REMOTE SENSING VISION-LANGUAGE FOUNDATION MODELS WITHOUT ANNOTATIONS VIA GROUND REMOTE ALIGNMENT
논문
Abstract
이 논문에서는 text 주석 없이 Remote sensing 이미지를 위한 VLM을 training하는 새로운 방법을 제안함
기존에는 image-text pair쌍이 있어야 training이 가능했지만, Remote sensing 이미지는 text 설명이 거의 없다는 한계가 있었다.
<핵심 아이디어>
- Remote sensing 이미지와 text를 직접 alignment하는 대신, 인터넷에서 얻은 지상 이미지를 중간 매개체로 사용한다.
Remote sensing 이미지와 동일한 위치에서 촬영된 지상 사진을 수집하여, 이를 CLIP의 Image encoder와 alignment하도록 training한다.
즉, Remote sensing 이미지 <-> 지상 이미지 <-> Text의 연결을 활용하여, Remote sensing 이미지와 간접적으로 Align한다
- 지상 이미지는 Text 설명이 있기 때문이다
이렇게 학습된 VLM은 text 주석 없이 학습되었음에도 기존의 Supervised learning VLM보다 성능이 뛰어남
Instruction
지구는 Remote sensor에 의해 지속적으로 촬영되고 있으며, 이러한 관측된 이미지는 다양한 지구상의 사건을 모니터링하는 데 활용되고 있다.
이러한 Remote sensing 이미지로부터 자동으로 정보를 추출하는 분석 모델이 개발되었으나, 이러한 모델들은 대부분 Specific한 task에 특화되어 있으며, 미리 정의된 개념만을 인식할 수 있다. 또한, AI 전문가가 아닌 사람들에게 접근성이 떨어진다는 단점이 있다.
기존의 VLM은 인터넷에서 수집한 대량의 image-text pair를 활용하여 training되어 Open-vocabulary recognition 능력을 갖추었다.
Remote sensing 데이터를 통해서도 이런 능력을 적용할 수 있다면 매우 유용할 것이다.
그러나, Open-vocabulary recognition 능력을 갖춘 VLM을 구축하기 위해서는 방대한 양의 image-text pair 데이터가 필요하다.
이러한 데이터 수집은 Remote sensing에서 매우 어렵다
- Remote sensing 이미지는 Remote sensor에 의해 자동으로 생성되므로, 인간의 개입이 거의 없고 text 주석도 존재하지 않는다.
- 기존 연구에서 사람이 직접 text를 추가하려고 했으나, 비용이 많이 들고 전문 지식이 필요하다.
- 그 결과, Remote sensing을 위한 데이터셋은 인터넷 데이터셋 대비 4만배 더 적다.
이러한 도전 과제로 인해 논문에서는 Text 주석 없이 Remote sensing 이미지를 위한 VLM을 구축하는 것을 핵심으로 다룬다.
이 논문에서는 Remote sensing 이미지와 text를 직접 연결하는 대신, 지상 이미지를 매개체로 사용하는 방법을 제안한다.
<핵심 아이디어 - GRAFT>
1. Remote sensing 이미지는 지구의 특정 지역을 촬영한다.
2. 같은 위치를 사람들이 카메라로 촬영한 사진이 인터넷에 존재할 가능성이 크다.
3. 이 지상 이미지와 Remote sensing 이미지를 연결하여, 간접적으로 t언어와 align 시킨다.
즉, Remote sensing 이미지 <-> 지상 이미지 <-> 언어 관계를 활용
- GRAFT 학습 방식
-
인터넷에서 지리적 tag가 포함된 지상 이미지를 수집한다.
-
해당 지리적 tag를 사용하여, 같은 위치의 Remote sensing 이미지를 찾는다.
-
이 Remote sensing - 지상 이미지 쌍을 사용하여, Remote sensing 이미지의 특징을 CLIP의 pre-training된 Image encoder를 활용하여 Alignment한다.
지상 이미지에는 해당 text가 존재한다. 이 지상 이미지를 매개체로 활용하여, Remote sensing 이미지와 언어를 연결할 수 있다.
