Segmentation
화면에 특정 부분을 분리하는 것을 컴퓨터비전에서 많이 봤을 것이다.

자율주행 자동차들은 사람과 도로, 나무, 벽 등을 구분해서 지나다닌다.
여기서 제일 중요한 것이 Segmentation 기술이다.
이미지 안에서 구역을 나눠 구분을 하는 것을 배워보자.
Global Thresholding
이때까지 Thresholding이라함은 T보다 작을땐 0 클땐 1 이런식으로 배웠다.
g(x,y)={1iff(x,y)>T0iff(x,y)≤T
g(x,y)=⎩⎪⎪⎨⎪⎪⎧2iff(x,y)>T11ifT1≥f(x,y)>T20iff(x,y)≤T2
Threshold는 여러개로 구역을 나눌 수도 있다.
아래에 Multiple Global Thresholding 참고.
Simple Iterative Technique

위와 같은 이미지를 2개의 영역으로 구분하려면 어떻게 알고리즘이 흘러갈까?
Principal
- T=T0로 초기값으로 초기화한다.
- C1이라는 [0,T]의 영역을 가진 클래스 구간을 나눈다.
- C2이라는 [T+1,L−1]의 영역을 가진 클래스 구간을 나눈다.
- C1의 평균 m1, C2의 평균 m2을 구한다.
- m1과 m2의 평균을 T에 대입한다. T=2m1+m2
- ∣Tnew−T≤ΔT∣ 때까지 1~5의 과정을 반복한다.
Example
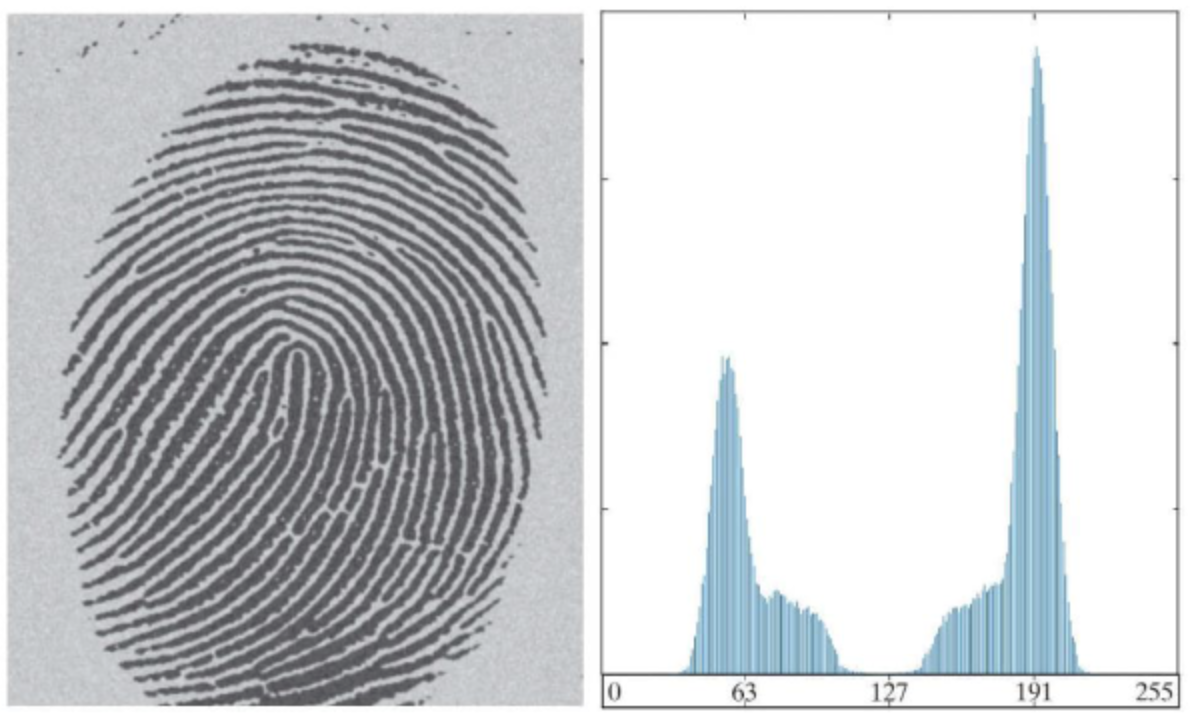
지문 사진과 사진의 히스토그램이 있다고 하자.
