들어가며
이번 주차는 크게 4주차-1(교육 정리)과 4주차-2(스터디 모임 회고록)에 대해 작성해 보려고 한다. 4주차에서는 AI Agent와 워크플로우 설계 대해 학습을 진행했다. 내용이 광범위하고 다음 주차, 프로젝트를 진행하기 위해서는 크게 복습을 한번 진행하는 것이 중요하다고 생각했기 때문에 주차를 나눠서 글을 작성하려고 한다. 4주차-2에서는 따로 스터디를 진행 중인 공모전/코딩테스트 스터디 모임에 대해 좀 더 이야기를 나눠보려고 한다. 이제 Agent에 내용에 관해 정리해 보자
1. AI Agent와 워크플로우 설계
들어가기 전 AI Agent는
- 모델 정의 (LLM 선택 및 프롬프트 엔지니어링)
- 지식 기반 구축 (RAG 및 벡터 데이터베이스 설정)
- 도구 정의 (외부 API, 웹 검색, 코드 실행 등 Tool 연동)
- 워크플로우 설계 (Planning, Reasoning, Reflection 구조화)
- 실행 및 모니터링 (실시간 대응 및 데이터 관리)
위 AI Agent 구축 사이클을 기억하자
이번 과정에서는 생성형 AI를 단순히 호출하고 답변을 얻는 것을 넘어서, 언어 모델이 스스로 의사를 결정하고 도구를 사용하여 문제를 해결하는 AI Agent를 구축하는 방법을 배우게 되었다. 특히 LangChain과 LangGraph 프레임워크를 활용하여 복잡한 워크플로우를 설계하는 것이 주된 목표다.
1.1 LLM 활용 방식과 LangChain의 역할
대규모 언어 모델(LLM)을 우리의 데이터에 맞게 활용하는 방법은 크게 세 가지로 나눌 수 있다. 첫째는 모델을 그대로 사용하는 것이고, 둘째는 나의 데이터를 추가로 학습시키는 파인튜닝(Fine-Tuning), 그리고 셋째는 외부 지식을 검색하여 프롬프트에 포함시키는 RAG(Retrieval-Augmented Generation) 방식이다. 파인튜닝은 연산 자원과 훈련 시간, 과적합 등의 한계가 존재하기 때문에 최근에는 RAG 기반의 접근이 매우 중요해지고 있다.
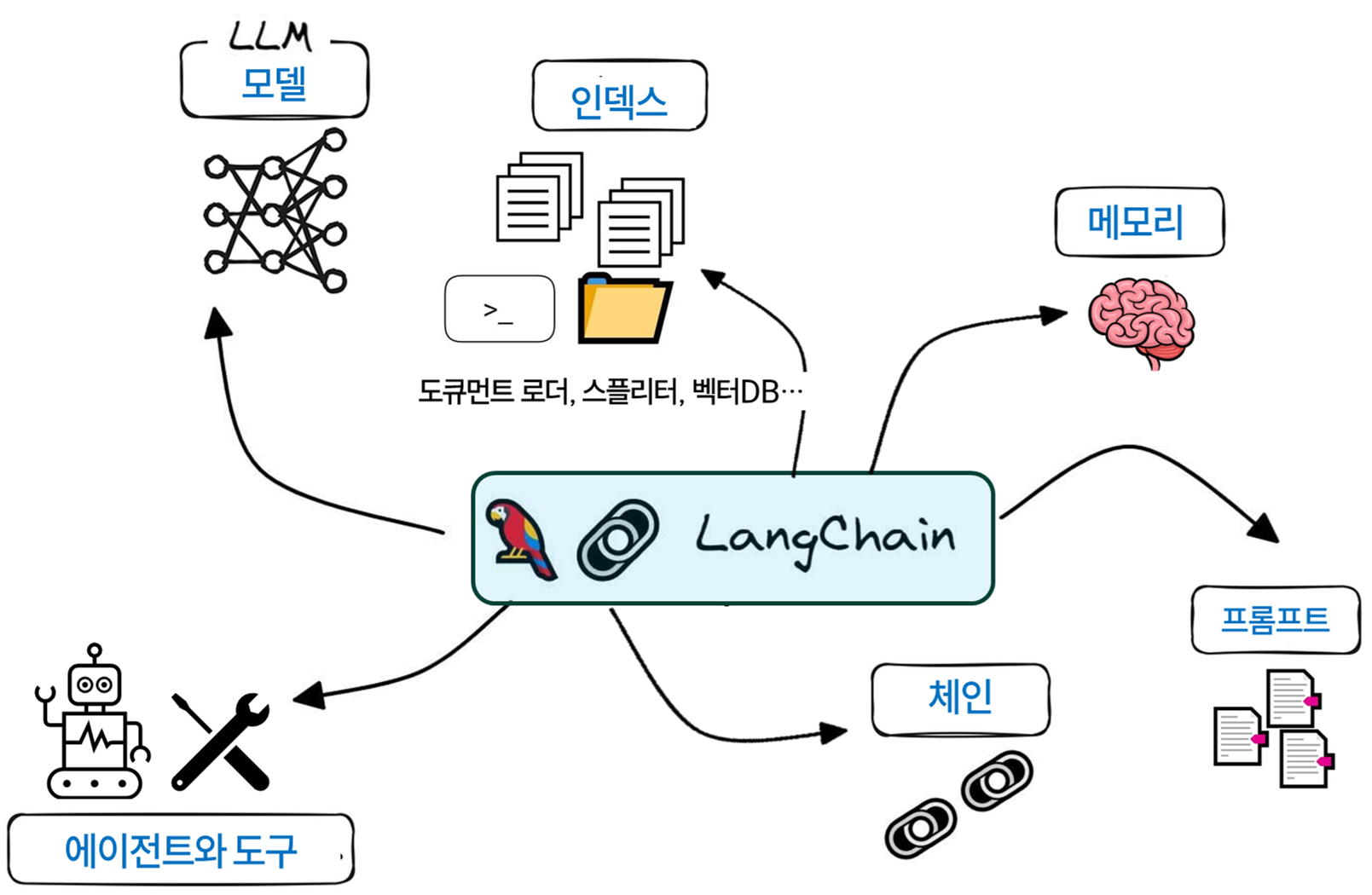
이러한 LLM 기반 애플리케이션을 쉽게 개발하도록 돕는 프레임워크가 바로 LangChain이다. LangChain은 대규모 언어 모델을 활용하여 다양한 컴포넌트들을 체인(Chain)으로 연결해 복잡한 작업을 자동화하도록 돕는다. 주요 구성 요소로는 모델(LLM), 프롬프트, 인덱스(벡터 DB 등), 메모리, 체인, 그리고 에이전트와 도구가 있다.
1.2. 메시지 구성과 프롬프트 엔지니어링
LangChain에서 모델에 입력값을 전달할 때는 단순한 문자열이 아닌, 명확한 역할을 부여한 메시지 객체를 사용한다.
메시지의 종류
- SystemMessage: AI에게 지침이나 역할, 성격을 지정하는 메시지다.
- HumanMessage: 사용자의 질문이나 요청을 담는 메시지다.
