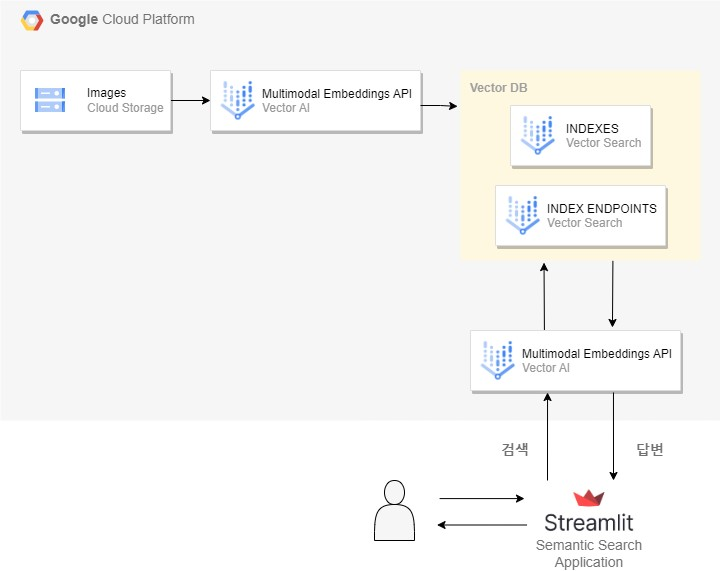
이미지에 대한 Semantic Search 어플리케이션을 만들어볼 것이다.
사용할 임베딩 모델과 벡터 DB는 GCP Vertex AI의 Multimodal Embeddings, Vector Search이다.
Workflow
1. 모든 이미지를 GCS 저장소에 업로드.
2. Vertex AI Multimodal Embeddings를 활용해 이미지에 대한 임베딩값 생성 후, 벡터 DB(Vertex AI Vecter Search)에 저장.
3. 웹 기반 검색 엔진 UI(streamlit 사용)를 통해 사용자가 검색 쿼리를 전송.
4. 해당 텍스트를 다시 Vertex AI Multimodal Embeddings를 사용해 임베딩 값으로 전환.
5. Vector Search의 datapoints들과의 유사도를 측정하여 가장 관련성 높은 결과를 반환.
아키텍처
사전 작업
작업을 하기 위해선 gcloud 설치및 python 환경을 구성해야 하고 후에 아래 명령어를 실행해야 구글에서 제공하는 Multimodal Embeddings를 클라이언트 라이브러리로 사용할 수 있다.
mkdir multimodalembedding
cd $_
gsutil cp gs://vertex-ai/generative-ai/vision/multimodalembedding/* .
pip3 install -r requirements.txt한도
| 한도 | 값 및 설명 |
|---|---|
| 프로젝트별 분당 최대 API 요청 수 | 120 |
| 최대 텍스트 길이 | 토큰 32개 (최대 32단어) 최대 텍스트 길이는 토큰 32개(약 32단어). 입력이 32개 토큰을 초과하면 모델은 내부적으로 입력을 이 길이로 줄임. |
| 언어 | 영어 |
| 이미지 크기 | 20MB 허용되는 최대 이미지 크기는 20MB. 네트워크 지연 시간을 늘리려면 작은 이미지 사용 권장. 또한 이 모델은 이미지 크기를 512x512픽셀 해상도로 조정함. 따라서 더 높은 해상도의 이미지를 제공할 필요가 없음. |
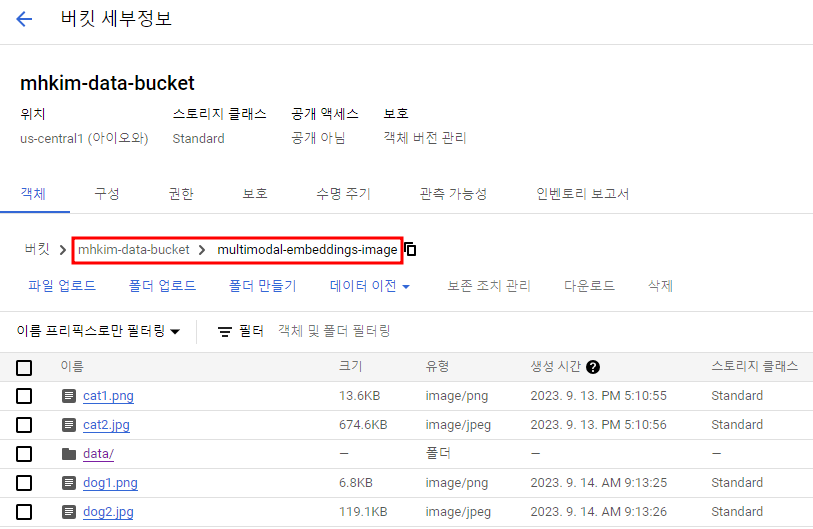
이미지 임베딩
아래 사진과 같은 경로에 이미지를 몇 개 넣어뒀다. 이미지는 강아지 사진, Dogs 문구가 있는 사진과 고양이 사진, Cat 문구가 있는 사진이다.