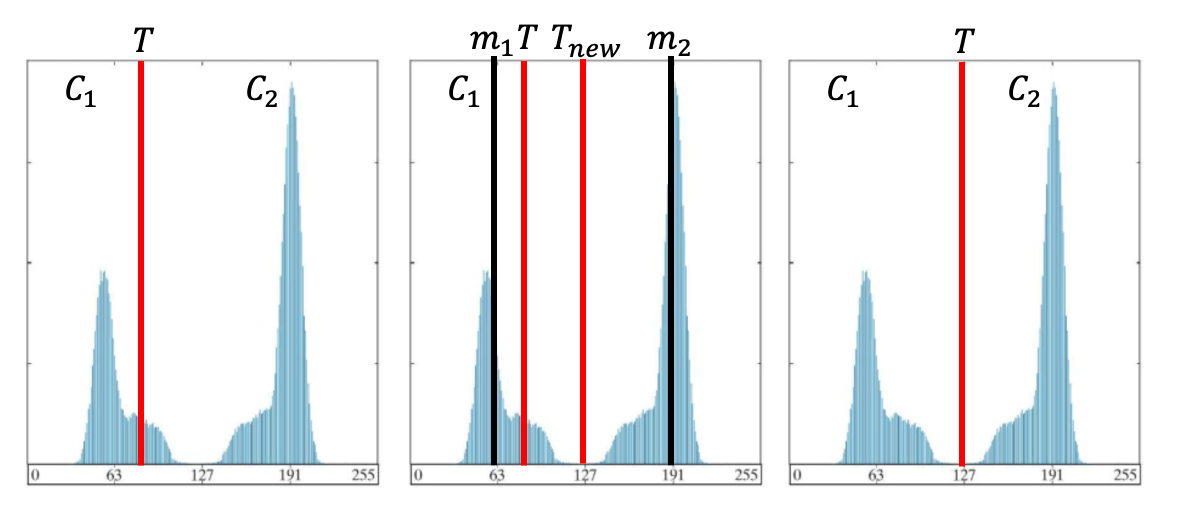
처음으로 T값을 아무데나 지정해 구간을 나눈다.
그 다음 각 구간에 대한 평균과 평균에 대한 평균(2m1+m2)을 새로운 Tnew에 갱신한다.
이를 반복해 거의 움직이지 않는다면(∣Tnew−T≤ΔT∣), T를 찾은 것이다.
하지만 이상적인 상황에서 딱 우리 눈으로 봤을때 쉬워보이는 히스토그램만 Segmentation한다는 단점이 있다.
Otsu's Method
그래서 Class간의 분산과 Class내부의 분산의 통계적인 개념을 도입한 방법이 있다.
Class 간의 분산이 크다는 것은, Class가 구분이 잘되어있다는 말이므로,
Class 간의 분산을 크게 최적화하는 것이 Otsu's Method이다.
Principal
-
within class variance: σW2(k)=P1(k)σ12(k)+P2(k)σ22(k)
-
between class variance:
σB2(k)=P1(k)(m1(k)−mG)2+P2(k)(m2(k)−mG)2=σG2−σW2(k)
-
p(i)=MNn(i), mG=E[i]=∑i=0L−1ip(i),
σG2=E[(i−mG)]2=∑i=0L−1(i−mG)2p(i)
여기서 σB2(k)를 최대화한다는 것은 σW2(k)를 최소화하는 것과 같다.
