Abstract
Remote sensing image-text retrieval은 위성이나 드론으로 수집된 대규모 원격 감지 데이터베이스에서 이미지와 텍스트 간의 매칭을 찾는 작업이다.
그러나, Remote sensing 이미지는 작은 object나 배경이나 관련 없는 object로 인해 Semantic noise에 취약하며, visual 및 text representation에 편향을 일으켜 검색 성능을 저하시킨다.
본 논문에서는 Prior Instruction Representation(PIR)이라는 새로운 학습 패러다임을 설계하여, Semantic noise 문제를 해결한다.
Instruction
RSITR은 이미지 또는 텍스트를 사용하여 대규모 Remote sensing database에서 일치하는 텍스트 또는 이미지를 검색하는 작업을 수행한다.
데이터베이스는 위성 또는 항공 드론을 통해 수집되었다.
RSITR의 training 패러다임에 따라 closed-domain 검색과 open-domain 검색으로 나눌 수 있다.
< Closed-domain retrieval >
단일 dataset에서 supervised training 방식으로 훈련 및 검색이 수행된다.
- 새로운 데이터셋에 대한 generalization 성능이 낮고, 복잡한 지형 요소를 검색하는 능력이 떨어지는 단점이 존재한다.
기존 Closed-domain retrieval은 주로 CNN 기반의 vision representation 및 RNN 기반의 text representation을 사용하며, pair-wise triplet loss를 통해 최적화된다.
< Open-domain retrieval >
대규모 데이터셋을 pre-training한 후, 작은 데이터셋에서 fine-tuning을 수행하는 방식이다.
이를 통해 정교한 ground element recognition(지형 요소 인식)이 가능하다.
- CLIP은 open domain retrieval에서 강력한 zero-shot 성능을 보였다
이후, Remote sensing에서의 여러 VLM을 구축하고 Image-text retrieval 성능을 향상시키는 데 집중하였다.이 모델들의 주요 목표는 Remote sensing 분야에서 foundation vlm을 구축하는 것이며, Remote sensing의 vision representation을 향상시키는 연구에는 focus를 맞추지 않았다.
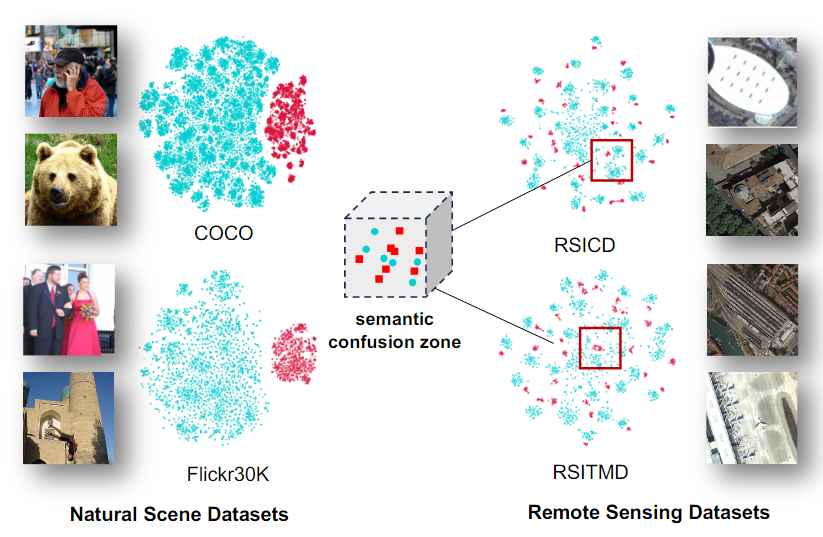
Natural Scene 데이터셋과 Remote sensing 데이터셋을 사용하여 subspace를 visualization한 것
- Natural scene의 subspace에서는 이미지와 텍스트 표현이 Remote sensing subspace보다 더 명확하게 분리된다.
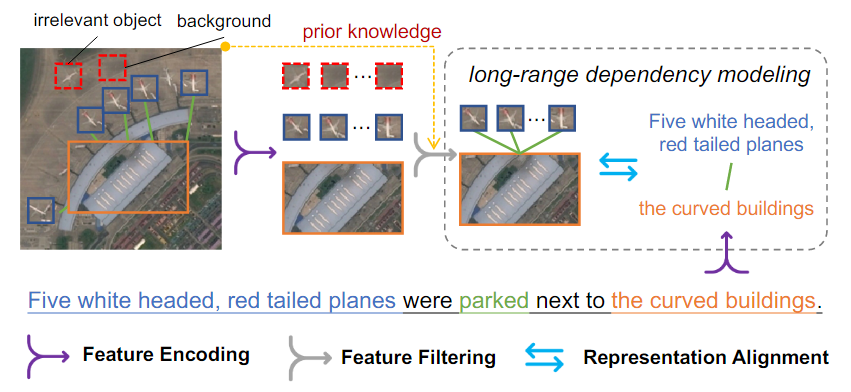
Natural 이미지와 다르게 Remote sensing 이미지의 작은 크기의 object는 Semantic noise의 영향을 더 많이 받는다.
