Abstract
대규모 비전-언어 모델(LVLM)은 image와 text의 풍부한 정보를 통합하여 종합적으로 이해할 수 있고, 이를 통해 multi-modal 다운스트림 작업에서 주목할 만한 발전을 이루어냈다.
하지만, LVLM은 크기가 매우 크고 연산량이 많아서, 배포 시 막대한 계산 비용과 에너지 소모로 인해 어려움을 겪는다
VLM은 기본적인 Image, Text를 함께 이해하고 처리하는 모델로 Image classification, Image captioning, VQA등 기본적인 Vision-language task에 활용된다.
LVLM은 VLM의 확장 개념으로 LLM과 결합되어 있어, 더 복잡한 Vision-language 문제를 해결한다.
예를 들어, 단순 Image captioning을 넘어서, 이미지에 대한 심층적인 질문에 답하거나, 이미지 속 맥락을 바탕으로 글을 쓸 수 있다.
- 기존 Pruning 방법
Global pruning
- 전체 모델의 중요도를 계산하기 위해 Hessian metrix 같은 복잡한 계산이 필요하여, 대규모 모델에서는 계산 비용이 너무 크다
가중치를 전역적으로 고려?
모델의 모든 layer에 있는 가중치를 한데 모아, 모델 전체의 관점에서 모델 전체 성능에 얼마나 기여하는지 평가
-> Layer별로 희소성이 균일하지 않아 전체 모델의 연산 효율성이 균일하지 않다.
Layer-wise pruning
- 각 layer 내에서만 병렬적으로 가중치의 중요도를 평가하여 Pruning하는 방법은 계산 비용은 적지만, 모델 전체의 관점에서 본 중요도는 반영하지 못해 최적의 Compression 효과를 내지 못한다.
가중치를 각 layer별로 고려?
모델의 각 layer마다 따로 가중치의 중요도를 평가하고, 해당 layer 내부에서만 중요도를 비교하여 일정 비율의 가중치를 제거
- 전체 모델의 중요도를 계산하기 위해 Hessian metrix 같은 복잡한 계산이 필요하여, 대규모 모델에서는 계산 비용이 너무 크다
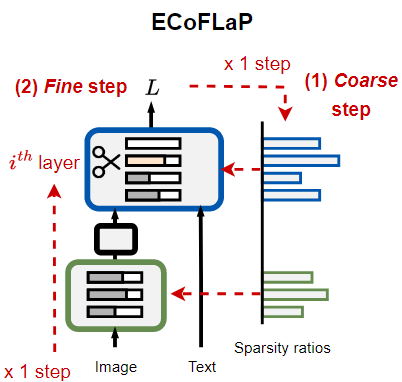
이러한 한계를 극복하기 위해 본 논문에서는 2단계로 이루어진 Efficient Coarse-to-Fine Layer Wise Pruning(ECoFLaP)을 제안한다.
기존의 Pruning 방식은 계산 비용, 최종 모델 성능에 영향을 주기 때문에, 연구에서는 이 두 pruning 방식의 장점을 결합하여 보다 Efficient한 pruning 방법을 제안하고자 함
Introduction
최근 Deep learning 모델들은 현실 세계의 어려운 문제들을 학습하는 데 필요한 용량을 확보하기 위해 매우 크고 복잡해지며 발전해왔다.
이런 대규모 모델은 엄청난 계산량과 메모리를 요구하기 때문에 Resource가 제한된 환경에서의 활용에 한계를 초래한다.
이에 대한 해결책으로, 모델의 성능은 유지하면서 Neural network의 크기를 줄이는 전략인 Model compression이 주목받고 있다.
<대표적인 Model compression 기법>
- Pruning(불필요한 가중치 제거)
- Quantization(숫자의 정밀도를 낮춤)
- Layer drop(일부 계층을 생략)
- Token merging(입력 데이터의 일부를 합침)
본 논문에서는 이 기법들 중에서, Large Vision-Language Model에서 높은 Compression rate에서도 성능을 잘 유지할 수 있는 잠재력을 가진 Unstructured pruning에 대해 연구한다.
