
✏️ 실전 머신러닝 기초 공부자료
👀 CNN(Convolutional Neural Networks)
👓 CNN(합성곱 신경망)이란?
뉴럴 네트워크(딥러닝)에 합성곱을 섞은 것
일정한 크기의 필터가 존재하는데 입력 데이터 곱하기 필터를 해서 특수한 형태의 데이터 출력값을 만듦
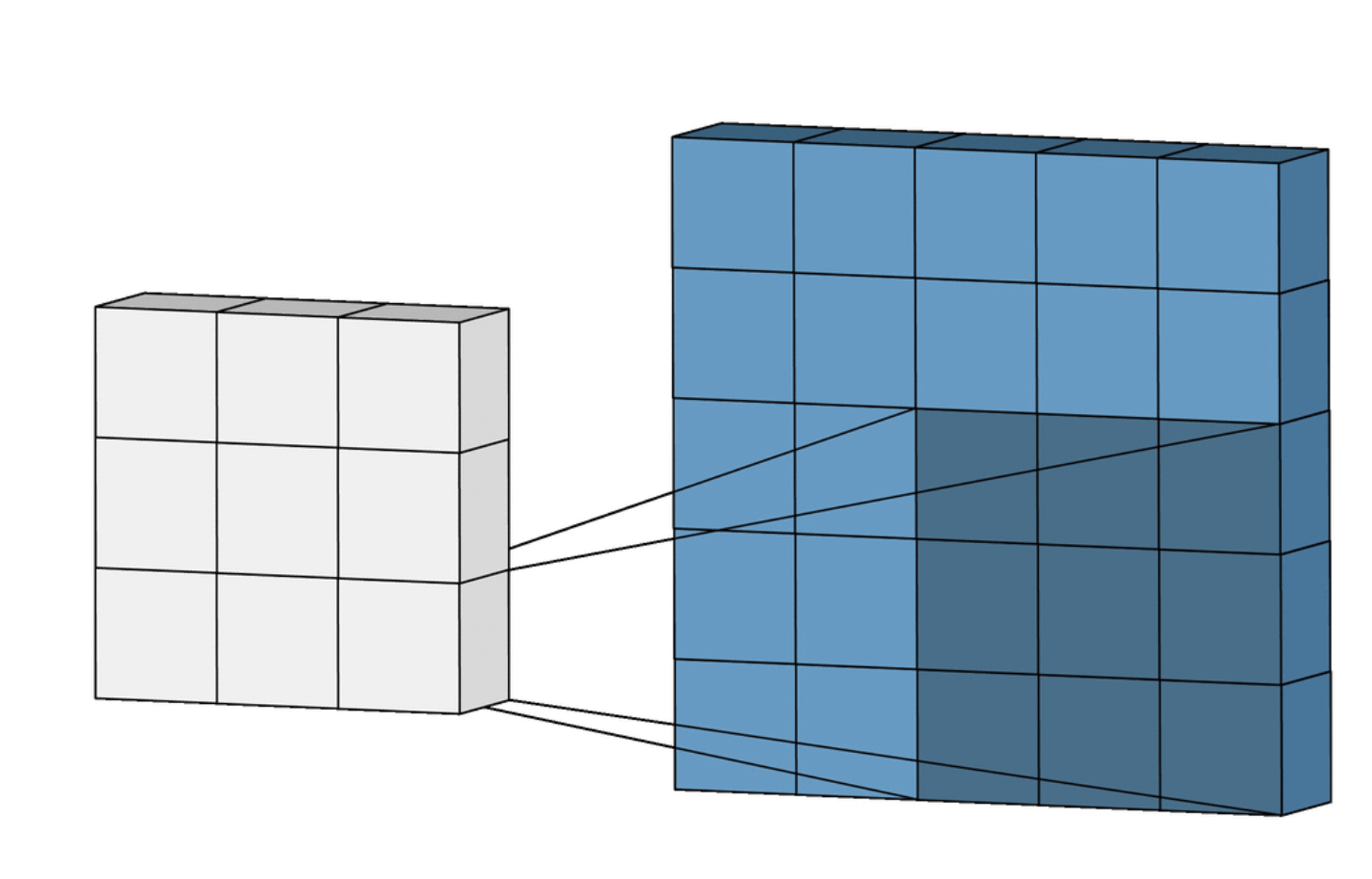
입력 데이터의 특정 부분을 필터 크기만큼 잘라 element wise 사용
- 같은 위치에 있는 요소 끼리 곱하기
- 곱한 수를 전부 더하기
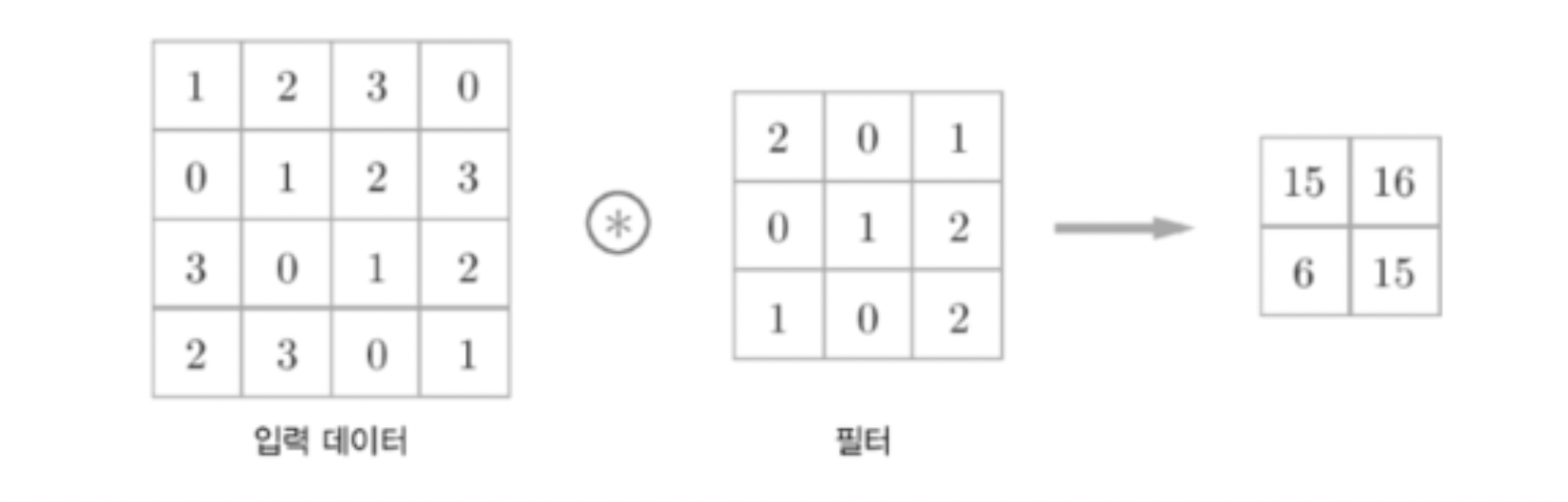
💡 입력 데이터가 필터와 빠짐없이 합성곱을 진행해야 함. 진행한 만큼 출력 값의 크기도 달라지게 됨
- 44의 입력데이터와 33의 필터를 합성곱하면 2*2의 출력데이터가 나옴
Filter(or Kernal)가 움직이는 한 칸 단위를 스트라이드(Stride) 라고 함
꼭 맞게 진행하기도 하지만, 넉넉하게 여백(margin, padding)을 주는 것으로 인풋과 아웃풋의 크기를 맞춰줄 수도 있다.
🗣 이미지는 색상값까지 3개 값, 3차원의 입력 값을 갖는다.
필터를 여러 개를 사용하면 여러 겹으로 출력되는 향상된 성능의 결과를 얻을 수 있다.
