Abstract
컴퓨터 비전 작업에서 Transformer 기반의 모델 중 하나인 SegFormer는 semantic Segmentation에서 우수한 성능을 보여주었지만, 높은 계산 비용으로 인해 엣지 디바이스에 SegFormer를 배포하는 데 어려움을 겪고 있다.
엣지 디바이스에는 고성능 GPU나 메모리가 작기 때문에 뉴런의 개수가 많으면 많은 메모리와 고성능의 계산 능력이 필요하기 때문이다.
이 논문에서는 SegFormer 모델을 동적으로 가지치기하여 계산 비용을 줄이는 동시에 성능을 유지하는 DynaSegFormer를 제안한다.
SegFormer 레이어의 뉴런이 이미지에 따라 큰 차이를 보인다는 관찰을 바탕으로, 입력 인스턴스를 기반으로 가장 정보가 적은 뉴런 집합을 잘라내는 dynamic gated linear layer(동적 게이트 선형 레이어)(DGL)를 사용하여 계산량을 감소시킴.
이미지에 따른 뉴런이 큰 차이?
어떤 뉴런은 이미지에서 중요한 정보를 추출, 생성하지만, 어떤 뉴런은 거의 아무런 정보도 제공하지 않는 경우가 존재특정 입력에 대해 중요하지 않은데도 계산에 포함되기 때문에 불필요한 계산 발생
pruning은 Weight-based pruning, 구조 기반 pruning으로 나뉨
또한, 가지치기로 인해 발생하는 성능 손실을 줄이기 위해 2단계 knowledge distillation(지식 증류)를 수행한다.
뉴런은 데이터를 표현하고 이해하는 데 필요한 다양한 특성을 학습하는데 뉴런을 제거하면 학습 가능한 표현에 제약이 발생할 수 있다.
교사 모델은 원래 크고 정확도가 높은 모델(가지치기 전의 SegFormer).
학생 모델은 계산량을 줄인 경량화된 모델(가지치기 후의 SegFormer).
지식 증류는 학생 모델이 교사 모델의 성능을 최대한 따라잡을 수 있도록 돕는다.
첫 번째 단계에서는 MiT(Mix Transformer) 인코더의 블록에서 교사 모델과 학생 모델의 특성을 정렬하며,
1.동일한 이미지 입력이 교사 모델과 학생모델로 전달되어 동시에 입력
2. 각 모델의 MiT인코더 블록이 input 데이터를 처리하면서 feature 맵 생성(인코더를 거쳐 출력된 임베딩 벡터)
두 번재 단계에서는 두 feature map 간의 Loss를 최소화한다.
손실함수를 이용해 두 Feature간 차이를 측정하여 계산된 손실을 최소화하도록 학생 모델의 가중치를 업데이트하며 교사 모델의 feature를 점진적으로 모방하게 된다.
이러한 연구는 SegFormer를 경량화하여 실시간 세그먼테이션 응용 가능성을 확대하는 데 기여한다.
ViT는 입력 크기에 따라서 셀프 어텐션 계산 복잡도가 N^2으로 증가해서 계산 비용이 높다
MiT는 계층적 구조로 셀프 어텐션 계산 비용을 줄이기 위한 효율적인 멀티 헤드 어텐션 메커니즘 사용MiT는 입력 이미지를 여러 단계로 처리, 각 단계에서 패치 크기를 점진적으로 증가시키고 해상도를 줄인다.
계층적인 표현 추출?
1. 초기에는 이미지의 저수준 특징(엣지, 텍스처..)을 추출 - 세부적인 정보 (local 세부 사항)
2. 후반 단계로 갈수록, 모델은 더 추상적이고 고수준 의미를 학습 - 객체 전체 형태, 구조, Sementic정보 (global 문맥, 의미)
MiT는 CNN의 계층적 특징 방식을 Transformer구조에 결합
초기에는 입력 이미지를 작은 패치로 나누어 저수준 특징 학습
점점 패치를 점진적으로 병합시켜 더 큰 영역의 특징을 학습 시킴ViT는 모든 패치를 동일하게 처리하고 Flatten하게 특징 학습하지만, MiT는 패치의 크기를 점점 키워나가면 저수준에서 고수준으로 특징을 학습함
1. Introduction
ViT 변종 모델 중 하나인 SegFormer는 트랜스포머 아키텍처를 사용하여 입력 이미지로부터 계층적 표현을 추출하며, 의미론적 분할 작업에서 기존의 합성곱 신경망(CNN)을 능가하는 뛰어난 성능을 보여준다.