- AIMessage: AI가 반환한 응답을 나타낸다.
메시지를 구성할 때는 튜플 방식과 객체 방식을 모두 사용할 수 있다.
| 구분 | 튜플 방식 ("role", "content") | 객체 방식 HumanMessage(content=...) |
|---|---|---|
| 주요 용도 | 유연한 메시지 구성, 프롬프트 템플릿 정의 | 고정된 메시지, 메시지 객체 직접 조작 및 메모리 관리 |
| 장점 | 코드가 간결하고 직관적임 | 객체 지향적이며 엄격한 타입 체크에 유리함 |
이러한 메시지들을 구조화하여 다중 메시지 기반의 흐름을 만드는 것이 ChatPromptTemplate이다. 프롬프트를 설계할 때는 역할(Role), 맥락과 목적(Context & Goal), 답변 형식(Format)을 명확하게 명시하는 프롬프트 엔지니어링이 필수적이다.
1.3. 모델의 답변 무작위성 제어
LLM은 내부적으로 다음 단어가 등장할 확률을 계산하여 텍스트를 생성한다. 이 생성 과정의 다양성과 무작위성을 제어하기 위해 몇 가지 중요한 파라미터를 조절할 수 있다.
- Temperature: 확률 분포 자체를 조절한다. 0에 가까울수록 가장 확률이 높은 단어만 선택하여 일관되고 논리적인 답변을 생성하며, 1 이상으로 높아질수록 낮은 확률의 단어도 선택할 가능성이 생겨 창의적인 답변을 도출한다.
- Top_k: 확률이 가장 높은 상위 K개의 단어만 다음 단어의 후보로 제한하는 방식이다.
- Top_p: 단어들의 누적 확률이 p 이상이 되는 최소 집합을 후보로 삼는다. 예를 들어 0.9로 설정하면, 상위 확률 단어들을 더해 총합이 90%가 되는 순간까지만 후보군에 포함시킨다.
1.4. 파이프라인 구성과 출력 결과 구조화
LangChain의 진정한 강력함은 컴포넌트들을 연결하는 LCEL(LangChain Expression Language)에서 나온다. 파이프(
|) 연산자를 사용하여 데이터가 흐르는 직관적인 파이프라인을 구축할 수 있다.
# LCEL을 이용한 체인 구성 예시
chain = prompt | llm | parser
response = chain.invoke({"user_input": "추천 도서 알려줘"})여기서 마지막에 연결된 parser는 Output Parser(출력 파서)를 의미한다. LLM은 기본적으로 단순한 문자열 텍스트를 반환하지만, 실제 애플리케이션 개발에서는 리스트나 JSON과 같이 구조화된 데이터가 필요한 경우가 많다.
이때 PydanticOutputParser를 활용하면 매우 편리하다. 파이썬의 Pydantic 라이브러리를 통해 우리가 원하는 데이터 스키마(예: 책 제목, 저자, 출판년도)를 명확히 정의하고, 모델이 해당 구조에 맞게 응답하도록 프롬프트 지침을 주입할 수 있다. 또한 반환된 데이터의 타입이 맞는지 자동으로 검증까지 수행해주어 출력의 안정성을 크게 높여준다.