<기존 Pruning 기법의 한계>
대부분의 Pruning 기법은 Single modal(Vision, Language)모델에 적용되어 왔으며, VLM과 같은 multi-modal에서의 Efficient한 Pruning은 구조적인 복잡성과 서로 다른 modality간 데이터 특성의 차이 때문에 충분히 연구되지 않았다.
VLM은 Image encoder와 Text encoder처럼 modality별로 특화된 서브 모듈을 결합하여 구성하는데,
이러한 모듈화로 인해 서로 다른 modality에 대응하는 모듈들 간에 가중치와 기울기 분포가 불균형해져, 통합된 방식으로 pruning하기가 어려워진다.
즉, 어떤 modal 모듈의 가중치는 크기가 크거나 기울기가 극단적으로 작을 수 있고, 다른 모달 모듈은 그 반대일 수 있다.
이러한 분포의 불균형으로 인해, 모델 전체를 통합적으로 보면서 어떤 가중치를 제거해야 하는지를 결정하기가 어려워진다.
<제안 기법 : EcoFLaP>
기존의 Global pruning이나 Layer-wise pruning의 한계를 극복하고자 이 논문에서는 EcoFLaP이라는 기법을 제안하였다.
-
먼저, 모델 전체 수준에서 가중치의 중요도를 Coarse(거칠게)하게 추정해 각 Layer별 희소성 비율을 결정하고
이때, global한 saliency(중요도)점수를 계산하기 위해, 1차 또는 2차 기울기를 직접 계산하면 메모리나 연산량이 매우 늘어나기 때문에 단순한 forward(순전파) 연산만으로 근사 기울기를 계산하는 0차 기법을 사용한다.
- 1차 기울기 : 손실 함수의 변화율
- 2차 기울기 : 1차 기울기의 변화율
-
그 다음, 산출된 희소성 비율에 기반하여 실제로 layer별로 가중치를 Fine(정밀)하게 제거한다.
global하게 saliency를 평가하여 층마다 다른 희소성 비율을 설정하기에 기존의 layer-wise pruning의 한계를 극복한다.
<성능>
다양한 모델들과 여러 데이터셋을 적용하여 검증한 결과, 높은 Sparsity에서도 기존의 Pruning 기법들보다 높은 성능을 보여주었고,
0차 기울기를 사용하여 중요도를 계산했을 때, 1차 기울기로 계산할 때보다 GPU 메모리를 최대 40%까지 줄일 수 있었다.
즉, ECoFLaP은 모델의 'Global한 정보'와 'Layer별 정보'를 모두 고려하는 2단계 Pruning 기법으로 효율적이면서 좋은 성능을 보인다.
Related work
Model pruning for transformers
효율적인 모델 학습을 위한 Pruning 기법은 오랫동안 연구되어 왔으며, transformer 기반 모델이 점점 커짐에 따라 더욱 주목받고 있다.
<Pruning 기법>
-
Structured pruning
모델의 모듈 단위로 한 번에 제거하여 모델의 성능은 다소 희생하면서도 추론 속도와 처리량을 가속화하는 데 초점을 맞춘 pruning 기법
-
Unstructured pruning
개별 가중치를 대상으로 중요도에 따라 AI 가속 소프트웨어나 Sparse metrix 계산 기법을 활용하여, 높은 sparsity에서도 모델 성능을 유지하는 데 유리
최근에는 각 Layer별로 가중치를 sparse하게 만드는 SparseGPT, Wanda같은 pruning 기법들이 제안되었으나,
이런 최신 pruning 기법들은 모든 Layer에 동일한 Pruning 비율을 적용하여 각 Layer가 갖는 특성이나 중요도를 충분히 반영하지 못해 Compression 효율이나 성능 면에서 한계가 있다.
이 논문에서는 큰 계산비용을 필요로 하는 전역적인 gradient 계산 없이 각 Layer마다 적절한 sparsity를 동적으로 결정하는 접근법을 제안하여, 기존 방법들의 한계를 극복하고자 한다.