즉, Remote sensing 이미지가 직접 text와 Align하지 않아도, 같은 위치의 지상 이미지가 CLIP을 통해 언어와 정렬되므로, 위성 이미지도 자연스럽게 언어와 연결될 수 있다.
-
이를 통해 Text 없이도 Remote sensing 이미지가 언어와 정렬되도록 학습된다.
또한, Remote sensing 이미지는 지상 이미지보다 훨씬 넓은 물리적 공간을 포함하기 때문에 Text-to-patch retrieval 모델을 추가로 개발한다.
- 지상 이미지는 호수의 일부만 포함할 수 있지만, Remote sensing 이미지는 전체 호수를 포함할 수 있다.
지상 이미지의 지리적 tag를 활용하여 Remotes sensing 이미지 내에서 해당 위치의 픽셀을 찾아내는 방법을 제안한다.
이를 통해 text 기반으로 remote sensing 이미지에서 특정 영역을 식별하거나, text-image 기반 segmentation을 수행할 수 있다.

Relate work
Foundation Models for Remote Sensing Images
최근 인터넷 Image를 통한 Foundation model의 성공에서 영감을 받아 Remote sensing image를 통한 Foundation model을 연구하는 작업이 시작되었다.
이러한 모델들은 이후에 세부 task 수행을 위한 Fine-tuning이 가능하다.
Foundation model 중 일부는 supervised learning 방식으로 training되며, 다른 model들은 unsupervised learning 기법을 사용한다.
이러한 모델들은 Image encoder로서 효과적이지만. Open-vocabulary recognition을 수행할 수 없다.
Open-vocabulary recognition이 가능하다면 비전문가들도 retrieval이나 QA같은 자연어 인터페이스를 통해 Remote sensing 이미지를 쉽게 분석할 수 있다.
Vision-and-Language Models in Remote sensing
이전 연구에서는 Remote sensing 이미지의 Caption 생성 또는 Retrieval을 위한 VLM을 구축해왔다.
그러나, 이러한 모델들은 기존 인터넷 데이터셋 기반 VLM보다 훨씬 적은 데이터로 훈련되었다.
- 인터넷 이미지의 경우, Crowdsourcing을 통해 자동 생성된 Caption이 포함되는 경우가 많다.
- Remote sensing 이미지는 자동으로 생성되므로 Caption이 없으며, 직접 수집하려면 많은 비용과 노력이 필요하다.
<최근 연구>
-
인터넷에서 대규모 image-texrt pair를 필터링하여, Remote sensing 이미지와 matching하는 방법을 제안하였으나, 다양한 출처에서 수집된 데이터로 인해 데이터 consistency가 부족한 문제가 존재한다.
-
기존 인터넷 이미지를 기반으로 한 모델을 활용하여 fine-tuning하는 접근 방식이 연구되었으나, 이러한 방법은 근본적으로 한계가 있다.
이러한 문제를 해결하기 위해, 지상 이미지를 매개체로 활용하는 GRAFT를 제안한다.
Multi-modality for better recognition
Remote sensing 이미지가 촬영된 같은 위치의 지상 이미지를 활용한다.
여러 modality를 결합하는 방식은 다양한 분야에서 성공을 거두었다.
