Distributed system
1.Time and clocks in Distributed System

Distributed system is Partial failure + unbounded latencyfor both, we have zero control over it. To deal with the problem, "time" and "clocks" are sug
2.Causality and happens-before
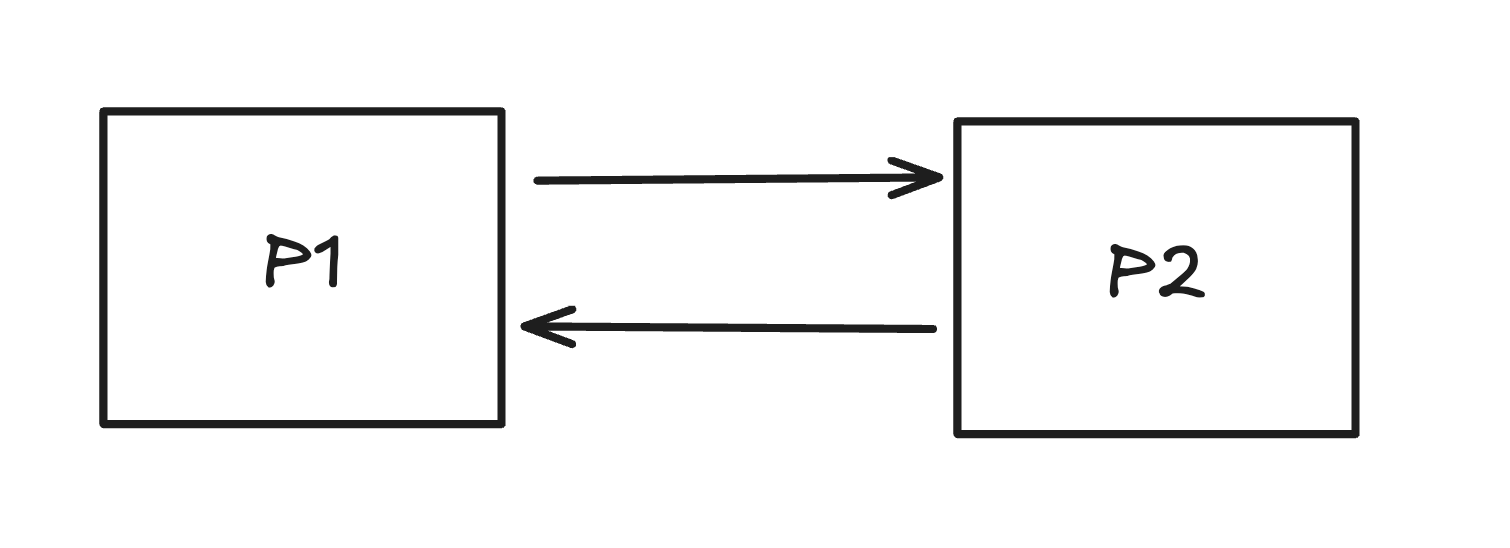
When we draw events that happen in two processes, we don't know what event causes one another in what time. The diaram like the following seems benign
