Abstract
양자화는 연속적인 실수 값의 집합인 신경망의 가중치 및 활성화 값을 이산 값으로 변환하여, 사용 비트 수를 줄이면서도 연산 정확도를 최대한 유지하는 기법이다.
메모리 용량이나 연산 능력이 제한된 환경에서 필수적인 기술
부동소수점 표현(float32, float16)에서 4비트 이하의 고정 정수 표현으로 전환할 경우, 이론상 메모리 사용과 지연 시간을 최대 16배까지 줄일 수 있으며, 이러한 효율성 개선은 배터리 수명 연장, 실시간 처리, 비용 절감 등 다양한 이점이 있다.
Introduction
지금까지 Overparameterized된 모델을 통해 다양한 문제에 대한 신경망의 정확도가 크게 향상되었다.
그러나, 과도하게 큰 신경망 모델은 그 크기 때문에 자원의 제약이 있는 환경에 배포하기가 어렵다.
효율적이고 실시간으로 동작하면서도 최적의 정확도를 유지하려면, 신경망 모델의 설계, 학습, 배포 방식을 고려해야 한다.
현재까지 많은 연구가 Latency, 메모리 사용량, 에너지 소비 등을 줄이면서도 정확도와 일반화 성능을 최적화하는 데 초점을 맞춰왔다.
1. 효율적인 신경망 모델 아키텍처 설계
- 아키텍처를 최적화 하는 연구
- 초기에는 수작업 탐색을 통해 새로운 최적 모듈을 찾아으나, 최근에는 AutoML, NAS를 통해 모델 크기, 깊이, 넓이 제약 하에서 최적 아키텍처를 자동으로 탐색
2. 신경망 아키텍처와 하드웨어의 공동 설계
- 신경망의 Latency와 에너지 오버헤드는 하드웨어에 따라 다르므로, 특정 하드웨어에 최적화된 아키텍처를 함계 설계하는 연구 활발
3. Pruning
- 중요도가 낮은 뉴런, 파라미터를 제거해 sparsity를 높이는 방법이다.
- Unstructured pruning은 임의 위치의 파라미터를 제거해 모델의 일반화 성능에 거의 영향을 주지 않으면서 높은 희소율을 달성하지만, 희소 행렬 연산으로 인해 메모리를 많이 사용하여 가속이 어렵다.
- Structured pruning은 모듈 단위로 제거해 밀집 연산은 유지하지만, 과도한 pruning 시 정확도 저하가 크다.
4. Knowledge distillation
- 고성능 대형 모델(teacher)가 생성한 soft label(확률 분포)를, 소형 모델(student) 학습에 활용
- 단독 distillation으로는 높은 compression이 어렵지만, 양자화, pruning과 결합하면 성능 저하 없이 compression을 크게 늘릴 수 있다.
5. Quantization
- 부동소수점 표현에서 8비트 이하의 저정밀 정수 표현으로 전환하면, 학습과 추론 모두에서 메모리, 지연 시간을 크게 줄일 수 있다.
- 특히 반정밀도(half-precision), 혼합 정밀도(mixed-precision) 학습의 도입은 AI 가속기 처리량을 획기적으로 향상시켰으나, 8비트 이하로 내리려면 섬세한 튜닝이 필요해 최근 연구는 주로 추론에 집중된다.
6. 뇌과학 관점의 Quantization
- 인간의 뇌가 연속값이 아닌 불연속(양자화) 신호로 저장한다는 연구가 있으며, 이는 noise에 강하고 자원 효율이 높다는 장점 때문이다.
개념 정리
FP, INT
Floating point(FP)와 int(정수)형 표현의 큰 차이는 숫자를 내부에서 어떻게 표현하고 연산하느냐이다.
부동소수점(FP)는 아주 크거나 작은 수를 지수, 가수 조합으로 표현
정수(INT)는 소수점 없이 고정된 정밀도로 정수 범위만큼 표현
부동소수점(FP)는 부호(Sign), 지수(Exponent), 가수(Fraction)으로 구성되어 있다.
-
부호 : 값이 양수인지(0), 음수인지(1)를 나타낸다.
ex) 0 10000001 ... -> 양수 / 1 10000001 ... -> 음수
-
지수 : Exponetial(스케일)을 의미하며, 보통 에서 를 의미한다.
예를 들어, 314.0을 FP로 표현한다면 가 되며, 여기서 지수(Exponential)은 2가 되고, 가수(유효 숫자)는 3.14가 된다.
-
가수 : 1.xxxx 형태의 소수부(유효 숫자)를 저장한다.