👀 CNN 구성
📌 레이어
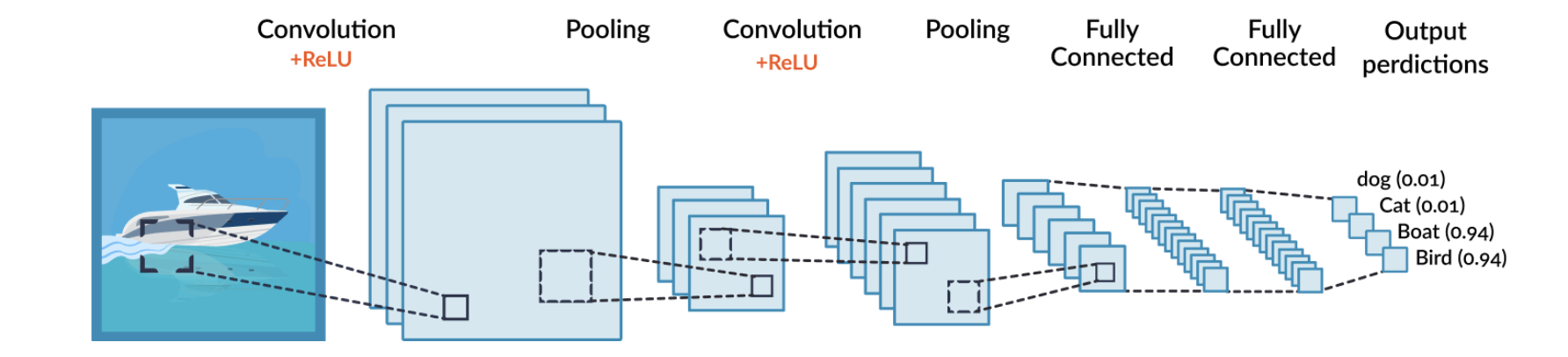
CNN은 합성곱(Convolution)레이어와 완전연결(Dense)레이어를 함께 사용한다
ReLU를 사용해 MLP로 학습하고, 필터를 통해 값을 Pooling으로 빼내며, 다시 ReLU-Pooling을 반복한 뒤 Dense Layer로 일렬로 쭉 세워 마지막 결과 값을 예측하게 되는 순서로 구성되어 있다.
🎯 평탄화 계층(Flatten Layer)
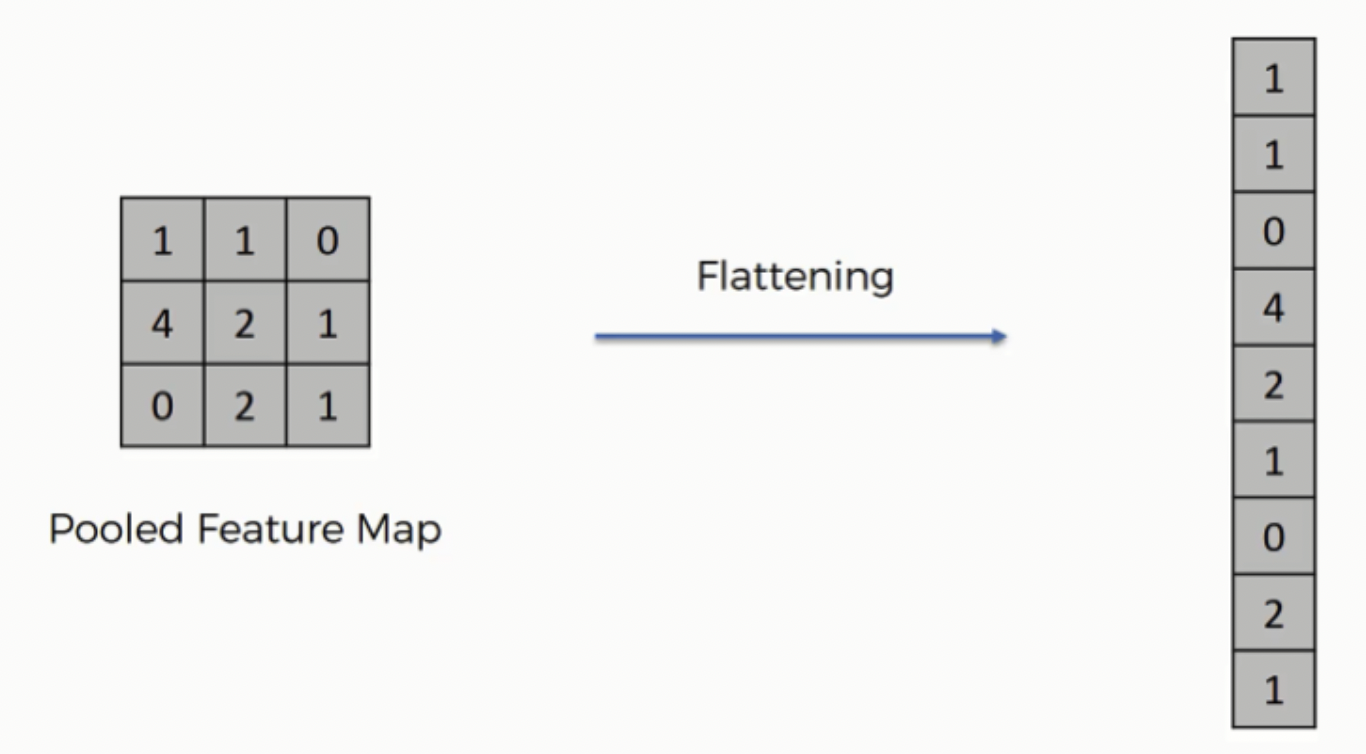
- Pooling 레이어는 2차원으로 구성되어 있고, 완전연결(Dense) 레이어는 1차원이기 때문에 1차원으로 바꿔주는 작업이 필요하다
🎯 Max-Pooling
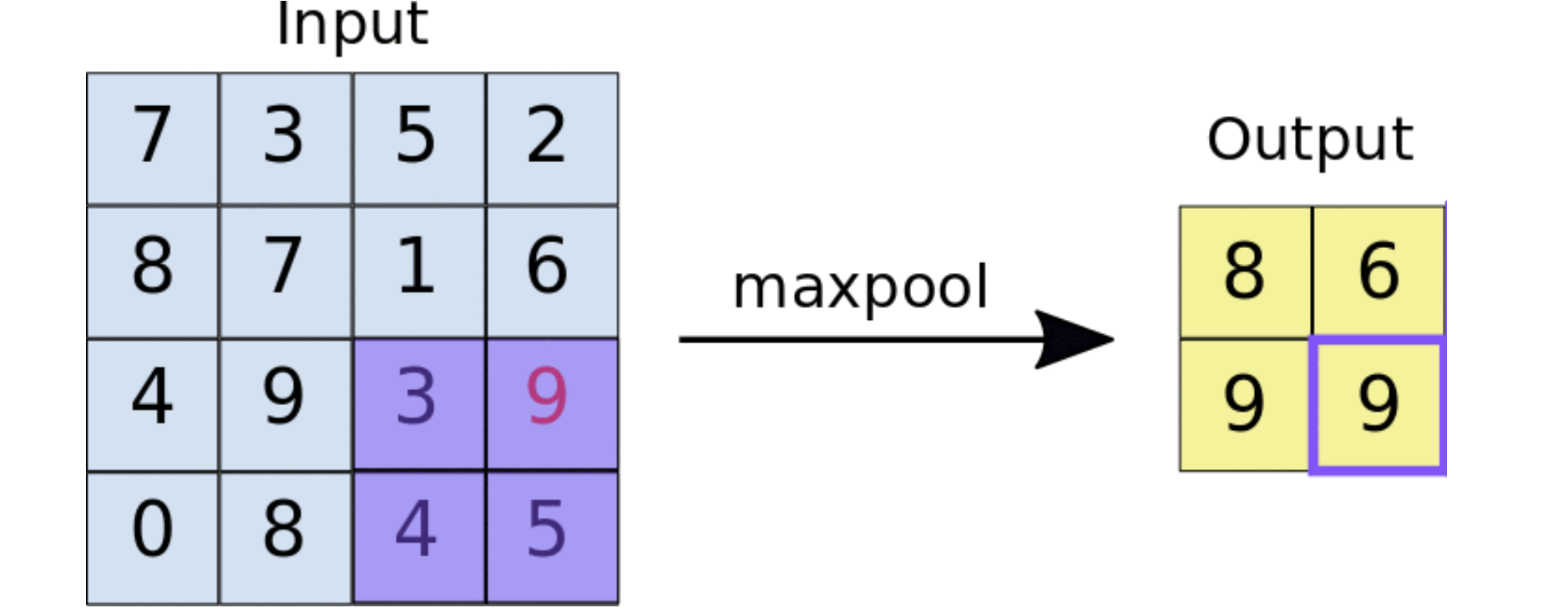
예시는 스트라이드 2로 설정된 인풋데이터의 최댓값을 출력하는 풀링
