Abstract
이 논문은 Remote sensing 데이터에서 image와 text 간의 연관성을 더 정확하게 찾아내기 위한 새로운 방법을 제안한다.(Remote Sensing Image-Text Retrieval)
기존의 Remote Sensing Image-Text Retrieval에서는 Semantic noise(배경, 불필요한 요소들)가 문제를 일으켜 image-text 간 관계를 표현하는 데 한계가 존재했다.
이 논문에서는 이를 개선하기 위해 새로운 아이디어를 도입하였다.
Prior instruction(사전 지식)을 활용
Remote sensing에서 Prior instruction이라 하면 특정 장면, 객체에 대한 general한 정보
ex)
- 장면 : 도시 지역의 위성 이미지에서는 특정 지역이 도시인지, 숲인지, 물이 있는 지역인지에 대한 general한 특성
- 객체 : remote sensing이미지에서 비행기, 도로, 호수, 산 등 Object가 어떻게 생겼는지에 대한 general한 특성
이를 위해 두 가지 새로운 구조를 제안하였다.
1. Spatial-PAE(공간적 Progressive Attention Encoder)
- 이미지의 공간적 정보를 파악하여 중요한 feature를 골라내는 역할
2. Temporal-PAE(시간적 Progressive Attention Encoder)
- 텍스트 데이터를 분석할 때, 단어들 간의 시간적인 흐름(문맥)을 잘 파악하여 더 정밀한 표현을 만든다.
Introduction
Remote sensing image-text retrieval이란?
위성이나 드론이 수집한 대규모 remote sensing 데이터베이스에서, 특정 image에 맞는 text 설명을 찾거나, 주어진 text에 맞는 image를 검색하는 작업이다.
최근 들어, Remote sensing 데이터의 폭발적인 증가와 image-text retrieval 기술의 발전으로 인해, Remote sensing에서의 image-text retrieval의 데이터와 기술적인 지원이 크게 향상되었다.
그러나, 기존의 RSITR 기술은 한계가 존재한다.
1. 기존 방법의 구조적 limitation
대부분의 기존 방법은 CNN을 기반으로 한 image representation과 RNN을 기반으로 한 text representation을 사용한다.
이 방법은 서로 먼 위치에 있는 정보 간 관계를 잘 모델링하지 못한다는 단점이 존재한다.
2. Semantic noise(의미적 잡음)의 영향
Natural 이미지와 다르게 Remote sensing 데이터는 작은 Object가 많고 배경이나 불필요한 정보의 간섭을 쉽게 받는다.
그리고, image와 text representation 간의 confusion zone이 발생하여 검색 정확도를 떨어뜨린다.
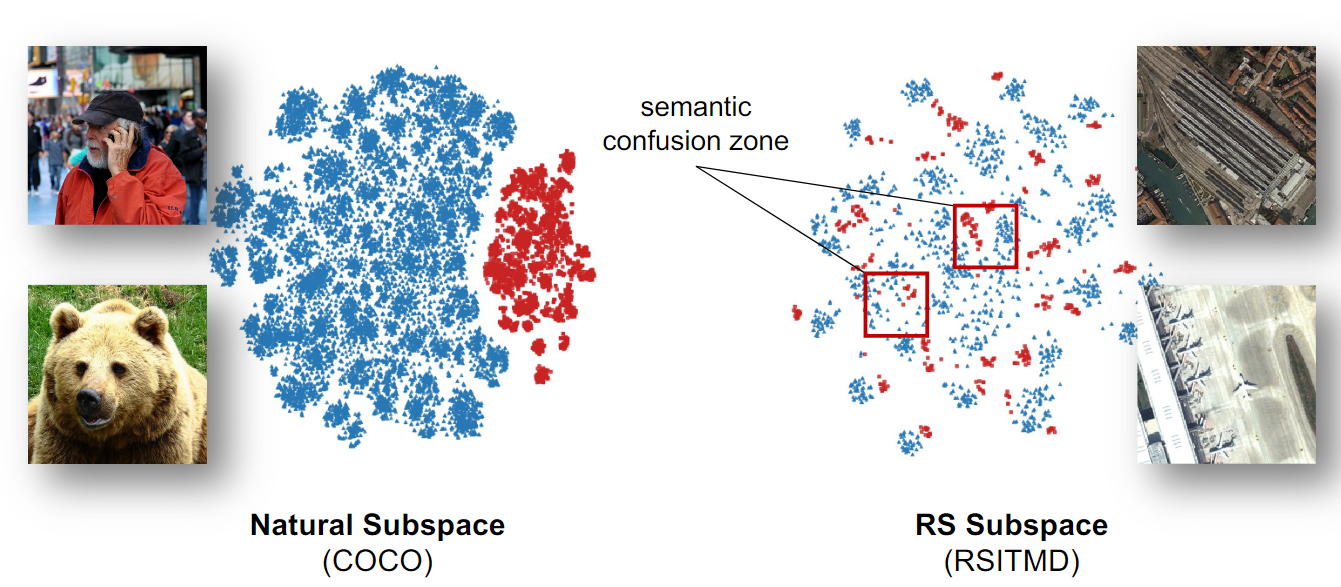
기존의 연구에서는 이러한 문제를 해결하기 위해 filtering 기술을 사용하여 Semantic noise를 줄이려는 시도를 했지만, CNN 및 RNN 기반의 한계로 인해 구조적인 Limitation에 효과적이지 못했다.
그래서, Transformer를 기반으로 한 모듈을 설계하여 Remote sensing에서의 image-text retrieval를 실험하였는데, 이는 서로 먼 위치에 있는 정보 간 관계를 모델링하지 못하던 구조적인 Limitation은 개선할 수 있었지만, Remote sensing 데이터의 특성을 무시하는 문제가 존재했다.
따라서, Remote sensing 데이터에 특화된 Framework의 필요성이 제기되었다.
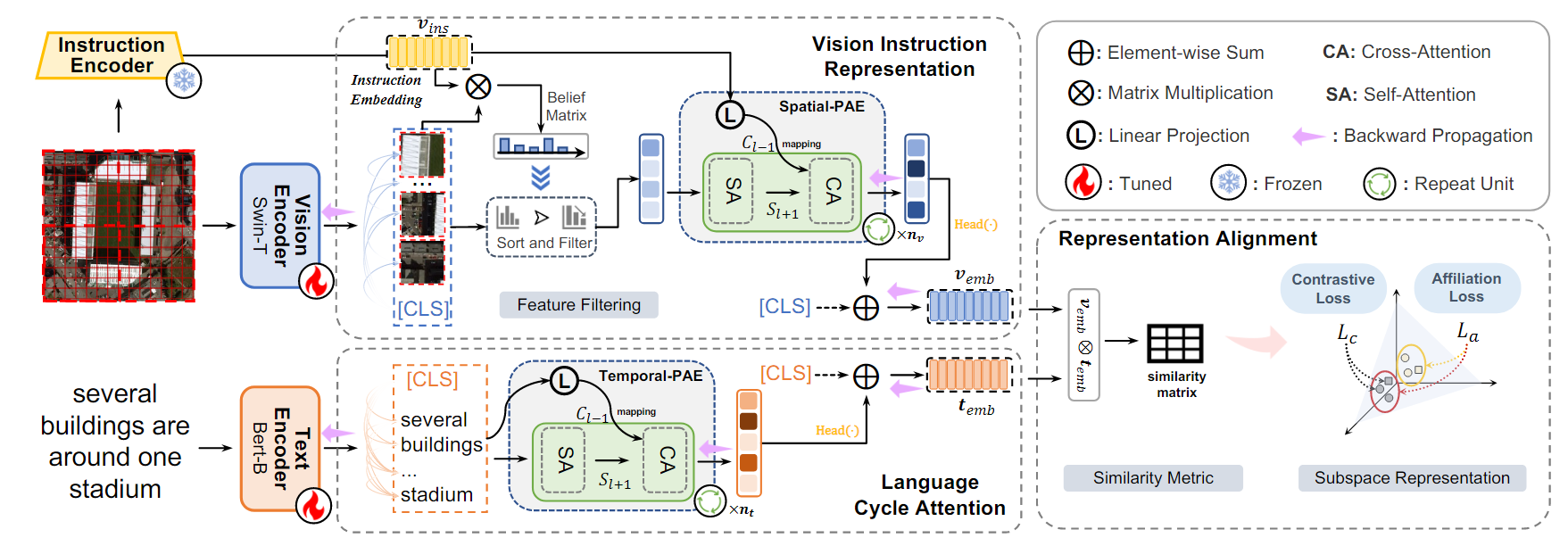
Remote sensing에서의 image-text retrieval를 위한 Prior Instruction Representation Framework(PIR)를 제안한다.