Semantic noise : 배경, 관련없는 객체 등
Semantic noise에 대한 과도한 focus는 시각적 및 텍스트 표현을 왜곡시키고, semantic confusion zone을 초래하여 retrieval 성능에 큰 영향을 미친다.
이를 해결하기 위한 여러 연구가 존재하였다.
- Redundant feature filtering network
불필요한 정보를 제거하는 필터링 기법
- Scene-aware aggregation network
Scene의 전반적인 구조를 인식해 confusion zone을 줄이는 방법
그러나, 이러한 방법들은 CNN-based vision representation 및 RNN-based text representation에 의존하고 있으며 long-range dependency modeling 및 remote sensing 데이터 증가에 효과적이지 않았다.
Transformer가 CV 및 NLP에서 강력한 성능을 보이며, Transformer 기반의 시각 및 텍스트 표현이 검색 성능을 더욱 향상시킬 수 있다.
하지만, Transformer를 기반으로 feature를 추출하는 방식을 사용하였는데, 이 방법은 Remote sensing 데이터의 특성을 완전히 반영하지 못해, 검색 성능 향상이 제한적이다.
따라서, Remote sensing 데이터에 특화된 framework가 필요하다
이 논문은 Prior instruction representation을 제안하여 Semantic noise를 줄이고자 한다.
1. PIR-ITR : Closed-domain retrieval용
PIR-ITR은 Remote sensing scene recognition의 prior knowledge을 활용하여 장기 의존성 모델링을 수행하도록 설계되었다.
이를 통해 unbiased한 시각 및 텍스트 표현을 보장한다.
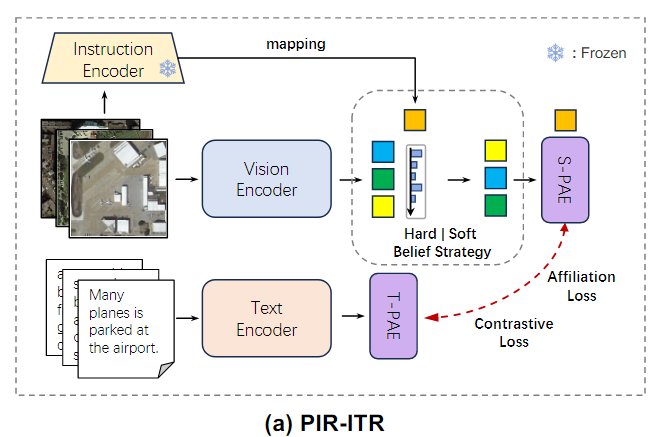
두 가지 Progressive attention encoder 구조를 도입하여 장기 의존성 모델링을 수행하고 주요 특징 표현을 향상시킨다.
- Spatial-PAE : 외부 지식을 활용하여 visual-spatial perception을 향상시킨다.
- Temporal-PAE : Previous time step을 활용하여 현재 time step을 cyclically activate 함으로써 position information의 부정확성을 줄인다.
추가적으로, Remote sensing 데이터는 클래스간 semantic similarity가 높아 혼동되는 경우가 많아, Cluster-wise attribution loss를 통해 클래스 간 semantic confusion을 줄이고 검색 성능을 향상시킨다.
2. PIR-CLIP : Open-domain retrieval용
이 논문에서는 PIR을 기반으로 한 2단계 CLIP 기반 method인 PIR-CLIP을 제안하여, Remote sensing vision-text representation의 Semantic noise문제를 해결하고, open-domain image-text retrieval성능을 향상시킨다.