CNN기반 모델들은 고정된 커널 크기로 인해 시각적 정보의 유연한 표현이 제한되지만 SegFormer는 Transformer구조를 사용하여 더 넓은 시야각과 더 풍부한 표현 제공
그러나, SegFormer 아키텍처는 높은 계산 비용이 요구되며, 이는 저전력 장치에서의 활용을 어렵게 만든다.
Mit에서 고수준의 시각적 특징을 추출하기 위해 FC 레이어가 사용된다는 점에서 높은 계산 비용이 요구된다.
기존 CNN 기반 계층적 아키텍처와 달리, Transformer기반의 다중 헤드 어텐션 구조와 Mix-Feedforward 구조는 복잡한 계산을 필요로 하여 오버헤드를 증가시킨다.
CNN은 Filter를 사용하여 특정 영역에 대해서만 계산하기 때문에 계산 효율이 높다
Transformer는 멀티 헤드 어텐션과 FFN를 통해 입력 데이터를 처리하는데 셀프 어텐션과 FFN에서 모든 입력 패치간 관계를 계산하기 때문에 계산량이 높다
본 논문에서는 MiT 인코더의 불필요한 뉴런을 동적으로 가지치기하여 효율적인 SegFormer 아키텍처를 설계하는 것을 목표로 한다.
MiT레이어의 뉴런들이 다양한 입력 인스턴스에서 큰 분산을 보인다는 사실을 발견하였고, 현재 입력을 설명하는 데 가장 적합한 뉴런 세트를 식별하고, 비정보성 뉴런을 가지치기할 수 있다면 효율적일 것이라는 결론에 도달하였다.
현재 입력에 가장 적합한 뉴런 하위 집합을 선택하여 행렬 곱셈에서의 계산을 줄이는 동적 게이트 선형 계층(DGL)을 제안한다.
또한, 두 단계 지식 증류를 결합하여 원래 SegFormer(교사 모델)에서 동적으로 가지치기된 모델(학생 모델)로 지식을 전달한다.
이 두 단계 증류는 각각 MiT 인코더 표현과 출력 로짓 간의 불일치를 최소화한다.
2. PRELIMINARIES(서론)
2.1 The SegFormer Architecture
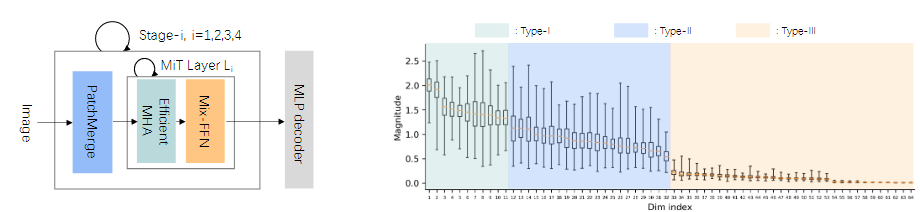
SegFormer는 의미론적 분할을 위해 다중 스케일에서 계층적 특징 표현을 추출하는 것을 목표로 한다.
SegFormer는 Mix TransFormer 인코더와 밀집 MLP 디코더로 구성되어 있다.
MiT 인코더는 네 개의 서로 다른 단계를 가지고 있다.
- PatchMerge
MiT의 i번째 단계에서 입력 데이터(입력이미지, 이전 단계에서 생성된 특징 맵)는 패치 임베딩으로 변환된다.