Remote sensing 장면 인식에 대한 Prior instruction을 활용하여 vision 및 text representation을 개선하고 semantic noise를 줄이는 데 focus를 맞춘다.
PIR framework는 다음과 같은 기술적 요소로 구성된다.
1. 두 가지 PAE(Progressive Attention Encoder)
-
Spatial-PAE
Remote sensing image를 더 잘 이해하기 위해, 외부 지식을 활용하여 이미지의 공간적 feature를 강조한다.
-
Temporal-PAE
Text의 시간적 흐름(단어 간 문맥)를 이해하기 위해, 이전 단어가 현재 정보를 강화하도록 만든다.
2. VIR(Vision Instruction Representation)
Spatial-PAE를 기반으로, Remote sensing 데이터의 Semantic noise를 줄이고, 중요한 feature만 남기도록 설계된 기술이다.
예를 들어, 공항 이미지를 분석할 떄, 주변의 풀밭이나 도로 대신 비행기와 활주로에만 집중하도록 돕는다.
3. LCA(Language Cycle Attention)
Temporal-PAE를 기반으로, Text에서 단어 간의 연결 관계를 더 잘 이해해, 더 명확한 텍스트 표현을 생성한다.
4. 클러스터 단위 손실 (Cluster-wise attribution loss)
클래스 간 혼동을 줄이기 위해(비슷한 특징을 가진 클래스 간에 잘못 매칭되는 경우) 같은 클래스에 속하는 이미지-텍스트는 서로 가까워지게, 다른 클래스에 속하는 데이터 간에는 서로 멀어지게 데이터의 유사성을 조정하여
모델이 클래스를 더 잘 구분할 수 있게 한다.
이 Framework를 도입하여 RSICD, RSIMD라는 두 데이터셋에서 실험한 결과, 기존 기술에 비해 4% 이상 성능이 향상되었다.
Methodology
Preliminaries
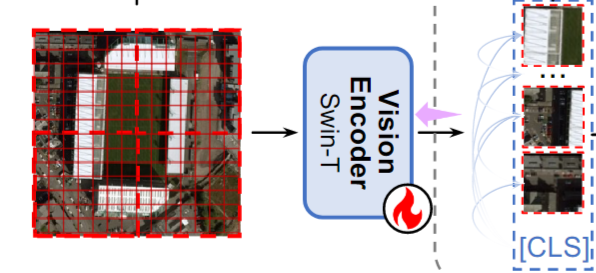
Vision Encoding
Transformer는 Convolution 대신, Self-Attention을 사용하여 Sequence 처리를 더 강력하게 만든다.
이를 바탕으로 Swin Transformer를 Vision encoder로 사용하여 이미지를 encoding한다.
입력 이미지 는 먼저 크기의 고정된 패치들로 나뉜다.
- : 3채널 RGB 이미지, 높이 H, 너비 W
이 패치들은 Swin transformer를 통해 인코딩되어, Global feature인 (CLS 토큰)과 Local feature인 을 얻는다
- : Vision encoder
- : Fine-tuning된 가중치
- : Concatenation(병합)을 나타낸다설
- : Local feature의 특징의 개수를 나타낸다
Remote sensing 이미지는 Semantic noise가 많아 vision representation에서 중요한 정보를 담는 데 방해가 된다.
예를 들어, 공항 이미지에서 주변 나무, 구름 같은 배경은 Semantic noise 이다.
편향이 없는 vision representation을 얻기 위해 ResNet을 Remote sensing 이미지로 구성된 데이터셋인 AID를 이용해 Pre-training하여 Instruction encoder로 사용한다.
시각적 표현에서의 편향이란?
이미지에서 불필요하거나 잘못된 정보가 중요한 정보를 가리는 현상
ResNet은 AID데이터셋을 이용해 pre-trained된 가중치 를 이용하여 입력 이미지를 분석한다.
이를 통해 생성된 Instruction embedding()은 이미지에서 중요한 특징에 대한 정보를 제공하여, 모델이 더 정확히 학습할 수 있도록 돕는다.
예를 들어, 공항 이미지라면, "비행기"와 "활주로"에 집중하도록 지시하고, 배경에 대해 덜 중요하다고 판단하도록 학습을 유도한다.
Text Encoding
RNN 기반 feature 추출 방법과 Bert 기반 text feature 추출 방법이 주요 접근 방식으로 사용된다.
RNN과 비교할 때, Bert는 Transformer의 능력을 기반으로 입력 Sequence 내 모든 위치를 동시에 고려할 수 있어, Global semantic 관계를 포착할 수 있다.
이 논문에서는 Text encoder로 Pre-trained된 Bert를 사용하여 텍스트 를 인코딩한다.
이를 통해, Global feature (([CLS] 토큰))과 Local feature ()을 얻을 수 있다.
- : Text encoder
- : Fine-tuning된 가중치
- : Local feature의 개수
Progressive Attention Encoder
기존의 Transformer 기반 모델은 종종 specific한 task에 특화되어 task에 따라 유연하게 확장되지 않는 경우가 많다.
Remote sensing에서 image-text retrieval에서는 맞춤형 transformer 구조를 재설계하고 재학습해야 하며, 이것은 efficient하지 않다.
Vision 및 text 표현을 향상시키기 위해, PAE 구조인 Spatial-PAE와 Temporal-PAE를 설계하였으며, 기존 Transformer 아키텍처를 활용하면서도 서로 먼 위치에 있는 정보 간 관계도 잘 모델링하기 위해 만들어졌다.
Transformer Encoder Layer(TEL)
TEL은 PAE의 주요 구성 요소로, 두 가지 주요 작업을 수행한다.
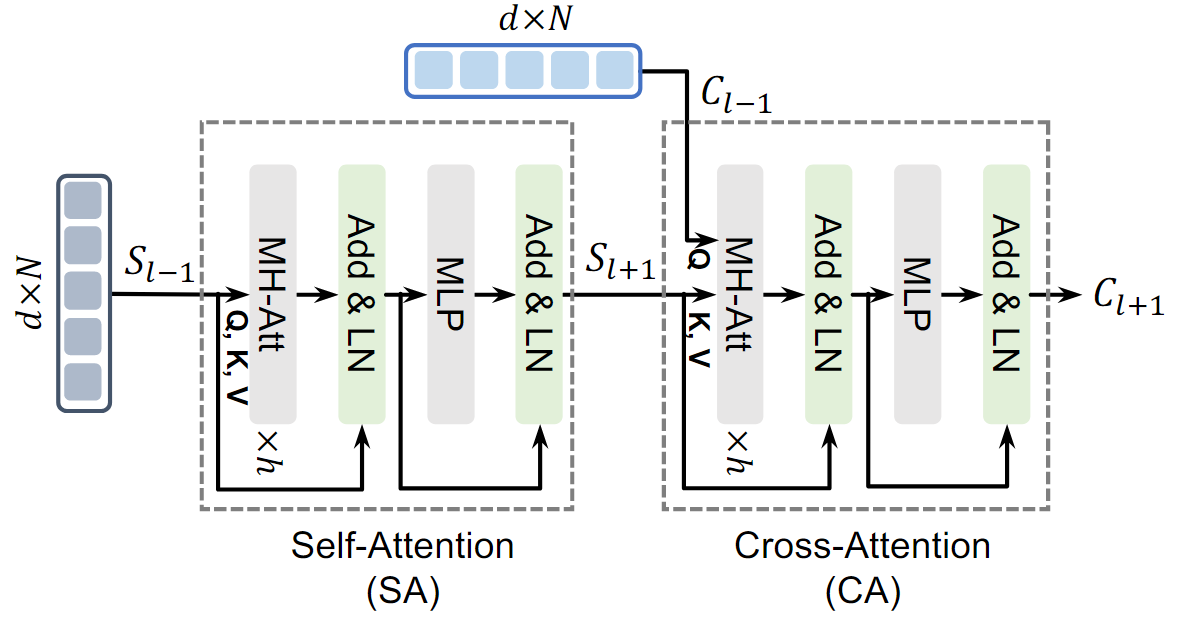
1. Self-Attention
하나의 Sequence 내에서 중요한 관계를 찾는다
- 단어 간 관계 또는 패치 간 관계 파악
2. Cross-Attention
서로 다른 두 Sequence 간 관계를 모델링한다.
