1. Lora: Low-rank adaptation of large language models
- Instruction
자연어 처리에서 많은 Task들은 하나의 대규모로 pre-trained 된 언어 모델을 여러 downstream task에 적용시키는 데 의존한다. (하나의 Foundation 모델을 fine-tuning)
이러한 Adaptation은 일반적으로 Pre-trained된 모델의 모든 파라미터를 업데이트하는 fine-tuning을 통해 수행된다.
Fine-tuning의 주요 단점은 전체 파라미터에 대해 Gradient를 구하고 Optimizing하는 과정이 포함된다.
- 모델의 크기가 클 수록 fine-tuning시 많은 파라미터를 학습 시켜야 하기 때문에, 시간, 비용 모든 측면에서 비효율적이다.
이러한 단점으로 인해, 많은 연구자들이 일부 파라미터만 조정하거나 새로운 task를 위한 외부 모듈을 학습하여 운영 효율성을 크게 향상시켰지만, 이 방식들도 모델의 Depth를 확장하거나 사용가능한 sequence 길이를 줄임으로써 Inference latency를 발생시키는 trade-off가 존재하였다.
연구진들은 저차원의 Intrinsic rank(내재적인 계수)를 이용해 fine-tuning하는 방법론인 Low-Rank Adaptation(LoRA)를 제시하였다.
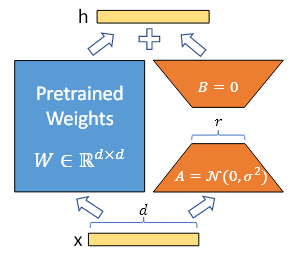
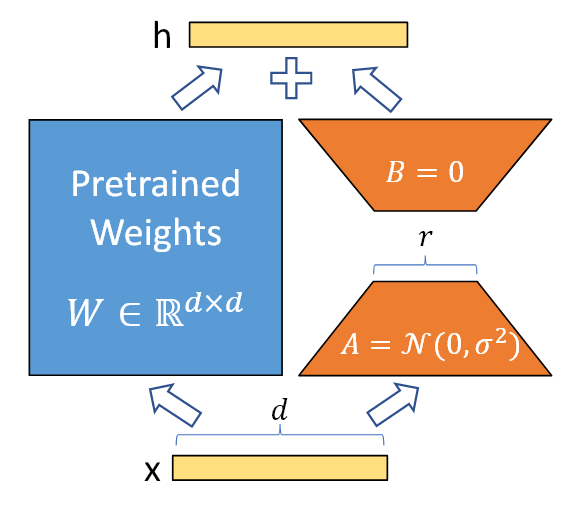
Fine-tuning 시, pre-training된 모델의 weight는 업데이트하지 않고(Freeze), LoRA의 rank decomposition matrices의 weight들만 업데이트
- Method
Pre-training된 가중치 행렬 의 경우
로 표현하여 업데이트를 제한한다.
여기서 은 rank이다.
학습하는 동안 은 고정되고 Gradient 업데이트를 받지 않고, A와 B는 학습 가능한 파라미터를 포함한다.
기존의 였던 경우, LoRA를 도입한 forward pass는 다음과 같다.
<LoRA에서의 Forward pass>
- Code
