Abstract
VLM은 여러 모달리티의 정보를 통합하여 다양한 과제에서 좋은 성능을 보여주었지만, 대규모 VLM을 리소스가 제한된 환경에 배포하는 것은 어려운 과제이다.
Pruning 후 Fine-tuning을 하는 것이 잠재적인 해결책이 될 수 있지만, VLM과 같은 멀티 모달에 대해서는 충분하게 연구되지 않았다.
또한, LoRA 기반 fine-tuning은 희소 모델의 성능 복원을 목표로 하지만, 희소 패턴이 파괴된다는 문제점이 있다.
이를 해결하기 위해, LoRA 가중치에 직접 sparse mask를 적용하는 SparseLoRA기법을 제안한다.
Introduction
모델의 크기가 계속해서 커짐에 따라 계산량 및 메모리가 증가하여 리소스가 제한된 환경에서의 적용이 제한된다.
성능을 유지하면서 모델 크기를 줄이는 Pruning과 fine-tuning은 리소스가 제한된 환경에서의 실제 배포를 가능하게 하는 가능성을 제시한다.
Pruning 후 fine-tuning은 비전과 언어 모델의 효율성을 크게 향상시켰지만, VLM에 대해서는 상대적으로 덜 연구되었으며, 두 가지 질문을 제기한다.
-
모달리티 별 sparsity를 어떻게 분배해야 하는가?
Vision 모델과 Language 모델에 다양한 sparsity 비율을 조합한 결과, 두 모델에 동일한 비율의 sparsity를 적용하는 방식이 거의 최적의 성능을 보였으나, sparsity가 높아질수록 성능 저하가 심각해져, pruning 후 성능 복원의 중요성이 강조되었다.
-
Pruning된 VLM의 성능을 어떻게 복원할 것인가?
PEFT 기법인 LoRA는 sparse 모델의 성능 복원을 위해 제안되었으나, dense한 LoRA 모듈을 sparse한 모델에 병합하면, sparse 패턴이 파괴되고, 병합하지 않으면 Latency가 발생하는 문제에 지면한다.
이러한 LoRA의 비호환성 문제를 해결하기 위해, LoRA 가중치에 binary mask를 직접 적용하는 SparseLoRA fine-tuning 기법을 제안한다.
Related Work
Vision-Language Models
VLM은 이미지와 텍스트를 사용하는 다양한 Cross modal 작업에서 뛰어난 성능을 보였다.
이러한 모델은 일반적으로 pre-training된 vision, language 능력을 갖고 있기 때문에 가능한 작은 모듈(예 : BLIP2의 Q-former)만 fine-tuning하여 가능한 fine-tuning 과정에서의 높은 training cost와 catastrophic forgetting 문제를 피한다.

Catastrophic forgetting
모델이 fine-tuning 과정에서 기존에 학습했던 지식을 잃어버리는 현상
각 weight 들이 해당 task를 학습할 때 정확히 어떤 correlation이 있는지 모르는 딥러닝에서, fine-tuning 시 weight를 섣부르게 바꾸면 기존 task를 망각
Model pruning for Large Language Models
대규모 Vision 모델 또는 LLM은 높은 성능을 보여주지만, 방대한 크기의 파라미터는 실제 배포에 어려움을 준다.
이를 해결하기 위해, 모델 pruning 기법이 도입되었다.
Pruning의 주요 목표는 pruning 전후의 모델 간 성능 차이를 최소화하면서, 모델의 크기를 줄이는 것이다.
Pruning에서 중요한 파라미터를 식별하기 위한 지표에는 Weight magnitude, Gradient, Activation과 같이 다양한 지표가 제안되었다.
그러나, fine-tuning 없이 pruning을 하면 성능이 저하되는 경우가 많다.
다른 논문에서는 Reconstruction errors-based metric을 활용하여 원본 모델과 sparse 모델 간 불균형과 sparse 모델의 성능 복구를 수행한다.