참고/출처
https://docs.langchain.com/
https://brunch.co.kr/@ywkim36/147
https://www.samsungsds.com/kr/insights/what-is-langchain.html
https://aws.amazon.com/ko/what-is/langchain/
https://pangguinland.tistory.com/318
2.RAG 기반 파이프라인 구축
대규모 언어 모델(LLM)은 자신이 학습하지 않은 최신 정보나 내부 비공개 문서에 대해서는 알지 못하며, 잘못된 정보를 사실처럼 말하는 할루시네이션(Hallucination) 문제가 발생하기 쉽다. LLM의 한계를 극복하기 위해 외부 지식을 검색하여 답변의 근거로 활용하는 RAG(Retrieval-Augmented Generation) 기술과 그 파이프라인 구축 과정을 정리!
2.1. RAG 개념의 이해
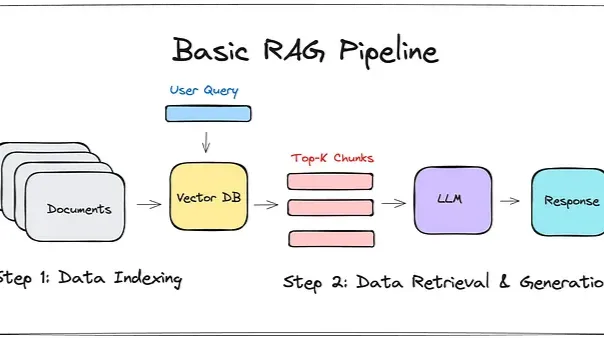
RAG는 쉽게 말해 '검색(Retrieval)'과 '생성(Generation)'을 결합한 기술이다. 사용자가 질문을 던지면 LLM이 바로 답변을 생성하는 것이 아니라, 먼저 준비된 지식 데이터베이스(Vector DB)에서 질문과 관련된 문서(Context)를 검색하여 찾아낸다. 그런 다음 검색된 문서의 내용을 프롬프트에 포함시켜 LLM에게 전달하고, LLM은 주어진 문맥만을 바탕으로 정확한 답변을 생성하게 된다.
이러한 시스템을 구축하기 위해서는 문서를 컴퓨터가 이해하고 검색할 수 있는 형태로 변환하여 저장하는 Vector DB 구축 과정이 선행되어야 한다.
2.2. Vector DB 구축 절차
Vector DB를 만드는 과정은 크게 4가지 단계(Load -> Split -> Embed -> Store)로 이루어진다.
(1) 데이터 불러오기 (Load)
가장 먼저 할 일은 다양한 포맷의 파일로부터 텍스트를 추출하는 것이다. LangChain에서는 Loader라는 도구를 제공하며, 파일 형식에 따라 알맞은 로더를 사용한다. 일반적인 텍스트 파일은 TextLoader, PDF 파일은 PyMuPDFLoader, CSV 파일은 CSVLoader를 사용하여 문서를 읽어 들인다. 로드된 데이터는 텍스트 내용(page_content)과 메타데이터(metadata)를 포함하는 Document 객체 형태로 변환된다.
(2) 텍스트 분할 (Split)
문서를 로드했다고 해서 그대로 LLM에 던져줄 수는 없다. LLM이 한 번에 처리할 수 있는 입력 토큰 수에 제한이 있기 때문이다. 따라서 긴 문서를 의미 있는 작은 단위인 청크(Chunk)로 나누는 작업이 필요한데, 이를 텍스트 분할이라고 한다.
텍스트를 나눌 때는 단순히 글자 수로만 자르면 문맥이 끊어질 수 있으므로, 문단이나 문장 단위를 고려하고 청크 간에 내용이 일부 겹치도록 설정하는 것이 중요하다. LangChain의 CharacterTextSplitter를 사용하면 최대 글자 수(chunk_size)와 겹치는 글자 수(chunk_overlap)를 지정하여 문서를 분할할 수 있다. 적절한 청크 크기(보통 300~800자)와 오버랩을 설정하는 것이 RAG의 검색 품질을 좌우하는 핵심 요소 중 하나다.
(3) 텍스트 벡터화 (Embed)
분할된 텍스트 청크들은 텍스트 자체로는 수학적 검색이 불가능하므로, 이를 숫자로 이루어진 벡터(Vector)로 변환해야 한다. 이 과정을 임베딩(Embedding)이라고 하며, 텍스트의 의미적 정보를 다차원 공간의 좌표로 매핑하는 것이다. OpenAI의 text-embedding-3-small과 같은 모델을 주로 사용하며, 의미가 유사한 텍스트일수록 벡터 공간 상에서 서로 가까운 위치에 놓이게 된다.
(4) 벡터 저장소에 저장 (Store)
마지막으로 임베딩된 벡터 데이터들을 효율적으로 저장하고 검색할 수 있는 데이터베이스에 보관한다. 이를 Vector Store라고 부른다.
2.3. 유사도 검색 원리
Vector DB에 문서가 저장되었다면, 이제 사용자의 질문을 임베딩하여 DB에 저장된 문서 벡터들과 비교할 수 있다. 이때 주로 사용되는 수학적 기준이 코사인 유사도(Cosine Similarity)다.