🎯 Average-Pooling
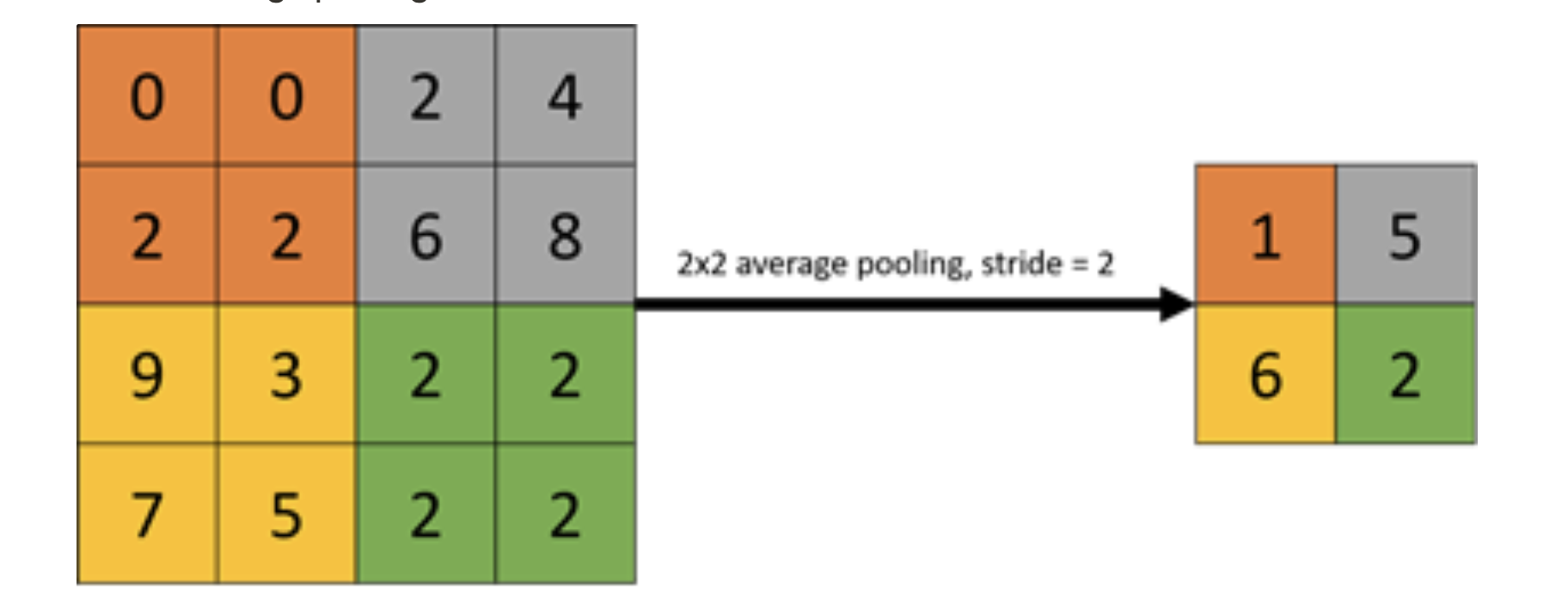
예시는 스트라이드 2로 설정된 인풋데이터의 평균값을 출력하는 풀링
📌 물체 인식 (Object Detection)
사진 이미지에서 정확히 물체를 인식하는 기술
스마트폰 셀피 얼굴 인식
YOLO(You Only Look Once) 모델을 사용한다
📌 이미지 분할 (Segmentation)
💡 물체인식은 이미지를 사각형의 형태로 포착하는데, 세그멘테이션은 이미지의 윤곽선을 따서 포착한다
인물 사진 모드에서 사람은 선명하게, 배경은 흐릿하게 하는 기능 -> 사람 부분을 세그멘테이션 해서 진행한 효과
의료분야에서 특정 부위 강조 효과
자율주행에서 물체인식 및 세그멘테이션을 사용함
📌 자세 인식 (Post Detection)
사람의 자세를 단순화된 직선의 형태로 움직임을 포착
게임 저스트 댄스에서 활용됨
📌 화질 개선 (Super Resolution)
저화질의 이미지를 고화질로 개선
📌 Style Transfer
이미지를 특정 화풍으로 변경
📌 Colorization
사진의 색을 복원하는 기능
오브젝트 디텍션이 선수행되어야 함
👀 CNN의 종류
AlexNet
첫번째 CNN
Dropout과 Image augmentation 사용
VGGNet
모델의 깊이가 굉장히 깊음
가장 먼저 테스트 해보는 관례 수준의 사용성
GoogLeNet(=Inception V3)
다양한 종류의 풀링, 필터를 사용해서 Inception Module을 사용함
깊어진 신경망과 적어진 파라미터로 효율성 증대
👀### ResNet
VGGNet, GoogLeNet에서 발생하는 문제를 ResNet에서 Residual block을 사용하여 Gradient Vanishing(테스트에서 오류가 트레이닝에 비해 덜 줄어듦)을 해소할 수 있도록 제안함
👀 전이 학습 (Transfer Learning)
📌 전이학습이란?