- 텍스트와 이미지 간 관련성을 이해
TEL에서는 Multi-head Attention 메커니즘이 사용된다.
single-head attention만 사용하면, 한 가지 관계 정보만 학습하게 되는데, 여러 개의 어텐션 헤드를 사용하면 다양한 시점에서 데이터를 바라볼 수 있다.
병렬 연산을 통해 더 강력한 표현 학습이 가능
scaled dot-product attention
- , , (
- , , : 가중치 행렬
Self-Attention
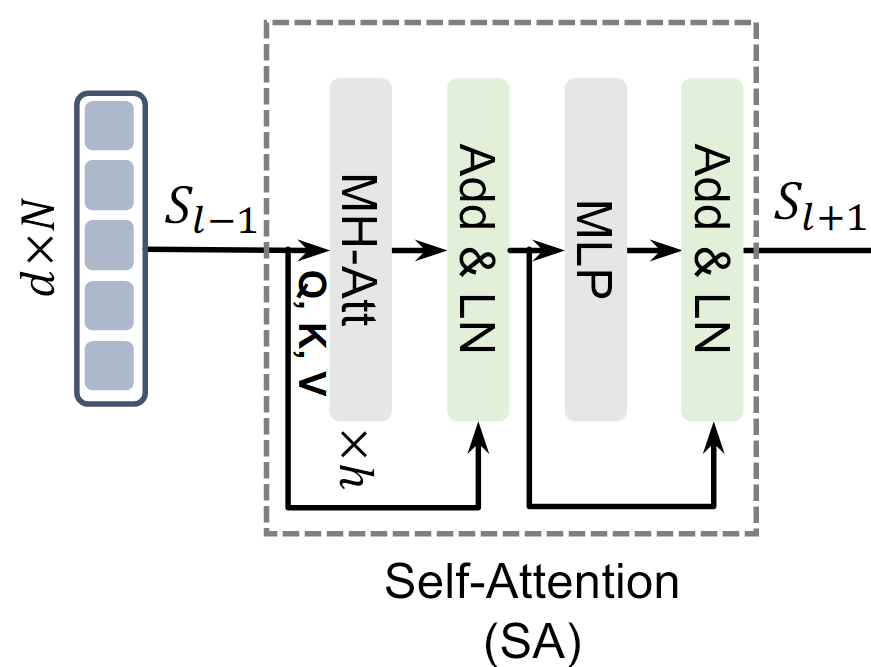
한 시퀀스 내에서 중요한 정보를 추출한다.
1.MHA + LN
- MHA를 통해 데이터를 다각도로 분석 후 LN으로 데이터를 정규화함
- Residual connection 추가
2.MLP + LN
추가적인 비선형 변환을 통해 시퀀스 표현을 정제
Cross-Attention
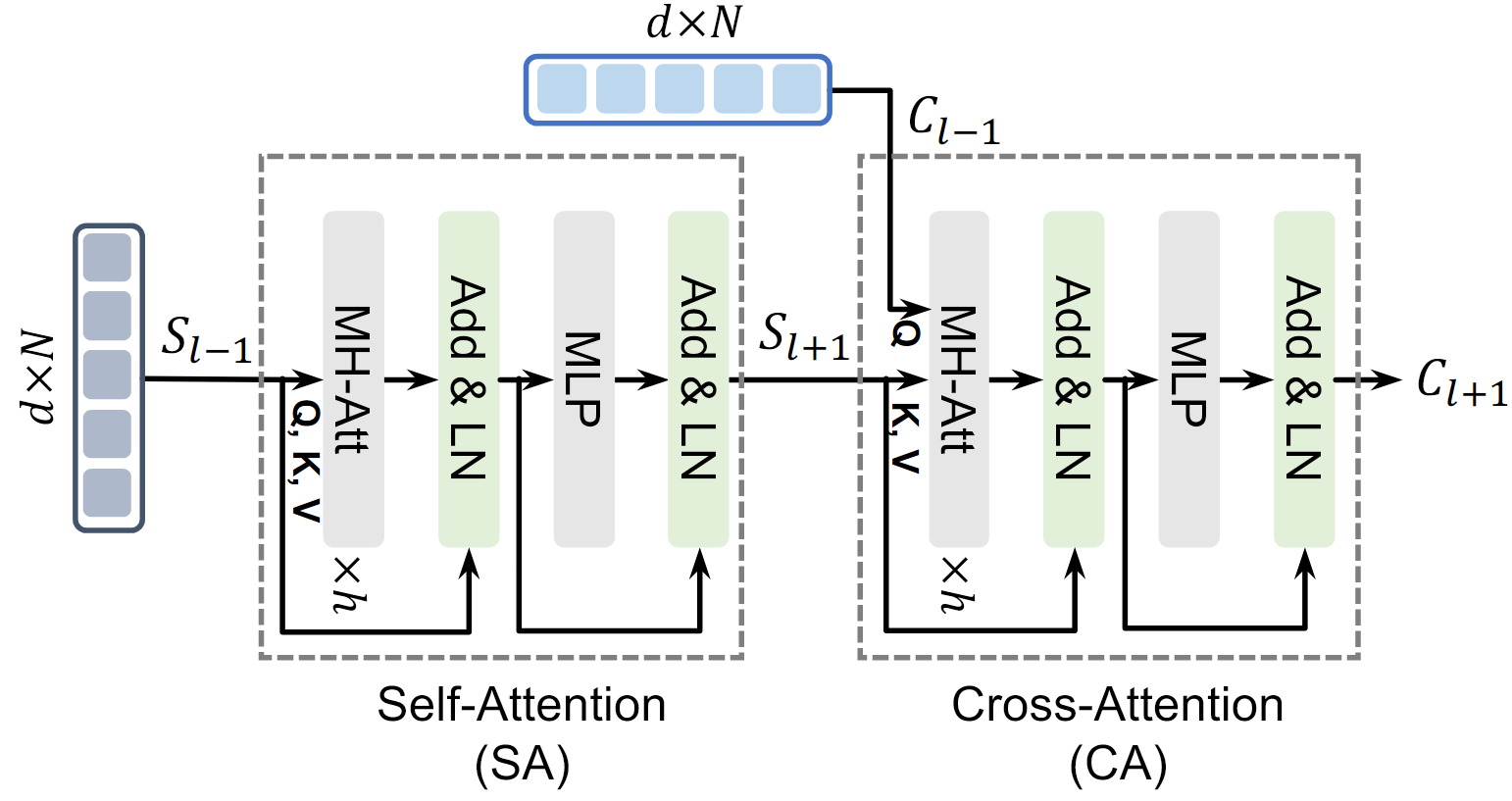
두 개의 른 시퀀스 간의 상호 관계를 학습한다.
1.MHA + LN
- MHA를 통해 데이터를 다각도로 분석 후 LN으로 데이터를 정규화함
- 은 다른 입력 시퀀스의 이전 layer 출력
2.MLP + LN
Cross-Attention이후 추가적인 비선형 변환을 통해 시퀀스 표현을 정제
Messaging between TELs
TEL 간 메시지 전달 방식에 기반하여, Spatial-PAE와 Temporal-PAE라는 두 가지 전달 방식을 설계하여, 주요 feature representation을 향상시켰다.