indexing.py
from absl import app
from google.cloud import aiplatform
import base64
from google.cloud import storage
from google.protobuf import struct_pb2
import typing
class EmbeddingResponse(typing.NamedTuple):
text_embedding: typing.Sequence[float]
image_embedding: typing.Sequence[float]
class EmbeddingPredictionClient:
"""Wrapper around Prediction Service Client."""
def __init__(self, project : str,
location : str = "<리전>",
api_regional_endpoint: str = "<리전>-aiplatform.googleapis.com"):
client_options = {"api_endpoint": api_regional_endpoint}
# Initialize client that will be used to create and send requests.
# This client only needs to be created once, and can be reused for multiple requests.
self.client = aiplatform.gapic.PredictionServiceClient(client_options=client_options)
self.location = location
self.project = project
def get_embedding(self, text : str = None, image_bytes : bytes = None):
if not text and not image_bytes:
raise ValueError('At least one of text or image_bytes must be specified.')
instance = struct_pb2.Struct()
if text:
instance.fields['text'].string_value = text
if image_bytes:
encoded_content = base64.b64encode(image_bytes).decode("utf-8")
image_struct = instance.fields['image'].struct_value
image_struct.fields['bytesBase64Encoded'].string_value = encoded_content
instances = [instance]
endpoint = (f"projects/{self.project}/locations/{self.location}"
"/publishers/google/models/multimodalembedding@001")
response = self.client.predict(endpoint=endpoint, instances=instances)
text_embedding = None
if text:
text_emb_value = response.predictions[0]['textEmbedding']
text_embedding = [v for v in text_emb_value]
image_embedding = None
if image_bytes:
image_emb_value = response.predictions[0]['imageEmbedding']
image_embedding = [v for v in image_emb_value]
return EmbeddingResponse(
text_embedding=text_embedding,
image_embedding=image_embedding)
def main(argv):
client = EmbeddingPredictionClient(project="<프로젝트명>")
#load all files in GCS bucket
gcs_image_path = "mhkim-data-bucket/multimodal-embeddings-image"
storage_client = storage.Client()
bucket = storage_client.get_bucket("mhkim-data-bucket")
delimter="/"
file_id="/multimodal-embeddings-image"
files = bucket.list_blobs(prefix="multimodal-embeddings-image")
#get vector embedding for each image and store within a json file
for file in files:
if "image" in file.content_type:
with file.open('rb') as image_file:
image_file_contents =image_file.read()
response = client.get_embedding(image_bytes=image_file_contents)
encoded_name = file.name.encode(encoding = 'UTF-8', errors = 'strict')
#write embedding to indexData.json file
with open("indexData.json", "a") as f:
f.write('{"id":"' + str(encoded_name) + '",')
f.write('"embedding":[' + ",".join(str(x) for x in response[1]) + "]}")
f.write("\n")
if __name__ == "__main__":
app.run(main)코드를 실행하면 indexData이라는 JSON 파일이 생성된다.
(indexing.py와 같은 경로에 key.json으로 서비스 계정 키 파일을 넣어두자.)
이 JSON 파일은 아래와 같은 내용으로 버킷에 있는 사진에 대해 임베딩한 벡터값들이 들어가 있는 것이다.