- text와 image를 함께 활용하는 방식은 인터넷 image 분석에서 성과를 보임
- Remote sensing 분야에서는 다중 스펙트럼 이미지 또는 레이더 센서를 활용하여 위성이 포착한 환경을 보다 정확하게 이해할 수 있다
- 또한, 지리적인 위치 추정을 위한 지상 이미지 modality를 활용하여 Remote sensing 이미지와 지상 이미지를 "명시적으로" 연결할 수 있는 모델을 구축하는 것을 목표로 하였음
이 논문에서는 이러한 연구들과는 다른 접근 방식을 제안
지상 이미지를 매개체로 사용하여 Remote sensing 이미지와 언어를 연결하는 방식을 제시한다
Training VLM without Textual Annotations
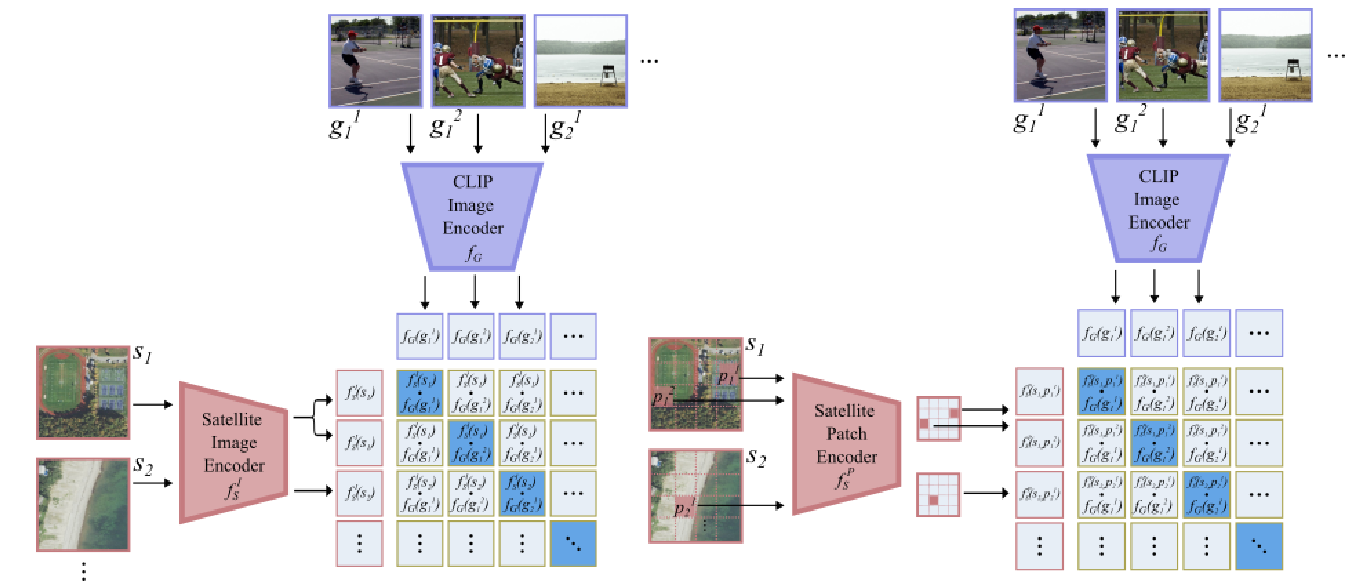
- 이미지 수준의 VLM을 GRAFT로 학습(왼쪽)
- 픽셀 수준의 VLM을 GRAFT로 학습(오른쪽)
GRAFT : Ground Remote Alignment For Training VLMs
이 논문에서는 두 가지 수준에서 작동하는 VLM을 구축한다.
- 이미지 수준
- 픽셀 수준
이미지 수준 모델
- 위성 이미지를 전체적으로 이해해야 하는 작업 수행
ex) Text-image retrieval, Zero-shot image classification
픽셀 수준 모델
- 정확한 위치가 필요한 경우 사용
ex) Zero-shot segmentation, VQA
기존의 VLM은 Image-text pair를 공통된 representation 공간으로 매핑한다.
이 논문에서 목표로 하는 VLM을 구축하기 위해, Remote sensing 이미지를 이 공통된 representation 공간으로 매핑할 수 있는 Feature extractor(특징 추출기)를 개발할 것을 제안한다.
이를 위해 Pre-training 된 CLIP을 사용하여 인터넷의 image-text pair를 공통된 표현 공간으로 매핑한다.
Image-Level VLMs
Remote sensing 이미지를 공통된 representation space()로 매핑하는 Image 수준 feature 추출기()을 구축하려고 한다.
이를 위해 CLIP과 같은 Contrastive learning을 사용하여 Remote sensing 이미지와 해당하는 지상 이미지 pair를 가깝게 Align하고, 관련 없는 Image pair는 멀어지도록 학습한다.