Spatial-PAE(공간적 연결)
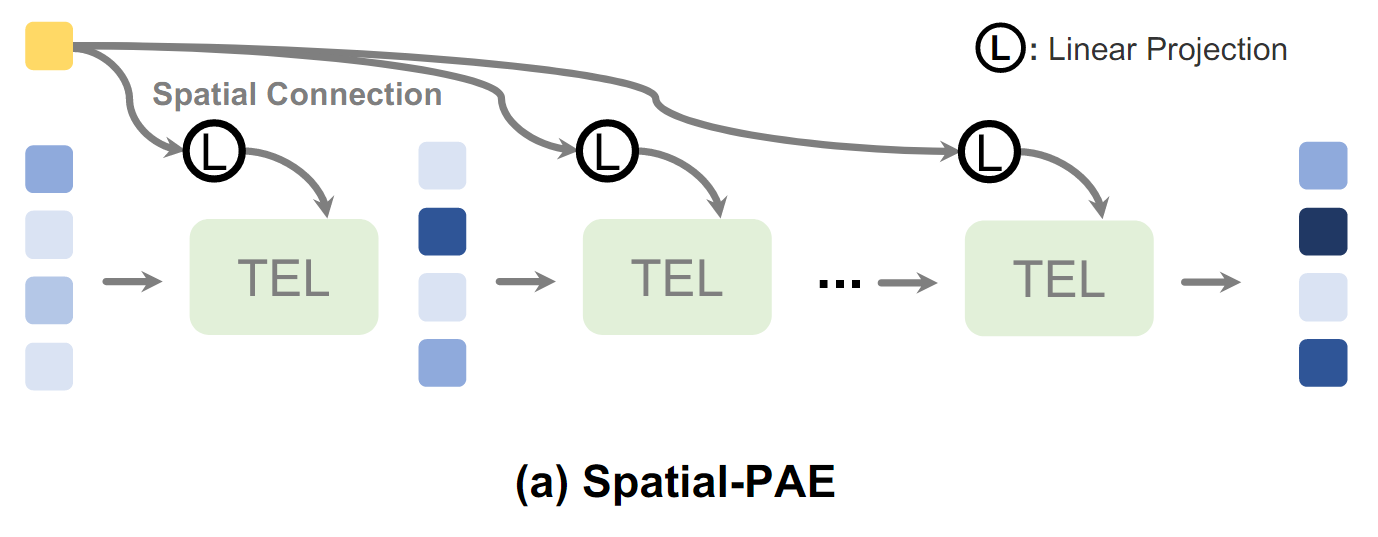
Spatial-PAE는 TEL에서 공간적 관계를 이해하는 데 도움을 준다
<동작 방식>
-
외부 소스의 입력 시퀀스를 linear projection을 통해 TEL에 연결한다.
이미지에서 각 패치의 공간적 관계를 외부 지식을 바탕으로 연결
-
Cross-Attention을 사용하여, 각 시퀀스의 관계를 모델링한다.
단순히 시퀀스를 fusion하는 것이 아니라, TEL이 글로벌 정보를 더 잘 포착하도록 돕는다.
<문제 해결>
-
기존의 Self-Attenion에서는 모든 입력 간 관계를 계산하기는 하지만, 외부 지식 없이는 충분히 글로벌한 의미를 반영한 관계를 학습하지 못할 수 있다.
예를 들어, "비행기"를 나타내는 패치와 "활주로"패치가 연관된다는 사실은 외부 지식이나 추가적인 정보 없이 학습하기 어렵다
-
또한, Self-Attention은 입력 전체를 고려하기 때문에 local detail에 대한 학습이 희석될 수 있다.
예를 들어, 이미지의 특정 작은 object인 작은 비행기는 전체 맥락에서 중요도가 낮게 평가될 가능성이 있다.
Spatial-PAE의 공간적 연결을 통해 TEL이 글로벌 정보를 더 잘 학습하도록 돕는다.
Temporal-PAE(시간적 연결)
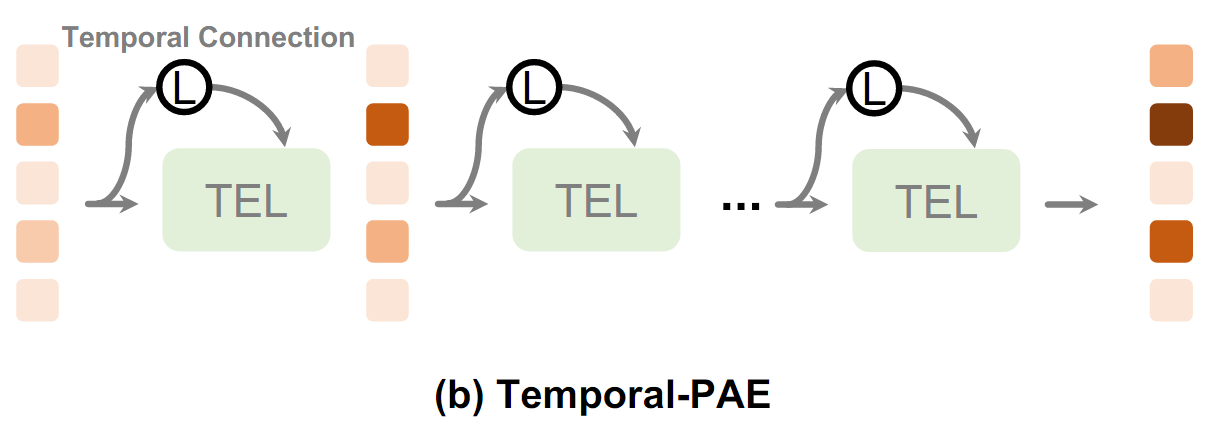
Temporal-PAE는 TEL에서 시간적 관계를 이해하는 데 도움을 준다
<동작 방식>
- linear projection을 사용하여, 이전 시점의 출력과 현재 시점의 입력 간에 연결을 만든다.
이전 시점과 현재 시점 간의 데이터를 기반으로 attention map을 계산한다.
Attention map은 Attention 메커니즘에서 만들어지는 가중치 행렬
- 입력 데이터 간 중요도를 나타냄
<문제 해결>
-
TEL에서 사용되는 positional encoding은 시퀀스 내의 위치 간의 관계를 완벽히 이해하지 못할 수 있다.
Transformer기반 구조에서는 positional encoding이 암묵적으로 전제됨
-
여러 Self-Attention layer가 쌓이면, 위치 정보가 모호해지거나 부정확해질 위험이 있다.
텍스트의 단어 순서나 이미지 패치의 순서가 섞일 수 있다.
-
Self-Attention은 각 입력 토큰 간 관계를 계산하지만, 시간적인 관계를 명시적으로 학습하지 않는다.
Temporal-PAE는 이전 시점의 정보를 현재와 결합하여, 위치 정보의 ambiquity(모호성)과 inaccuracy(부정확성)을 줄인다.
Vision Instruction Representation
Natural 이미지와 달리, Remote sensing 이미지의 크기가 작은 Object는 Semantic noise의 영향을 받기 쉽고, Vision representation에 큰 영향을 미친다.
