-
풀고자 하는 문제
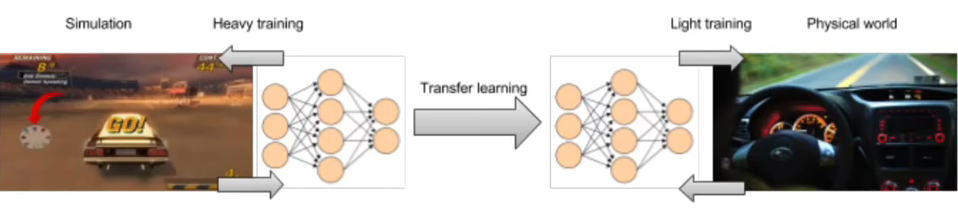 로봇 분야에서는 sim2real이 큰 문제임. 특히나 환경이 조금 바뀌어도 크게 영향을 받는 민감한 task들에 대해서 성공적으로 simulation에서 학습된 강화 알고리즘을 실제 환경에 적용시키기 위해 reality gap을 해결해야 한다. 이 논문은 로봇 하키를 위한 강화학습 알고리즘에 기반하여 쓰여졌는데, 여기서 다양한 환경이란 puck과 지면 사이의 마찰력을 의미한다.(unknown parameter values)
로봇 분야에서는 sim2real이 큰 문제임. 특히나 환경이 조금 바뀌어도 크게 영향을 받는 민감한 task들에 대해서 성공적으로 simulation에서 학습된 강화 알고리즘을 실제 환경에 적용시키기 위해 reality gap을 해결해야 한다. 이 논문은 로봇 하키를 위한 강화학습 알고리즘에 기반하여 쓰여졌는데, 여기서 다양한 환경이란 puck과 지면 사이의 마찰력을 의미한다.(unknown parameter values) -
Main contributions
- Policy simplification (+ latent space modeling)
- 기존에 policy라 함은 한 state가 주어졌을 때 그에 해당하는 적절한 action을 내뱉는 방식으로 모델링되는데, 여기서는 하나의 goal state가 주어지면 그에 해당하는 적절한 trajectory 전체 (현재 state에서 goal state까지의 경로)를 내뱉는 방식으로 모델링 함
- 하지만 trajectory 자체 또한 여러 센서의 time series 데이터로 고차원이기 때문에 latent space generative model (VAE)를 활용한다. VAE는 실제 데이터를 활용하여, encoder를 통해 저차원의 latent z로 맵핑된 후, decoder를 통해 다시 원본 데이터를 reconstruct 하는 방식으로 학습된다. 학습이 완료된 decoder는 latent space를 실제 trajectory로 맵핑하는 역할을 하므로, 결국 우리가 학습해야 하는 policy는 하나의 goal state가 주어지면 그에 해당하는 적절한 trajectory latent z를 내뱉는 방식으로 simplification 될 수 있다. 또한 VAE 자체가 실제 데이터 학습 되었기 때문에 실제 physical 환경에서 실행 될 수 있는 safe trajectory만 생성하게 된다는 장점이 있다.
- VAE는 다양한 환경(마찰계수)에서 수행된 실제 데이터를 통해 학습되어야 한다.
- MAML (meta learning)
 수식 자체를 이해하면 MAML을 쉽게 이해할 수 있음. 1) Meta policy 에다가 각 task 1,2,3에 대해 gradient update를 수행한 , , 가 있다. 2) 그 각 adapted policy의 loss 총합이 작아지는 방향으로 meta policy를 학습한다. 그리하여 각 task에 가장 적합하도록 학습하는 것이 아니라, 미래 한번 gradient update가 최상의 결과를 불러올 수 있도록, adaptation을 젤 잘하도록 학습을 시키는 것이다.
수식 자체를 이해하면 MAML을 쉽게 이해할 수 있음. 1) Meta policy 에다가 각 task 1,2,3에 대해 gradient update를 수행한 , , 가 있다. 2) 그 각 adapted policy의 loss 총합이 작아지는 방향으로 meta policy를 학습한다. 그리하여 각 task에 가장 적합하도록 학습하는 것이 아니라, 미래 한번 gradient update가 최상의 결과를 불러올 수 있도록, adaptation을 젤 잘하도록 학습을 시키는 것이다.
- Policy simplification (+ latent space modeling)
-
방법론
- Domain adaptation

- Adjust the policy parameters in such a way that the policy's performance will improve for the current dynamic conditions (단 하나의 환경)
- 알고리즘을 보면, input meta policy가 필요하고(이걸 얻는 방법은 Meta training에서 다룰 것임) 단일 환경에 대해 N번 adaptation이 수행됨.
- Meta training ※

- Find the optimal meta paramters which result in fast adaptation to new dynamic conditions (여러 환경에 빠르게 adapt할 수 있는 meta policy 만들기)
- 여기서 말하는 각 task = New environment with different, randomized dynamics
- Trajectory는 randomized dynamic simulated setup(아까 말한 여러 환경!!!)에서 각각 수행됨 사실 이부분 확실하지 않음.... simulation에서 수행된다는 건지 real 환경에서 수행된다는건지... simulation일 것 같긴함.. (The policy is trained in simulation using the simulated setup)
- 참고를 위한 MAML 알고리즘 재첨부

- Domain adaptation
-
코드: 없음
-
참고자료
https://www.youtube.com/watch?v=Xd4f2SJTAQ4&t=1699s
논문 읽었을 때 잘 이해 안가던 부분들도 영상에서 명확하게 집어주고 강조해주셔서 좋았음. 이 논문을 이해하고 싶다면 시청하는 것 추천!