FP 표기법은 유효숫자 지수 표기로 생각하면 됨
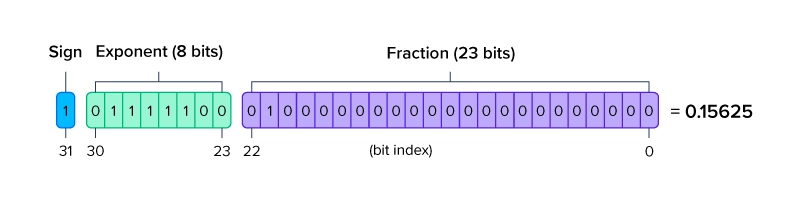
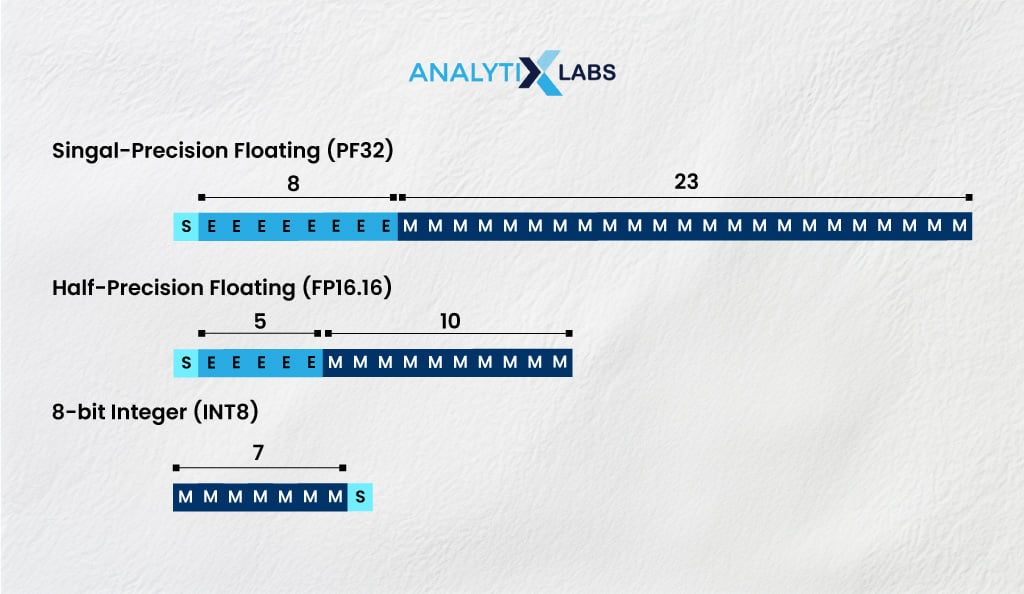
FP32
- 비트 수 : 32bit(부호 1비트 + 지수 8비트 + 가수 23비트)
- 정밀도 : 약 7자리 십진수
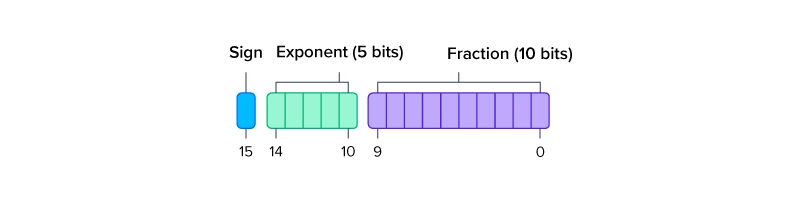
FP16
- 비트 수 : 16bit(부호 1비트 + 지수 5비트 + 가수 10비트)
- 정밀도 : 약 3~4자리 십진수
INT8
- 비트 수 : 8bit(부호 1비트 + 값 7비트)
- 정밀도 : 정수 단위
메모리 절약
같은 개수의 숫자를 저장할 때
- FP32 : 4바이트(32비트)
- FP16 : 2바이트(16비트)
- INT16 : 2바이트(16비트)
- INT8 : 1바이트(8비트)
메모리 측면에서는 FP16과 INT16 둘 다 2바이트로 같은 개수의 값을 저장할 때 차이가 없고, 표현 방식의 차이만 존재한다.
예를 들어, 파라미터 1억 개를 저장하면
FP32는 4바이트 x 1e8 = 약 400MB
INT8은 1바이트 x 1e8 = 약 100MB (1/4 크기)
따라서, 비트 수가 적을수록 메모리 사용량이 줄어든다.
연산 속도 원리
1. 하드웨어 복잡도
FP 연산
- 덧셈, 곱셈 시 지수부 정렬, 가수 정규화, 오버플로우/언더플로우 검사 등이 필요
- 논리적으로 복잡하여 더 많은 사이클과 더 큰 전력을 소모한다.
INT 연산
- 비트가 단순하여 덧셈, 곱셈만 수행한다
- 회로가 단순하고 빠르다
2. SIMD 최적화
- INT형 연산은 CPU/GPU에서 한 번에 더 많은 요소를 병렬 처리 가능하여 한 사이클에 더 많은 연산을 처리할 수 있다.