3.Logical clocks(1) - Lamport clocks

In the previous post, we discussed why we shouldn't use physical clock in distributed system. In this post, I'll be talking about number of logical cl
4.Logical clocks(2) - Vector clocks
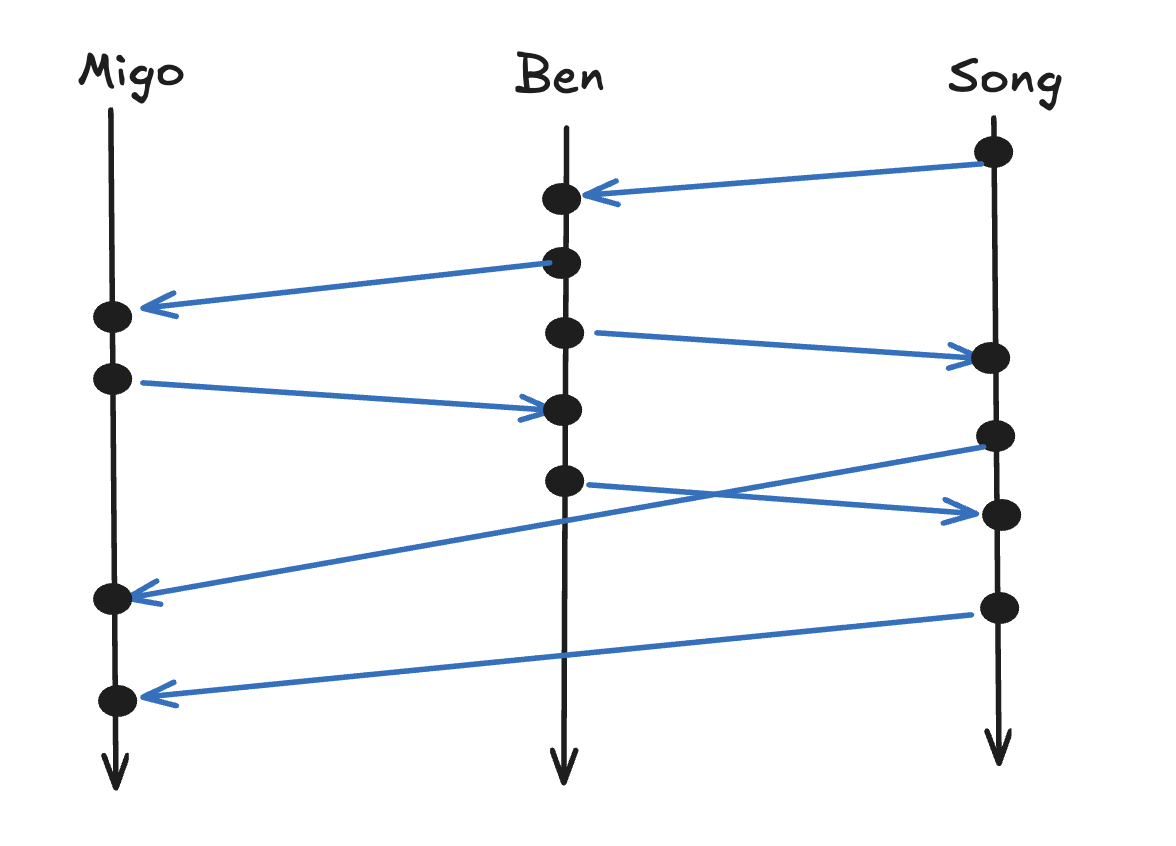
In the previous post, The very first kind of logical clock - Lamport clock - was