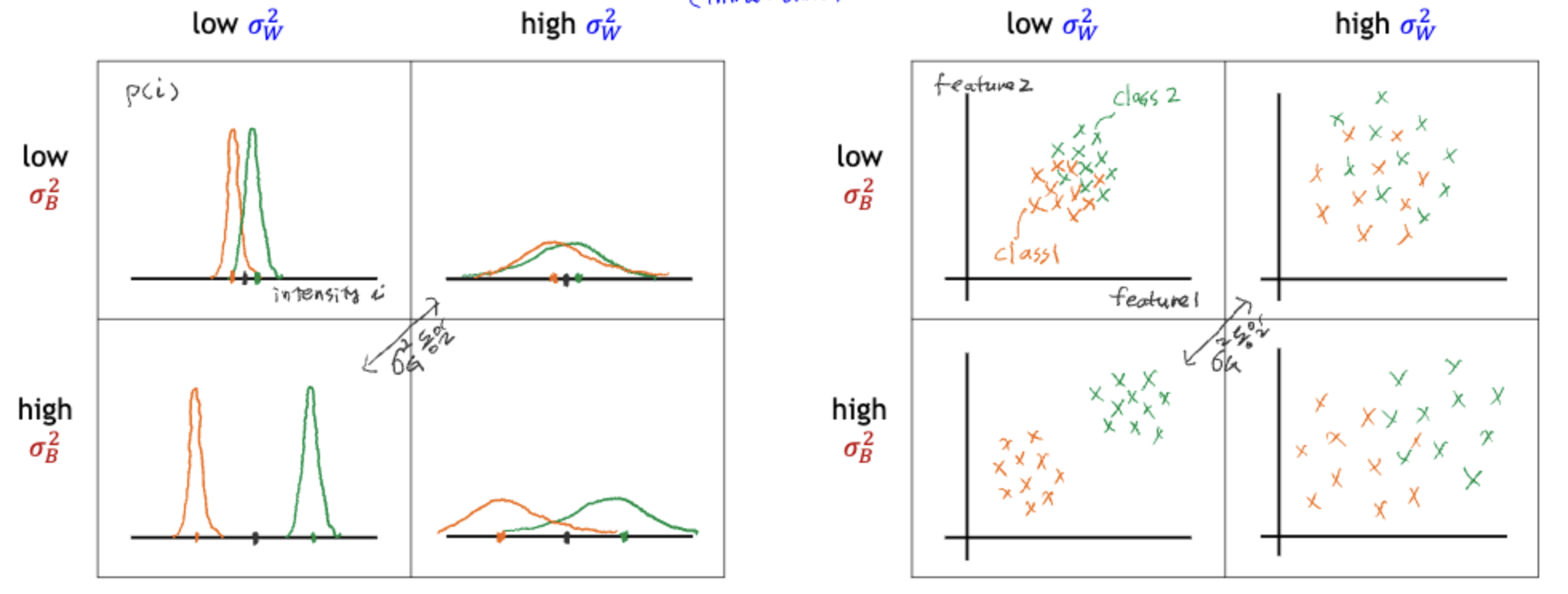
그림을 참고하면 이해하기 쉽다.
클래스 내부 분산이 작으면 군집의 너비가 좁아지고, 분산이 크다면 넓어진다.
클래스 간 분산이 작으면 군집끼리의 거리가 좁아지고, 분산이 크다면 멀어진다.
P(C1)=P1(k)=∑i=0kp(i)이므로
P(C2)=P2(k)=∑i=k+1L−1p(i)는 1−P1(k)와 같다.
왜냐면 P(C1)+P(C2)=1이기 때문이다.
아까 언급한 클래스 내부 분산의 식은 다음과 같다.
σW2(k)=P1(k)σ12(k)+P2(k)σ22(k)
그리고 클래스 간 분산의 식은 σB2(k)=σG2−σW2(k)=P1(k)(m1(k)−mG)2+P2(k)(m2(k)−mG)2=P1(k)P2(k)(m1(k)−m2(k))2
여기서 P1(k)+P2(k)=1 이므로 P1(k)=P2(k)=0.5로 갈때 최대값을 가진다.
또한, (m1(k)−m2(k))2은 클래스 간의 거리제곱으로도 볼 수 있다.
두 클래스의 너비(분산)이 거의 같아지고, 두 클래스 간의 거리가 커지면 최적화 된다는 것이다.
P1(k)P2(k)(m1(k)−m2(k))2=P1(k)(1−P1(k))(mGP1(k)−m(k))2 로 P2를 제거한 P1에 관한식으로 유도할 수 있다.
η(k)=σG2σB2(k) (0≤η(k)≤1)로 나타내어 η(k)를 1에 가깝게 만들도록 최적화한다.
max0≤k≤L−1σB2(k)=max0≤k≤L−1P1(k)(1−P1(k))(mGP1(k)−m(k))2로 P2를 안구해도 되는 식을 써보자.
- 모든 i에 대한 p(i)를 구한다.
- mG를 구한다.
- 모든 0≤k≤L−1에 대한 P1(k), m(k), σB2(k)를 구한다.
- σB2(k)들 중 최대가 되는 k가 최적의 T이다.
Example

위 같은 노이즈가 심한 이미지가 있을 때는 당연히 뭐 먼저한다?
Low pass Filtering으로 노이즈를 제거해야한다.