3. 메모리 대역폭
- 전송 데이터량이 줄어들어 메모리 병목 상황에서 이득이고, 이동이 빠르다.
정확도 vs 효율성 Trade-off
- FP32 : 가장 넓은 범위의 높은 정밀도
- FP16 : FP32 대비 2배 빠르고 메모리는 절반이나, 지수, 가수 비트가 줄어들어 아주 작은 값 구분이 어려움
- INT8 : FP16 대비 2배 빠르고 메모리는 절반이나, 정밀도는 소수점 단위를 모두 버려 근사치가 크게 어긋날 수 있다.
General History of Quantization
1. 초기 수치 근사 기법으로서의 양자화
양자화는 크기가 무한하거나 연속적인 값을 유한한 범위의 정수나 이산 값으로 근사할 때 사용된다.
19세기 중반부터 수치 적분 등을 위해 이산화를 이용했으며, 반올림 오차가 적분 결과에 미치는 영향을 연구했다.
즉, 반올림과 절단은 모두 양자화의 전형적 사례로, 컴퓨터가 등장하기 전에도 수치 해법에서 중요한 요소였다.
2. 정보 이론과 통신에서의 양자화 발전
1928년 정보 이론을 발표하면서, 양자화는 부호화 이론의 핵심으로 떠올랐다.
Shannon은 가변 비트 길이를 서서 효율적으로 부호를 할당하는 가변률 양자화 개념을 도입했다.
1959년에는 왜곡률과 비트율 간의 최적 절충을 다루는 왜곡률 함수와 벡터 양자화가 제안되었으며, 이후 다양한 통신 시스템과 신호 처리에 응용되었다.
3. 수치해석 관점에서의 양자화
수치해석에서는 연속 문제를 유한 비트로 다룰 때 발생하는 반올림 오차와 절단 오차가 알고리즘의 정확도와 안정성에 큰 영향을 준다.
이 두 오차는 문제의 조건수에 의해 서로 연관되며, 높은 조건수는 작은 입력 오차가 큰 출력 오차로 증폭될 수 있음을 의미한다.
양자화는 초기 수치 근사 → 정보 이론/통신의 부호화 → 수치해석의 안정성 분석의 흐름으로 발전해 왔으며, 각 분야에서 요구하는 성능에 맞춰 다양한 이론과 기법이 정립되었다.
Quantization in Neural Nets
위 주제에 관해 많은 수의 논문이 발표되었으며, 많은 사람들이 최근의 신경망 양자화 연구가 과거 연구와 어떻게 다른지 궁금해한다.
1. 계산 집약적인 신경망 inference, training 환경
전통적인 신호 처리나 수치해석에서는 계산량이 한정적이거나, 오프라인으로 처리하는 경우가 많았지만,
신경망은 inference와 training 모두 초대형 행렬 연산을 수백만 번 수행하므로, 메모리 대역폭과 연산량이 곧 실시간 성능과 직결된다.
값을 얼마나 효율적으로 표현하느냐가 신경망 전체 속도, 전력 효율을 크게 좌우한다.
2. Over-paramerization으로 인한 자유도
대부분의 현대 신경망은 수천만~수억 개의 파라미터를 갖고 있어, 원래 모델은 정확도를 조금 희생해도 파라미터를 줄이거나 비트폭을 낮춰도 성능이 크게 떨어지지 않는다.
이러한 과파라미터 구조 덕분에, 8비트, 4비트 같은 공격적인 양자화도 가능해졌고, 정확도나 복잡도 같은 지표를 잘 유지할 수 있다.
3. 순방향 오차 중심의 평가
전통적인 양자화 연구는 주로 신호 왜곡을 수치적으로 제어하면서 정확한 계산과 이산 계산 간 차이를 최소화하는 데 초점이 맞춰져 있었다.
하지만, 신경망 양자화에서는 이산화된 모델이 실제로 얼마나 잘 분류, 생성하느냐가 관심사이다.
4. 계층별 영향도를 활용한 혼합 정밀도(mixed-precision)
신경망 내부에서도 각 layer가 loss에 기여하는 정도는 다르다.
이를 활용해 중요한 layer는 8비트, 덜 민감한 layer는 4비트처럼 layer-wise로 다른 비트폭을 사용하는 mixed-precision 전략이 효과적이다.
위 4가지가 과거 연구와 달리 신경망 양자화가 갖고있는 고유한 차별점이다.
Basic Concepts of Quantization
A. Problem Setup and Notations
개의 layer를 가진 신경망(Neural Network)이 각 layer마다 학습 가능한 파라미터 를 가지며, 이들의 전체 조합을 라 칭한다.
Supervised learning에서 최적화해야 할 empirical risk minimization(경험적 위험 최소화)은 다음과 같다.