인간이 학습한 방법을 모사한 것으로, 과거에 문제를 해결하면서 축적된 경험을 토대로 유사한 문제를 해결할 수 있도록 신경망을 학습시키는 방법
👀 순환신경망 RNN (Recurrent Neural Network)
📌 RNN이란?
자연어처리에 사용됨
번역 모델을 만들 때 사용한 것으로 유명
소설쓰기, 챗봇, 가상화폐 시장 예측 등에도 사용됨
👀 생성적 적대 신경망 GAN (Generative Adversarial Network)
💡 서로 적대하는 관계의 2가지 모델을 동시에 사용함
굉장히 유행하고 있는 모델
생성모델과 판별모델이 동시에 학습을 해서 위조지폐와 같은 이미지를 만든다고 가정했을 때, 진짜 같은 위조지폐를 만들 수 있게 되는 긍정적 결과를 도출한다
에폭을 진행할 수록 정교한 이미지를 만들어냄
딥페이크로 유명함
👀 CNN 실습
✏️ 패키지 로드
Convolution 레이어, Dense 레이어, 맥스풀링, 평탄화 레이어, 드롭아웃 임포팅
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout이미지 증강을 위한 라이브러리 임포트
from tensorflow.keras.preprocessing.image import ImageDataGenerator🪄 전처리
X 데이터를 (28,28,1(그레이스케일)) 크기의 이미지 형태로 변환
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values
x_train = x_train.reshape((-1, 28, 28, 1))
y_train = train_df[['label']].values
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
x_test = x_test.reshape((-1, 28, 28, 1))
y_test = test_df[['label']].values
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)ImageDataGenerator()를 사용해서 일반화
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
)
test_image_datagen = ImageDataGenerator(
rescale=1./255
)학습 효과를 높이기 위한 트레인셋의 배치 사이즈를 설정 및 데이터 셔플
train_datagen = train_image_datagen.flow(
x=x_train,
y=y_train,
batch_size=256,
shuffle=True
)test_datagen = test_image_datagen.flow(
x=x_test,
y=y_test,
batch_size=256,
shuffle=False
)데이터제너레이터에 인덱스 값으로 이미지와 라벨링 선언
이미지사이즈로 리쉐이프해서 보여주기
매번 실행할 때마다 트레인셋의 섞인 데이터를 보여주기 때문에 이미지가 달라짐
index = 1
preview_img = train_datagen.__getitem__(0)[0][index]
preview_label = train_datagen.__getitem__(0)[1][index]
plt.imshow(preview_img.reshape((28, 28)))
plt.title(str(preview_label))
plt.show()🌟네트워크 구성
CNN의 핵심부분. 어려우니 확실하게 보고 넘어가자
인풋데이터->Convolution->Pooling->Convolution->Pooling
1. 인풋데이터 사이즈 쉐이핑
2. 필터 사이즈 33, 스트라이드 1, 패딩을 입출력이 같도록 설정, ReLU 함수로 모델링, 인풋 넣기
3. 풀링 데이터 사이즈 22, 스트라이드 2
input = Input(shape=(28, 28, 1))
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)2차원 레이어 1차원으로 평탄화->완전연결 레이어 컴파일
1. 레이어 평탄화
2. 덴스 레이어로 ReLU 모델링
3. 드롭아웃으로 겹치는 데이터 제거 -> 학습효율 증가
4. 소프트맥스 함수로 다항 논리 회귀 결과 도출
5. 모델에 인풋, 아웃풋 넣기
6. 카테고리컬 크로스엔트로피로 모델 컴파일
7. 모델 요약해서 보기
input = Input(shape=(28, 28, 1))
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Flatten()(hidden)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dropout(rate=0.3)(hidden)
output = Dense(24, activation='softmax')(hidden)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()👀 이미지 증강
이미지 변형으로 데이터 증강하기
트레인셋의 학습을 높여주기 위함이므로 트레인셋 이미지에 적용
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 랜덤하게 이미지를 수직으로 이동 (%)
)폴더에서 직접 가져오기
라벨이 여러 개면 카테고리컬, 이진 분류는 바이너리
train_gen = train_datagen.flow_from_directory(
'fruits-360/Training',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=True
)👀 전이학습 실습