코사인 유사도는 두 벡터가 이루는 각도를 계산하여 텍스트 간의 의미적 유사성을 측정한다. 값이 1에 가까울수록 문맥적 의미가 매우 유사함을 뜻하며, 0이면 관계가 없고, -1이면 반대 의미를 가짐을 나타낸다. 시스템은 질문 벡터와 코사인 유사도가 가장 높은 상위 K개의 문서를 추출하여 응답의 근거로 사용한다.
2.4. RAG 파이프라인(Chain) 구성
지식 DB 준비가 끝났다면, 사용자의 질문을 받아 검색하고 답변을 생성하는 전체 파이프라인을 LCEL 문법으로 엮어주어야 한다.
1단계: Retriever 선언
Vector DB를 검색기(Retriever)로 변환한다. .as_retriever() 함수를 사용하며, 코사인 유사도를 기준으로 상위 몇 개(k)의 문서를 가져올지 설정한다.
2단계: RAG 전용 프롬프트 정의
LLM이 외부 지식을 활용해 답변하도록 역할을 고정하고, 제공된 문맥(Context) 내에서만 답하도록 프롬프트를 설계한다. 특히 "제공된 문맥에 답이 없다면 모른다고 답변하고 억지로 지어내지 마라"는 조건을 명시하여 할루시네이션을 방지한다.
3단계: LCEL 체인 연결
입력된 질문이 Retriever를 통과해 관련 문서(Context)를 찾아오고, 이 문맥과 원본 질문이 프롬프트 템플릿에 삽입된 후 LLM을 거쳐 최종 답변이 나오는 체인을 구성한다.
# 문서 객체 리스트를 하나의 문자열로 결합하는 포맷 함수
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# LCEL 기반 RAG 파이프라인 구성
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
)
# 챗봇 실행
response = rag_chain.invoke("가장 심각한 사이버 보안 위험이 뭐야?")2.5. RAG 성능 최적화 고려 사항