버킷에 data폴더를 생성한 후 그 안에 이 indexData.json을 넣어주자.
gsutil cp indexData.json gs://mhkim-data-bucket/multimodal-embeddings-image/data/indexData.json인덱스 생성 및 배포
index_metadata.json
메타데이터 파일을 갖고 생성해줄 것이다.
{
"contentsDeltaUri": "gs://mhkim-data-bucket/multimodal-embeddings-image/data",
"config": {
"dimensions": 1408,
"approximateNeighborsCount": 150,
"distanceMeasureType": "DOT_PRODUCT_DISTANCE",
"featureNormType": "UNIT_L2_NORM",
"shardSize": "SHARD_SIZE_MEDIUM",
"algorithm_config": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"leafNodesToSearchPercent": 10
}
}
}
}인덱스에 대한 메타데이터 설정값들은 Index Configure 문서에서 확인할 수 있다.
- contentDeltaUri : 임베딩 정보를 가져오는 GCS 경로.
- Dimensions : 우리가 사용하는 Multimodal Embeddings는 1408차원 벡터까지 생성할 수 있으므로 이를 1408로 설정할 것(기본값). 정확한 성능을 위해선 기본값인 1408이 좋지만 Multimodal Embeddings Dimensions를 보면 알 수 있듯이 128,256,512등의 저차원으로도 구성이 가능하다.
1408차원이면 생성되는 데에도 시간이 꽤 많이 걸린다. - distanceMeasureType : 최근접 이웃 검색에 사용되는 거리 측정 알고리즘. 일반적으로 COSINE_DISTANCE가 자주 사용됨.
인덱스 생성
인덱스를 생성함으로서 임베딩 데이터를 벡터 DB에 저장
gcloud ai indexes create \
--metadata-file=<메타데이터 파일 경로> \
--display-name=<인덱스 이름 지정> \
--project=<프로젝트 ID> \
--region=<리전>인덱스 엔드포인트 생성
gcloud ai index-endpoints create \
--display-name=<인덱스 엔드포인트 이름 지정> \
--public-endpoint-enabled \
--project=<프로젝트 ID> \
--region=<리전>확인
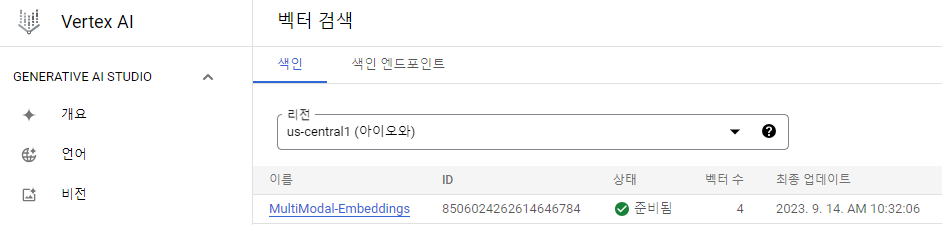
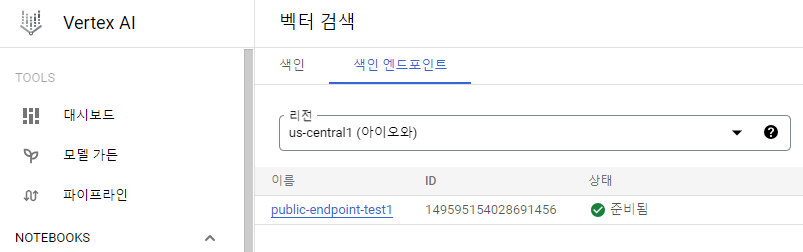
인덱스 배포
gcloud ai index-endpoints deploy-index <인덱스 엔드포인트 ID> \
--deployed-index-id=<배포되는 인덱스 ID 지정> \
--display-name=<인덱스 표시 이름> \
--index=<인덱스 ID> \
--project=<프로젝트 ID> \
--region=<리전>명령어 실행 예시

인덱스가 성공적으로 배포된 후에는 아래 명령을 실행하여 퍼블릭 엔드포인트 도메인을 가져와서 인덱스에 대한 후속 쿼리에 사용할 수 있어야 한다.
curl -H "Content-Type: application/json" -H "Authorization: Bearer `gcloud auth print-access-token`" <엔드포인트>/v1/projects/ <프로젝트 ID>/locations/<리전>/indexEndpoints /<인덱스 엔드포인트 ID>명령어 실행 예시

어플리케이션 실행
main.py
import streamlit as st
from predict_request_gapic import *
import json
from google.oauth2 import service_account
from google.cloud import storage
from google.cloud import aiplatform_v1beta1
st.set_page_config(
layout="wide",
page_title="민형이의 Lab",
page_icon="https://api.dicebear.com/5.x/bottts-neutral/svg?seed=gptLAb"
)
# Sidebar
st.sidebar.header("About")
st.sidebar.markdown(
"A place for me to experiment different LLM use cases, models, application frameworks and etc."