Reconstruction errors-based metric
원본 모델의 출력과 sparse 모델의 출력의 차이를 직접 계산하여, 출력 값의 차이가 큰 파라미터부터 제거하는 방식
Preliminary Study
VLM은 모달리티별 foundation model과 이들을 align을 담당하는 크로스-모달 인터페이스(예: Q-former)로 구성된다.
다른 VLM pruning 논문(Ecoflap)을 따라, 본 논문 역시 가벼운 Q-former는 그대로 두고 Vision 모델과 Language 모델만 pruning 대상으로 삼는다.
- Pruning 기법 : Wanda
모달리티별 sparsity 비율 분배
Vision 모델의 sparsity 비율(sv)과 Language 모델의 sparsity 비율(sl)의 합 sv+sl을 고정한 뒤, 두 비율의 분포만 조정한다.
- 그림에 따르면, sl(Language sparsity)가 70%이상일 때, VLM이 붕괴하는 반면 Vision 모델에 부과된 sparsity는 상대적으로 덜 민감했다.
- sv+sl을 일정하게 유지할 때 두 모달리티에 동일한 비율의 sparsity를 적용하는 방식이 최적의 성능을 낸다.
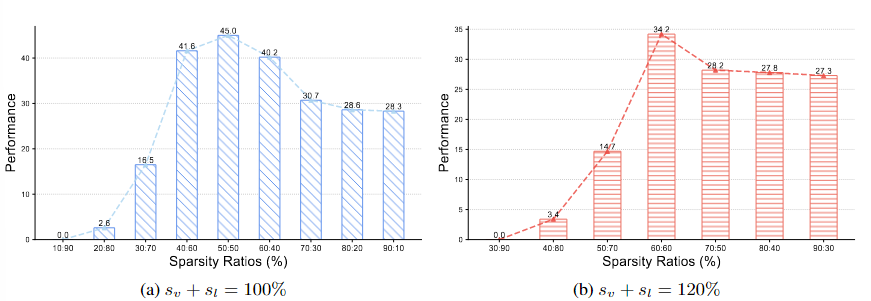
서로 다른 sparsity가 VLM 성능에 미치는 영향
세 가지 전략으로 VLM을 pruning하였음
- V + L : Vision 모델과 Language 모델 모두 동일한 sparsity로 pruning
- Vision : Vision 모델만 pruning
- Language : Language 모델만 pruning
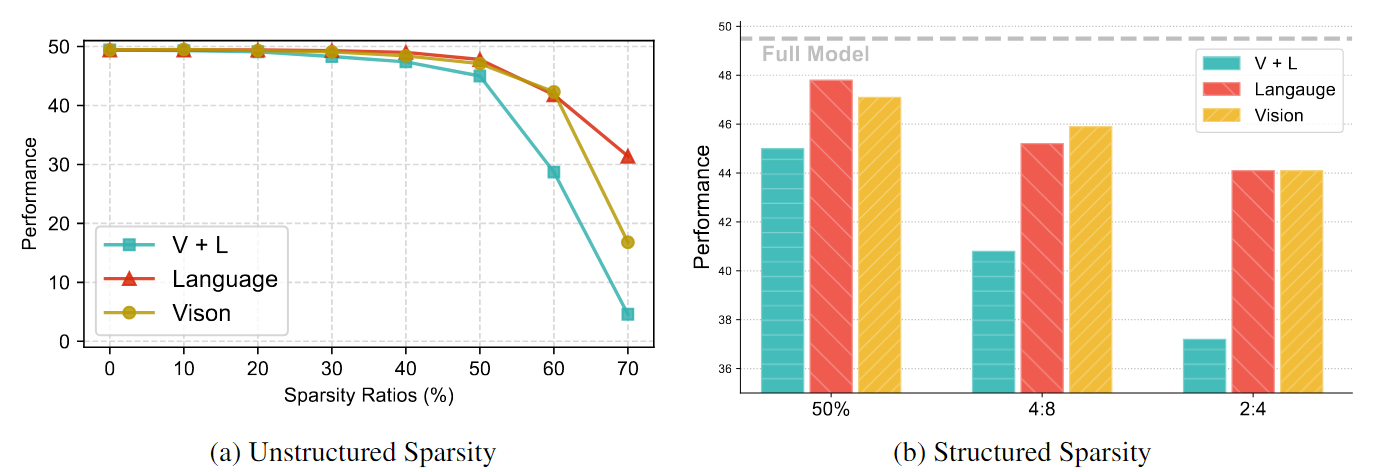
Methodology

Pruning with few samples
모델 pruning은 미리 정의된 중요도 지표 를 사용해 중요도가 낮은 가중치를 식별하며, 일반적으로 pruning 전,후 모델 간 재구성 오차(Magnitude, Gradient, Activation)를 측정한다.