그러나, 기존의 Contrastive learning은 한 모달리티에서 추출한 feature는 다른 모달리티에서 추출된 단 하나의 feature에 매핑된다고 가정한다.
하지만, Remote sensing 이미지는 넓은 지역을 포함하므로, 여러 개의 지상 이미지와 연결될 수 있다.
하나의 Remote sensing 이미지의 Embedding이 해당 지역의 모든 지상 이미지의 Embedding과 가까워지고, 다른 지역의 지상 이미지와는 멀어지도록 학습해야 한다.
- : Remote sensing 이미지
- : 해당 Remote sensing 이미지의 지리적 영역에서 촬영된 개의 지상 이미지
- : 배치 내 Remote sensing 이미지의 개수
이러한 관계를 Loss function을 사용하여 모델링한다.
- : Batch에 포함된 모든 데이터
- : Batch 내의 Remote sensing 이미지 개수
- : 특정 Remote sensing 이미지 에 해당하는 지상 이미지 개수
- 분자는 Remote sensing 이미지 와 해당하는 지상 이미지 간의 유사도를 지수화
- 분모는 Remote sensing 이미지 가 Batch 내 모든 지상 이미지 와 얼마나 유사한지 계산한 값
- : 하이퍼파라미터
일 경우, 이 Loss funtion은 기존 CLIP의 Contrastive learning의 Loss와 동일해진다.
를 Frozen한 상태에서 이미지 수준 특징 추출기()를 학습하기 위해 이 Loss function을 사용한다.

<기존 Contrastive loss와의 차이점>
- CLIP 기반 : 일반적으로 한 image에 하나의 text 설명 -> 1:1 정렬
- GRAFT : 하나의 Remote sensing 이미지는 여러 개의 지상 이미지와 연결될 수 있음 -> 1:N 정렬 필요
Pixel-Level VLMs
Remote sensing 이미지의 Segmentation과 같은 task에는 pixel 수준의 정밀한 위치 정보를 학습할 수 있어야 한다.
이를 위해, 지상 이미지()가 촬영한 정확한 지리적 위치가 Remote sensing 이미지()의 특정 pixel 위치()에 매핑되도록 한다.
이를 활용하기 위해 Pixel-Level 특징 추출기를 학습해야 한다.
Remote sensing 이미지 의 각 pixel 에 대해 특징 벡터를 생성할 수 있는 네트워크 구조를 가정한다.
를 ViT 기반으로 구현하여, Remote sensing 이미지를 겹치지 않는 패치로 나누고, 각 패치에 대한 특징 벡터를 생성한다.
- : Remote sensing 이미지 내 pixel 를 포함하는 패치의 출력 특징 벡터
이 Pixel-Level 특징 추출기를 학습하기 위해 Loss function을 사용한다.
- : Remote sensing 이미지 의 픽셀 에 해당하는 특징 벡터