(Transformer가 처리할 수 있는 벡터 형태로 변환)
이후, 각 단계의 PatchMerge마다 패치를 병합하여 패치의 크기를 키워가며 고수준의 feature map을 추출할 수 있게 계층적인 처리를 하게 한다.

여기서 N은 패치의 개수, C는 각 패치의 임베딩 크기이다.
- Efficient Multi-Head Attention
각 트랜스포머 계층의 Efficient Multi-Head Attention은 다음과 같이 계산된다.
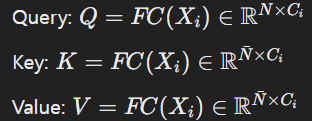
여기서 FC는 선형 계층이다. Key와 Value는 더 작은 시퀀스 길이를 가지며 이는 셀프 어텐션의 시간 복잡도를 줄인다.
Fully Connected Layer를 통해 input데이터를 다양한 방식으로 투영할 수 있게하고 모든 벡터에 대해 동일한 방식으로 동작하기 때문에 쉽고 효율적이다.
Efficient Multi-Head Attention의 출력은 다음과 같다.

1.Q와 전치 행렬 K의 내적에 임베딩 차원의 루트값으로 나눈 값에 Softmax를 적용한 뒤 V를 곱하여 패치 간 관계를 나타내는 Attention행렬을 구한다.
2. Attention행렬을 다시 선형 변환한 값에 Attention을 거치지 않은 임베딩 벡터를 더하여 기존의 임베딩 정보를 보존한 뒤 데이터를 정규화하여 안정성을 높인다. -> Xmha구함
- Mix-FFN
그 후, Mix Feed-Forward Network는 Efficient Multi-Head Attention의 출력 값을 다음과 같이 변환한다.

여기서 Conv는 합성곱 연산을 나타낸다.
주목할 점은, SegFormer는 이미지 패치 내에서 위치 인코딩을 사용하지 않고, 대신 위치 정보를 누출하기 위해 합성곱 계층 Conv을 사용한다는 것이다.
마지막으로, MLP 디코더는 단계별 특징 맵을 변환하고 연결하여 픽셀 단위 예측을 수행한다.
- FC(Xmha)를 선형 변환하여 차원을 조정
- SegFormer는 위치 인코딩을 사용하지 않기 때문에 Conv() 합성곱 연산을 통해 위치 정보를 반영한다.
기존 Transformer는 포지션 인코딩으로 위치정보를 임베딩 벡터에 추가했었음. 이러면 고정된 패턴을 사용하기 때문에, 입력 크기가 변하면 적응이 어렵기 때문에 합성곱을 통해 입력 데이터의 지역적 정보를 학습해서, 입력 크기에 무관하게 위치 정보를 학습할 수 있다.
- GeLU() 비선형 활성화 함수를 사용하여 표현력 강화하고
- 다시 선형 변환하여 차원을 다시 조정하고 FFN을 거치지 않은 Xmha값을 도해 입력 정보를 보존한 뒤 LN()으로 정규화하여 데이터의 안전성을 유지한다.
- MLP Decoder
각 스테이지의 출력값(x1, x2, x3, x4)은 별도로 저장되며, MiT 인코더의 모든 처리가 완료된 후, 각 스테이지 출력값이 병렬로 MLP 디코더에 전달됩니다.
즉, Stage 1에서 나온 출력값은 Stage 2로 전달되면서 동시에 저장되며, 나머지 스테이지에서도 동일한 방식으로 진행됩니다.
각 스테이지의 출력값은 해상도와 채널 차원이 다르기 때문에 모든 출력값의 해상도를 동일하게 만든다.(x1의 해상도와 똑같게 만듦)
채널 차원을 동일하게 하기 위해 각 스테이지 출력값을 선형 변환시킴
각 출력값들을 병렬로 연결하여 하나의 통합된 feature map을 만들거나, 모두 더하여 최종 출력을 생성한다.
픽셀 단위 semantic segmentation 결과를 생성.
2.2 Motivation
SegFormer의 계층적 시각 표현은 MiT 인코더의 폭을 증가시켜 FC Layer에서의 계산량이 증가하여, 저전력 장치에서 더 큰 계산 부담을 초래한다.