)
st.title("Vertex AI로 이미지에 대한 Semantic Search 테스트")
st.subheader("Vertex AI의 Multimodal Embedding, Vector Search 기반")
#client to access multimodal-embeddings model to convert text to embeddings
client = EmbeddingPredictionClient(project="gsn-haalsgud97-prj")
sa_file_path = "<서비스 계정 키 경로>"
scopes = ["https://www.googleapis.com/auth/cloud-platform"]
credentials = service_account.Credentials.from_service_account_file(sa_file_path, scopes=scopes)
client_options = { "api_endpoint": "<인덱스 퍼블릭 엔드포인트 도메인>"}
#client to access GCS bucket
storage_client = storage.Client(credentials=credentials)
bucket = storage_client.bucket("<버킷명>")
#vertex ai client to do similarity matching
vertex_ai_client = aiplatform_v1beta1.MatchServiceClient(
credentials=credentials,
client_options=client_options,
)
request = aiplatform_v1beta1.FindNeighborsRequest(
index_endpoint="projects/<프로젝트 ID>/locations/<리전>/indexEndpoints/<인덱스 엔드포인트 ID>",
deployed_index_id="<deployed_index_id>",
)
allResults=[]
search_term = 'a picture of ' + st.text_input('Search: ')
if search_term !="a picture of ":
converted_query_to_embedding = client.get_embedding(text=search_term)
dp1 = aiplatform_v1beta1.IndexDatapoint(
datapoint_id="0",
feature_vector=converted_query_to_embedding[0])
#pass the embedding to do matching
query = aiplatform_v1beta1.FindNeighborsRequest.Query(