RAG 파이프라인이 제대로 동작하더라도 검색 품질이나 생성 결과가 아쉬울 수 있다. 이를 개선하기 위해 다음과 같은 요소들을 튜닝해야 한다.
-
청크 전략: 문서의 특성에 맞춰 chunk_size와 chunk_overlap을 조정한다. 청크가 너무 작으면 문맥이 잘리고, 너무 크면 여러 주제가 섞여 유사도 검색 성능이 떨어진다.
-
검색 개수(k): LLM의 입력 토큰 한계를 넘지 않는 선에서 충분한 문맥을 제공하기 위해 최적의 k값을 찾는다 (보통 3~5개).
-
프롬프트 고도화: 출력의 제약(길이, 형식 등)을 프롬프트에 구체적으로 명시할수록 응답의 일관성이 향상된다.
참고/출처
https://m.blog.naver.com/rainbow-brain/224072340830
https://kr.linkedin.com/pulse/unlocking-power-rag-pipelines-enhancing-ai-real-time-data-zaveri--lmzif?tl=ko
https://m.blog.naver.com/rainbow-brain/224040868079
3. AI Agent - LangGraph
모델이 단순히 주어진 질문에 대답하는 것을 넘어서, 주어진 목표를 달성하기 위해 스스로 계획을 세우고 도구를 활용하며 문제를 해결하도록 만들 수는 없을까? 능동적인 문제 해결 시스템인 AI Agent의 개념과, 이 에이전트의 복잡한 작업 흐름을 통제하기 위한 LangGraph의 정리!
3.1. AI Agent란 무엇인가?
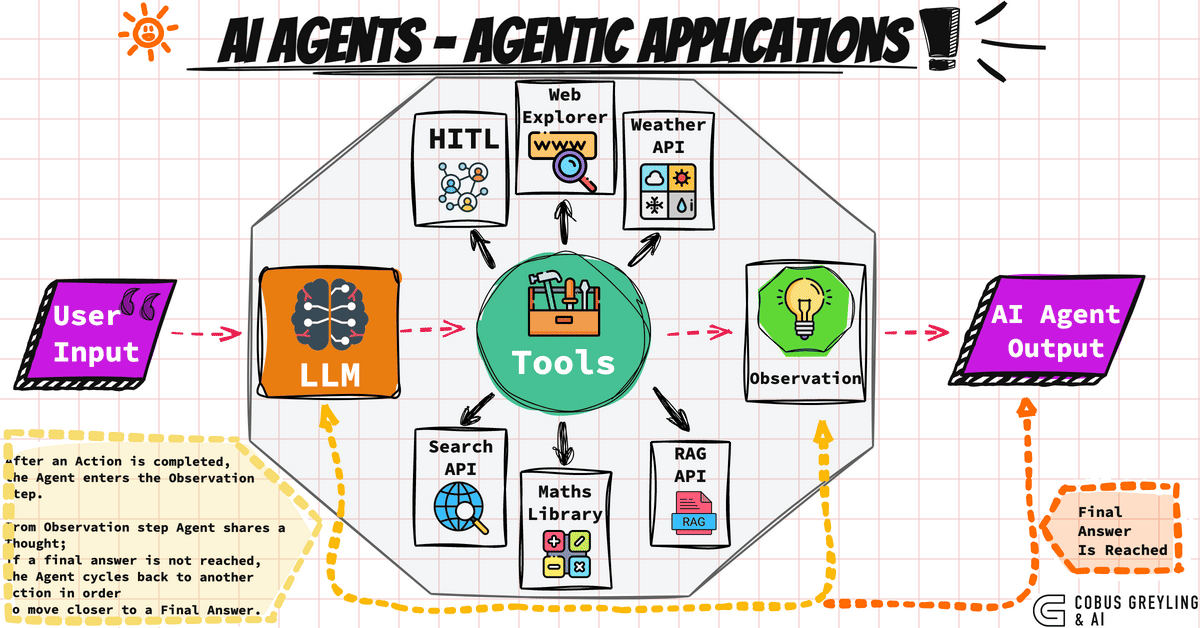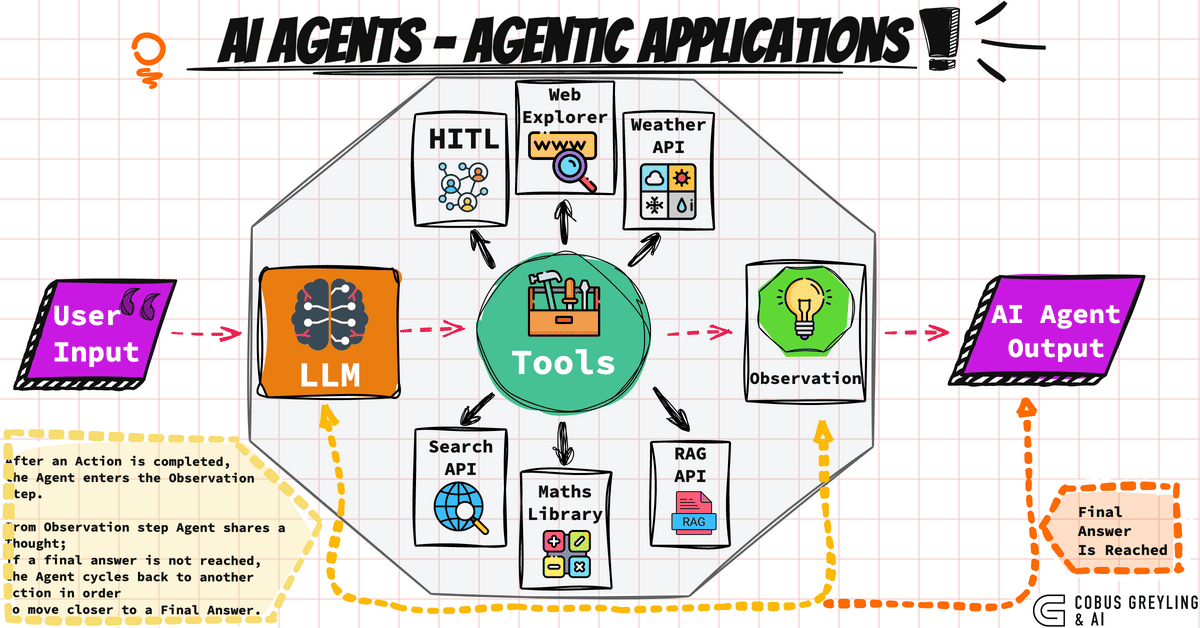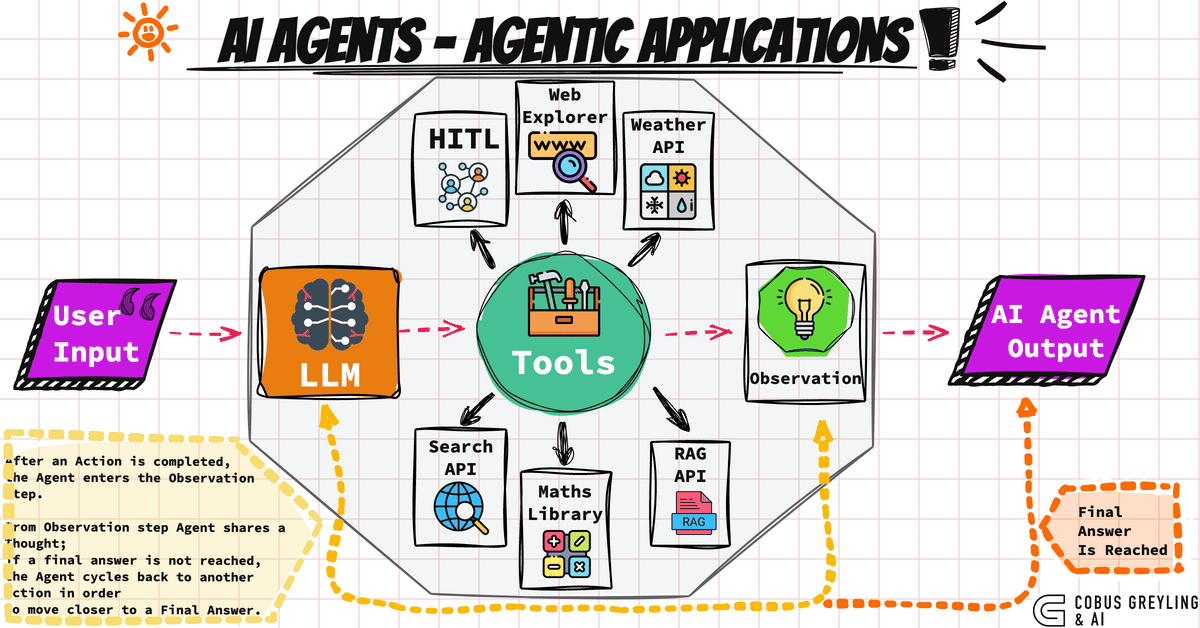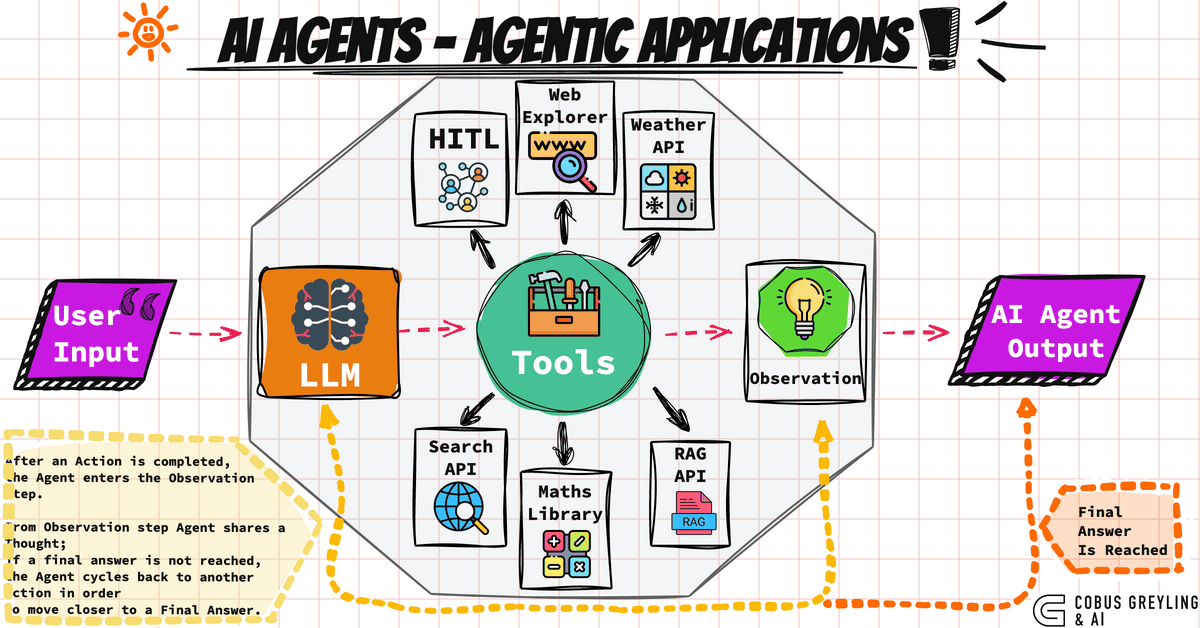