- : 지상 이미지 의 특징 벡터
- : 두 벡터 간의 cosine similarity를 계산한 후 지수화
- 분자 : 해당 픽셀의 특징 벡터와 올바른 지상 이미지 간 similarity
- 분모 : 해당 픽셀의 특징 벡터와 batch 내 모든 지상 이미지 간 similarity 총합
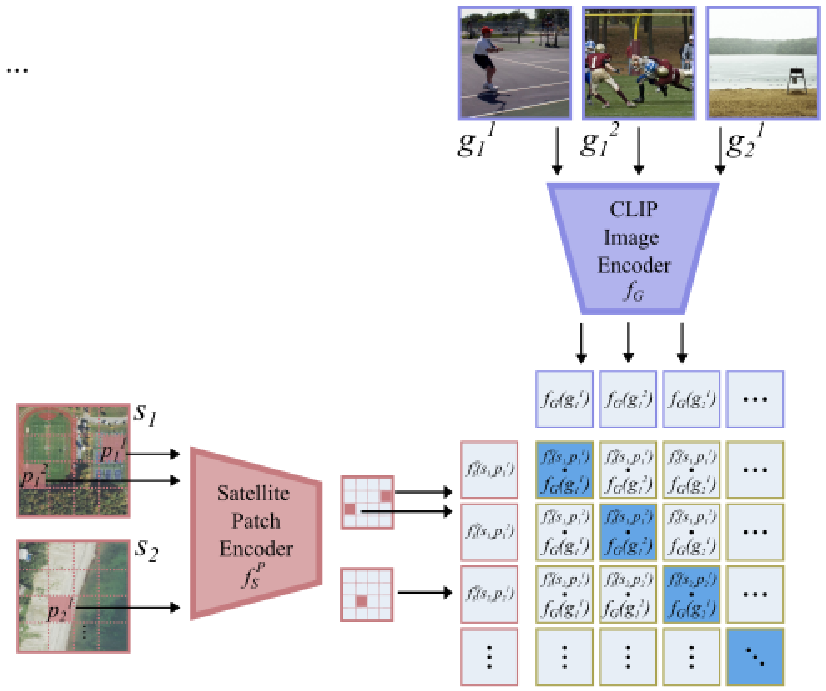
이 Loss function은 특정 Remote sensing 이미지의 특정 pixel이 올바른 지상 이미지와 가까워지고, 다른 지역의 지상 이미지와는 멀어지도록 학습한다.
Collecting Ground-Satellite Image Pairs
모델을 학습하기 위해, 지상 이미지와 Remote sensing 이미지의 쌍으로 이루어진 데이터셋이 필요하다
이를 위해 두 가지 종류의 Remote sensing 이미지 데이터셋을 수집하였다.
- NAIP : 고해상도(1pixel당 1미터)
- Sentinel-2 : 저해상도(1pixel당 10미터)
Ground Images
Flickr에서 지상 이미지를 수집함
다양한 지역의 대표적인 이미지를 얻기 위해
- 특정 인구 밀집 지역만이 아니라 균등하게 여러 위치에서 샘플링
- 정확한 지리적 tag를 가진 중복되지 않는 이미지만 선택
실내 이미지는 Remote sensing과 관련성이 낮으므로, 제거하기 위해
- ResNet18을 활용한 실내-실외 분류기를 사용
실외 이미지만 사용해도 성능 차이가 거의 없었기에 실험의 일관성을 위해
실외 이미지만을 필터링하여 실험의 일관성을 유지하였음
다양한 지역에서 수집한 실외 지상 이미지와 Remote sensing를 연결하여 데이터셋 구축
Remote sensing Images
지상 이미지의 지리적 tag가 있는 위치를 중심으로 Remote sensing 이미지를 샘플링
지상 이미지가 찍힌 곳과 같은 위치의 Remote sensing 이미지를 매칭
모든 지상 이미지는 해당하는 Remote sensing 이미지와 매칭됨
동일한 위치에서 Remote sensing 이미지가 이미 존재하는 경우 추가적인 Remote sensing 이미지 샘플링을 하지 않음
- Remote sensing 이미지 간 과도한 overlap(중복)을 방지(최소 112픽셀 이상 간격 유지)
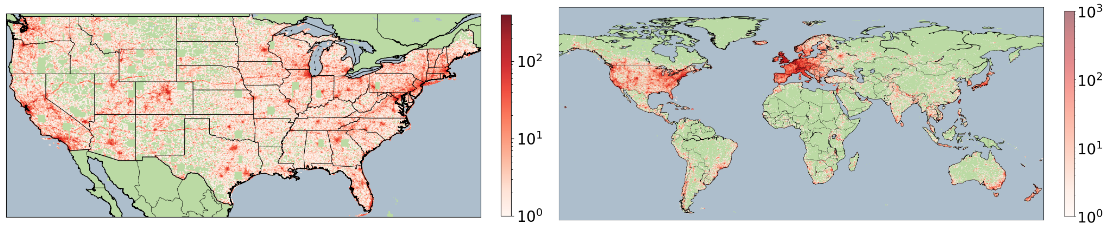
<샘플링 방법>
과도한 데이터 중복을 방지하기 위해, 동일 위치에서 25개 이상의 지상 이미지가 있는 경우, 무작위로 25개만 선택
Augmentation을 위해 224x224 크기가 아닌 448x448 크기의 Remote sensing 이미지를 다운로드함
<위치 및 시간 일관성>
지상 이미지와 Remote sensing 이미지 간 위치 Alignment 유지
Sentinel-2 데이터에서는 시간적인 Alignment도 고려한다.