datapoint=dp1,
)
request.queries.append(query)
response = vertex_ai_client.find_neighbors(request)
for r in response.nearest_neighbors:
for n in r.neighbors:
id = n.datapoint.datapoint_id
path=id.split("'")[1]
distance = n.distance
if distance<0.2:
allResults.append(bucket.blob(path).download_as_bytes())
#st.write(distance)
if len(allResults)>=1:
st.write("")
st.write("검색 쿼리와 가장 연관성이 높은 사진 :")
st.image(allResults, width=200)
elif search_term =="a picture of ":
st.write("위에 검색 쿼리를 입력하세요.")
else:
st.write("죄송합니다! 검색 쿼리와 일치하는 이미지가 없습니다. 다시 시도해 주세요.")실행
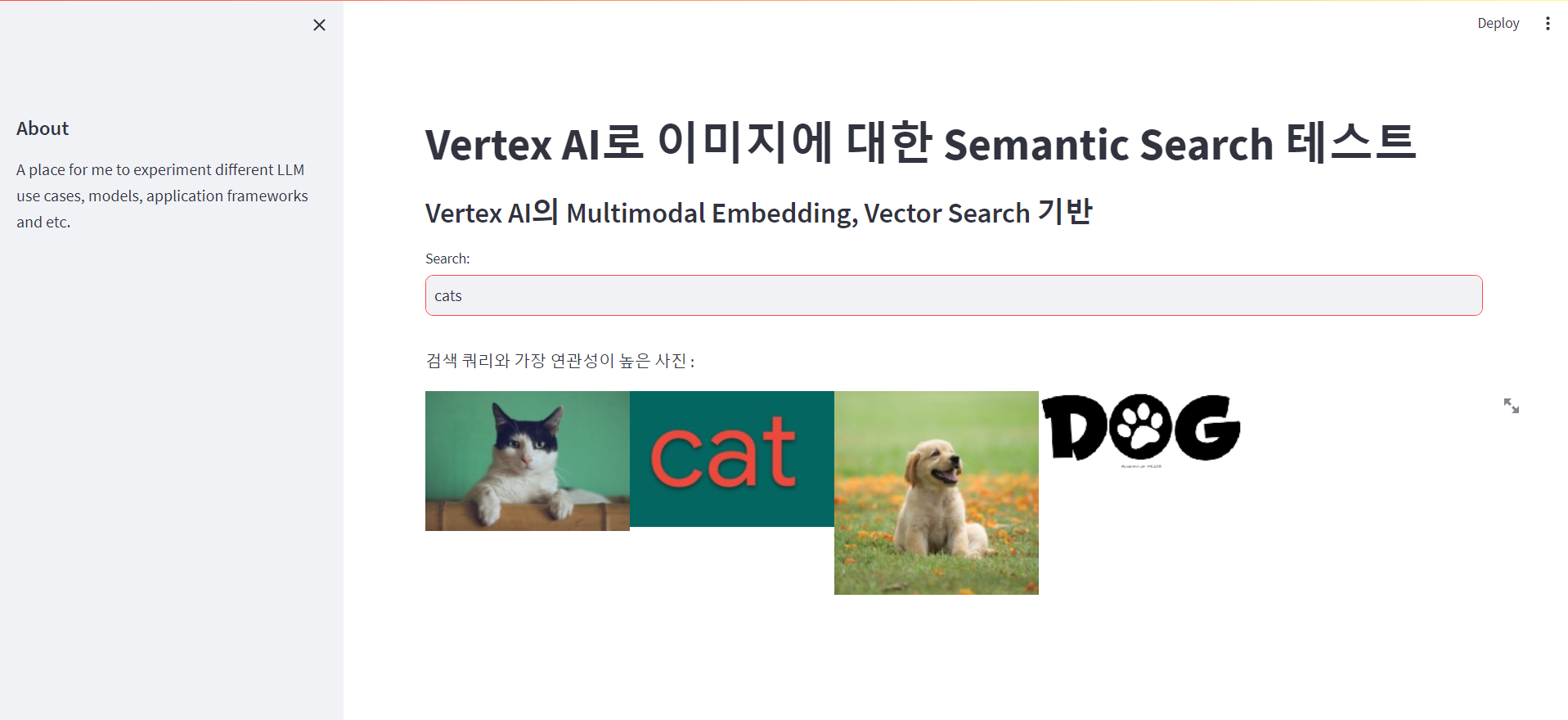
streamlit run main.py웹 화면은 간단하게 구성하였고 아래와 같은 화면이 나오게 된다.

검색을 했는데 K값 지정을 해주지 않았어서 그런지 모두 나온다..ㅎㅎ...
그래도 유사도를 기반으로 dogs을 검색했을 땐 강아지 관련 사진이 앞에, cats를 검색했을 땐 고양이 관련 사진이 앞에 나오는 것을 확인할 수 있다.

주의할 점
2024.01 기준
Vector Search를 사용할 일이 있어서 몇 번 사용하다가 느낀 점이다. Vector Search는 glcoud CLI 및 REST API를 사용하는 방법 외에도 Python Library를 사용해서도 쉽게 생성할 수 있다.
하지만 현시점 기준 테스트용으로 Python을 활용해서 생성하고자 할 때 주의해야할 점이 있다..!
gcloud CLI 및 REST API 사용
Manage indexes
링크를 통해 들어가보면 샤드 사이즈 선택 옵션이 있을 것이다.
이 포스팅에서도 난 이 방법을 사용했다. 위의 index_metadata.json을 보면 샤드 사이즈를 설정해줬었다.
아래 사진을 보면 알겠지만 샤드 사이즈에 따라 인덱스를 배포할 때 지원하는 머신 타입이 다르다.

Python 사용
MatchingEngineIndex Python Client Library
링크를 통해 들어가보면 인덱스를 생성할 때 샤드 사이즈 설정 옵션이 없다. 그렇다면 저 코드를 사용하여 생성하면 샤드 사이즈가 어떻게 설정될까?