Transformers for vision-language multimodal learning
최근 Transformer 기반의 Vision-language multimodal은 Image와 Text를 동시에 처리할 수 있도록 발전하면서 Classification, Retrieval, few-shot learning, VQA, image/video generation 등 다양한 task에서 좋은 성과를 보여준다.
이러한 Transformer는 Pre-training된 Single-modal을 활용하여, multimodal 모델을 구성할 수 있게 해주며, 이 과정에서 비용이 많이 드는 재학습 과정 없이도 효과적인 multimodal 학습이 가능해졌다.
multimodal을 처음부터 학습하려면, 계산 비용과 많은 리소스를 부담해야 하는데, 이미 각각의 modality에 대해 학습된 모델들을 결합하면, 기존에 학습된 지식을 그대로 활용할 수 있다.
전체 모델을 재학습하는 것이 아닌, 결합된 모델을 task에 맞게
fine-tuning한다.
BACKGROUND: LAYER-WISE PRUNING FOR VISION-LANGUAGE MODELS
PRELIMINARIES: A FRAMEWORK FOR VISION-LANGUAGE MODELS
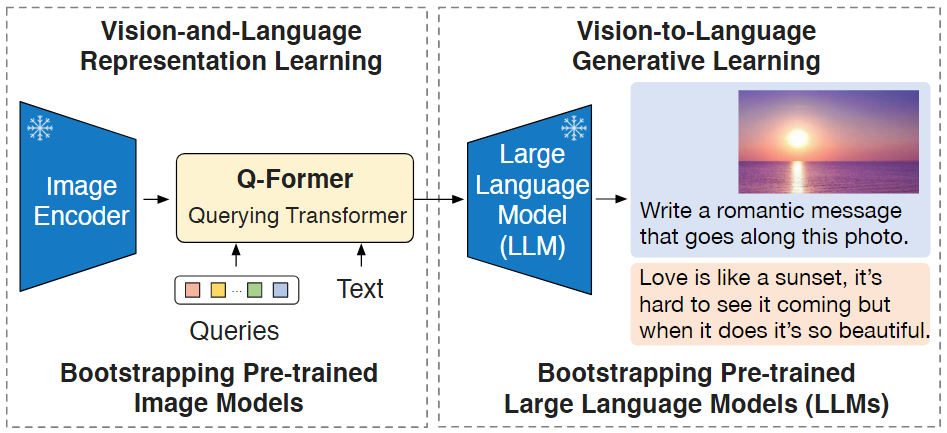
본 논문에서는 대표적인 Vision-Language model인 BLIP, BLIP2를 기반으로 Pruning 기법을 사용한다.
BLIP 계열 모델에서는 Vision encoder와 LLM을 Pre-trained된 상태로 가져와 Frozen한다.(가중치 업데이트X)
즉, 두 모델은 Fine-tuning하지 않고, Q-former라는 작은 모듈만 학습하여 계산 비용과 학습 시간을 크게 절약한다.
BLIP Architecture
Vision encoder()
Pre-training된 ViT를 사용해, Input image()에서 image feature를 추출한다.
가중치 : {} (은 Vision encoder layer 개수)
Language model()
Pre-training된 LLM을 사용하여 Text를 생성한다.
가중치 : {} (은 LLM의 layer 개수)
Q-former()
BLIP에서 사용하는 가벼운 module로, Vision encoder에서 나온 image feature를 받아서, LLM이 이해할 수 있는 형태로 변환한다.
라는 별도의 가중치 집합을 가지며, Vision, Language 모델 사이를 연결하는 중개자 역할을 한다.
Learning process
Input data : Image(), Text()
-
Vision encoder()가 image()를 받아 visual feature를 추출한다.
-
Q-former()는 이 visual feature를 받아, ""라는 align된 embedding을 생성한다.
- : Vision encoder
- LLM()은 최종적으로 []을 받아 결과를 출력한다.

Q-Former가 핵심적인 연결 고리로 작동함으로써, 거대 비전·언어 모델을 별도의 재학습 없이 효과적으로 결합한다.