- 인터넷 이미지가 촬영된 날짜와 가장 가까운 Remote sensing 이미지를 선택(구름 <1%)
- NAIP는 재촬영 주기가 길어(2년에 1회), 이러한 시간적인 Alignment를 적용할 수 없다.
- Sentinel-2는 5일마다 재촬영 가능하므로 시간적인 Alignment가 가능하다.
EarthEngine API를 사용하여 Remote sensing 이미지를 수집하여 최종적으로,
- NAIP : 1,020만 개의 이미지 pair 수집
- Sentinel-2 : 870만 개의 이미지 pair 수집


결과적으로, 공간적, 시간적으로 Alignment된 대규모 데이터셋을 구축하였다.
Enhancing GRAFT VLMs with Foundation Models
GRAFT 모델의 성능은 이미 뛰어나지만 다른 Foundation 모델과 결합하여 성능을 더욱 확장하여 다양한 응용을 가능하게 할 수 있다.
Zero-shot Segmentation
GRAFT의 Fixel-Level 모델은 이미 Segmentation task를 수행할 수 있다.
하지만 SAM과 결합하면 성능을 더욱 향상시킬 수 있다.
GRAFT 모델을 사용하여, 가장 높은 점수를 가진 패치를 선택
점수를 측정하는 과정이 기술되지 않았는데 위의 내용을 고려했을 때, 각 Pixel과 지상 이미지간 Cosine similarity로 점수를 계산했을 것으로 생각
선택된 패치의 중심을 SAM에 point prompt로 제공
SAM을 활용하여 더 정교한 Segmentation 수행
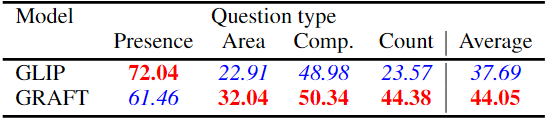
VQA
GRAFT는 기본적으로 간단한 질문에 답할 수 있지만, 복잡한 질문이 필요한 경우, 추가적인 모델이 필요하다.
ViperGPT와 결합하여 자연어 Question을 복잡한 논리 연산으로 변환한다.
ViperGPT는 LLM을 사용하여 자연어 질이를 프로그램으로 변환하여, 변환된 프로그램이 Open-vocabulary object detector를 호출
기존의 ViperGPT는 GLIP 기반 detector를 사용하지만, GRAFT pixel-level 모델로 대체하여 활용한다.
Implementation Details
기본 모델을 ViT-B/16을 사용하여 구축하였고, 일부 실험에서는 기본 모델과의 공정한 비교를 위해 ViT-B/32와 비교하여 분석하였다.
모든 모델은 CLIP의 Image encoder로 초기화되었다.