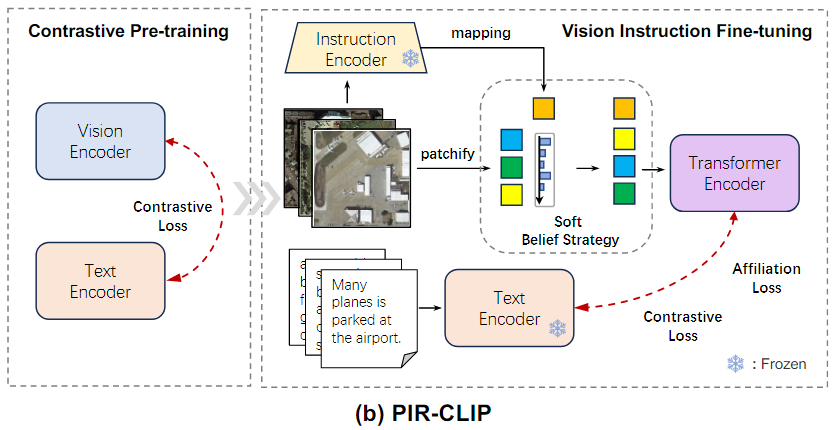
PIR-ITR보다 더 높은 검색 성능을 보여준다
Related work
Remote Sensing Image-Text Retrieval
Closed-domain Method
Closed-domain method는 단일 데이터셋에서 supervised learning으로 training 및 retrieval을 수행하는 방식이다.
이 방법은 단순한 환경에서는 효과적이지만, 복잡한 지형 요소를 검색하는 데 한계가 존재한다.
<기존 연구들의 접근 방식>
-
Self-Interaction
동일한 모달리티 내에서만 상호작용하여 modal semantic representation을 강화
-
multi-modality fusion
서로 다른 모달리티의 정보를 결합하여 공동 semantic representaion을 얻음
-
Global&Local information fusion
Attention 기반 모듈을 사용하여 다층 정보를 동적으로 fusion
이러한 방법들은 실제 Remote sensin 환경의 복잡성을 충분히 반영하지 못하고, 세밀한 인식 학습에 실패하였다.
Open-domain Method
Open-domain Method는 대규모 데이터셋에서 pre-training한 후, 특정 데이터셋에서 fine-tuning을 통해 성능을 개선하는 방식이다.
CLIP이 등장하면서, Remote sensing 분야에서도 CLIP을 활용한 다양한 연구가 진행되었다.
<기존 연구들의 접근 방식>
-
RemoteCLIP
최초의 Remote sensing VLM으로, 언어 기반 검색 및 Zero-shot 검색을 가능하게 함
-
GeoRSCLIP
500만 개 이상의 Remote sensing image-text 데이터셋(RS5M)을 구축하고, 지리 정보를 활용하여 GeoRSCLIP 모델을 학습했다.
-
SkyCLIP
새로운 Remote sensing 데이터셋인 SkyScript 및 SkyCLIP 모델을 개발
그러나, 이 모델들은 Remote sensing 데이터를 위한 foundation 모델을 구축하는 데 초점을 맞추었으며, visual representation을 향상시키는 방법을 깊이 연구하지 않았다.
따라서, CLIP을 기반으로 한 새로운 모델을 개발하여, Remote sensing open-domain retrieval 성능을 향상시키는 것이 목표이다.
Cross-Attention Mechanism
Cross-Attention은 transformer 아키텍처에서 두 개의 서로 다른 embedding sequence를 혼합하는 Attention mechanism이다.
이 두 개의 embedding sequence는 서로 다른 modality에서 오거나, 서로 다른 output에서 생성될 수 있다.
-
Stacked Cross Attention
이미지와 문장 간의 Contextual Attention을 제공하는 방법을 제안하여 이미지와 문장 간의 관계를 더욱 효과적으로 학습할 수 있도록 함
-
Multi-Modality Cross Attention Network
이미지와 문장을 정렬하는 네트워크를 개발하여 단일 딥러닝 모델에서 모달리티 간, 또는 모달리티 내부의 관계를 학습할 수 있다
-
CASC Framework
다중 레이블 prediction과 local alignment를 결합한 cross modal attention 모델로 global semantic consistency를 유지하는 방식을 제안
-
Plug-and-Play Regulators
자동으로 cross-modal representation을 contextualize하고 aggregate할 수 있는 regulator를 개발
기존 연구들은 특정 문제에 맞춰 최적화 되어 있어 범용성이 부족하다.
보다 범용적(Universal)이고 쉽게 조정가능한(Adjustable) Cross-Attention 구조가 필요하다.
Remote Sensing Image-Text Retrieval
Generic Image and Text Encoding(일반적인 이미지-텍스트 인코딩)
Remote sensing image를 해석하는 한 가지 방법은 이미지와 텍스트를 의미적(semantically)으로 align하는 것이다.
Remote sensing image-text retrieval은 이러한 image-text alignment를 위한 기술이다.
일반적으로, visual 및 text encoder를 통해 feature를 encoding한 후, 공통되는 semantic space에서 align하는 방식을 따른다.