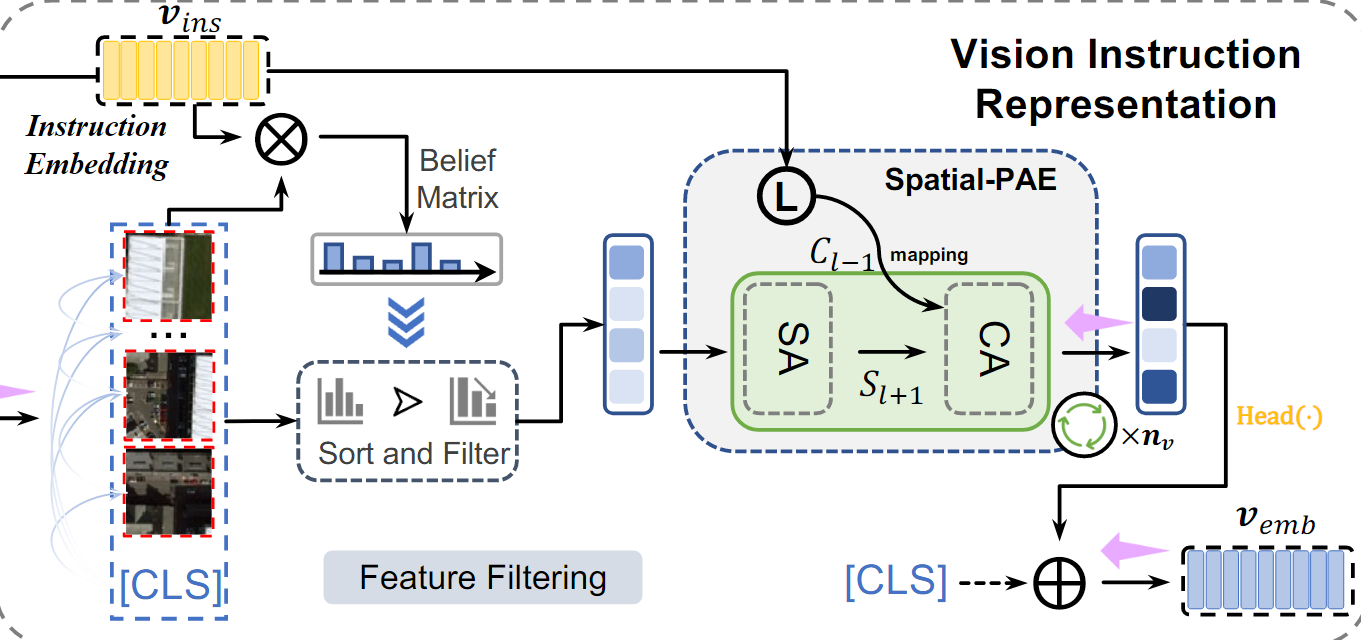
1. Belief matrix 생성
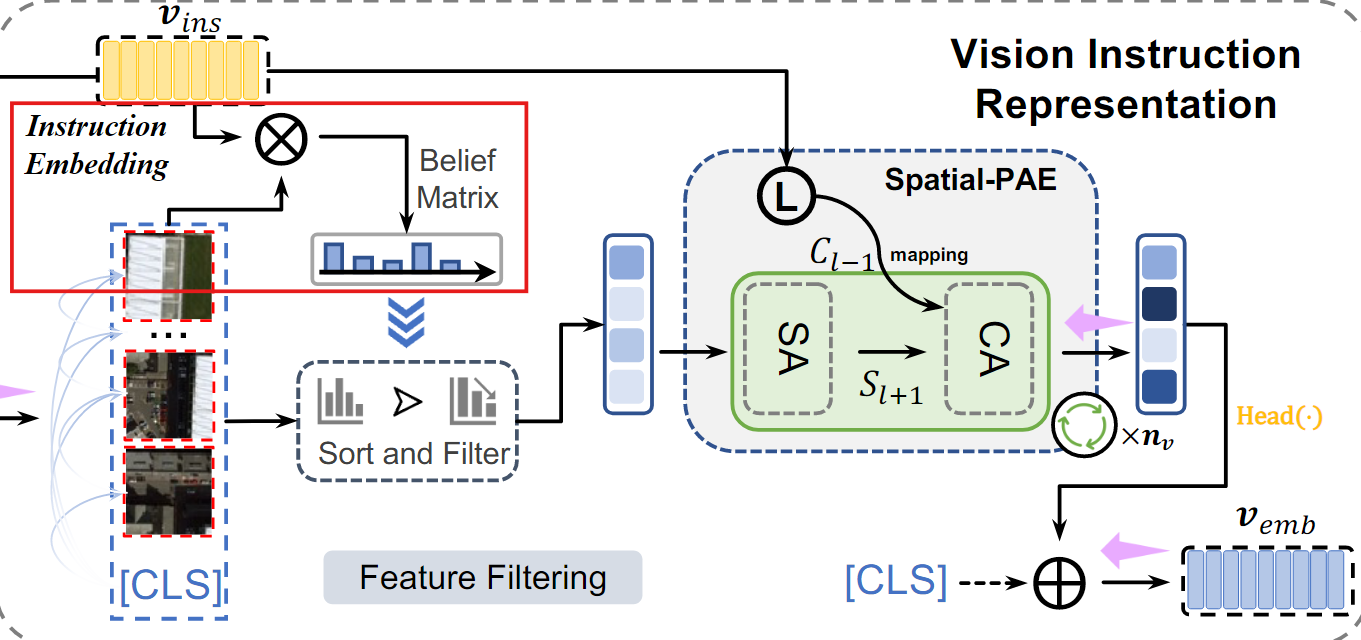
VIR은 먼저 Instruction embedding을 사용하여 belief matrix를 생성한 다음, 특징을 필터링하여 편향 없는 vision representation을 생성한다.
- Instruction embedding과 Vision embedding 간 내적 (Dot Product)을 통해 Intruction과 vision feature간 유사도 산
- : Remote sensing 데이터에 대한 prior instruction(Instruction embedding)
- : 이미지 전체의 global feature
- : 이미지의 각 패치(local feature)
- : 각 특징의 중요도를 확률 값으로 변환
즉, Instruction이 강조하고 싶은 vision feature에 높은 가중치를 부여한다
belief matrix 은 각 패치의 중요도를 나타내는 확률 분포 행렬
2. 특징 정렬 및 필터링
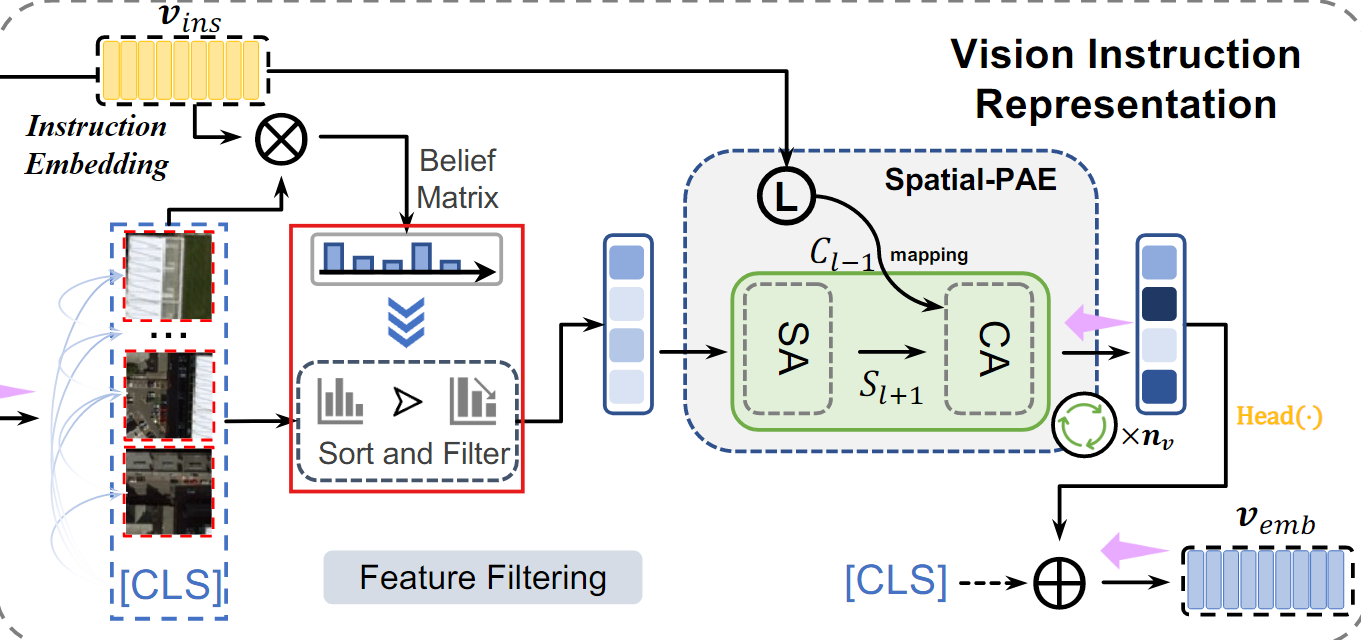
생성된 belief matrix 를 사용해, 중요도가 높은 패치만 남기고 제거한다.
- : 정렬 및 필터링된 feature(중요한 정보만 남은 상태)
3. Spatial-PAE를 통한 장거리 의존성 학습
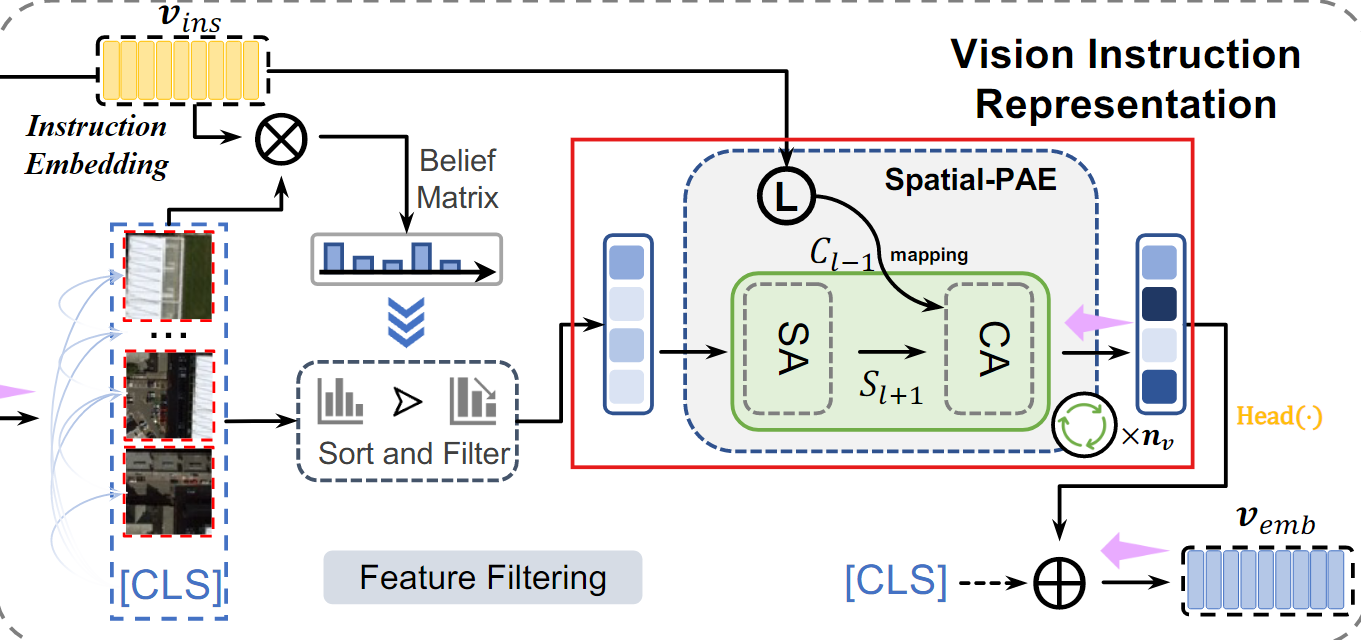
정렬된 feature 응 TEL로 입력하여, 각 feature간의 장거리 의존성을 학습한다.