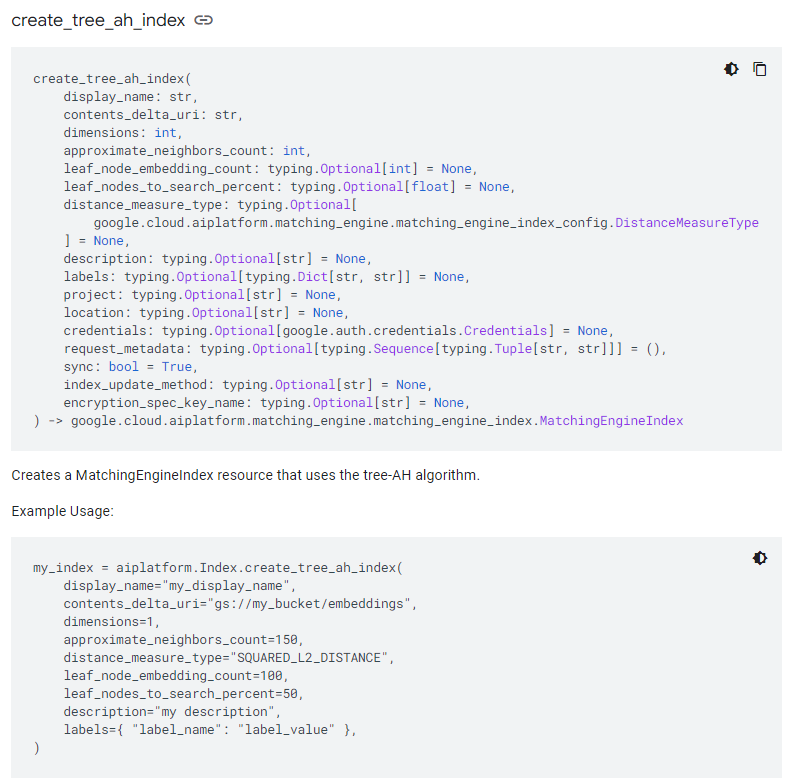
default는 미디움이었다. 미디움의 최소 스펙은 e2(혹은 n1)-standard-16이고 vCPU 16개, 메모리 60GiB였다. 이는 테스트용으로 구성해보기엔 비용적인 측면에서 부담스러울 수도 있다.
배포시 스펙 확인
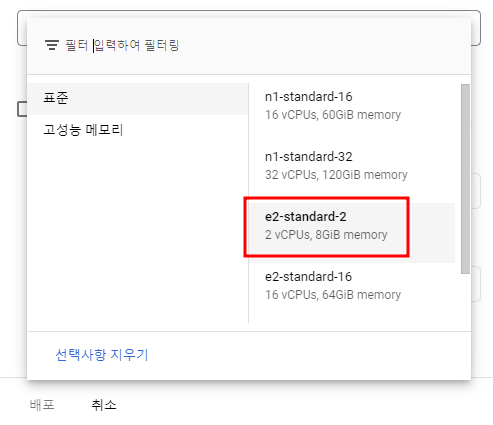
콘솔에서 인덱스를 엔드포인트에 배포하려고 할 때 샤드 사이즈에 따라 보여지는 것이 다르다.
index_metadata.json 파일을 통해 샤드 사이즈를 스몰로 설정하고 인덱스를 만들었을 때
Python Library를 사용하여 인덱스를 만들었을 때
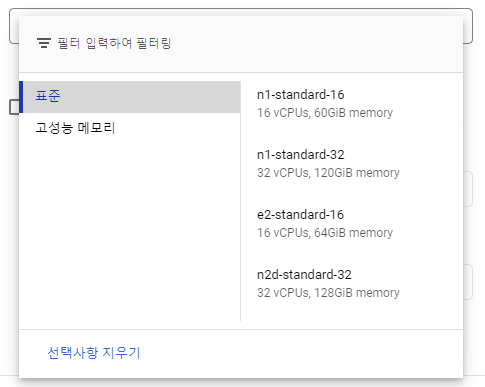
당연히 Python Library에서도 지원이 되겠지만 공식 Docs에선 아직 확인할 수 없었고 샘플 데이터에 대해 간단한 PoC를 진행하는 경우 지금은 gcloud CLI나 REST API를 사용할 것을 권장한다.
[Vertex AI Multimodal Embeddings와 Vector Search를 사용한 이미지 검색 어플리케이션 구현 참고]