- Train data 에 대해 평균 loss 를 최소화하도록 를 학습
- Loss function 은 task에 따라 MSE, Cross Entropy 등 사용
- 는 입력 데이터와 그에 대응하는 정답 label(Supervised learning)
- : 전체 데이터 포인트 수
또한, 번째 layer의 input hidden activation을 , output hidden activation을 로 정의해 둔다.
현대의 Neural network는 크고 복잡하며, 32비트 부동소수점으로 pre-training된 모델 파라미터 를 갖고 있기 때문에 메모리, 연산량 측면에서 부담이 크다.
Quantization의 목표는 이 파라미터 뿐만 아니라, 중간 activation 값들()까지도 최소한의 정확도 손실만을 남기면서 저비트로 바꾸어 모델 경랼화 및 추론 속도를 향상시키는 것이다.
이를 위해, floating point 값을 양자화된 int값으로 mapping시켜주는 Quantizaton operator(양자화 연산자)를 정의해야 한다.
이 과정에서 모델의 accuracy가 크게 떨어지지 않도록 하는 것이 관건이다.
B. Uniform Quantization
먼저, Neural network의 가중치와 활성화 값을 유한한 값의 집합으로 Quantization할 수 있는 양자화 함수를 정의해야 한다.(Quantization operator/function)
이 함수는 Floating point값을 받아서 더 낮은 정밀도의 범위(Int)로 매핑한다.
널리 사용되는 Quantization function은 다음과 같다.
- : Quantization operator, 양자화된 정수 값
- : 정수로 변환하는 함수(반올림 함수 등)
- : 실수(Floating point) 입력값(가중치, 활성화 값)
- : 실수 값의 scaling 인자
- :정수(Int)형 zero point
Zero point?
실수 을 정수로 바꾸는 데 있어서, 0이 어떤 정수로 매핑되어야 할지를 지정해 주는 값
- 이면 중심이 0으로 대칭 양자화
- 이면 중심을 살짝 옮겨서 비대칭 양자화
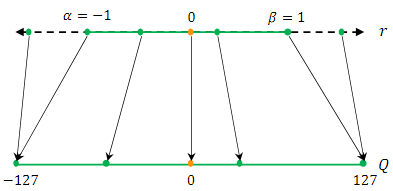
이 함수는 실수 을 정수 값으로 매핑하는 함수이다.
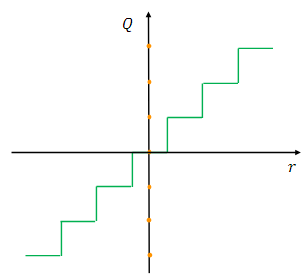
이러한 Quantization 방식은 Uniform Quantization(균등 양자화)라고 불린다.
양자화된 값이 균등한 간격으로 배치되기 때문이다.균등한 간격?
양자화된 값들 사이의 간격이 모두 일정한 상태로, 변환 전 실수 값들을 균들한 간격으로 변환시킨 경우 나타난다.
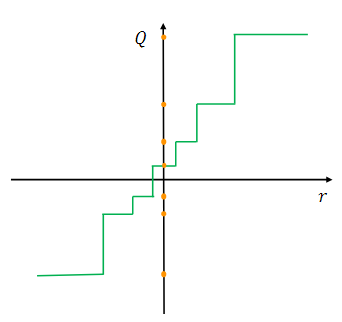
한편, 비균등 양자화(Non-uniform Quantization) 방법도 존재하는데, 이 경우 양자화된 값들이 균등하게 배치되지 않을 수 있다.
양자화된 값 로부터 다시 실수 로 복원하는 것도 가능한데, 이를 비양쟈화(Dequantization)이라고 한다.
- : Quantization operator, 양자화된 정수 값
- :정수(Int)형 zero point
- : 정수를 다시 실수로 늘려주는 scaling 인자
- : 양자화된 값을 기반으로 다시 실수로 바꾼 실수 값
여기서 복원된 실수 은 반올림 연산으로 인해 원래 값 과 정확히 일치하지 않을 수 있다.
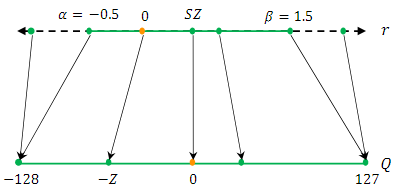
C. Symmetric and Asymmetric Quantization
Uniform Quantization에서 중요한 요소 중 하나는 의 scaling 인자 의 선택이다.
이 scaling 인자 는 주어진 실수 값 의 범위를 여러 개의 구간으로 나누는 역할을 한다.
- [] : 클리핑 범위로, 실수 값이 너무 넓게 퍼져 있으면, 정수로 표현할 때 오차가 커지기 때문에 실수 값을 일정한 범위 안으로 잘라내는(cliping) 작업 수행
- : 양자화 비트 수(bit width)로, INT8이면 =8, 총 256개의 정수
따라서, Scaling 인자 를 정의하려면 먼저 Cliping range []를 정해야 한다.