외부 지식(Instruction embedding)을 결합해 feature 간의 관계를 강화한다.
- : i번째 TEL의 출력
- : i번째 linear projection 가중치
여러 layer를 통과하며, 중요한 특징 간의 관계를 점점 정교하게 학습한다
4. 편향 없는 local embedding 생성
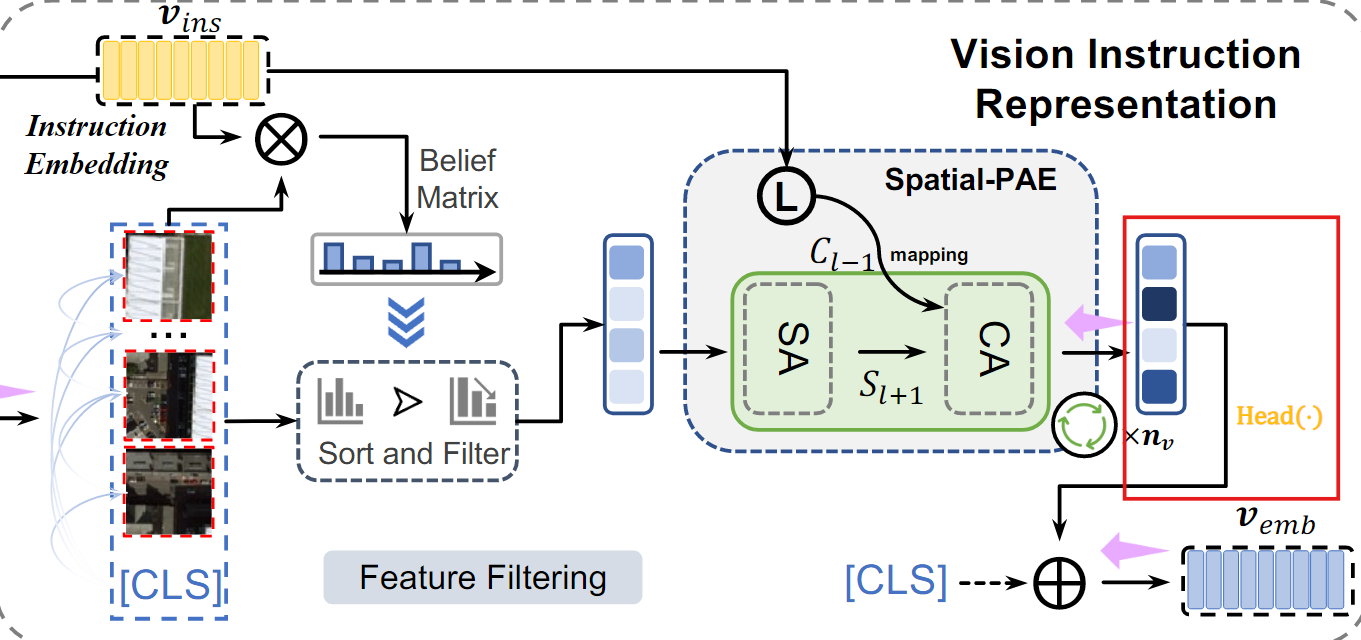
마지막 TEL layer의 출력에서 나온 가장 중요한 feature를 변환하여 local embedding을 생성한다.
- : TEL의 마지막 layer에서 중요한 정보를 추출하는 모듈(마지막 layer의 head embedding을 편향되지 않은 embedding으로 매핑)
5. 최종 vision embedding 생성
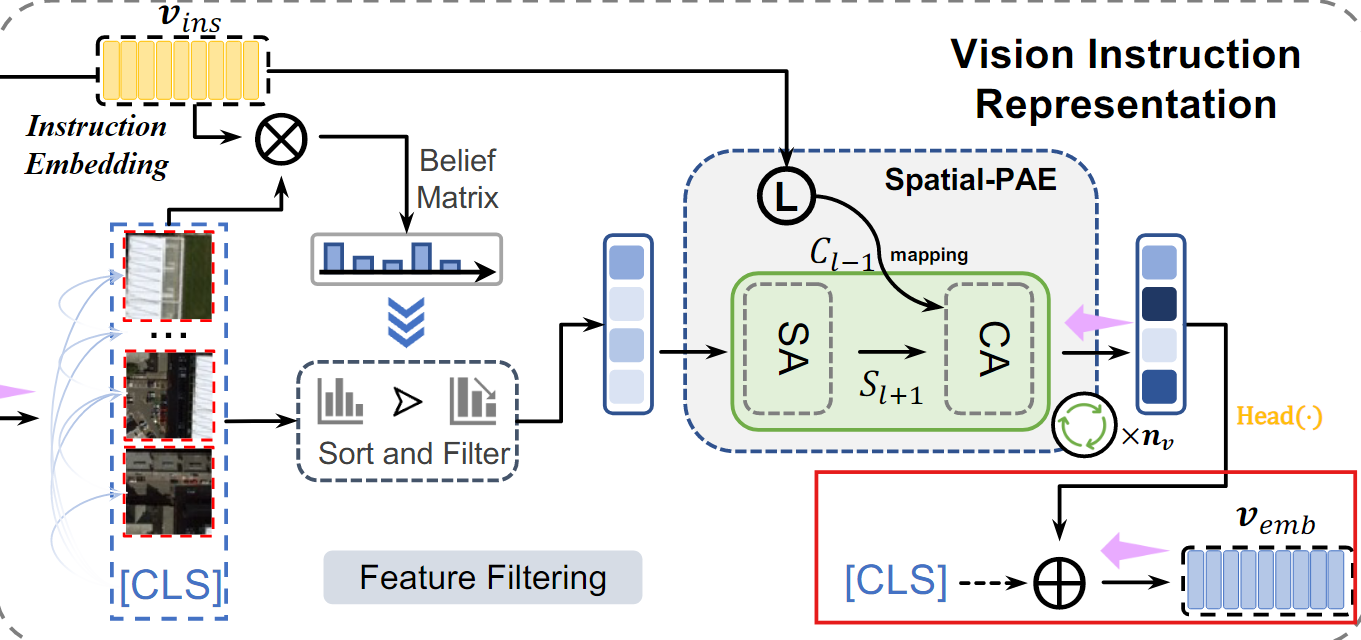
VIR은 global feature()와 local feature()을 결합해 최종 vision embedding을 생성한다.
이 최종 임베딩은 Semantic noise가 제거된 상태에서 중요한 feature만을 담고 있다.

- Vision Instruction Representation (VIR)은 Remote sensing 이미지의 Semantic noise를 줄이기 위해 사전 지식(Prior instruction)을 활용한다
Language Cycle Attention
Transformer는 Self-Attention 메커니즘을 활용하여, 입력 텍스트 시퀀스의 모든 단어 간 관계를 학습한다.
<Transformer의 한계>
-
Transformer는 단어 간 순서를 명시적으로 처리하지 않는다.
