Abstract
Structured pruning은 계산 비용 및 메모리 사용을 줄일 수 있지만, structured하게 잘라내어졌기 때문에 Retrain이 필요하여 cost가 많이 드는 경우가 많다.
이를 해결하기 위해, One-shot structured pruning 방법인 variance based pruning을 도입하였다.
1. Introduction
Vision/Text transformer는 CV와 NLP에서 가장 보편적으로 사용되는 아키텍처이지만, training/storage/inference라는 세 가지 주요 영역에서 상당한 cost를 요구한다.
이 세 가지 주요 영역에서의 문제를 동시에 해결하는 건 어렵다
예를 들어 training cost문제를 해결하기 위해 Pre-trained 모델을 사용한다고 해도, Stroage/Inference 문제를 해결할 수 없다.
이를 해결하기 위해 Pruning이라는 방법이 존재한다.
-
Unstructured pruning은 pre-trained 모델에서 아주 높은 accuracy를 유지할 수 있지만, 이는 이론적인 성능일 뿐, 실제 속도 향상으로 전환시키기는 어렵다.
-
Structured pruning은 inference와 memory의 cost를 모두 줄일 수 있지만, 넓은 범위의 pruning으로 인해 손실된 accuracy를 회복하기 위해 retrain이 필요하여 추가적인 cost가 필요하다.
-
Token pruning과 같은 동적 pruning 방식은 모델의 아키텍처를 수정하지 않고, 모델에서 처리하는 feature의 개수를 동적으로 줄이며 pruning 후 accuracy 하락을 최소화하지만, 리소스가 제한된 하드웨어에서는 한계가 존재한다.
본 논문에서는 최소한의 fine-tuning으로 속도 향상과 메모리 절약을 제공하는 Variance based strucutured pruning을 소개한다.
다양한 아키텍처에 배포할 수 있도록 transformer block 내 MLP layer에만 pruning을 수행한다.
-
Welford's algorithm을 사용하여 layer내 활성화 값의 통계를 활용한다.
-
이 통계를 이용하여 영향력이 가장 작은 가중치를 식별 후 제거한다.
-
제거된 뉴런의 평균 활성화 값을 사용하여 평균 기여도를 계산한 후, 출력 layer의 bias에 재분배함으로써 보상을 주어 accuracy 저하를 완화한다.
2. Related work
2.1 Transformer Architectures
Transformer 아키텍처가 NLP에 처음 도입된 후 CV에 도입되고 나서는 대부분의 CNN은 ViT로 대체되고 있다.
Transformer 아키텍처를 기밥으로 한 모델들은 좋은 성능을 보여주며 발전하였지만, inference 속도와 memory 요구 사항에 상당한 영향을 미치는 MLP layer로 인해 계산 비용이 매우 높다.
2.2 Model compression
대규모 모델의 cost를 줄이기 위한 model comperssion은 모델의 다양한 구성 요소를 compress하는 데 중점을 둔다.
Pruning은 네트워크 내 중복된 구조를 식별하고 제거하는 데 중점을 둔다.
Structured pruning은 전체 뉴런, layer, filter를 제거하여 하드웨어에서 직접적인 계산 비용을 줄일 수 있는 작은 크기의 행렬로 만든다.
이러한 Structured pruning으로 인한 구조에 직접적인 수정은 성능에 상당한 영향을 미치게 되어, accuracy 회복을 위한 반복적인 retrain 비용을 필요로 한다.
이에 대한 대안으로 Dynamic pruning이 있는데, 이는 inference 중에 feature의 하위 집합만 동적으로 처리하거나, feature 간 결합을 통해 비용을 절감하는 방식이다.
하지만 이러한 방법은 memory 사용량은 줄일 수 없다.
2.3 Our Approach
본 논문에서는 Variance가 낮은 활성화 뉴런을 제거함으로써 structured pruning의 장점과 dynamic pruning의 장점을 결합하여 아이디어를 구축하였다.