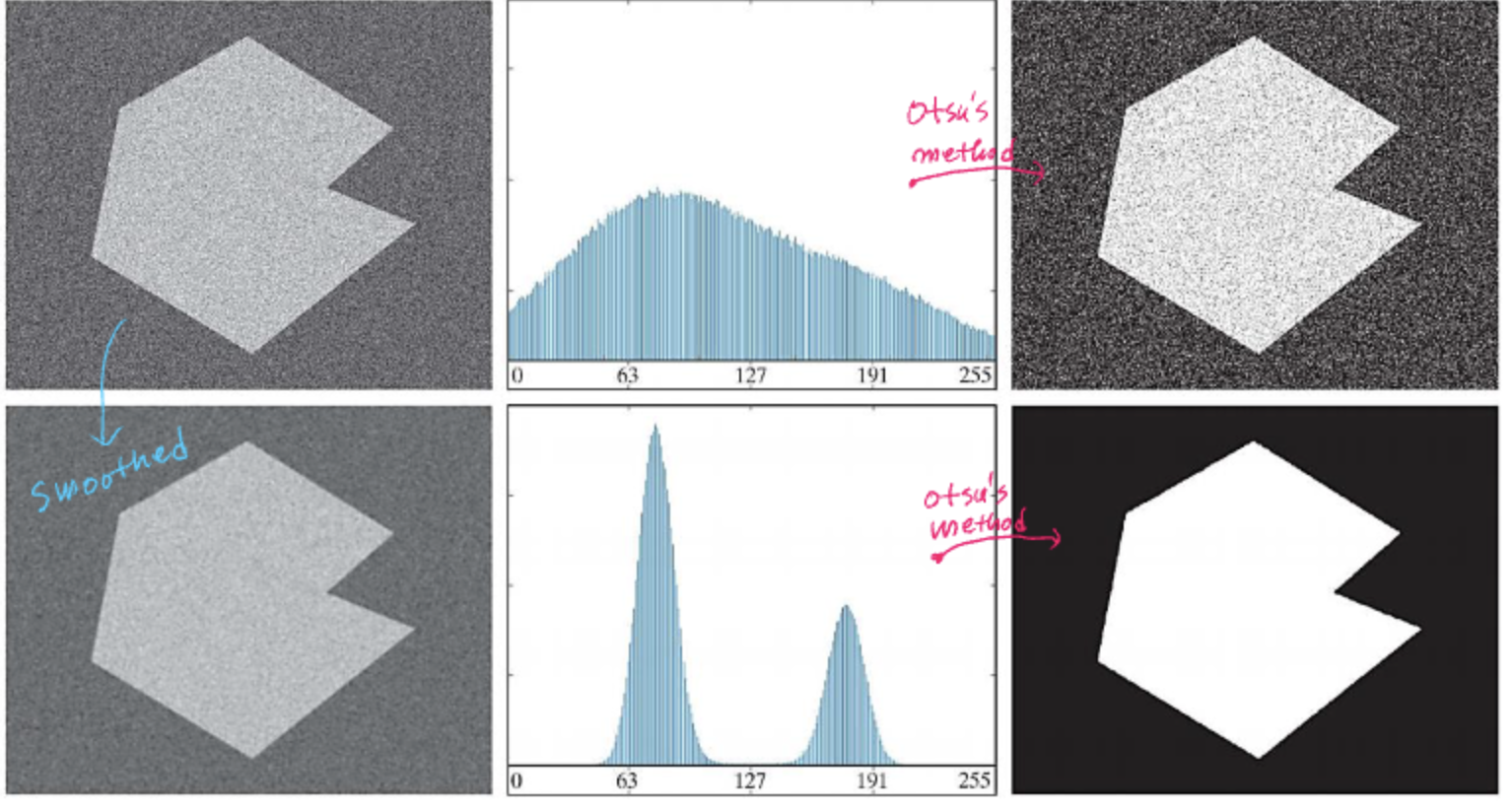
Smoothing을 진행하고 Otsu's Method를 거쳐 Segmentation을 하면 된다.
Using Edges
하지만 클래스간의 간격이 매우 좁고, 가운데 클래스의 피크가 너무 커서
주변의 다른 클래스와 구분이 안가는 경우가 있을 수 있다.