이 Cliping range를 선택하는 과정을 Calibration이라고 부른다.
간단한 선택 방법은 값의 최소/최댓값을 이용하여 Cliping range를 설정하는 것이다.
이러한 방식은 비대칭 양자화(Asytmmetric quantization) 접근법에 해당한다.
왜냐하면, 이 Cliping range는 원점 0을 중심으로 대칭적이지 않기 때문이다.
즉, 인 경우이다
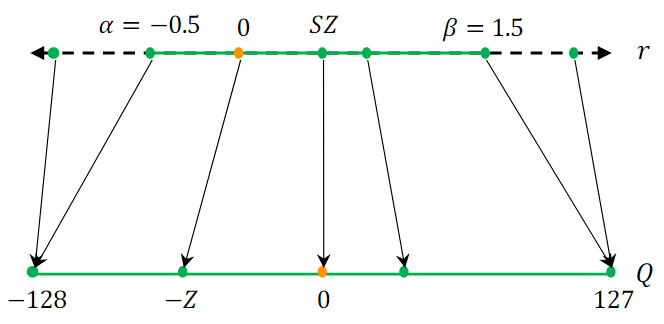
반면, 로 대칭적인 cliping range를 설정하여 대칭 양자화(Symmetric Quantization) 방식을 사용할 수도 있다.
입력 값의 최댓값과 최솟값의 절댓값 중 더 큰 값을 기준으로 으로 설정한다.
비대칭 양자화는 대칭 양자화에 비해 더 좁은 Cliping range를 얻는 경우가 많다. 이는 특히 가중치나 활성화값이 비대칭적일 때 유리하다.
대칭 vs 비대칭 cliping range
예를 들어, 실수 값이 [0,5]에 몰려 있는데 대칭 양자화의 경우 cliping range가 [-5,5]로 10의 범위 폭을 갖지만, 비대칭의 경우 [0,5]로 범위 폭이 절반으로 줄어든다.
실제 데이터 분포에 맞게 필요한 만큼의 범위만 쓰기 때문에 비대칭이 더 효율적
좁은 Cliping range가 왜 중요?
양자화에서는 Cliping range가 좁을수록, 정해진 비트 수로 더 촘촘하게 값들을 표현할 수 있다.
즉, 정수 하나당 더 정밀한 실수값 표현이 가능하다
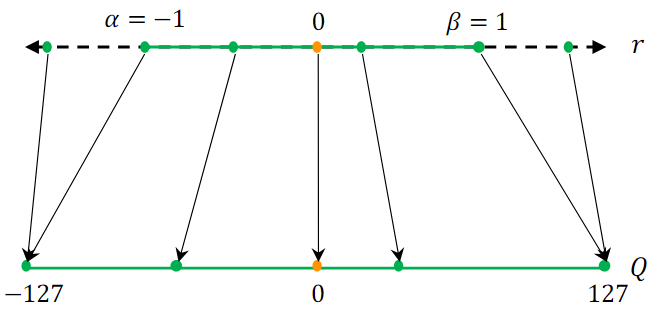
한편, 대칭 양자화를 사용하면 의 수식을 더 단순화할 수 있다.
이 경우, Zero point 는 0으로 설정된다.
여기서, Scaling 인자 를 설정하는 방식은 두 가지가 있다.
-
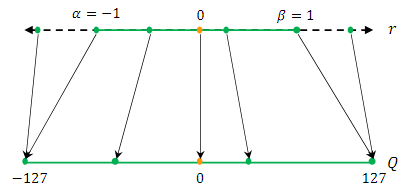
Full range 대칭 양자화
INT8 범위 [-128,127]을 모두 사용(반올림 모드 필요)
-
Restricted range 대칭 양자화
- max(|r|) = 127
[-127,127] 범위만 사용
Full range 대칭 양자화를 사용하는 방법은 더 정확하며, 실제로 대칭 양자화는 구현이 간단하고 Zero point를 0으로 둘 수 있어 많이 사용된다.
Full 이랑 Restricted는 딱 1차이밖에 안 나는데, 기술적 관점에서 큰 차이?
INT8의 경우 -128~127의 범위를 갖기에 비대칭 구조를 띈다.
그래서, -128은 딱 하나뿐인 "특이한 값"이 된다.주로 -128은 에러 표시, 패딩, 마스킹 등 특정 용도를 갖고 사용하게 되는데 이로 인해, 성밀도은 높일 수 있지만 -128이란 값으로 인해 버그나 오버플로우가 생길 수 있다.
이 오류는 심각할 수 있기에 대부분 -127까지의 restricted range를 사용한다.
반면, 비대칭 양자화는 Zero point가 0이 아니기 때문에 offset이 발생한다.