RSITR에서는 CNN 및 Transformer 기반 image encoder가 이미지 feature를 추출하는 데 사용된다.
이미지 인코딩 과정
- RGB형식의 이미지
- Image encoder 를 사용하여 feature를 추출
- 이를 통해 Global() 및 Local feature() 생성
- : Global feature
- : Local feature
- : Fine-tuning 가중치
- : Squence 길이 dimension을 따라 Concatenate
CNN VS Transformer
- CNN 기반 Image encoder
- 는 고수준 특징(Global feature)
- 는 저수준 특징 집합(Local feature)
- Transformer 기반 Image encoder
- CNN 보다 Long range dependency를 효과적으로 학습
텍스트 인코딩 과정
- 주어진 입력 텍스트
- 텍스트 인코더 를 사용하여 feature를 추출
- 이미지와 마찬가지로 Global() 및 Local feature()를 생성
- : Global feature
- : Local feature
- : fine-tuning 가중치
RNN VS Transformer
- RNN 기반 Text encoder
Global feature 는 주로 Local feautre 의 Average pooling으로 생성됨
- Transformer 기반 Text encoder
입력 Sequence의 모든 position을 동시에 고려하여 관계를 학습
Various Image-Text Alignment
Image와 Text 간의 Alignment를 달성하는 간단한 방법은 Vision 및 Text encoder의 파라미터를 Learnable한 가중치()로 fine-tuning하여 Global feature
()를 align하는 것이다.
가중치들을 미세 조정(fine-tuning)하여, 모델이 이미지-텍스트 정렬에 더 잘 적응하도록 하여 두 인코더의 출력(특징 벡터)을 정렬하여 이미지와 텍스트가 서로 매칭되는지 확인
대표적인 방법으로 Visual Semantic Embedding(VSE)이 있다.
이미지와 텍스트 공통 semantic space에 매핑하여 정렬
이 방법은 COCO와 같은 General한 Image-text pair가 많은 데이터셋에서는 좋은 성능을 발휘한다.
하지만, Remote sensing 이미지는 일반 이미지와 다르다.
- 위성 사진은 Semantic noise가 많고 지형과 Object가 다양하고 정밀한 정렬이 어렵다.
기존 방법의 성능 및 한계
SCAN, CAMP, CAMERA와 같은 방법들은 Image와 Text 간의 feature level 상호작용을 도입하였으나 Remote sensing 데이터의 복잡성을 충분히 반영하지 못했다.
<문제점>
- Remote sensing 이미지의 규모가 다양하다.
- 데이터가 방대하여 Redundant information이 많이 포함되어 있다.
- Semantic consistency를 이루는 것이 어렵다.
Remote sensing 이미지를 위한 개선된 방법
- Multi-scale feature fusion(다중 스케일 특징 융합)
AMFMN, SWAN 같은 방법은 Global, Local feature를 multi-scale로 fusion한다.
multi-scale로 fusion?
Global feature와 Local feauture를 fusion하여 이미지를 더 정밀하게 이해하는 방법
- Global feature만 사용하면 이미지의 전체적인 의미는 파악할 수 있으나, 세부적인 정보가 부족하다
- Local feature만 사용하면 세부적인 정보는 알 수 있지만, 전체 맥락을 놓칠 수 있다.
Remote sensing 이미지에서 중요한 feature를 추출하고 Semantic noise를 줄이는 효과를 얻을 수 있다.
- Graph-based models(그래프 기반 모델)
GaLR은 Local visual feature()와 그래프 합성곱 신경망 GCN을 통해 처리된 외부 Object-level knowledge()를 결합한다.
Graph-based model?
Remote sensing 이미지는 복잡한 구조와 다양한 객체들이 포함되어 있어, 단순히 Global, Local feature 만으로는 복잡한 관계를 이해하기 어렵다.이미지의 object들(Node)과 External object-level knowledge(Edge)를 활용하여 object간의 관계를 학습한다.
- : Local visual feature
- : External object-level knowledge
Feature level 상호작용을 통해 정밀한 정렬 시도
<요약>
기존 방법들은 일반적인 Image-text retrieval에서는 효과적이지만 Remote sensing 데이터에서는 정밀한 alignment를 이루는 데 한계가 존재
Remote sensing 이미지는 Semantic noise가 많고, 다양한 스케일의 데이터가 존재하기 때문에 Multi-scalue fusion 및 Graph-based model이 필요하다.
Prior Instruction Representation Learning
Preliminaries
Remote sensing 이미지에는 많은 Semantic noise가 존재하여, Visual semantic representation에 편향을 발생시킨다.