Positional encoding을 입력에 추가하여 단어의 위치를 나타낸다.
하지만, 긴 시퀀스에서는 이 위치정보가 모호해지거나 손실될 가능성이 높다 -
또한, Transformer는 긴 시퀀스를 처리할 때, 단어 간의 글로벌 관계를 잘 모델링하지 못할 수 있어 전체적인 문맥을 이해하는 데 방해가 된다.
<LCS의 역할>
-
위치 정보의 모호성 해결
이전 시점의 feature를 현재 시점으로 순환적으로 전달하여, 위치 정보의 왜곡을 줄임
-
문맥 표현 강화
긴 시퀀스에서도 각 단어 간의 관계를 순환적으로 학습하여, 문맥 표현을 더 정교하게 만듦
<LCA 동작 과정>
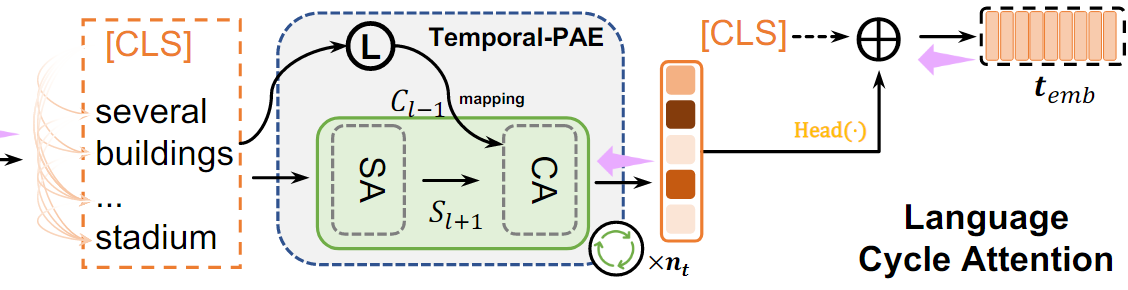
LCA는 Temporal-PAE를 사용하여 텍스트 특징을 순환적으로 활성화한다.
1. 초기 텍스트 특징 추출
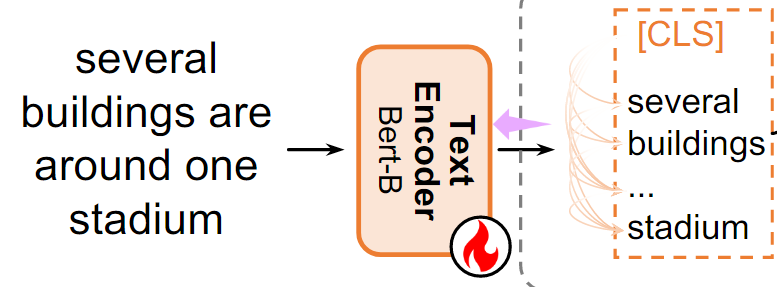
텍스트 인코더를 통해 global feature 와 local feature 로 인코딩되어 LCA의 입력으로 사용된다.
2. 순환적 활성화
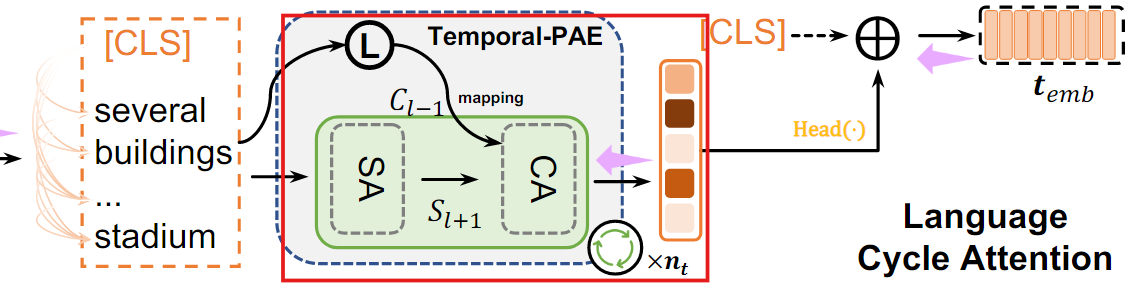
LCA는 Temporal-PAE를 사용하여 cyclic한 방식으로 단어 수준의 feature를 활성화하여, 이전 시간 단계의 정보를 현재 시간 단계에 반영한다.
- : 번째 TEL의 출력
- : 번째 linear projection 가중치
- 첫 번째 TEL(i=1) : 문장의 global feature()와 local feature()을 TEL로 전달하여 초기 feature 활성화
- 이후 TEL(i=2,3..) : 이전 TEL 출력(이전 시간 단계의 feature)을 입력으로 사용해, 현재 시간 단계의 feature를 활성화
<최종 Text embedding>
1. Local embedding
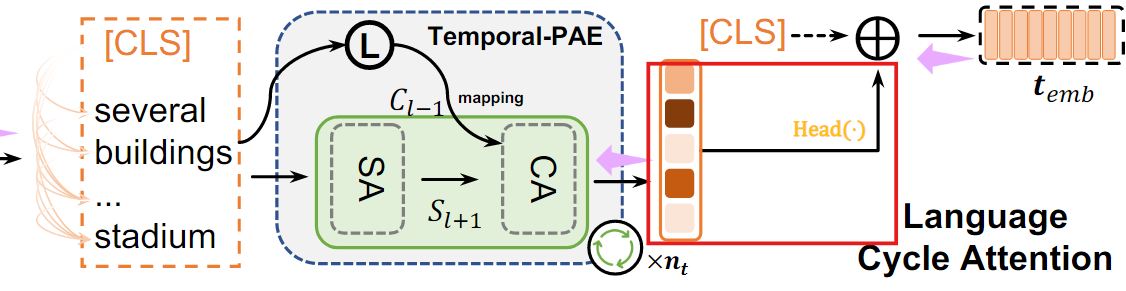
마지막 TEL layer에서, local feature()을 기반으로 local embedding을 생성
)
- : TEL의 마지막 layer 출력에서 중요한 정보를 추출하는 모듈
(Linear projection을 적용해, 차원을 축소하거나 정규화된 표현 생성)
2. 최종 Text embedding
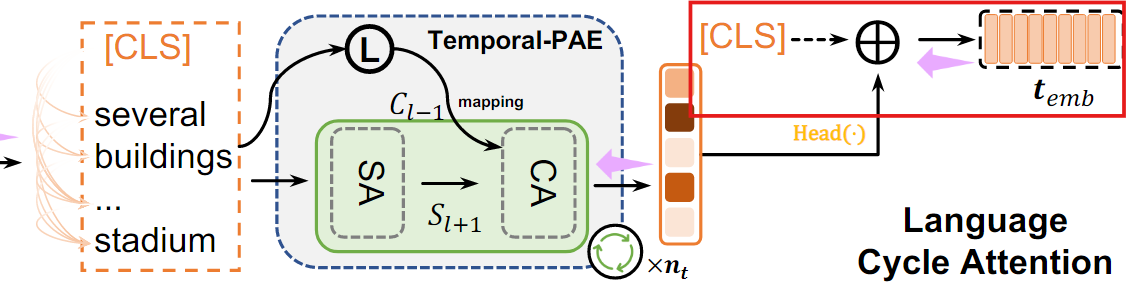
LCA는 global feature와 local feature를 결합하여 최종 텍스트 embedding을 생성
- : 문장 전체의 global feature
- : 문장의 local feature
LCA의 장점
-
LCA는 이전 시간 단계의 정보를 현재 시점으로 순환적으로 전달하여, 위치 정보의 모호성을 해결하고 긴 시퀀스에서도 단어의 순서를 더 정확히 표현하였다.
-
global feature와 local feature를 결합하여, semantic noise를 줄이고 중요한 정보를 강조하였다.
Loss Function
Contrastive Loss
Remote sensing에서 image-text retrieval은 모델이 image-text 쌍을 잘 매칭할 수 있도록 학습해야 함
기존에는 Triplet Loss을 사용하여 positive sample과 negative sample을 사용하여 loss를 계산했지만, 이 방식은 negative sample을 추가로 선택해야 하므로, 계산 비용이 크고 efficiency가 낮을 수 있다.
Anchor(기준 데이터)를 기준으로 positive, negative sample을 정의하여 Anchor에 더 가깝게, 더 멀어지게 학습함
추가적인 negative sample 없이도 샘플 간 유사성을 계산하기만 하면 되는 contrastive loss를 사용한다.