NLP와 CV 모두에 대해 training된 transformer에서의 MLP layer 내 뉴런이 전체 feature에 대한 상당한 기여를 보인다는 사실에 기반하여 variance based structured pruning을 MLP layer에 적용하는 방법을 제공한다.
MLP 계층이 계산 비용에 크게 기여하는 transformer와 같은 아키텍처에서 특히 유용하다.
3. Method
1. Activation statics computation : Welford's algorithm
2. Variance based pruning : 가장 낮은 활성화 분산을 기준으로 pruning
3. Mean-shift compenstation : Pruning될 뉴런의 평균 활성화가 output bias에 다시 추가된다.
3.1 Step 1: Activation Statistics Computation
본 논문의 method는 간단하면서 범용적으로 사용될 수 있는 방법을 목적으로 하기 때문에, MLP layer만 pruning한다..
이를 위해서는 input과 output의 dimesion을 일관되게 유지하여 나머지 모듈과 통합되도록 하기 위해, intput/output layer는 그대로 유지하면서 hidden layer를 pruning해야 한다.
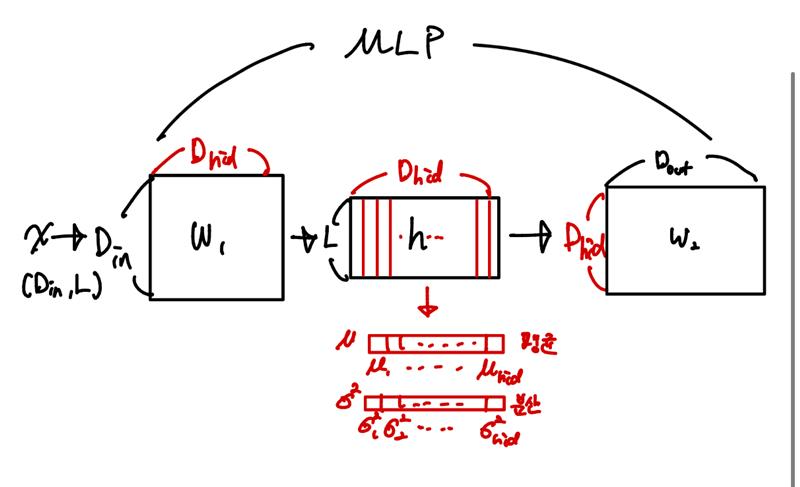
따라서, Input vector 을 output vector 에 매핑하는 차원의 single hidden layer를 가진 MLP를 목표로 한다.
MLP 구조
이 MLP layer에서 입력 를 받아 만들어진 hidden layer의 활성화 값에 대해 평균과 분산을 모아 평균 벡터/분산 벡터를 만든다.

이러한 통계를 계산하기 위해 모든 batch에 대한 활성화 값 를 저장하고 iterative하게 들어오는 data를 효율적으로 계산하기 위한 Welford's algorithm을 사용하여 평균 와 열별 (현재 값 - 평균)의 누적합 을 계산한다.
총 N개의 data sample이 주어졌을 때, j번째 샘플의 활성화 값은 이다.
Welford's algorithm은 j번째 샘플을 관찰한 후 평균 와 누적합 를 업데이트하여 수치적으로 안정적인 계산을 보장한다.
- 평균 update :
- 누적합 update :
N개의 sample이 모두 처리되면 분산을 계산할 수 있게 된다.

3.2 Step 2: Variance-Based Pruning
Welford's algorithm으로 구한 분산 벡터 를 사용하여 분산 값인 를 기준으로 순위를 매긴다.
<분산의 의미>
직관적으로, 활성화값이 평균 에서 거의 벗어나지 않는다면 해당 뉴런은 네트워크의 표현력에 덜 기여하는 것이다.