CHALLENGES IN PRUNING VISION-LANGUAGE MODELS
Global pruning의 접근과 한계
global pruning은 모델 전체 가중치 중, Loss function의 변화량를 최소화하면서 제거할 수 있는 최적의 가중치를 찾아내는 것이 핵심이다.
각 가중치가 Loss function에 미치는 영향을 2차 미분을 이용하여 구한 다음, 영향이 적은 가중치를 pruning
테일러 전개
가중치 w에 대한 Loss function L(w)가 있을 때, w의 값이 조금이라도 변하면 L(w)가 변하고, 실제 Loss function의 형태는 매우 복잡하기 때문에 Loss function의 값을 근사화하기 위해 테일러 전개를 사용한다.테일러 전개를 통해, 가중치를 조금 변경했을 때 손실 함수가 어떻게 변하는지 근사
Pruning에서 특정 가중치 를 제거했을 때 손실이 얼마나 증가하는 지를 추정할 때, 보통 gradient(1차 미분)에 대해서는 가중치의 기여도가 이미 반영되어 있다고 가정하고, 손실값의 변화량인 2차 항에 집중한다.
신경망이 충분히 학습된 후에는, 손실 함수의 기울기가 거의 0에 가까워져 1차 항의 기여가 무시할 수 있을 정도이기에 Loss function의 주된 영향은 2차 항이 차지하게 된다.
Hessian에 기반하여, 모델의 i번째 파라미터의 중요도는 공식을 이용해 측정한다.
은 i번째 가중치를 제거했을 때 모델의 손실의 변화량을 헤시안을 이용해 추정하는 공식으로, 가 클수록 분자가 커지고 분모가 작아져, 손실 함수의 변화량이 커져 매우 중요한 가중치로 해석할 수 있다.
역헤시안()에서 대각 원소 ()값을 이용하여, 어떤 가중치를 제거했을 때, 모델의 손실 정도를 추정한다.
Hessian
Loss function 를 각 가중치 에 대해 2차 미분(gradient의 변화량)을 구한 결과들을 모아놓은 행렬역헤시안
Hessian 행렬의 역행렬로 2차 미분 정보를 반대로 해석할 수 있게 한다.
- 는 역헤시안의 대각 위치에 있는 값으로, i번째 가중치가 손실에 끼치는 변화량을 반영한 값으로 볼 수 있다.
역헤시안을 계산하는 것은 모델 전체 모든 가중치에 대해 2차 미분 연산이 필요하며, LVLM은 파라미터 수가 방대하기 때문에, 메모리와 계산량 측면에서 LVLM에서는 적용이 매우 어렵다.
헤시안 행렬은 모든 파라미터에 대한 2차 미분값을 포함하기 때문에 행렬의 크기가 매우 커져 상당한 메모리 자원이 필요하게 되고, 각 파라미터에 대해 2차 미분 값을 구하는 것은 엄청난 양의 연산을 요구하게 된다.
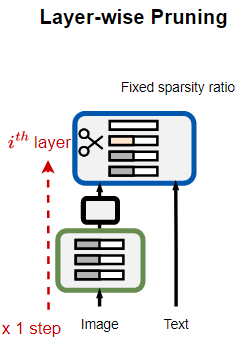
Layer-wise pruning의 한계
Layer-wise pruning은 한 층씩 순차적으로 가중치의 중요도를 계산해 제거하는 방식으로, 한 layer 내 가중치들만 대상으로 중요도를 평가하기 때문에 전체 가중치들의 중요도를 한 번에 평가하는 global pruning과 다르게 계산 비용이 훨씬 적고 메모리 부담도 적다.
Vision-language model은 image encoder와 text encoder가 결합된 형태로, modal별로 가중치, 기울기 분포가 크게 다른데 Local-wise는 각 layer 내부만을 보고 가중치를 pruning하기 때문에, 다른 modal과의 상호작용이나 전역적인 중요도를 반영하기 어렵다.