Experiments
Image-Level Understanding
GRAFT 모델이 Image-Level의 task에 대해 어떻게 성능을 보이는지 분석
-
Zero-shot Image Classification
이미지에 적절한 텍스트 라벨을 할당하는 작업
-
Zero-shot Text-Image Retrieval
특정 텍스트 쿼리와 관련된 모든 이미지를 검색하는 작업
<데이터셋 및 평가>
Sentinel-2 데이터셋으로 학습된 모델의 벤치마크
- EuroSAT
- BigEarthNet
NAIP 데이터셋으로 학습된 모델의 벤치마크
- SAT-4/Sat-6
- OpenStreetMap 기반 멀티라벨 데이터셋
<기준 모델>
CLIP을 기본 비교 모델로 설정
기존에는 텍스트 annotation없이 학습된 VLM이 없었음
따라서, Supervised-learning 방식으로 텍스트 annotation과 함께 학습된 모델과 비교
- CLIP-RSICD
- RemoteCLIP
또한, 기존의 Zero-shot 모델 외에서, one-shot 학습을 수행한 모델과 비교
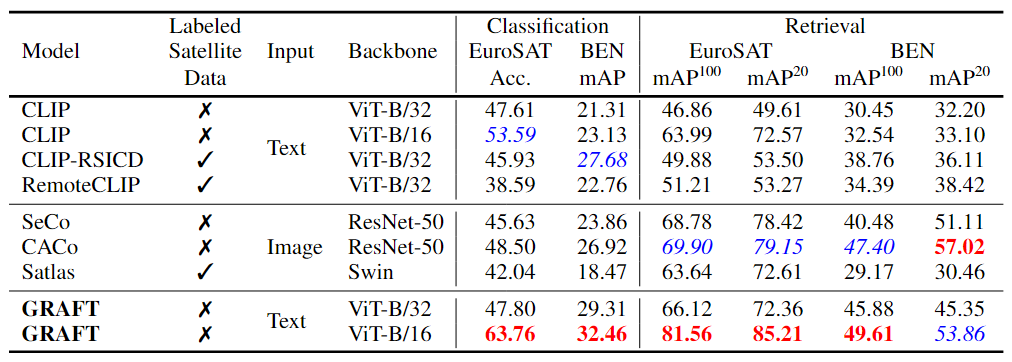
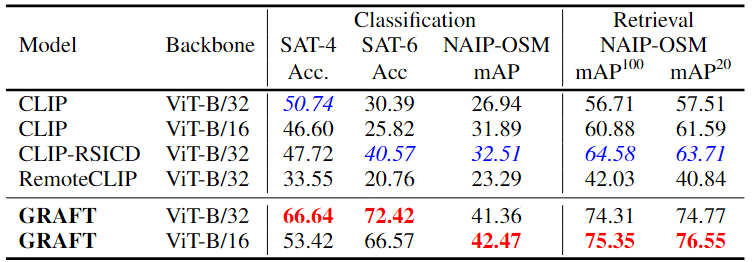
GRAFT 모델의 대부분의 데이터셋에서 다른 모델들을 능가함
- GRAFT는 텍스트 없이도 기존 수퍼바이즈드 모델보다 더 높은 성능을 보임
- 특히, Sentinel-2 데이터를 사용한 EuroSAT, BigEarthNet에서 기존 모델보다 월등한 성능을 기록
- 지도학습 기반 모델보다, 대량의 지상-위성 이미지 쌍을 활용하는 GRAFT 방식이 더 효과적임
즉, GRAFT는 텍스트 없이도 강력한 성능을 발휘하며, 기존 학습 방법보다 더 효율적임을 입증
Pixel-Level Understanding
GRAFT의 Pixel-Level 모델을 Zero-shot Segmentation task에서 평가하였다.
이 실험은 두 가지 벤치마크에서 수행됨
- NAIP 해상도
- Sentinel-2 해상도
<비교 모델>
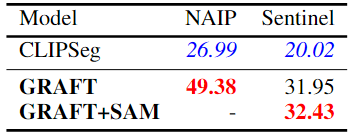
GRAFT 모델을 CLIPSeg와 비교
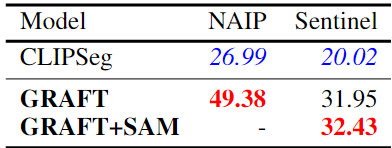
<실험 결과>
GRAFT는 Pixel-Level Segmentation에서도 강력한 성능을 보임
- NAIP 데이터에서는 기존 모델 대비 성능을 2배 가까이 향상
- Sentinel-2 데이터에서도 50% 이상의 성능 향상
- GRAFT는 별도의 지도 학습 없이도 뛰어난 zero-shot Segmentation 성능을 달성 가능
GRAFT는 픽셀 수준에서도 강력한 zero-shot 성능을 발휘하며, 기존 CLIP 기반 모델보다 훨씬 효과적이다

비밀 댓글입니다.