기존 방법에서는 추가적인 Prompts또는 Instructoin을 도입하여 모델이 더 나은 representation을 학습하도록 유도하였다.
이러한 방법에 영감을 받아, AID 데이터셋에서 Pre-train된 ResNet을 Instruction encoder로 사용한다.
- 는 Pre-trained 가중치로, 이를 통해 Instruction embedding을 추출한다.
- 공간에서 embedding이 표현된다.
GaLR과의 차이점
GaLR은 Local visual feature()와 그래프 합성곱 신경망(GCN)으로 처리된 External object-level knowledge을 통합한다.
하지만, GaLR의 feature fusion은 이미지의 고유 representation에 영향을 줄 수 있다.
PIR의 차이점
GaLR과 달리, PIR은 Instruction embedding을 사용하여 Visual feature representation을 보조한다.
지시문 의 도움을 받아 편향되지 않은 visual representation을 전역 특징과 지역 특징으로부터 필터링하는 것이 목표
External object-level knowledge vs Instruction embedding
- External object-level knowledge
이미지 외부에서 얻어지는 지식으로 Object 간의 관계나 일반적인 특성을 나타내어 이미지 속 object에 대한 추가적인 정보를 제공한다.
GCN은 외부 지식을 통해 object간의 관계를 학습하여 더 나은 검색 accuracy를 달성한다.
객체 간의 관계를 관계를 강화하는 것이 목적
- Instruction embedding
모델 학습 과정에서 사전 학습된 모델 또는 모델 내부에서 생성된 지시문을 임베딩 형태로 변환한 것으로 모델이 어떤 특징에 집중해야 하는지를 유도하는 학습 가이드라인이다.
Instruction embedding은 이미지 인코딩 과정에서 visual feature의 표현 방식을 조정하는 데 사용되어 더 나은 visual representation을 학습하도록 지원한다
모델 학습의 방향성을 유도하여 편향 없는 표현을 학습하는 것이 목적
Belief Strategy
Belief strategy는 Instruction embedding을 사용하여 belief matrix를 구축한 후 feature를 필터링하여 편향되지 않은 visual representation을 달성한다.
신뢰 전략은 모델이 어떤 시각적 특징(Visual Features)에 더 집중해야 하는지를 Instruction Embeddings을 통해 유도한다
Remote sensing 장면 인식의 사전 지식 는 Local feature에 대한 belief matrix를 계산하는 데 사용된다.
1. Belief matrix 생성
Instruction embedding과 Local feature 를 결합하여 계산한다.
결합하는 방법은 나와있지 않으나, 내적, Attention 메커니즘을 사용할 수 있을 것으로 추측
이 행렬은 각 특징의 중요도를 나타내는 점수를 제공
2. 시각적 특징 정렬 및 필터링
이후, 신뢰 행렬의 점수를 기반으로 특징을 정렬하고, 필터링하여 상위 k개의 특징만 선택
- 중요한 특징만 선택하여, 덜 중요한 정보는 제거
이 방식은 경험적으로 설정된 k값에 의존하며, 선택된 특징 수가 고정되어 있다.
- 실제 상황에서는 정확히 몇 개의 특징을 사용할지 미리 정하기 어렵다
특징을 동적으로 필터링할 수 있도록 Soft belief strategy를 제안
Soft belief strategy
순위 기반 방식으로 각 특징의 상대적인 중요도를 계산한다.
- 는 Soft belief strategy에서의 feature의 순위를 계산한다.
- 지표함수 는 조건이 참이면 1, 거짓이면 0을 반환하여 특징의 순위를 결정한다.
마지막으로, 계산된 신뢰 행렬 점수와 랭킹 점수를 사용하여 각 visual feature에 가중치를 부여한다.
- Belief matrix 과 순위 기반 가중치 를 통해 각 특징에 가중치를 부여한다.
중요한 특징에 더 높은 가중치를 부여하여 편향되지 않은 visual feature를 생성한다.
Image-Text Alignment with PIR Learning
Progressive Attention Encoder Layer
TEL(Transformer Encoder Layer)을 기반으로 한 Progressive Attention Encoder Layer를 설계하였으며, 이 layer는 self-attention과 cross-attetion을 통합한다.