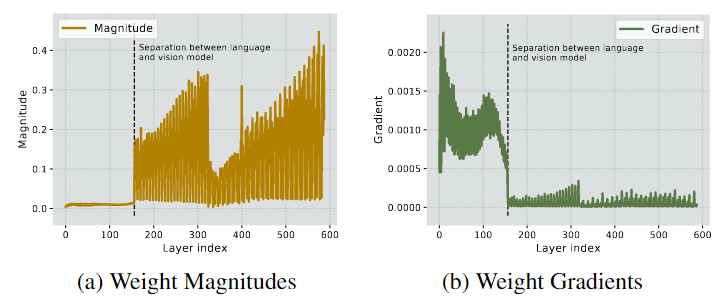
Vision 모듈과 Language 모듈로 구성된 LVLM의 가중치 크기와 기울기 차이를 보여준다.Vision-Language 모델 내부에서 모듈별로 가중치 크기 분포와 기울기 스케일이 다름을 보여준다.
- (a)에서 0~200 layer의 가중치 크기는 작지만, (b)에서 기울기의 크기가 매우 큼
ECoFLaP : EFFICIENT COARSE-TO-FINE LAYER-WISE PRUNING
위에서 언급했듯이, LVLM에 Layer-wise pruning을 적용하는 데에는 크게 세 가지 문제가 있다.
- 서로 다른 modality 간 구조의 불균형
- 매우 큰 모델 규모
- 전역적인 정보의 부족
이러한 중요한 문제들을 해결하기 위해, ECoFLaP을 제안한다.
BLIP 계열의 multimodal 아키텍처를 pruning하는 데 초점을 맞춘다.
BLIP 모델에서 Vision 및 Language 모듈을 compression하되, Q-former는 그대로 유지한다.
Q-former는 전체 모델에서 약 5% 정도의 파라미터만을 차지하는 가벼운 구조이기 때문이다.
THE FRAMEWORK OF COARSE-TO-FINE LAYER-WISE PRUNING
pruning 시, 가중치의 중요도를 평가하기 위한 multimodal 데이터
이 있다고 가정한다.
이 데이터는 training 데이터보다 훨씬 소량이다.
Layer-wise pruning
번째 layer의 pruning된 가중치는 로 나타낸다.
- : 가중치의 중요도를 계산하는 스코어 함수
즉, 가 높아지도록 를 선택한다- : 이전 layer의 pruning된 가중치
(이전 layer의 pruning 결과가 현재 layer에 영향을 줄 수 있어 참고하는 경우가 존재)- : 해당 layer에서의 간단한 loss function으로 가중치 중요도 계산 시 사용
- : 번째 layer의 sparsity로, 가 되도록 하는 제약 조건이다
Layer-wise pruning에서는 모든 layer에 동일한 값을 적용하는 것으로 전체 모델의 sparsity가 50%라면, 모든 layer가 동일하게 50%의 가중치를 pruning한다는 것을 의미한다.
이는 각 layer, 각 module의 중요도가 다를 수 있다는 점을 반영하지 못한다.
Efficient Coarse-to-Fine Layer-wise Pruning (ECoFLaP)
본 논문에서 제안하는 Efficient Coarse-to-Fine Layer-wise Pruning (ECoFLaP) 기법은, Vision-Language 모델의 각 layer에 대해 전역적인 중요도를 활용하여 최적의 sparsity를 추정한 뒤, 실제 pruning을 layer-wise하게 수행한다.
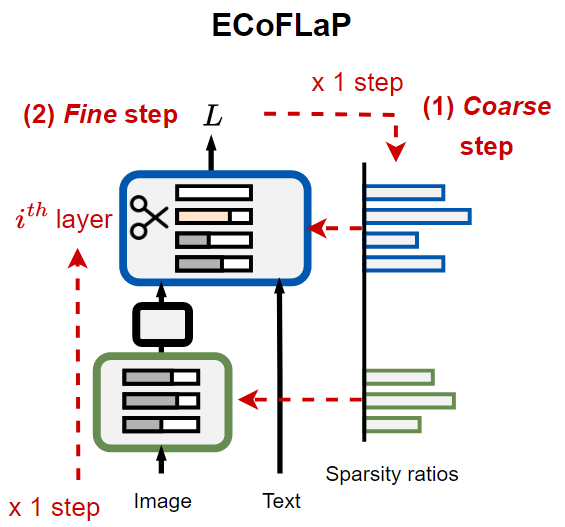
기존의 직관적 접근법
전체 모델의 가중치()에 대해 목표 sparsity p%를 달성하도록 global loss function()에 기반하여 global pruning을 수행한다.