최소/최댓값 사용에 대한 논의점
대칭 및 비대칭 양자화 모두에서 값의 min/max를 사용하는 방식은 매우 일반적이지만, 이 방식은 활성화 값 내의 outlier(이상치)에 민감하다는 단점이 있다.
이상치는 범위를 불필요하게 넓게 만들고, 결과적으로 양자화의 해상도를 떨어뜨릴 수 있다.
해결 방법
-
Percentile(분위율) 사용
가장 큰 값이나 가장 작은 값 대신, i번째로 큰 값을 , i번째로 작은 값을 로 사용하는 방식이다.
-
KL divergence
실수 값과 양자화 값 사이의 정보 손실을 최소화하도록 와 를 선택하는 것이다.
D. Range Calibration Algorithms: Static vs Dynamic Quantization
의 clipping range를 결정하기 위한 방법을 보았는데, 그렇다면 clipping range를 언제 결정되느냐도 중요한 논의점이다.
대부분의 경우 가중치는 inference에서 고정되어 있기 때문에 정적인 계산이 가능하지만, activation의 경우 input data에 따라 다르다.
따라서, activation을 정량화하는 방법은 Dynamic/Static 두 가지 접근 방식이 존재한다.
Dynamic quantization
Clipping range가 runtime 중에 각 activation에 대해 동적으로 계산된다.
실시간으로 activation에 대한 통계를 계산해야 하기 때문에 오버헤드가 매우 높다
각 input에 대한 activation이 정확히 계산되기 때문에 정확도가 높은 경우가 많다.
Static quantization
Clipping range가 미리 계산되어 inference 중에 정적으로 유지된다.
계산 오버헤드가 추가되지 않지만, dynamic에 비해 정확도가 떨어진다.
clipping range를 사전 계산하기 위해 사용되는 방법 중 하나는 Calibration data를 이용하여 일반적인 activation 범위를 계산하는 것이다.
또 하나는 training 중에 clipping range와 가중치를 공동으로 최적화하는 방법이다.
E. Quantization Granularity
CLipping range 계산에서 또 한 가지의 논의점은 어떻게 세분화시켜 계산할지에 대한 논의이다.
Layerwise Quantization
한 layer 내 모든 가중치를 고려하여 clipping range를 결정한다.
해당 layer의 모든 parameter에 대해 통계를 검토한 다음 모든 parameter에 대해 동일한 clipping range를 사용한다.
구현이 매우 간단하지만, 각 parameter의 range가 다양할 수 있기 때문에 정확도가 최적이 아닌 경우가 많다.
Groupwise Quantization
Layer 내에서 여러 채널을 grouping하여 clipping range를 계산한다.
layer내 parameter의 분포가 매우 다양한 경우에 유용하다.
다양한 scaling factor를 고려해야 하는 추가 비용이 발생한다.
Channelwise Quantization
각각의 채널에 대해 전용 scaling factor가 할당한다.
채널마다 전용 scaling이 되기 때문에 정확도가 높아진다.
F. Non-Uniform Quantization
양자화된 값들의 간격이 비균일하게 되는 양자화 방법이다.
- : 양자화된 값
- 실수 이 어떤 구간 안에 들어가면, 그 구간에 대응하는 대표값 로 projection(매핑)한다.
Non-uniform quantization은 중요한 값 영역에 더 집중하거나, 적절한 범위를 찾아 분포를 더 잘 포착할 수 있기 때문에 더 높은 정확도를 달성할 수 있다.
Non-uniform quantization에서의 최적화 문제
원래 텐서와 양자화된 텐서 사이의 최소화하도록 최적화
G. Fine-tuning Methods
Pre-trained 모델이 주어졌을 때, quantization은 FP로 학습된 모델의 파라미터에 perturbation을 주어 학습에서 수렴된 지점에서 멀어질 수 있다.
양자화 후에 파라미터를 조정해야 하는 경우, 모델을 재훈련하거나 QAT(Quantization Aware Training)라고 하는 training 중에 quantization을 하며 조정하는 방법 또는 재훈련 없이 quantization을 수행하는 PTQ(Post Training Quantization)을 수행한다.
Quantization-Aware Training
Training 중 forward/backward를 quantized 모델로 수행(Fake quantization)
하지만, 파라미터 업데이트 자체는 FP로 하고, 업데이트 후 다시 양자화로 투영시켜 forward/backward 수행
Weight를 진짜 INT8로 저장해서 학습하면 업데이트가 너무 거칠거나 불안정
-
실제 학습 파라미터는 FP32/16으로 유지
-
Forward/backward에서는 quantized weight 사용
- Forward에 쓰는 값은 (Fake quant)
-
업데이트는 FP에 적용
- Gradient는 형태로 FP weight에 적용
- 업데이트 후 다시 로 forward용 fake quant weight 만들기
QAT에서는 forward는 fake quant로 양자화 효과를 시뮬레이션,
Gradient 누적과 업데이트는 FP로 해서 학습 안정화
양자화된 값으로 Gradient를 구하고 저장할 경우, 너무 작은 값은 0으로 떨어져서 큰 오차가 발생하게 됨
STE
Quantization은 구간별로 대표값 mapping이기 때문에 구간별로 출력이 일정한 계단함수이다.