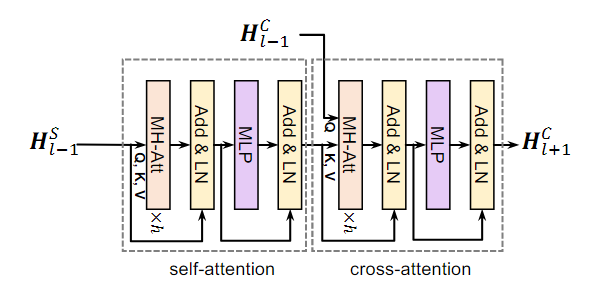
두 개의 서로 다른 시퀀스가 주어졌을 때
Self-Attention
시퀀스 에 multi-head attention을 적용하고 레이어 정규화를 통해 정규화한 결과에 를 더한다
FFN
MLP를 통해 시퀀스를 FFN으로 처리한 후, 레이어 정규화한 결과에 을 더한다
Cross-Attention
시퀀스 에 시퀀스 를 병합하여 MHA를 적용하고 레이어 정규화를 수행한 결과에 를 더한다
FFN
시퀀스를 MLP를 통해 처리한 후 레이어 정규화를 수행한 결과에 를 더해 최종 시퀀스를 만든다
Progressive Attention Encoder Layer의 계산은 로 정의할 수 있다
Progressive Attention Encoder
PAEL간의 메시지 전송을 위한 두 가지 구별된 방법을 개발하였다.
- Spatial-PAE
- Temporal-PAE
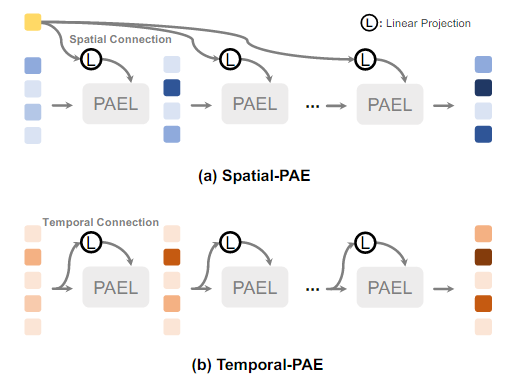
Spatial-PAE
외부 정보로부터 입력 시퀀스에 linear projection을 통해 Spatial connection을 설정한다.
fusion based 방법과 달리 Cross-attention에 의존한다.
Fusion based 방식은 다양한 데이터 소스를 단순히 결합하여 특징을 추출하는 방식으로 Concatenation을 사용
외부 정보 로 활성화된 필터링된 특징에 대한 장거리 의존 관계를 모델링한다.
- : i번째 PAEL의 output이다.
- : 초기 local visual feature
- : i번째 linear projection(선형 변환)의 가중치
편향되지 않은 임베딩을 얻기 위해, local embedding을 계산한다.
- : TEL의 마지막 layer에서 중요한 정보를 추출하는 모듈(마지막 layer의 head embedding을 편향되지 않은 embedding으로 매핑)
이후, 편향되지 않은 임베딩과 global feature를 결합하여 최종 visual embedding을 얻는다.
Temporal-PAE
이전 시간 단계(Previous Time Step)로부터의 입력 시퀀스에 Linear Projection을 통해 시간적 연결(Temporal Connection)을 설정한다
TEL에서는 Positional encoding이 시퀀스 내의 위치 관계를 효과적으로 반영하지 못할 수 있다.
- : i번째 PAEL의 output이다.
- : 초기 Text sequence
- : i번째 linear projection의 가중치
이후, 편향되지 않은 local embedding을 계산한다.
- : TEL의 마지막 layer에서 중요한 정보를 추출하는 모듈(마지막 layer의 head embedding을 편향되지 않은 embedding으로 매핑)
마지막으로, 편향되지 않은 임베딩과 global feature를 결합하여 최종 ㅅtext embedding을 얻는다.
PIR-ITR and PIR-CLIP
PIR-ITR
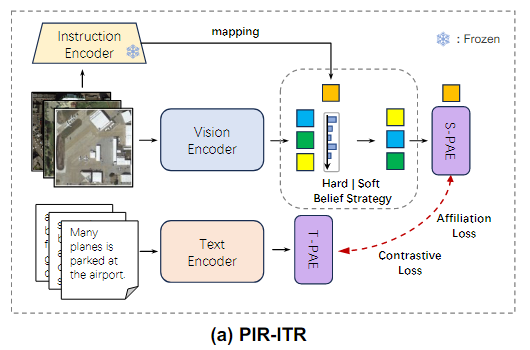
PIR-ITR의 hard belief strategy을 계승하여 soft belief strategy를 설계했다.
1. 이미지-텍스트 쌍 생성
Remote sensing 데이터셋 로부터 Image-text pair의 positive sample을 수집한다
2. feature encoding
이미지와 텍스트를 각각 인코딩한다
- : Global/Local visual feature
- : Instruction embedding
- : Global/Local text feature
3. Belief matrix 및 순위 계산
Visual feature와 Instruction embedding을 이용하여 Belief matrix ()를 계산하고 각 요소에 대한 순위 를 산출한다.