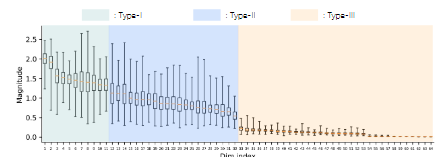
- X축 : Transformer에서 각 입력 특징 벡터의 임베딩 차원
- Y축 : 각 차원의 뉴런이 학습 중에 얼마나 중요한지를 나타냄
그러나 우리는 각 뉴런이 각 입력에 따라 중요도가 다르다는 것을 발견했다.
뉴런은 다음 세 가지 유형으로 분류한다.
-
Type1 - 큰 중앙값과 작은 범위 : 이는 뉴런이 다양한 인스턴스에서 일반적으로 유효함을 의미
-
Type2 - 큰 중앙값과 큰 범위 : 이는 뉴런 정보가 입력에 크게 의존함을 의미
-
Type3 - 작은 중앙값과 작은 범위 : 이는 뉴런이 대부분의 입력에서 비정보성임을 의미
관찰 결과, Type2와 Type3 뉴런은 계산 비용만 증가시키고 실제 정보 기여도 낮음을 알 수 있었다.
따라서, 입력마다 덜 중요한 뉴런을 동적으로 제거하면 계산 효율을 증가시킬 수 있다.
3. METHODOLOGY(방법론)
3.1. Dynamic Gated Linear Layer(동적 게이트 선형 계층)
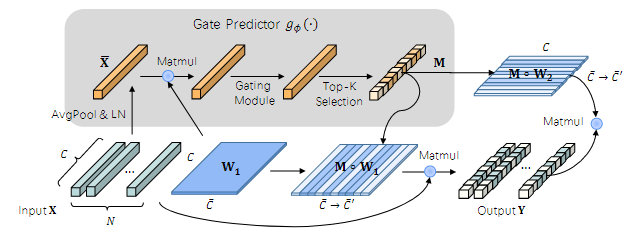
SegFormer에서 정보성이 낮은 뉴런을 식별하고 가지치기하기 위해, 동적 게이트 선형 계층을 제안한다. "DGL은 기존 선형 계층을 대체"할 수 있는 플러그 앤 플레이 방식의 모듈이다.
-> Mix_FFN Layer, MHA에서 사용한다
Mix-FFN은 일반적으로 두 개의 선형 계층(FC Layer)과 활성화 함수(GELU 등)로 구성된다
- 입력 데이터를 고차원 공간으로 변환.
- 비선형 활성화 후 다시 저차원으로 변환.
Mix-FFN은 뉴런 간의 학습과 변환을 담당하며, 계산량이 많다.
SegFormer의 MiT인코더는 입력 데이터와 관계없이 모든 뉴런을 활성화하여 선형 계층을 처리하기 때문에 모든 뉴런이 정보성을 가지지 않음에도 불필요한 계산량을 초래한다.
Type-II와 Type-III 뉴런(입력에 따라 중요도가 낮거나 거의 비활성화되는 뉴런)을 동적으로 제거하여 계산 효율성을 높이고자 한다.
-> 비정보성 뉴런을 가지치기한다면 계산량을 줄일 수 있을 것이다.
작동 과정
DGL 과정
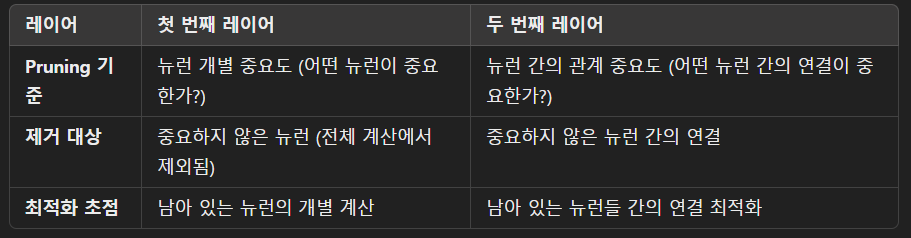
1. 입력 요약 : 평균 폴링과 정규화입력 임베딩 벡터 X는 Average Pooling과 정규화를 통해 요약된다.