대부분 구간에서 미분이 0이 되고, 경계에서는 미분이 정의되지 않음
STE는 Forward시에 진짜 양자화(rounding)로 값이 뭉개지게 만들고, backward에서는 rounding을 없는 셈치고 기울기를 1로 근사해서 gradient를 통과시킨다.
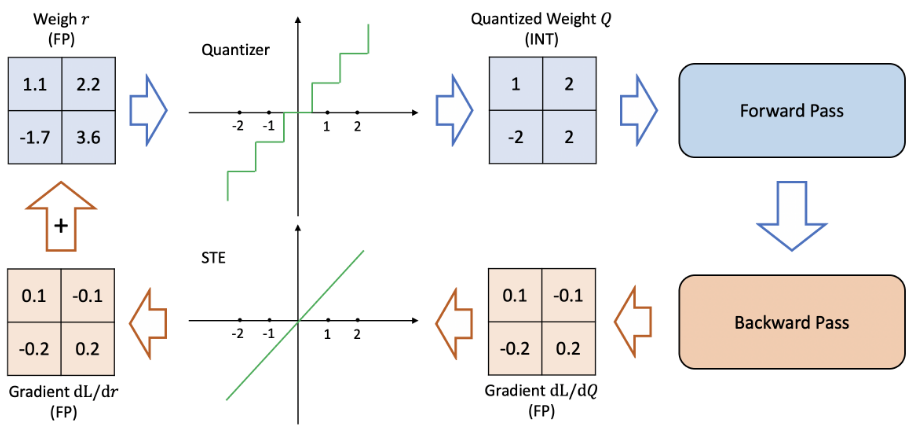
QAT는 STE의 근사에도 불구하고 잘 작동하지만, 모델을 재훈련하는 데 드는 계산 비용이 크다는 단점이 있다.
Post-Training Quantization
비용이 많이 드는 QAT 방법의 대안으로 fine-tuning없이 양자화 후 약간의 가중치 조정을 수행하는 PTQ가 있다.
재학습을 위해 충분한 양의 training data가 필요한 QAT와 다르게, PTQ는 데이터가 제한적이거나 label이 없는 상황에서도 적용할 수 있다는 추가적인 장점이 있다.
하지만 QAT에 비해 정확도가 떨어지는 단점이 존재하지만, PTQ의 정확도 저하를 완화하기 위해 양자화 후 가중치 값의 편향을 보정하는 등의 대안이 존재한다.
Zero-shot Quantization
양자화를 잘하기 위해 필요한 조건
-
Activation range를 알아야 함
Activation이 어느 범위로 나오는지 알아야 clipping range와 scale을 정할 수 있는데, 이는 calibration 데이터가 필요함
-
Fine-tuning
양자화로 떨어진 성능 복구
하지만, 실제로는 dataset에 접근이 안 될 수 있다.
Dataset없이도 quantization을 하기 위해 나온 ZSQ
1. Level 1 : 데이터 없음 + Fine-tuning도 없음
완전 바로 양자화(빠르고 쉽지만, 정확도 회복 어려움)
2. Level 2 : 데이터 없음 + Fine-tuning은 함
데이터는 없지만, 어떤 방식으로든 학습/최적화를 해서 정확도 회복
H. Stochastic Quantization
Inference에서 양자화는 보통 같은 입력 에 대해 항상 같은 양자화 결과 가 나오는 round-to-nearest같은 deterministic(결정적) rounding이 기본이다.
하지만, 학습에서는 확률적으로 위/아래로 rounding해서 모델이 더 탐색할 수 있게 만들자는 접근의 stochastic quantization이 나옴
Deterministic quant에서는 작은 업데이트가 있어도 업데이트가 양자화 격자 간격보다 좁아 round결과가 그대로인 경우가 존재한다.
Stochastic quant에서는 작은 변화도 확률적으로 반영되어 정체된 학습이 완화될 수 있다.
Advanced Concepts : Quantization Below 8bits
A. Simulated and Integer-only Qunatization
양자화된 모델을 배포하는 데는 Fake-quant(Simulated)와 Integer-only quant라는 일반적인 접근 방식 존재
Fake-quant에서는 모델 파라미터는 low-precision로 저장되지만, 연산은 FP로 수행된다. Fake-quant로는 빠르고 효율적인 low-precision의 이점을 충분히 누릴 수 없다.