- 분산이 작으면 네트워크에 덜 기여한다. -> 잘라내도 손실이 적다
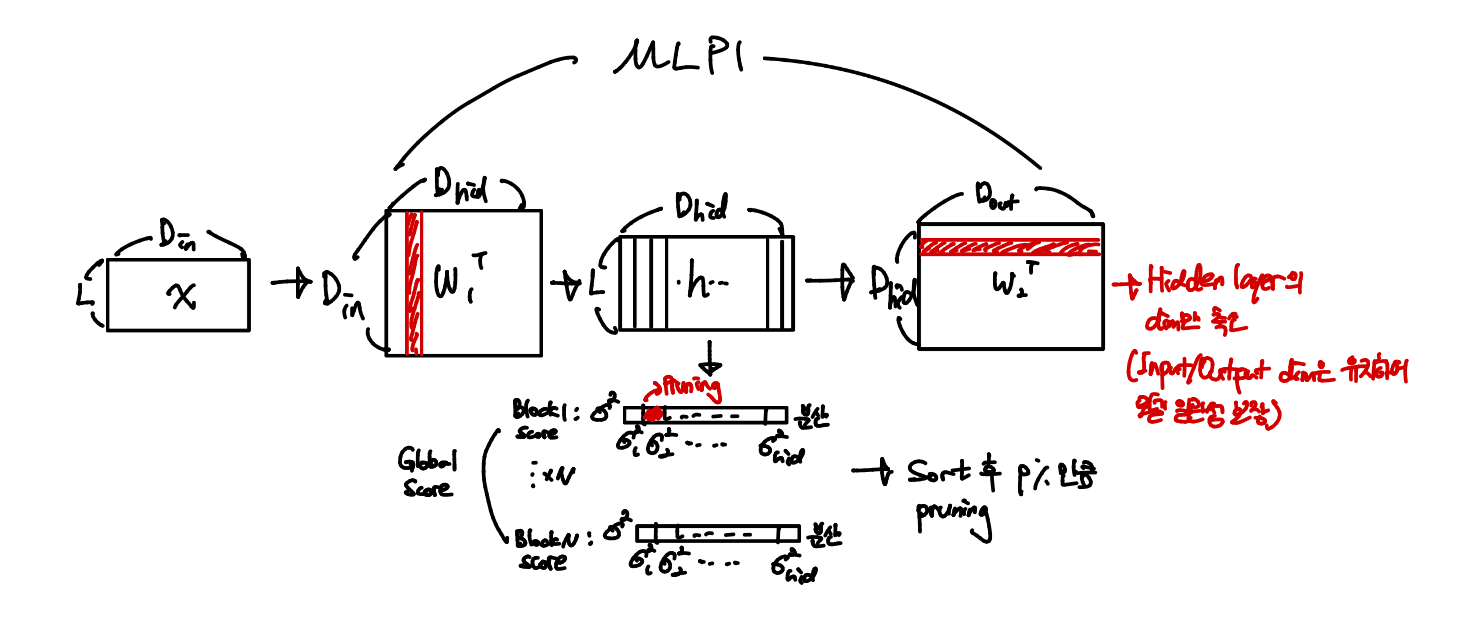
모든 layer에서 분산이 가장 작은 뉴런을 찾기 위해 모든 hidden layer에 대해 분산을 구해 pruning을 결정한다.
Sparsity가 주어지면 Global하게 score 집합 를 형성하고 이중에서 가장 작은 score를 가진 %의 뉴런을 선택해 pruning을 수행한다.
Layer별 고정 비율이 아닌 전 layer를 통틀어 작은 분산 순으로 잘라낸다.
3.3 Step 3: Mean-Shift Compensation
Pruning 후 출력을 최대한 보존하기 위해, pruning될 활성화값 을 평균값으로 대체한다.