covered.In this post, vector clock follows. If A -> B, then Lc(A) <
5.Delivery guarantees(1) - definition
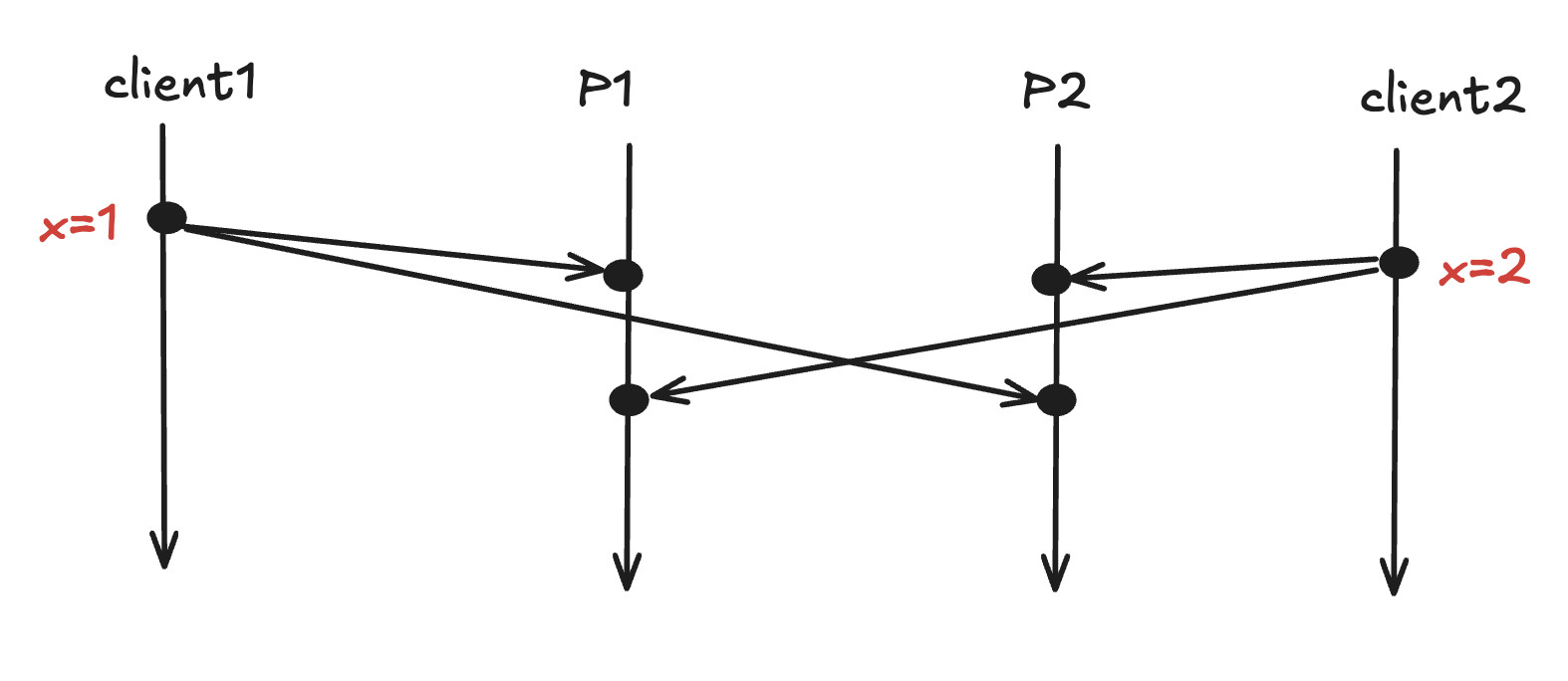
FIFO delivery > If a process sends a message(m1) after m1, then any process delivering both messages must deliver m1 first and m2. Violation of FIFO
6.Delivery guarantees(2) - FIFO and Causal delivery implementation
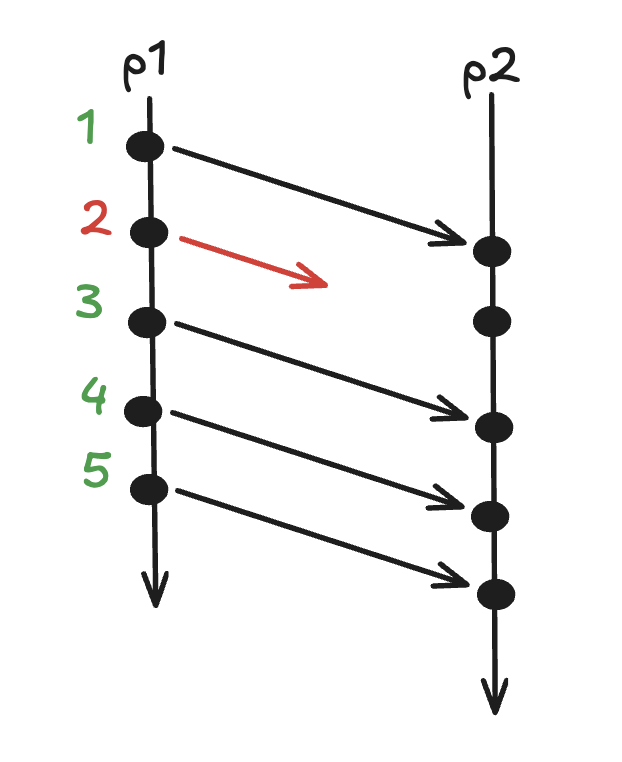