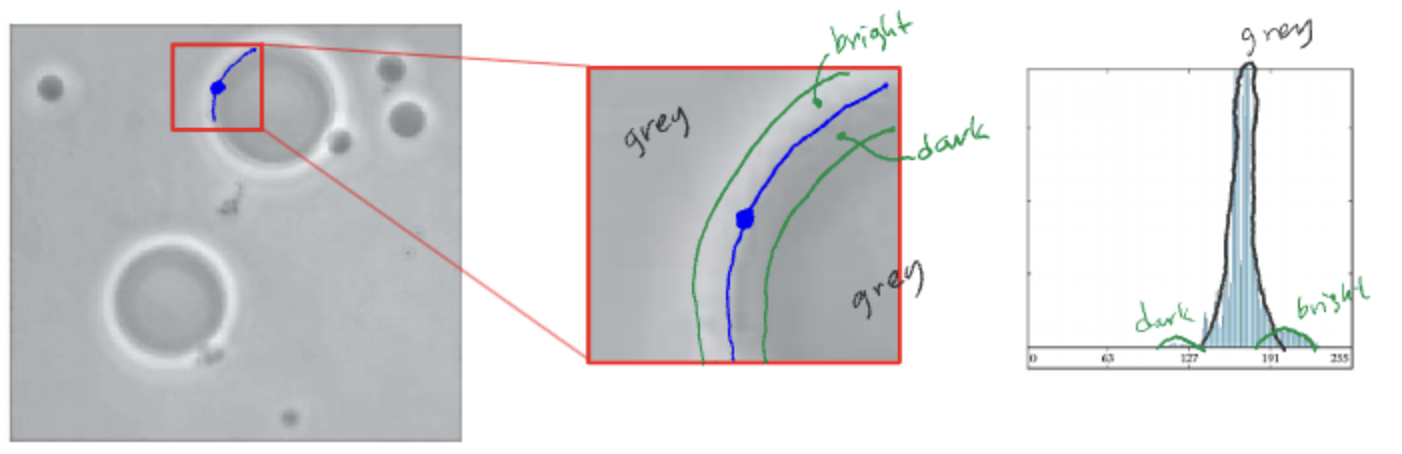
히스토그램만 보면 클래스가 단 하나로 판단할 수도 있다.
이때는 엣지만의 데이터를 검출해서 엣지안의 데이터만 보고 Segmentation을 실행한다.
Principal
- Laplacian이나 magnitude of the gradient 를 이용해서 엣지를 검출한다.
- 엣지 이미지 내에서 히스토그램을 그린다.
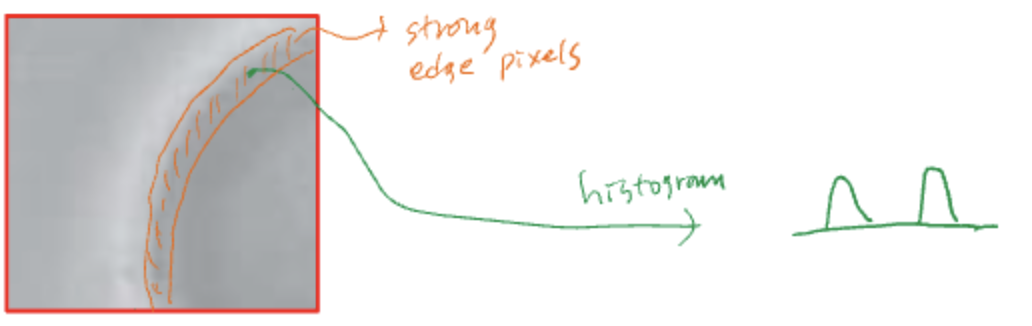
- 구분이 어려웠던 히스토그램이 간단해졌으므로, 여기서 Otsu's Method를 쓴다.
Example
회색 배경에 아주작은 흰 점의 이미지가 있다고 하면, 히스토그램은 다음과 같다.