평균값은 분산이 0 = 편차가 작을 수록 분산이 작다
- 기존 출력 = Pruning에서 살아남은 뉴런의 output + Pruning 대상 뉴런 output + bias
(: Pruning될 집합, : Pruning 후 집합)
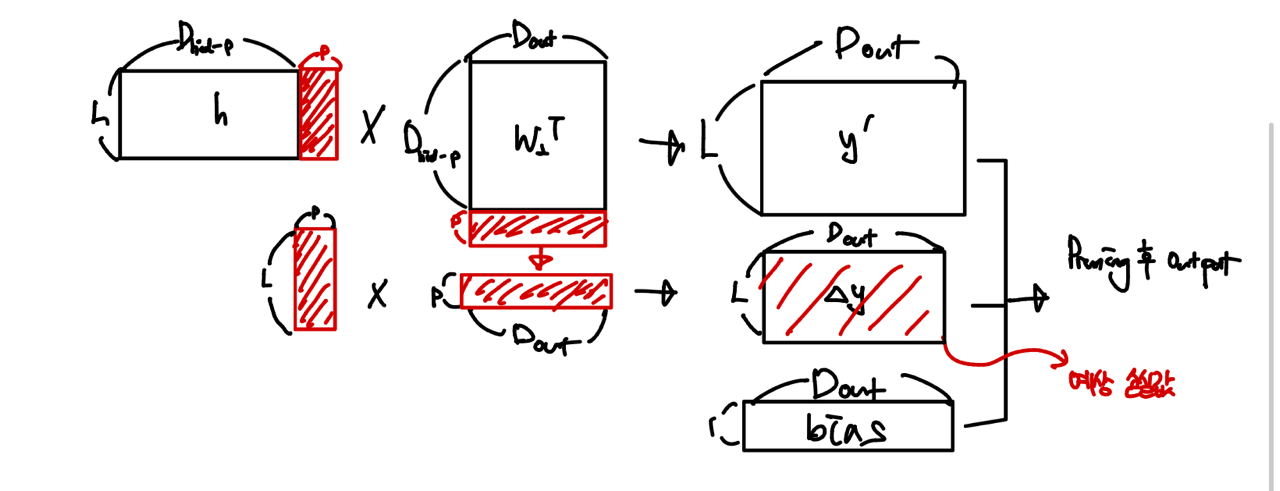
- Pruning 대상 뉴런을 평균값으로 대체한 값을 bias에 흡수
- 실제 pruning 후 값
- 출력 오차
- 왜 평균 + 편차?