Read this post first if you haven't already. If a process sends message m2 after message m1, then any process delivering both must deliver m1 first. M
7.Delivery guarantee(3) - Causal Broadcast
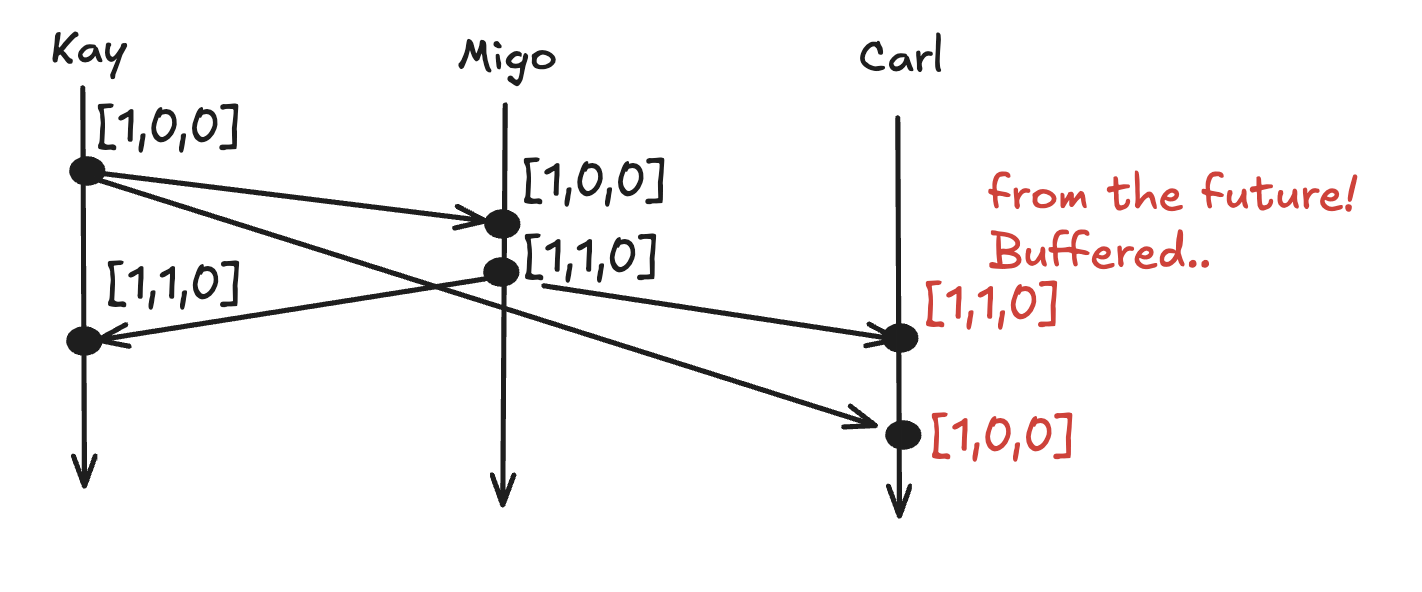
From the last post, we learned how to prevent causal anomaly using vector clock: So, here the message with vector clock \[1,1,0] received on Carl's s