<Contrastive loss정의>
1. 입력 데이터
-
N개의 Positive sample쌍
- : i번째 이미지
- : i번째 텍스트
-
각각의 입력 이미지와 텍스트는 최종적으로 임베딩으로 표현됨
- 비전 임베딩 : (이미지 의 임베딩)
- 텍스트 임베딩 : (텍스트 의 임베딩)
2. 코사인 유사도 계산
- 이미지 임베딩 와 텍스트 임베딩 간의 코사인 similarity계산
- : i번째 이미지와 j번째 텍스트 간의 similarity
<Loss 계산 과정>
Contrastive loss는 두 가지 loss로 구성된다.
1. Vision-to-Text Loss
- 모델이 특정 이미지 임베딩 과 텍스트 임베딩 을 매칭하도록 유도
- : 이미지 임베딩 과 텍스트 임베딩 간의 유사도
- : i번째 이미지와 모든 텍스트 간 유사도의 합
- : Temperature parameter는 유사도 값의 스케일을 조정
모델은 가 커지도록 학습한다.
(이미지와 올바른 텍스트의 유사도 극대화)
2. Text-to-Vision Loss
- 모델이 특정 텍스트 임베딩 과 이미지 임베딩 을 매칭하도록 유도
- : 텍스트 임베딩 과 이미지 임베딩 간의 유사도
- : i번째 텍스트와 모든 이미지 간 유사도의 합
- : Temperature parameter는 유사도 값의 스케일을 조정
모델은 가 커지도록 학습한다.
(텍스트와 올바른 이미지의 유사도 극대화)
3. 최종 Loss
- 두 Loss의 평균을 최종 Contrastive loss로 정의
Image-text쌍 간의 유사도를 극대화하고, image와 관련 없는 text의 유사도는 최소화하도록 학습
Affiliation Loss
대부분의 검색 작업에서는 Contrastive Loss와 같은 pair-wise loss를 사용하며, Contrastive Loss 에서는 데이터 전체의 분포나 카테고리 간의 구조적 정보를 고려하지 않는다.
Affiliation Loss는 Remote sensing 데이터의 분포적 특성에 기반하여, 카테고리의 clustering center을 사용하여, 같은 카테고리에 속하는 데이터끼리 더 가까워지도록 군집시켜 Semantic confusion을 줄인다.
<Affiliation Loss 동작 방식>
1. 입력 데이터
-
데이터를 카테고리 정보에 따라 C개의 클래스로 그룹화한다.
예를 들어, 비행기 이미지-활주로 텍스트는 같은 카테고리로 그룹화
-
각 데이터는 cluster center와의 관계를 기반으로 학습된다.
- : i번째 텍스트와 연결된 cluster center
- 각 데이터는 자신의 cluster 중심(해당 카테고리의 대표 벡터)과의 관계를 학습한다.
즉, 같은 카테고리 내 샘플들끼리 더 가깝게 학습된다
2. cosine similarity 계산
- 각 이미지 와 텍스트 간의 cosine similarity를 계산
- vision-text similarity
- 이미지 임베딩 와 텍스트 cluster center 간의 similarity
- text-vision similarity
- 텍스트 임베딩 와 이미지 cluster center 간의 >>similarity
3. Affiliation Loss 계산
- Affiliation Loss는 비전-텍스트와 텍스트-비전 간의 관계를 기반으로 정의
1. vision-text loss
- 이미지와 텍스트 cluster center 간 similarity 최대화
2. text-vision loss
- 텍스트와 이미지 cluster center 간 similarity 최대화
3. Affiliation Loss의 최종 loss
- 위 두 Loss를 평균 내어 Affiliation Loss를 정의
<Affiliation Loss와 Contrastive Loss의 결합>
- 최종 Loss function
Affiliation Loss와 Constrastive Loss를 결합
- : Contrastive Loss
- : Affiliation Loss
- : cluster center에서 군집 정도를 조정하는 가중치 매개변수
<Affiliation Loss의 효과
1. 데이터 분포 반영
같은 카테고리 내 데이터는 더 가까워지고, 다른 카테고리 간의 데이터는 더 멀어진다.
2. Semantic confusion감소
카테고리 간의 경계에서 발생하는 semantic confusion을 줄여 모델이 더 명확한 구분을 학습
Experiments
Datasets
실험에는 두 가지 Remote sensing image-text retrieval 벤치마크 데이터셋이 사용되었다.
1. RSICD 데이터셋
10,921개의 이미지로 구성되어 있으며, 각 이미지에는 5개의 캡션이 제공된다.
- 학습용 7,862개
- 검증용 1,966 개
- 테스트용 1,093개
2. RSTIMD 데이터셋
4,743개의 이미지로 구성되어 있으며, RSICD보다 더 세분화된 텍스트 설명이 제공된다.
- 학습용 3,435개
- 검증용 856개
- 테스트용 452개
Metrics
실험에서 사용하는 평가 지표
- R@K : 상위 K개의 검색 결과 중 정답이 포함된 비율을 측정
- mR : R@1, R@5, R@10의 평균값으로, 전체 검색 성능을 종합적으로 평가한다.
Implementation Datails
- Vision encoder : Swin transformer를 사용하며, ImageNet 데이터셋에서 pre-trained된 Swin-T를 사용
- Text encoder : Bert를 사용하며, 공식 소스에서 제공하는 Bert-B의 pre-trained된 파라미터를 사용
- Instruction encoder : ResNet-50을 사용하며, AID 데이터셋에서 pre-trained된 모델 사용
Performance Comparisons
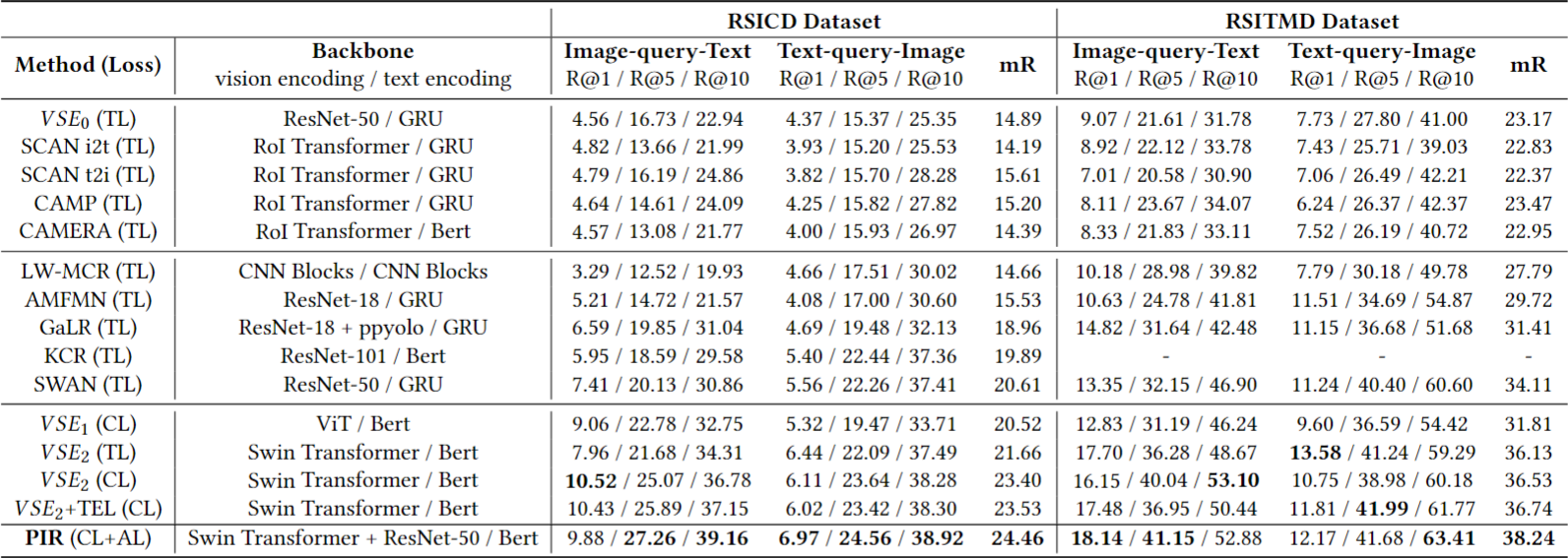
제안된 방법 PIR은 기존의 방법들과 비교하여 두 데이터셋에서 우수한 성능을 보였다.

비밀 댓글입니다.