Quant와 Dequant를 반복해야 함
그러나 Integer-only quant에서는 모든 연산이 low-precision으로 수행되어 효율적인 정수 연산으로 inference가 가능하다.
Dequant없음
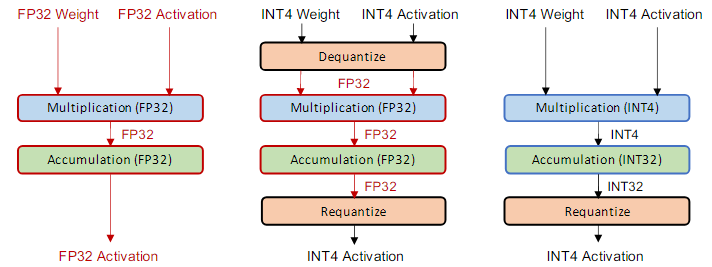
하지만, 많은 연산들이 FP에 친화적으로 설계되어 있어 어려운 부분이 많음
B. Mixed-Precision Quantization
Low-precision quant를 사용할수록 hardware의 성능이 향상되지만, 매우 낮은 precision으로 양자화할 경우 정확도가 크게 저하될 수 있다.
Mixed-precision양자화로 이 문제 해결 가능
각 layer가 서로 다른 bit의 precision으로 quantization된다.
이 bit설정을 선택하기 위한 search space가 layer 수에 따라 기하급수적으로 증가한다는 문제가 있어, RL기반 방법, NAS 기반 방법으로 다양한 방법이 제안되었다.
C. Hardware aware Quantization
양자화의 목표 중 하나는 inference의 latency 개선이다.
하지만, 특정 layer, 연산을 양자화한다고 모든 hardware에서 동일한 속도 향상이 이뤄지는 것은 아니다.
양자화의 이점은 hardware에 따라 달라지며, 여러 요소가 속도 향상에 영향을 미친다.
양자화를 통해 최적의 이점을 얻기 위해서는 이러한 사실을 고려하는 것이 중요하다.
D. Distillation-Assisted Quantization
Distillation을 통해 양자화의 정확도를 높일 수 있다.
정확도가 높은 대형 모델을 teacher로 사용하여 소형 student 모델의 학습을 돕는 방법
Student 모델을 학습하는 동안, teacher 모델이 생성한 soft label을 학습하도록 하며, 전체 loss function은 student 모델 자체의 loss + distillation loss가 통합된다.
E. Extreme Quantization
1 bit 양자화는 메모리 요구량을 32배로 줄이는 극단적인 양자화 방법이다.
메모리 이점 외에도 binary/ternary 연산은 비트 단위 연산을 통해 효율적으로 계산할 수 있으며, 상당한 연산 가속을 달성할 수 잇다.
Binary connect는 가중치를 +1, -1로 제한하는 방법으로, 이 방식에서는 이진화 효과를 시뮬레이션하기 위해 forward/backward에서만 이진화된다.
그런 다음, STE를 사용하여 gradient를 전파하여 훈련한다.
이러한 극단적인 양자화는 ImageNet classification과 같은 복잡한 작업에서 심각한 정확도 저하를 초래하며, 이를 위한 여러 가지 해결책이 제안되었다.
하지만, 극단적인 양자화는 CV 작업에서 많은 CNN 모델의 크기, latency를 대폭 줄이는 데 성공하며, 덜 중요한 작업에서는 허용될 수 있다.
F. Vector Quantization
Quantization은 작은 손실만을 초래하는 low-precision 표현을 찾는 것이 목표이다.
고전적인 양자화에서는 가중치를 여러 그룹으로 클러스터링하여, 각 그룹의 중심을 양자화된 값으로 사용한다.
k-means clustering을 사용하면 정확도 저하 없이 모델 크기를 최대 8배까지 줄일 수 있는 것으로 밝혀졌다.
Quantization and Hardware Processors
양자화는 모델 크기를 줄일 뿐만 아니라 정밀도가 낮은 로직이 있는 하드웨어의 경우 더 빠른 속도를 구현하고, 더 낮은 전력을 필요로 하기 때문에, IoT 및 엣지 디바이스 배포에 중요하다.
엣지 디바이스는 컴퓨팅 리소스 제약이 엄격한 경우가 많다.
STM32의 경우 MCU 제품으로 일부 ARM Cortex-M 코어에는 FP유닛이 포함되어 있지 않기 때문에 배포하기 전에 먼저 모델을 정량화해야 한다.
지난 몇 년동안 엣지 디바이스의 컴퓨팅 성능이 크게 향성되어 이전에는 서버에서만 사용할 수 있었는 모델을 배포하고 추론할 수 있게되었다.
low-precision 로직 및 전역 가속기와 결합된 양자화는 이러한 엣지 디바이스의 진화에 중요한 원동력이었다.

정말 좋은 서베이네요.
번창하세요.