8.Chandy-Lamport Algorithm(1) - Consistent global snapshots
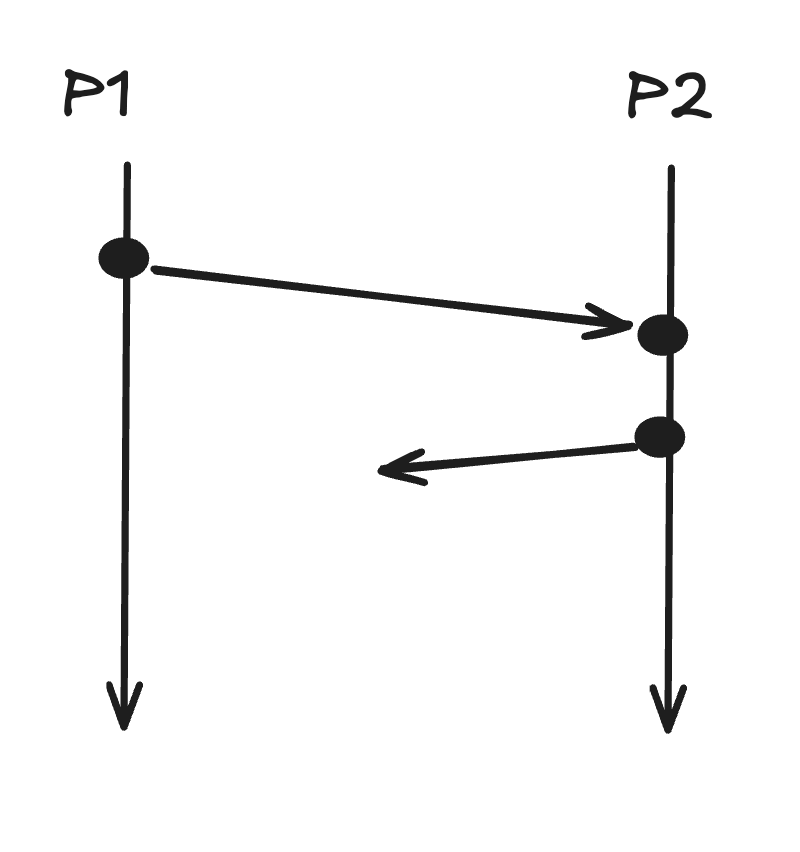
These are ways that potential causality is used in distributed system:Determining order of events after the fact(debugging)Causal ordering of events a
9.Chandy-Lamport Algorithm(2) - In depth
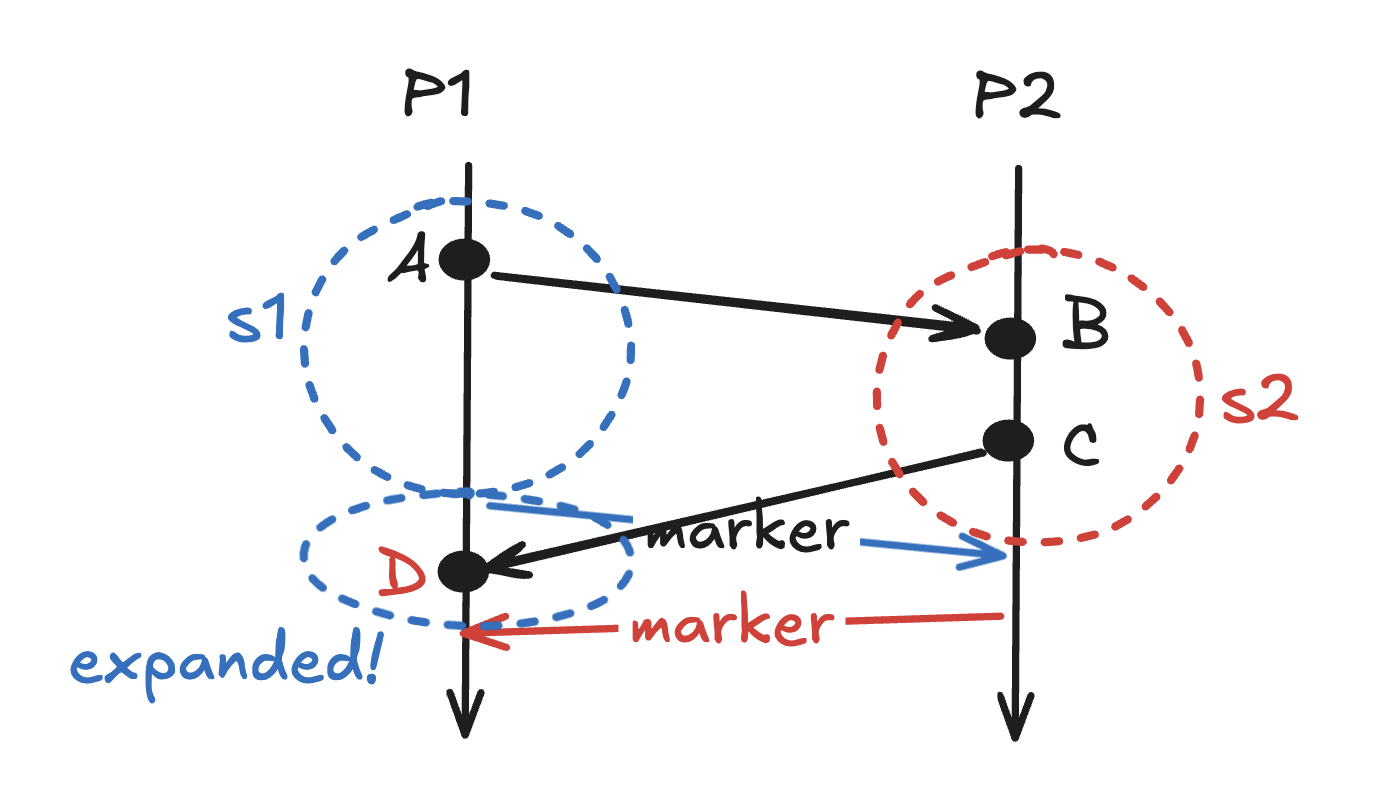