AI Agent는 스스로 의사를 결정하며, 도구를 사용하여 목표를 달성하는 시스템이다. 단순한 텍스트 생성을 넘어, 다단계 추론과 외부 도구 호출 능력을 결합한 것이 특징이다. 즉, 언어 모델(LLM)에 손과 발, 그리고 기억력을 달아주어 하나의 독립적인 작업자로 만드는 과정이라고 이해할 수 있다.
AI Agent는 크게 네 가지 핵심 요소로 구성된다.
- 첫째, 시스템이 최종적으로 해결해야 할 목표(Goal)다.
- 둘째, 이 목표를 달성하기 위해 계획을 세우고 판단을 내리는 두뇌 역할의 추론 엔진(Reasoning Engine)이며 주로 GPT 같은 LLM이 담당한다.
- 셋째, 웹 검색, 계산기, 사내 API 등 에이전트가 호출하여 사용할 수 있는 외부 기능인 도구(Toolset)다.
- 넷째, 이전의 대화나 수집한 정보, 현재의 진행 상황을 저장하고 추적하는 공간인 메모리와 상태(Memory/State)다.
3.2. 워크플로우 제어를 위한 LangGraph
이러한 Agent 시스템을 구축하기 위한 프레임워크로는 여러 가지가 있지만, 복잡한 다단계 프로세스를 개발자가 원하는 대로 세밀하게 제어하기 위해 LangGraph를 활용한다. LangGraph는 에이전트의 작업 흐름을 그래프(Graph) 구조로 설계할 수 있게 해준다.
LangGraph를 구성하는 핵심 요소는 다음과 같다.
- State (상태): 그래프 전체를 관통하며 현재 상태 값을 저장하고 전달하는 역할을 한다. 에이전트가 통과하는 각 단계마다 정보가 누적되며, 파이썬의
TypedDict를 사용하여 어떤 데이터가 들어갈지 딕셔너리 형태로 명확히 구조를 정의한다. - Node (노드): 특정 작업이나 판단을 수행하는 실제 단위다. 파이썬 함수로 구현되며, 상태(State)를 입력으로 받아 특정 작업을 수행한 후 업데이트된 상태를 반환한다.