각 특징의 중요도를 평가하여 순위 기반 visual feature()를 생성한다.
4. Spatial-PAE & Temporal-PAE 적용
Spatial-PAE를 사용하여 공간적 특징(Spatial Features)을 강화하고,
Temporal-PAE를 통해 시간적 관계(Temporal Relationships)를 보완한다.
5. 최종 임베딩 (Final Embedding)
최종 visual embedding()와 최종 text embedding()를 얻는다.
<PIR-ITR의 특징>
- 복잡하고 큰 구조로 인해 대규모 데이터 학습에 어려움이 있고 Spatial-PAE와 Temporal-PAE같은 추가 모듈이 필요하여 training cost가 증가한다.
PIR-CLIP
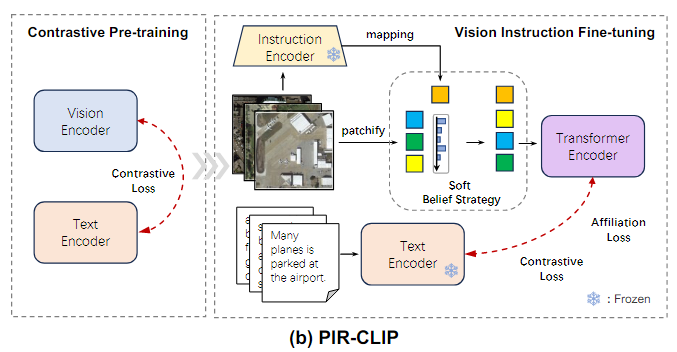
PIR-CLIP은 CLIP 모델을 기반으로하여 PIR 학습을 적용해 Remote sensing image-text retrieval 성능을 개선한 방법이다.
1. RS5M 데이터셋 사전 학습 (Pre-training on RS5M Dataset)
CLIP을 사용하여 RS5M 데이터셋에서
대조 손실(Contrastive Loss)로 사전 학습(Pre-training)을 수행한다
RS5M 데이터셋이라는 큰 데이터로 이미지와 텍스트를 미리 학습한다
- 입력 데이터 : Remote sensing image, text description
시각 인코더와 텍스트 인코더의 출력은 공통 임베딩 공간(shared embedding space)에 매핑.
이때, 대조 손실(contrastive loss)을 통해 올바른 이미지-텍스트 쌍은 가까이 위치하고, 잘못된 쌍은 멀리 떨어지도록 학습
2. 세부 조정 (Fine-Tuning)
이후, RSITR 데이터셋에서 시각적 표현(Visual Representation)을 세부 조정(Fine-Tune)한다.
이후, 실제 위성 이미지 데이터로 미세 조정을 해서 더 정확하게 만든다
-
앞서, Pre-trained된 ResNet을 Instruction encoder로 Remote sensing image의 instruction embedding 추출
-
이미지를 작은 패치로 나눠, 앞서 Pre-trained된 ViT에 입력하여 visual feature 추출한다.
ViT 구조 수정 (ViT Structure Modification)
- PIR-CLIP의 ViT는 Patching을 위해 Convolution을 사용하여 ViT 구조를 수정한다.
- Connvolution을 적용하여 Spatial-PAE 없이도 패치 간 공간적 관계를 더 잘 포착하고 더 세밀하게 이미지 특징을 파악할 수 있다
-
Instruction encoder를 통해 얻은 embedding을 기반으로 Soft belief strategy를 실시
PIR-ITR과의 차이점 (Differences from PIR-ITR)
- 1. 시각적 백본(Visual Backbone) 변경
기존의 단순한 CNN encoder 대신 ViT(Vision Transformer)와 ResNet 모델로 시각적 백본을 업데이트한다.- 2. 텍스트 인코더 변경
텍스트 인코더는 대규모 Remote sensing 데이터셋으로 훈련된 Language Transformer로 교체한다.
- 최종 프로세스 (Final Process)
소프트 신뢰 전략(Soft Belief Strategy)을 적용한 후,
트랜스포머 인코더(Transformer Encoder)를 통해
시각적 특징(Visual Features)과 지시문 특징(Instructional Features) 간의 상호작용을 강화한다.
3. 최종 손실 계산 및 모델 최적화
대조 손실(contrastive loss)과 소속 손실(affiliation loss)을 결합하여 모델을 최적화합니다
<PIR-CLIP의 특징>
- 대규모 데이터셋에 적합하도록 설계되어 효율적으로 빠른 학습이 가능하다.