모든 뉴런의 정보를 일일이 분석하는 것은 비효율적이므로 평균적인 정보를 추출
- 게이트 값 계산
요약된 X를 사용해 Gate Predictor를 적용하여 각 뉴런의 중요도를 나타내는 게이트 값 𝑔𝜙계산
gate module
요약된 X에 대해 MLP 적용하여 G값 생성
(값이 클수록 뉴런이 중요)

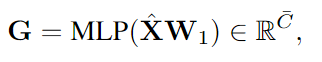
- Top-K Selection
게이트 값을 정렬하여 계산된 게이트 값에서 중요도가 높은 K개의 뉴런을 선택하여 마스크 벡터M 생성
선택된 뉴런은 1, 그렇지 않은 뉴런은 0으로 설정
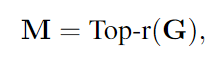
- 마스크 적용
게이트에서 선택한 K개의 뉴런만 계산에 포함되도록 가중치 행렬에 마스크 M를 적용하여
활성화된 뉴런만 반영한 중간 출력 결과 Y 계산
(⊙는 원소별 곱을 의미)
Top-K Selection에서 0으로 설정된 가중치는 계산에서 제외된다.
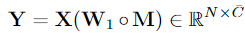

- 최종 출력 계산
활성화된 뉴런에 해당하는 가중치만 사용하도록 가중치에 마스크의 전치 행렬을 곱하여 Y추가 계산을 수행하여 Y와 활성화된 가중치 행렬을 곱하여 최종 출력 Z 생성
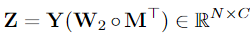
SegFormer 동작 방식 다시 공부, W1, W2가 의미하는 것?(FFN의 Layer1, 2를 의미?)
전치행렬을 한번 더 곱해주는 이유?
첫 번째 M을 곱해주는 Y=X(W1⊙M) 부분은 입력 X에서 중요하지 않은 뉴런을 제거하고 중요한 뉴런만 반영한 결과를 만드는 과정
-> 입력 데이터에서 중요한 정보만 남겨놓는 역할(두 번째 M^T를 곱해주는 Y=X(W2⊙M^T)부분은 W2의 차원에 맞게 M도 전치시킴)
두 번째 M을 곱해주는 이유는 뉴런 간의 관계 중요도를 나타내기 위해 함
첫 번째 레이어에서는 뉴런 단위로 Pruning을 수행했지만, 두 번째 레이어에서는 관계 단위로 최적화하여 중요한 관계를 보존하면서도 계산량을 줄인다.
활성화함수와 편향 없이도 선형 변환을 대체할 수 있는 이유?
M은 𝑊1와𝑊2에 곱해지며, 중요하지 않은 뉴런을 제거(비활성화)한다.
따라서, Mix-FFN에서 활성화 함수로 얻는 비선형성의 효과를 마스크
𝑀가 대체
- DGL은 𝑀를 통해 뉴런 간의 관계를 동적으로 조정하므로, 별도의 활성화 함수 없이도 충분히 복잡한 표현을 학습
- 마스크𝑀 자체가 입력 데이터를 동적으로 반영하므로, 편향의 역할이 이미 포함되어 있다고 볼 수 있다.
SegFormer 동작
최종적인 Stage의 결과는 MLP디코더로 전달됨

게이트 예측기 설계
게이트 예측기는 입력 X에 대해 평균 풀링과 레이어 정규화를 수행하여 입력 특징을 요약한다.
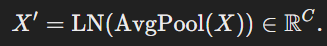
요약된 입력 X와 선형 계층 W1을 두 개의 MLP계층에 입력하여 게이트 M을 생성한다.
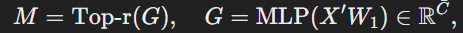
여기서 Top-r(.)은 상위 r%의 값을 유지하고 나머지는 0으로 설정한다.