The Chandy–Lamport algorithm is a snapshot algorithm that is used in distributed systems for recording a consistent global state of an asynchronous sy
10.Comparison between strict and sloppy quorum
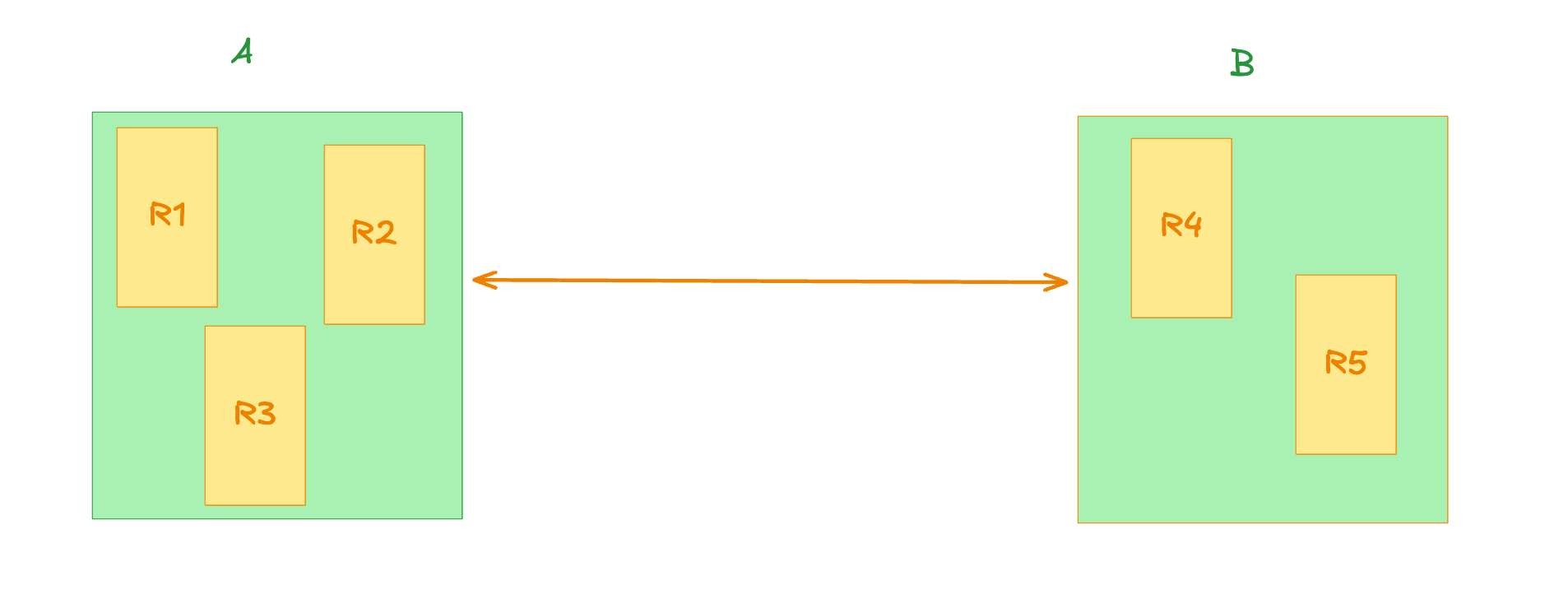
Quorum is quite a well-known concept that allows for tunable consistency. But then, it is also weak at (mostly) inter-datacenter partition. Imagine yo
11.Chandy-Lamport Algorithm(3) - Assumptions, Properties