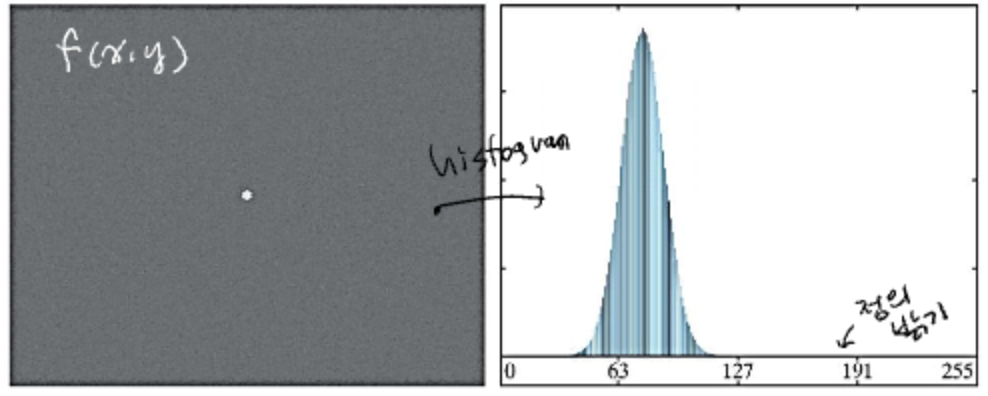
점이 매우 작기때문에 히스토그램에서는 무의미한 점의 밝기가 표현된다.
이러한 이미지에 Edge를 검출하는 gN을 취하면 다음의 히스토램의 분포처럼 변한다.
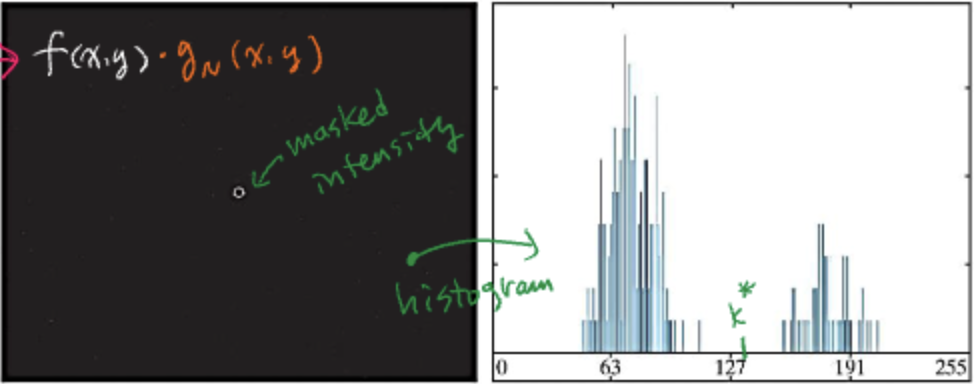
히스토그램에서 점의 밝기가 증폭된 것처럼 변환이 된다.
왜냐하면 Edge만을 검출했기 때문에, Edge 주면의 값만 히스토그램에 나타나기 때문이다.
저 히스토그램으로 Otsu's Method를 진행한다.
cv2.threshold()
OpenCV에는 threshold()라는 함수로 이미지에 Global Threshold를 적용할 수 있다.

type으로 다음의 종류를 가진다.

우리가 배운 Otsu's Method의 Threshold를 자동으로 정해주는 기능도 있다.
Multiple Global Thresholding
Threshold가 여러개있는 것이다.
이를 Otsu's Method에 적용해보자.
2 classes(1 Thresholds)
σB2(k)=P1(k)(m1(k)−mG)2+P2(k)(m2(k)−mG)2
P1(k)=∑i=0kp(i), P2(k)=∑i=k+1L−1(1−p(i))
m1(k)=∑i=0kiP1(k)p(i), m2(k)=∑i=k+1L−1iP2(k)(1−p(i))
K classes(K-1 Thresholds)
σB2=P∑k=1KPk(mk−mG)2
Pk=∑i∈ckpi
mk=Pk1∑i∈ckipi
뭐 수식은 복잡하지만 별거 없다.

왼쪽이 2Classes, 오른쪽이 Multiple Threshold라고 보면 저 수식이 이해가 될 것이다.
Local Thresholding
실제 사진을 찍으면 음영차가 있는 경우가 있다.

스도쿠에서 Thresholding을 적용해서 밝게 적용하고 싶다고 할때
Global Thresholding을 적용해버리면 사진이 타노스마냥 반토막 날 수도 있다.
그래서 이미지를 나눠서 Thresholding을 적용하는 것을 Local Thresholding이라고 한다.
방법은 크게 3가지가 있다.
Partitioning
첫 번째 방법인만큼 간단하다.
-
이미지를 히스토그램으로 바로 나타내면, 어디가 class인지 구분하기 어렵다.