여기서 얻은 를 통해 layer별 sparsity 를 추정한다.
이 방법은 모델 전체에 대한 gradient 계산과 argmax 연산이 필요해, 대규모 모델이 적용하기에는 연산량과 메모리 비용이 매우 크다.
ECoFLaP
ECoFLaP에서는 전역적인 중요도 정보를 효율적으로 계산하면서 각 layer별 sparsity를 산출할 수 있다.
전역 중요도 점수를 이용해 sparsity 비율 산출(Coarse 단계)
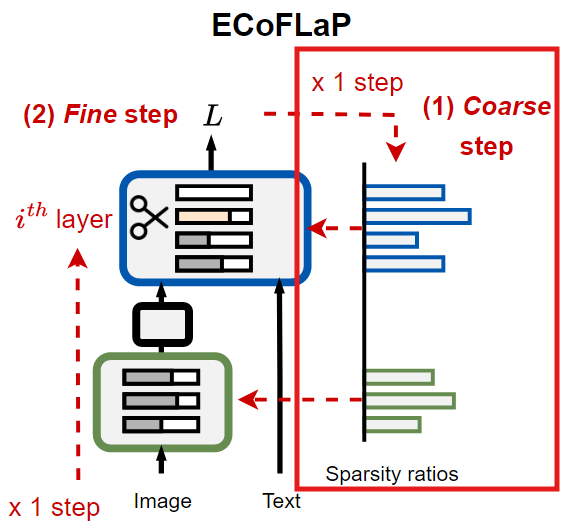
먼저, 전체 모델의 가중치 에 대해, 주어진 데이터 와 전역 loss function 을 이용해 각 가중치가 모델 성능에 얼마나 기여하는지 평가한다.
- : 모든 가중치에 대한 중요도 점수
모델 전체 가중치에 대한 중요도 점수를 계산하면 결국 ECoFLaP도 계산비용이 큰 게 아닌가?
ECoFLaP에서는 0차 기울기를 사용하여 계산하기 때문에 계산 비용이 작다
1. 목표 sparsity 에 따라 남겨야 하는 파라미터 수 계산
- : 전체 가중치 수
2. 각 layer 별 점수 정규화와 sparsity 비율 결정
각 layer 에 대한 중요도 점수 는 전체 모델에 대해 계산된 전역 중요도 점수인 에서 각 layer에 속한 가중치들의 점수의 합이다.
- : i번째 layer의 가중치
<정규화>
각 layer 에 대한 점수 를 전체 가중치 점수 로 나눠, 해당 layer가 전체 중요도에서 차지하는 비중을 구한다.
<layer별 sparsity 비율>
각 layer 가 남겨야 하는 전체 파라미터 수 중에서 몇 개의 파라미터를 유지해야 하는지를, 해당 layer의 파라미터 수 를 기준으로 할당한다.
- (번째 layer가 전체 중요도에서 차지하는 비중)이 낮으면 (번째 layer의 sparsity)가 커져 많이 pruning되고,
높으면 가 낮아져 해당 layer는 적게 pruning된다.
이렇게 함으로써, 전체 모델의 전역적인 중요도 정보를 반영하여, 각 layer마다 다른 sparsity 비율을 동적으로 결정할 수 있다.
에서 데이터셋 에 따라 가 바뀌기 때문에 동적으로 sparsity가 결정된다.