Gradient나 Activation을 계산하려면 소량의 Calinbration dataset이 필요하다.
중요도 지표 와 데이터셋 를 이용해 원본 가중치 에 점수를 부여하고, 상위 s%를 제외한 가중치에 대해 binary mask 을 생성하여 제거한다.
- 는 의 pruning 임계값
- 는 masking된 가중치
Sparse LoRA finetuning
VLM은 Vision 모델과 Language 모델을 모두 포함하므로 전체 모델을 fine-tuning 하는 것은 비효율적이다.
따라서, LoRA를 사용한다.
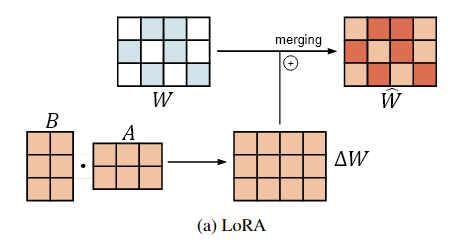
하지만, 가 dense하기 때문에, 병합 시 sparse 패턴이 파괴되고, 병합하지 않으면 LoRA 모듈로 인해 추론 Latency가 발생한다.
이를 해결하기 위해 SparseLoRA는 에도 mask 을 적용하여
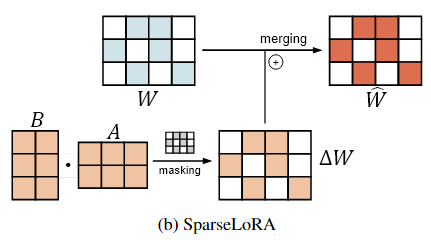
로 업데이트한다. 이렇게 하면 제거된 위치의 가중치가 Backpropagation을 통해 업데이트되지 않아 sparse 패턴이 유지된다.
A와 B의 최적화
VLM은 Vision, Language 모달 외에, 이를 align하는 Q-former를 포함하기 때문에, Q-former에도 LoRA 모듈을 삽입하여 최소한의 계산 비용으로 크로스 모달 성능을 향상시킨다.
Finetuning Objectives
Pruning된 VLM의 성능을 회복하기 위해, 두 가지 fine-tuning objective(loss)를 도입한다.
-
Task loss
Pruning 후 Task에 대해 손실을 최소화하며 VLM을 계속 fine-tuning하여 과제별 성능을 복원한다.
-
Distillation loss
원본 모델의 지식을 pruning된 모델로 이전하기 위해, 두 모델의 출력 값의 분포 간 KL divergence를 제약한다.
- : KL divergence distance
KL divergence는 두 확률 분포 (교사)와 (학생) 사이의 차이를 측정하는 값
작게 만들수록 학생 분포 가 교사 분포 에 가까워진다.
- : SparseLoRA로 pruning된 모델의 출력 로짓(값)
- : 원본 가중치 를 가진 모델의 출력 로짓(값)
최종적으로, 두 손실을 가중 합한 전체 최적화 loss function은 다음과 같다.