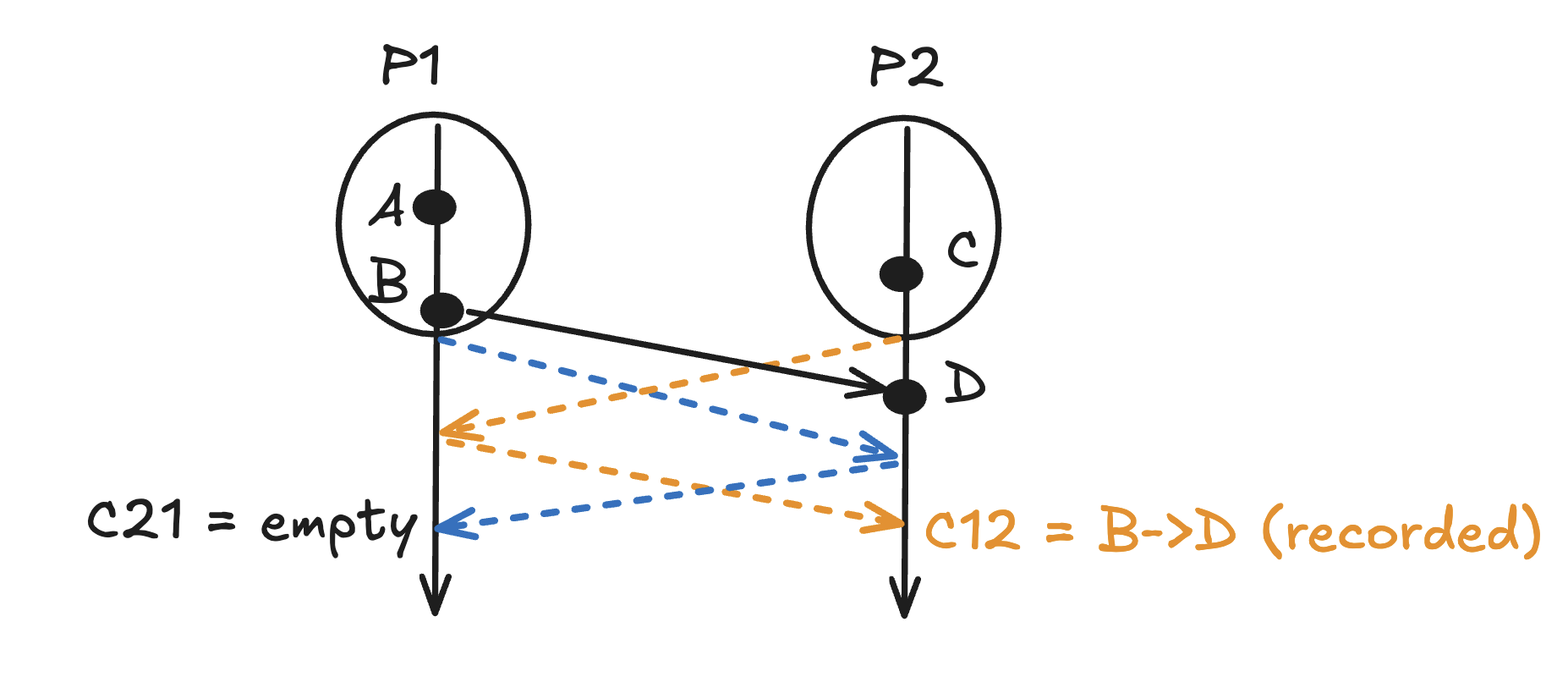
Read these articles if you haven't already:Chandy-Lamport Algorithm(1) - Consistent global snapshotsChandy-Lamport Algorithm(2) - In depthCheckpointin
12.Two phase commit in distributed system
this is the same word that describes the actor that manages consensus in consensus algorithm the actor that manages replication within the shardHoweve