산출된 sparsity 비율로 layer별 pruning(Fine 단계)
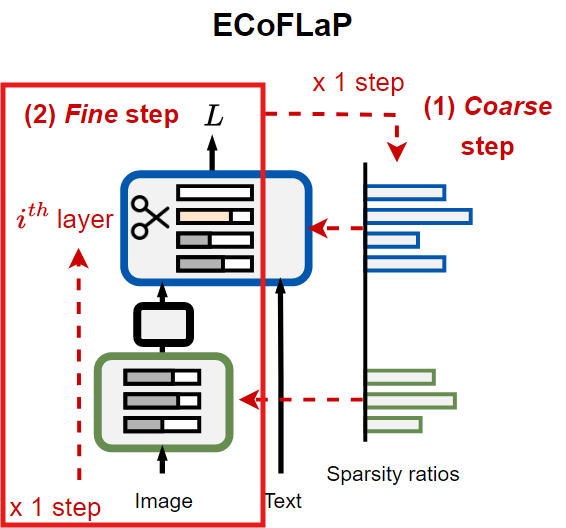
Coarse단계에서 구한 layer별 sparsity 비율을 적용하여, 모델을 layer-wise하게 pruning한다.
- : Wanda 기법 활용
각 가중치의 입력 활성값과 가중치 크기를 곱해 중요도 점수를 계산하여 중요도가 낮은 가중치부터 선택적으로 제거
복잡한 기울기 계산에 의존하지 않고, 단순한 forward 연산에서 구할 수 있는 입력 활성값과 가중치 정보를 활용하기 때문에 계산 비용이 크게 줄어든다.
layer collapse 방지
전역 정보를 그대로 반영했을 때, 어떤 layer는 중요도가 낮게 평가되어 모든 가중치를 제거해버리는 경우가 발생할 수 있다.
- 하이퍼파라미터 도입
각 layer가 가질 수 있는 최대 sparsity(일정 sparsity 이상으로 제거되면 안 된다)를 제한하여, 해당 layer의 최소한의 파라미터를 보존한다.
를 에 반영하려면, 최대 sparsity를 만족하기 위해 각 layer에 필요한 최소 파라미터를 미리 할당하고, 에서 빼 준 뒤 알고리즘을 시작한다.
ZEROTH-ORDER GLOBAL INFORMATION
기존에는 가중치의 중요도를 평가하기 위해서는 backpropagation을 통한 1차 gradient구해 "가중치의 크기 x 기울기"의 형태로 사용했다.
하지만, 파라미터가 수십~수천억 개에 달하는 모델에서는 backpropagation을 통해 모든 파라미터의 gradient를 구하는 것만으로도 메모리, 계산 비용이 매우 크다.
Forward-forward Algorithm
이 논문에서 사용하는 Forward-forward 알고리즘은 backpropagation 없이도 가중치가 loss function에 얼마나 기여하는지 근사적으로 계산할 수 있는 방법이다.
이를 0차(zeroth-order) 근사라고 부르는 이유는, 1차 미분을 직접 계산하지 않고, 오직 forward(활성화 값)연산의 결과만으로 근사하기 때문이다.
단순히 가중치에 gaussian noise를 더하거나 빼면서 Forward 연산만 수행하여, 그 차이를 통해 가중치의 중요도를 추정한다.
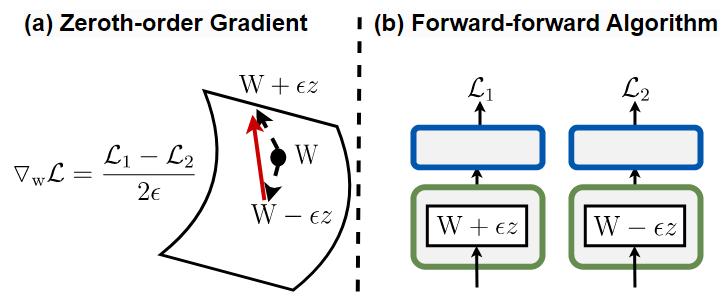
0차 기울기 벡터의 L2 norm -> 가중치의 중요도() - 0차 기울기 벡터
- : 작은 스케일의 noise 크기
- : 정규분포 에서 추출된 noise 벡터
는 "한 번의" 측정으로 가중치 공간에서 더 다양한 방향을 살펴보기 위한 장치
- : 가중치 에 작은 noise 를 더한 상태로 한 번 forward 연산했을 때의 loss
- : 가중치 에 작은 noise 를 뺀 상태로 한 번 forward 연산했을 때의 loss
Forward-forward Algorithm을 통해 구한 를 통해 Zeroth-order gradient를 구하는 수식이다.