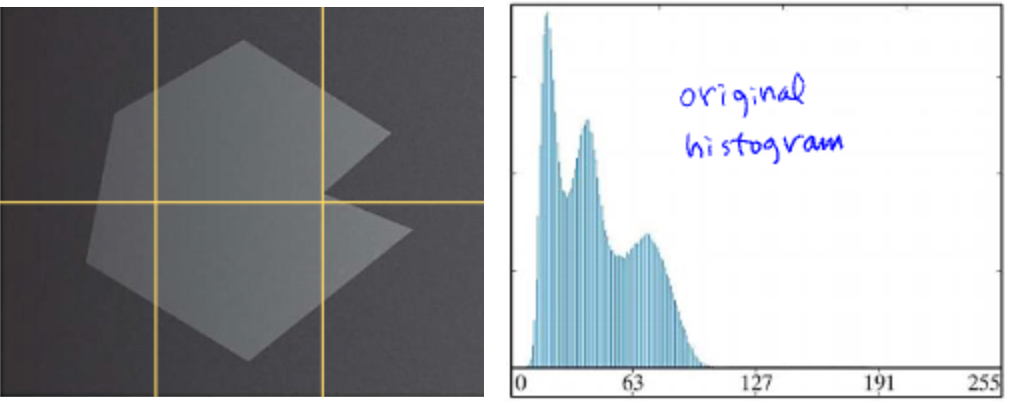
-
이미지를 원하는 개수만큼 sub image로 나누고 각 구간별로 히스토그램을 그린다.
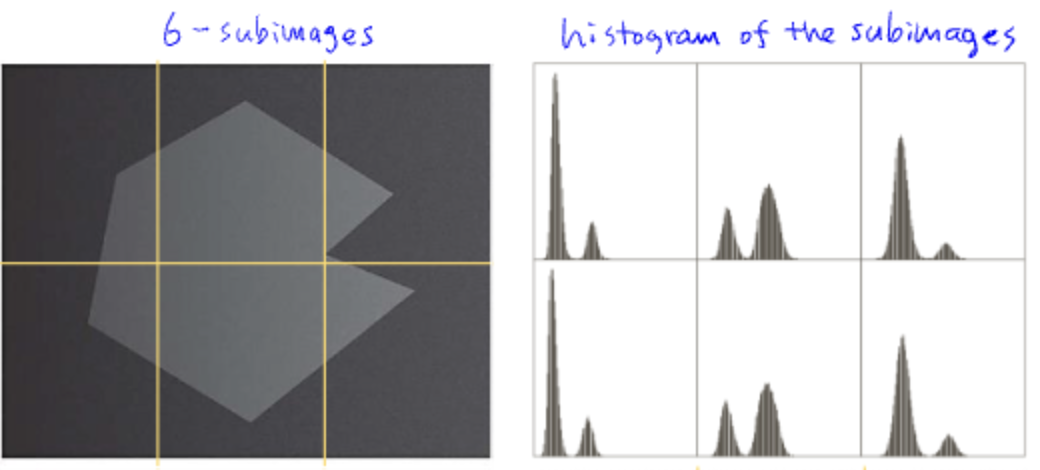
- 히스토그램별로 Otsu's Method 를 적용하여 최종 이미지로 합친다.

Local Statistics
가장 많이 쓰이는 방법으로 통계적 관점으로 접근한다.
이미지를 (0,0)부터 (M-1, N-1)픽셀까지 3x3, 5x5, ... 마음대로 주변 픽셀을 관찰한다.
마치 Convolution에서 주변 픽셀을 관찰하는 것처럼 말이다.
자신을 포함해서 주변픽셀들 Sxy의 평균 mxy과 표준편차 σxy를 구한다.
Sxy에 대한 local threshold Txy=aσxy+bmxy로 정한다.
임계값보다 작으면 0, 크면 1을 적용한다.
Moving Averages
Local Statistics는 평균과 표준편차를 쓴다면, Moving Averages는 평균만 사용한다.
Txy=bmxy로 정한다.
Example

주변은 어둡고 가운데가 밝은 이미지도 잘 검출해낸다.

1111 자로 어두운 영역 또한 맛있게 걸러낸다.
P.S. 글씨체를 검출할 때는 글씨체의 두께(stroke)픽셀의 5배정도로 윈도우 사이즈 n을 잡는게 좋다고 한다.
cv2.adaptiveThreshold()
OpenCV 에서는 threshold가 local별로 다르기 때문에 적응형 임계값이라고 한다.