점진적 희소화
희소화 비율 rt는 학습 초기에는 낮게 시작하여, 학습이 진행됨에 따라 점진적으로 증가한다.

여기서 t는 현재 학습 단계이고 T는 총 학습 단계 수이다.
학습 초기에 뉴런을 지나치게 많이 가지치기하면 모델이 제대로 학습하지 못할 수 있기에 초기 학습 단계에서는 모델이 모든 뉴런을 사용해 충분히 데이터를 학습하게 하고, 학습이 진행됨에 따라 점점 비정보성 뉴런을 가치치기한다.
희소성 제약을 강화하기 위해, G에 대해 L1정규화를 적용하여 선택된 뉴런을 제어한다.
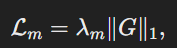
DGL은 MiT인코더의 Q,K,V와 Mix-FFN의 중간 계층에서 계산을 줄이기 위해 적용된다.
MLP 디코더에서는 단계별 특징 맵의 결합 방식을 덧셈으로 대체하여 추가적인 계산 절감을 달성한다.
DGL의 핵심 아이디어는 중요한 뉴런만 골라서 계산하는 것으로, 입력 데이터를 보고 어떤 뉴런을 비활성화할지를 판단한다.
1. 입력데이터 분석
DGL은 먼저 입력데이터를 분석하여 뉴런의 중요도 점수를 계산한다.
- 입력 데이터 X를 받아서 게이트 예측기라는 모듈이 중요도를 평가한다.
- 이 점수를 기반으로 중요한 뉴런만 골라냄(활성화/비활성화는 게이트 생성 단계에서 결정)
- 게이트 생성
2-1.입력 데이터를 압축하여 작은 크기의 특징(요약 정보)를 만든다.
-X -> 평균 풀링과 정규화 -> X'
- 불필요한 뉴런을 제거하면서도 중요한 정보를 유지하기 위함
2-2. X'와 첫 번째 선형 계층의 가중치 W1을 사용해 중요도 점수를 계산한다.
2-3. 상위 r%의 뉴런만 선택하고 나머지는 비활성화
- 필요한 뉴런만 계산
첫 번째 선형 계층이 입력 데이터를 압축하고, 두 번째 선형 계층이 데이터를 다시 복원한다.
3.2. Training with Knowledge Distillation(지식 증류)
동적으로 가지치기된 SegFormer는 필연적으로 원래 모델에서 지식을 잃게 된다. 동적 가지치기로 인해 발생하는 격차를 줄이기 위해, 우리는 두 단계 지식 증류를 사용한다.
이는 트랜스포머 기반 모델에서 뛰어난 성능을 보여주는 방법이다.
가지치기를 하면 교사 모델이 가지고 있던 세부적인 정보가 손실될 수 있다. 이러한 정보 손실은 성능 저하로 이어질 가능성이 있다.
지식 증류는 이런 문제를 해결하기 위해 교사모델(원래 SegFormer)에서 학생 모델(가지치기된 SegFormer)로 정보를 전달하는 과정이다.
첫 번째 단계에서는, SegFormer의 각 블록에서 교사 모델의 출력과 학생 모델의 출력 간의 평균 제곱 오차를 최소화한다.
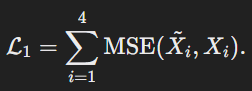
이를 통해 학생 모델이 교사 모델의 중간 표현을 학습하도록 돕는다.
SegFormer는 여러 블록으로 구성되어 있고, 각 블록은 입력 데이터를 처리하면서 중간 결과를 생성한다.
첫 번째 단계에서는 각 Stage에서의 학생 모델의 출력이 교사 모델의 출력과 비슷해지도록 학습한다.MSE를 사용하여 교사 모델의 중간 결과와 학생 모델의 중간 결과간 차이를 최소화한다.
두 번째 단계에서는 학생 모델이 최종적으로 출력하는 값이 교사 모델의 최종출력값과 실제 정답값까지 비슷해지도록 학습한다.