Finite difference(유한 차분) 근사
1차원 함수 로부터 도함수 를 구할 때 근사하여 구하는 방식이다.
위와 같이 가중치 에 를 더하거나 빼서 (0차 기울기 벡터)로 근사한 뒤 L2 Norm을 이용하면, 1차 gradient를 구하지 않아도 'w가 조금 변했을 때 손실이 얼마나 바뀌는지'를 이용해 기울기를 추정할 수 있다.
L2 Norm을 사용하는 이유?
Layer별로 그 0차 근사 기울기 벡터()를 전부 다루는 대신, 벡터의 크기(노름)만 사용하면,
“이 레이어가 전체 손실에 얼마나 민감하게 작용하는지”를 하나의 숫자로 압축하여 Layer별 “중요도 점수"로 사용한다.
기존의 backpropagation에서는 활성화값과 gradient를 모두 저장하고 계산해야 하지만, 이 방식은 forward 연산만하면 되기 때문에 메모리와 연산량을 크게 줄일 수 있다.
이 방식으로 모델 전체에 대해 forward 연산을 하며 가중치의 중요도를 추정하면, global한 중요도를 알 수 있다.
이 global한 중요도를 각 layer별 sparsity에 활용한다.
Experiments
Architecture
- BLIP : ViT + BERT
- BLIP2 : EVA-ViT + FlanT5
Dataset
- VQAv2, OK-VQA, GQA : VQA task
- NoCaps, COCO captions : Image captioning task
- Flickr30k : Image-text retrieval task
Pruner
- Global Magnitude Pruning : 전역적으로 모든 가중치의 크기를 보고, 작은 것부터 제거하는 전통적 글로벌 프루닝 기법
- Gradient-based Pruning : 1차 역전파 기울기(기울기 × 가중치 크기)를 이용해 중요도를 계산하고, 여러 번 반복(iterative)하며 3단계로 목표 희소성에 도달하는 방식
- SparseGPT : 헤시안 근사 정보를 활용하여 각 층에서 가중치를 제거. GPT 등 대규모 언어 모델에 적용되는 방식
- Wanda : 가중치 크기 × 입력 활성값(norm)을 이용해 로컬 중요도를 측정하고, 동일한 층별 프루닝 비율로 가중치를 제거
- UPop : 비전-언어 모델을 프루닝과 재학습을 동시에 진행하는 “통합(progressive) 프루닝” 방식
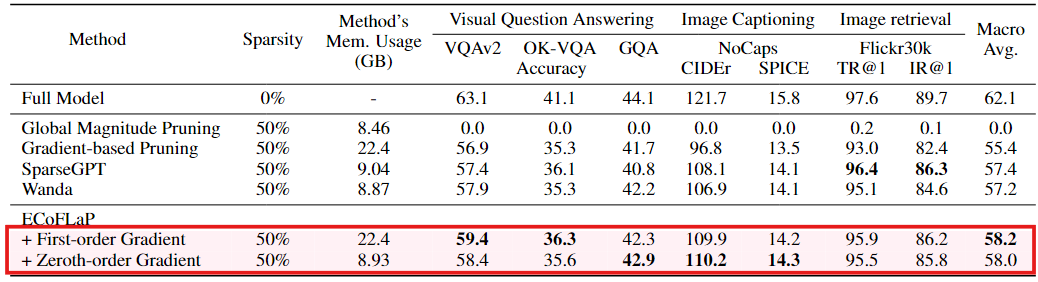
- ECoFLaP이 Gradient-based Pruning, SparseGPT, Wanda, Global Magnitude Pruning보다 전반적으로 높은 성능을 보임
- 메모리 사용량 측면에서도, 0차 기울기 방식을 활용할 경우 기존 기울기 기반 방법 대비 훨씬 적게 듦

요새 포스팅이 안올라오네요,,,
좋은 포스트 부탁드립니다,,,