- PIR-ITR에 비행 추가적인 Spatial-PAE가 필요하지 않고 더 간단한 구조로 작동한다.
Loss Function
Contrastive Loss
1. 임베딩된 벡터 (Embedded Vectors)
PIR-ITR 또는 PIR-CLIP을 통해 임베딩된 이미지 임베딩 와 텍스트 임베딩 를 사용한다.
2. 코사인 유사도 계산
배치 이미지-텍스트 쌍에서 코사인 유사도(Cosine Similarity)를 계산
- 는 i번째 이미지와 j번재 텍스트의 유사도이다.
3. 대조 손실 공식 (Contrastive Loss Formula)
최종적으로 Contrastive Loss를 계산한다.
- : Temperature parameter로 모델이 유사도 분포를 얼마나 부드럽게 만들지 결정한다.
Affiliation Loss
Remote sensing 데이터의 분포 특성을 활용하여, 각 모달리티와 해당 소속 카테고리의 cluster center 간의 거리를 최소화한다
1. 미니 배치 샘플(Mini-Batch Sample) 분류
미니 배치 샘플을 장면 카테고리 정보(Scene Category Information)에 따라 C개의 클래스(Class)로 분류
2. 양의 쌍(Positive Pairs) 생성
각 이미지에 대해, 해당하는 텍스트를 하나의 카테고리로 그룹화하여
양의 쌍을 생성
는 i번째 텍스트에 해당하는 Cluster center를 나타냄
3. 코사인 유사도 계산 (Cosine Similarity Calculation)
- 시각-텍스트 유사도(Vision-to-Text Similarity)
- 텍스트-시각 유사도(Text-to-Vision Similarity)
<소속 손실 공식 (Affiliation Loss Formula>
- : Temperature parameter로 모델이 유사도 분포를 얼마나 부드럽게 만들지 결정한다.
최종 Loss Fuction
최종 손실 함수는 대조 손실(Contrastive Loss)과 소속 손실(Affiliation Loss)을 결합
는 중심 척도(Center Scale)로, 카테고리 중심(Category Center)에서의 클러스터링 정도를 나타냄
Experiments
Dateset
1. RSICD
RSICD는 10,921개의 이미지로 구성되어 있으며, 해상도는 224 × 224이다.
각 이미지에는 5개의 캡션(captions)이 제공
2. RSIRMD
RSITMD는 4,743개의 이미지로 구성되어 있으며, 해상도는 256 × 256이다.
이 데이터셋은 RSICD보다 5배 더 세밀한(fine-grained) 캡션을 제공
Metric
1. R@K (Recall@K)
K개의 검색 결과 중 정확하게 일치한 쌍의 비율을 측정
K=1,5,10으로 설정
2. mR (mean Recall)
다양한 R@K 값의 평균을 계산하여, 검색 성능(retrieval performance)의 전반적인 평가를 제공
Implementation Details
Closed-domain Retrieval
- Swin Transformer를 시각 인코더로 사용하며, ImageNet으로 사전 학습된 Swin-T (tiny version)을 적용
- 텍스트 인코더로는 BERT-B를 사용
Open-domain Retrieval
- ResNet-50 (AID 데이터셋으로 사전 학습된)을 Instruction Encoder로 사용
- 개방형 검색을 위해, ResNet-50 + ViT-B 및 Transformer를
CLIP의 시각 및 텍스트 백본으로 사용하여 정렬
Results
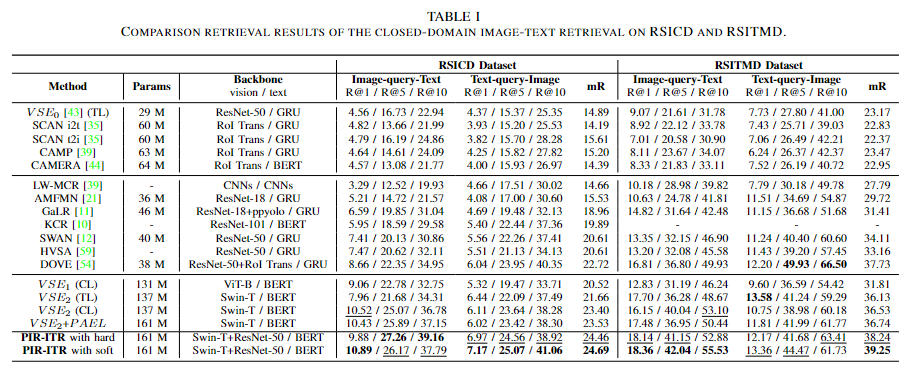
Closed-domain Image-Text Retrieval
Open-domain Image-Text Retrieval