- Edge (엣지): 노드와 노드를 연결하는 선으로, 작업의 흐름을 정의한다. 한 노드의 작업이 완료된 후 다음으로 이동할 노드를 지정한다.
- Conditional Edge (조건부 엣지): 단순한 순차적 이동이 아니라, 특정 조건이나 상태 값에 따라 노드 간의 분기 처리를 수행할 때 사용한다.
3.3. 에이전트 워크플로우의 세 가지 기본 패턴
상태와 노드, 엣지를 조합하면 다양한 형태의 워크플로우를 설계할 수 있다. (세 가지 그래프 구조를 학습)
(1) 단순 그래프 (Simple Graph)
입력, 처리, 출력으로 이어지는 단순한 파이프라인 형태다. 가장 기본적인 구조로, 시작점(START)에서 출발해 정의된 노드들을 차례대로 거친 후 종료점(END)에 도달한다.
(2) 라우팅 (Routing)
사용자의 입력이나 특정 조건에 따라 서로 다른 경로를 선택하여 실행 흐름을 제어하는 구조다. 이때 조건부 엣지(Conditional Edge)가 핵심적인 역할을 한다.
강의에서는 입력된 숫자가 짝수인지 홀수인지 판별하여 각각 다른 노드를 실행하는 예제를 다루었다. 짝수/홀수 판별 함수를 먼저 만들고, 이를 조건부 엣지에 연결하여 흐름을 동적으로 분기시키는 방식이다.
# 조건 분기를 결정하는 라우터 함수
def parity_condition(state: State):
return "even" if state["number"] % 2 == 0 else "odd"
# 조건부 엣지 추가 (check_parity 노드 실행 후 분기)
builder.add_conditional_edges(
"check_parity",
parity_condition,
{"even": "even_node", "odd": "odd_node"}
)(3) 반추 (Reflection)
에이전트가 스스로의 추론 과정이나 결과물을 돌아보고 피드백을 생성하여, 결과가 만족스러울 때까지 반복 작업을 수행하는 메커니즘이다. 그래프 상에서 특정 노드에서 종료로 가지 않고 다시 이전 노드로 돌아가는 루프(Loop)를 형성하여 구현한다.
예를 들어, 문서를 요약하는 노드를 거친 후 결과의 만족도를 평가한다. 평가 결과가 '만족'이면 시스템을 종료하지만, '불만족'이면 다시 생각해보기(반추) 노드를 거쳐 원래의 요약 노드로 되돌아간다. 이러한 순환 구조를 통해 에이전트는 한 번에 완벽한 답을 내지 못하더라도, 점진적으로 결과물의 품질을 향상시킬 수 있다.
참고/출처
https://wikidocs.net/268610
https://cobusgreyling.medium.com/whats-your-definition-of-an-ai-agent-edb7d5e1c760
https://www.langchain.com/langgraph
4. AI Agent와 Tool 활용
도구(Tool) 활용법과, 과거의 대화를 기억하며 도구를 능동적으로 사용하는 실질적인 챗봇 에이전트 구축 과정을 정리!
4.1. AI Agent와 Tool의 역할
일반적인 대규모 언어 모델은 사용자의 입력을 받아 단순히 텍스트 응답을 생성한다. 하지만 실제 업무에서는 실시간 웹 검색이 필요하거나, 정확한 수학 계산을 해야 하거나, 사내 데이터베이스를 조회해야 하는 등 외부 시스템과의 상호작용이 필수적이다.
이러한 외부 기능들을 에이전트가 사용할 수 있도록 묶어놓은 것을 Tool(도구)이라고 부른다. 모델은 사용자의 질문을 분석한 뒤, 스스로 판단하여 필요한 시점에 적절한 도구를 호출(Tool Call)하고 그 결과를 바탕으로 최종 응답을 만들어낸다.
도구는 크게 두 가지로 나뉜다.
- Custom Tool: 우리가 필요에 따라 파이썬 함수로 직접 정의하고 만든 도구다.
- 외부 도구: 검색 엔진(Tavily 등), 날씨 API 등 외부 업체에서 미리 만들어 제공하는 도구다.
4.2. 메모리를 가진 대화형 챗봇 만들기 (State 관리)
도구를 사용하는 복잡한 에이전트를 만들기 전, 먼저 에이전트가 과거의 대화를 기억하게 만들어야 한다. LangGraph에서는 이를 State를 통해 관리한다.
단순히 텍스트 하나만 주고받는 것이 아니라, 대화 기록 전체를 리스트 형태로 State에 담아 관리해야 문맥이 유지된다. 이때 매번 기존 리스트를 덮어쓰는 것이 아니라 새로운 메시지를 계속 누적해서 추가(Append)해야 하는데, LangGraph는 이를 아주 쉽게 구현할 수 있도록 add_messages라는 기능을 제공한다.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
# 대화 이력을 자동으로 누적해서 관리하는 State 구조
class State(TypedDict):
messages: Annotated[list, add_messages]
이렇게 Annotated와 add_messages를 활용해 State를 정의하면, 새로운 메시지가 반환될 때마다 프레임워크가 알아서 기존 메시지 목록의 맨 뒤에 새 메시지를 추가해 준다. 이를 통해 모델은 항상 전체 대화 히스토리를 보며 자연스러운 맥락을 이어갈 수 있다.
