높일 수 있도록)
- Knowledge transfer from source domain to target domain
- Unsupervised 방법론
-
방법론
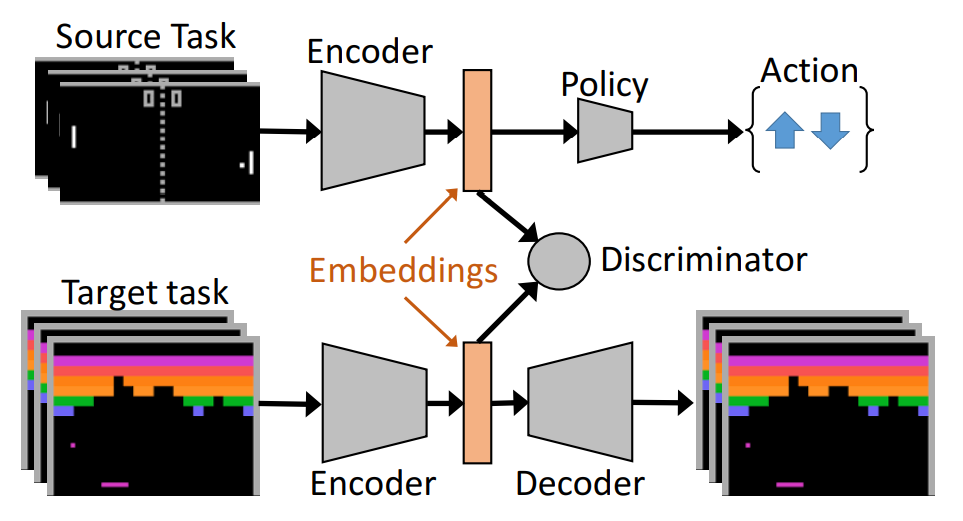
- 먼저 source task에 대해 학습이 완료된 encoder + policy를 준비
- [Pre-training phase] AAE 통해 target state representation 다듬는 시기 (train target embedding network)
- [Training phase] 학습 완료된 target encoder을 encoder initialization으로 활용하고 policy(A2C)를 학습함 (finally we use the trained target embedding network to initialize the target modael and train it using A2C)
- 코드: 없음