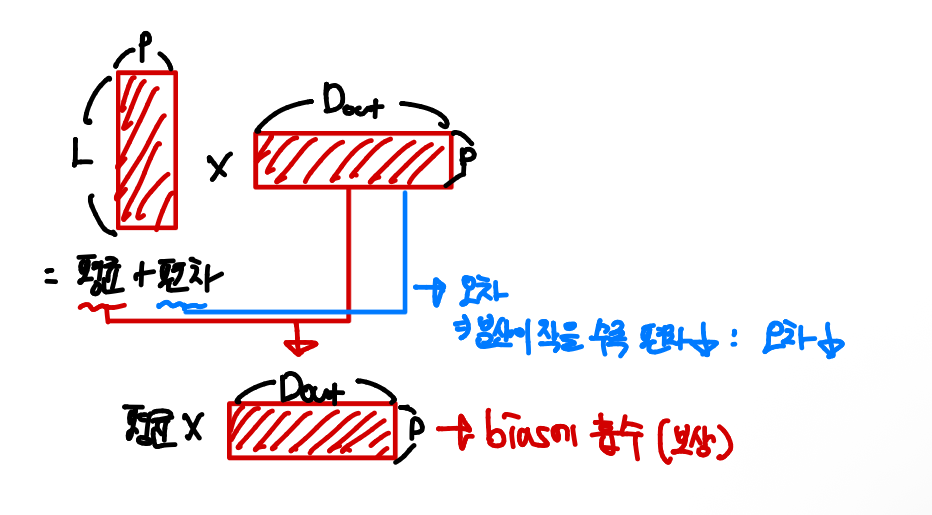
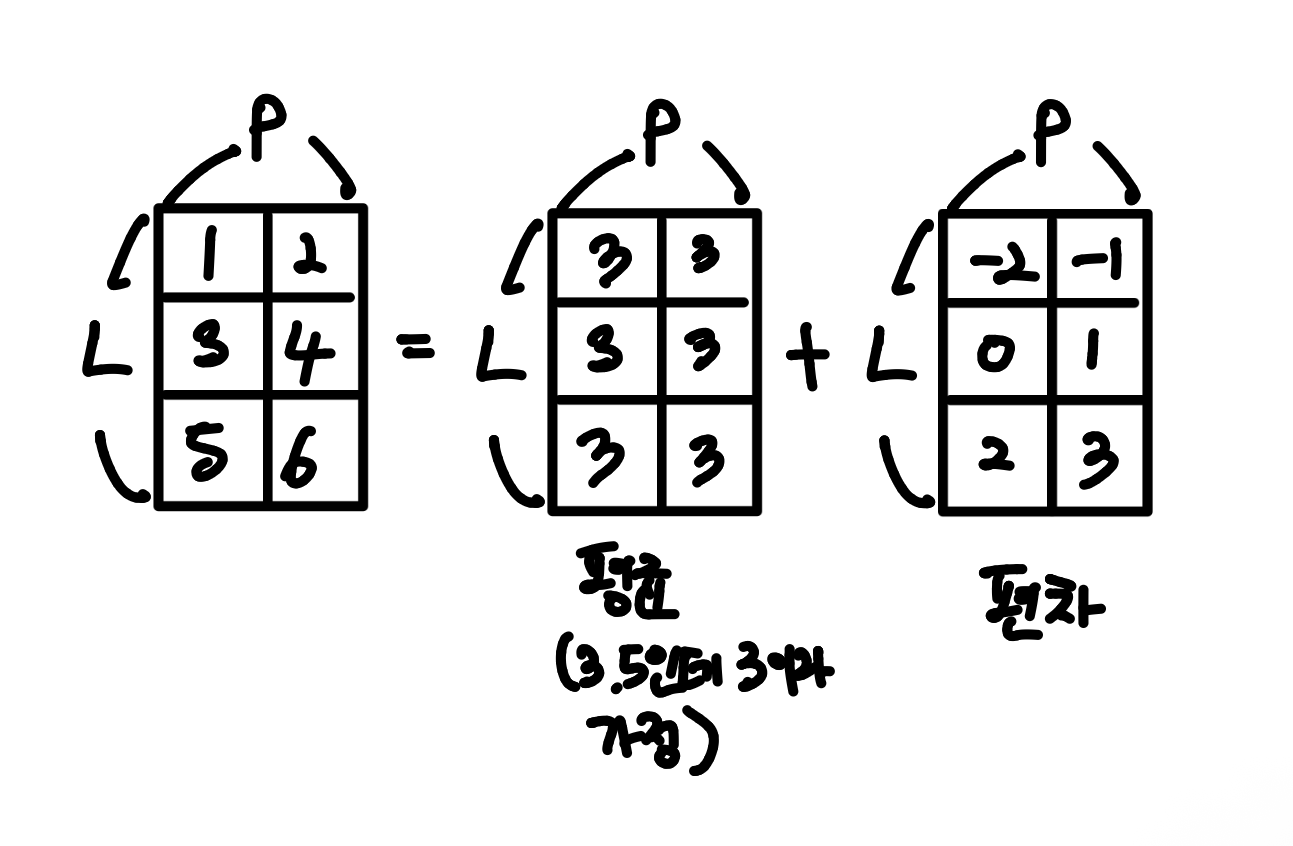
- 평균제곱오차
평균으로 대체했을 때의 최소 MSE가 분산이다
Pruning할 뉴런을 평균으로 바꿨다고 본 뒤에, 그 해당 뉴런의 기여를 bias에 흡수하면, 남는 오차는 분산만큼이고, 그래서 분산이 가장 작은 뉴런부터 자르는 게 이론적으로 합리적이다.

Data-driven한 structured pruning 기법 이군요!