4.3. Custom Tool 만들기 및 모델에 연결하기
에이전트에게 쥐어줄 도구를 만드는 방법은 매우 간단하다. 일반적인 파이썬 함수를 작성한 뒤, 그 위에 @tool 데코레이터만 붙여주면 LangChain이 인식할 수 있는 도구로 변환된다. 이때 함수 내부의 매개변수 타입과 독스트링을 명확히 적어주는 것이 중요한데, 모델이 이 설명을 읽고 언제 어떻게 이 도구를 써야 할지 결정하기 때문이다.
from langchain_core.tools import tool
# 계산기 도구 정의
@tool
def calculator_tool(expression: str) -> str:
"""수학 수식을 입력받아 계산 결과를 반환합니다."""
return str(eval(expression))
# 1. 사용할 도구들을 리스트로 묶기
tools = [calculator_tool]
# 2. LLM에 도구 목록 연결 (Binding)
llm_with_tools = llm.bind_tools(tools)가장 핵심적인 부분은 만든 도구들을 리스트로 묶어 LLM에 바인딩하는 것이다. 이 과정을 거쳐야만 LLM이 자신에게 어떤 무기들이 주어졌는지 인지하고, 필요할 때 함수 실행을 요청할 수 있다.
4.4. Tool을 사용하는 Agent 워크플로우 구성
이제 모델과 도구를 LangGraph의 노드와 엣지로 엮어 실제 에이전트의 워크플로우를 구성할 차례다. 도구를 사용하는 에이전트의 흐름은 대체로 다음과 같은 순환 구조를 가진다.
사용자 입력: 사용자가 질문을 던진다.
모델 판단 (call_model 노드): LLM이 질문을 분석한다. 만약 도구 사용이 필요 없다면 바로 최종 답변을 생성하고 종료(END)한다.
도구 호출 요청: 도구가 필요하다고 판단되면, LLM은 응답 텍스트 대신 "이 도구를 이런 매개변수로 실행해줘"라는 Tool Call 명령을 내뱉는다.
조건부 분기: 조건부 엣지가 모델의 응답을 확인하여 Tool Call이 포함되어 있다면 흐름을 도구 실행 노드로 보낸다.
도구 실행 (tools 노드): ToolNode가 실제 파이썬 함수를 실행하고 그 결과값을 State의 messages에 추가한다.
결과 피드백: 흐름은 다시 모델 판단 노드(call_model)로 돌아간다. LLM은 방금 실행된 도구의 결과값을 확인하고, 이를 바탕으로 최종 답변을 정리하여 사용자에게 전달한다.이러한 과정을 통해 에이전트는 한 번에 답을 내기 어려운 복잡한 문제도 스스로 도구를 여러 번 호출해가며 해결책을 찾기
생각정리
Agent에 대한 공부는 처음이 아니었지만, 이번에는 이전보다 훨씬 깊이 있게 개념을 탐색하고 정리할 수 있었던 시간이었다. 단순히 겉핥기식으로 이해하는 것이 아니라, 직접 검색하고 구조를 파악하면서 개념을 보다 명확하게 이해할 수 있었다는 점에서 의미가 크다.
과거에는 Agent를 학습할 때 GitHub에서 스타가 많은 레포지토리를 중심으로 글을 읽고, 코드를 클론하여 실행해보는 방식에 집중했었다. 또한 실제 프로젝트에 Agent가 필요한지, 필요하다면 어떻게 적용할 수 있을지에 대한 고민보다는 구현 자체에 초점을 맞췄던 것 같다. 일종의 ‘바이브 코딩’에 가까운 접근이었다.
하지만 이번 학습을 통해 Agent의 전체적인 구조와 동작 방식, 그리고 실제로 어떻게 활용해야 하는지에 대해 한 단계 더 깊이 이해할 수 있었다. 단순히 사용하는 것을 넘어서, 어떤 상황에서 적절하게 적용할 수 있는지를 고민하게 되었다는 점이 가장 큰 변화다.
최근에는 다양한 Agent들이 등장하고 있고, 나 역시 GitHub Copilot, Cursor, Codex, Claw-Code 등 여러 도구의 도움을 많이 받고 있다. 이러한 흐름 속에서 Agent를 단순한 도구로 사용하는 것을 넘어, 나에게 가장 잘 맞는 형태로 어떻게 활용할 수 있을지 고민하는 것이 중요하다고 느꼈다.
이번 학습은 단순한 개념 이해를 넘어서, 앞으로 내가 진행할 프로젝트에 Agent를 왜 필요할지, 어떻게 활용하면 좋을지, 왜 화두가 되고 모두가 편리하게 사용하는지에 관한 생각을 하게했던거 같다. 4주차 공부를 마무리한다.
결국 차이를 만드는 것은 도구가 아니라, 그것을 바라보는 관점이다
Github-Private