-
크로스 엔트로피 손실(CE) : 학생 모델의 출력과 실제 정답값 간의 차이를 최소화하기 위해 사용한다.
-
소프트 크로스 엔트로피 손실(SCE) : 교사 모델이 출력한 값과 학생 모델이 출력한 값 간 차이를 줄인다.
전체 손실 함수는 다음과 같다.
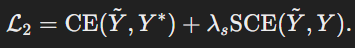
지식 증류의 흐름
블록별 출력 정렬 (1단계):
학생 모델의 중간 결과가 교사 모델의 중간 결과를 따라가도록 학습.
결과: 학생 모델이 교사 모델처럼 데이터를 처리하도록 돕습니다.최종 출력 정렬 (2단계):
학생 모델이 교사 모델의 최종 출력값과 실제 정답 값을 출력하도록 학습.
결과: 학생 모델이 교사 모델 수준의 분할 성능을 발휘하도록 만듭니다.
4. Experiments

DynaSegFormer는 DGL(Dynamic Gated Linear) 레이어를 적용한 SegFormer를 나타낸다.
-
Encoder (인코더)
각 모델에서 사용하는 인코더 아키텍처이다.
예: MobileNet-V2, ResNet-101, MiT-B0, MiT-B2 등.
SegFormer 및 DynaSegFormer는 MiT 인코더를 사용합니다. -
Params (M): 모델 파라미터 수
모델의 파라미터 수를 나타냅니다(단위: 백만 개, M).
값이 작을수록 모델이 더 경량이다.
DynaSegFormer는 SegFormer에 DGL 레이어를 추가하여 약간의 파라미터 증가가 발생합니다. -
ADE20K와 CityScapes
두 데이터셋에서의 성능을 나타냅니다:
FLOPs (G): 연산량(단위: Giga FLOPs). 값이 작을수록 효율적입니다.
mIoU (%): Mean Intersection over Union, 즉 모델의 정확도를 나타내는 지표. 값이 클수록 좋습니다. -
Real-Time과 Non Real-Time
모델을 실시간(real-time) 또는 비실시간(non-real-time)으로 분류합니다:
Real-Time: 주로 경량 모델들.
Non Real-Time: 계산량이 많고 높은 정확도를 추구하는 모델들.
결과 분석
Real-Time
- FLOPs:
SegFormer(MiT-B0): 8.4 GFLOPs.
DynaSegFormer(MiT-B0): 3.3~3.8 GFLOPs로 감소 → 계산량 절감. - mIoU:
SegFormer(MiT-B0): 37.4% (ADE20K).
DynaSegFormer(MiT-B0): 35.0%~36.9%로 비슷한 정확도 유지. - CityScapes 데이터셋 성능
DynaSegFormer(MiT-B0): 74.3%~75.1% (SegFormer보다 유사하거나 약간 낮음).
Non Real-Time
-
FLOPs:
- SegFormer(MiT-B2): 45.8 GFLOPs (ADE20K), 285 GFLOPs (CityScapes).
- DynaSegFormer(MiT-B2): 18.518.5 GFLOPs (ADE20K), 185186 GFLOPs (CityScapes).
- 계산량이 크게 줄었음에도 불구하고 성능(mIoU)은 유지되거나 향상됨.
-
mIoU:
- ADE20K 데이터셋:
- SegFormer(MiT-B2): 46.7%.
- DynaSegFormer(MiT-B2): 45.4%.
- CityScapes 데이터셋:
- SegFormer(MiT-B2): 80.4%.
- DynaSegFormer(MiT-B2): 79.8%~81.2% (SegFormer와 비슷하거나 약간 높음).
- ADE20K 데이터셋:
=>연산량 감소
DGL 레이어를 통해 뉴런 가지치기(Pruning)를 수행하여 연산량(FLOPs)을 크게 줄임.
MiT-B0 기반 DynaSegFormer의 FLOPs: 8.4G → 3.3~3.8G.
MiT-B2 기반 DynaSegFormer의 FLOPs: 45.8G → 18.5G.
