CTR 예측에 딥러닝이 필요한 이유
현실의 CTR 데이터(주로 광고 데이터)는 기존의 선형 모델로 예측하는 데에는 한계가 있다.
그 이유는 CTR 데이터는 Highly Sparse 하고 super high-dimensional features 로 이루어져있져 있고, 각 feature간의 관계가 highly non-linear 하기 때문이다.
이러한 특성을 가진 데이터는 선형 결합모델로는 풀기 어렵기 때문에 딥러닝 기법들이 CTR 예측문제에 적용되기 시작했다.
Wide & Deep
Wide & Deep Learning for Recommender Systems
Wide & Deep은 선형적인 모델(Wide)와 비선형적인 모델(Deep)을 결합하여 두 모델의 장점을 모두 취하고자 한 논문으로 구글 Playstore에서 검색한 쿼리를 통해 추천해주는 방법이다.
등장배경
논문에서는 추천시스템에서는 해결해야할 과제가 2가지 있다고 말한다.
- Memorization
- Generalization
Memorization은 말 그대로 암기하는 특성이다. 빈번히 등장하는 아이템이나 특성 관계를 과거 데이터로부터 학습하여 모델이 그대로 암기하여 예측에 활용한다는 것이다. 예를들어 X(남자,컴퓨터) -> Y(1) (남자가 컴퓨터를 클릭) 한 경우가 많이 존재한다고 한다면 모델은 이 패턴을 그대로 암기하게 된다.
이런 경우 단순하고 확장 및 해석이 용이하여 대규모 추천 시스템이나 검색엔진에서 많이 사용하지만, 학습데이터에 없는 feature 조합에는 취약하다는 단점이 있다.
이를 극복하기 위해 Generalization을 한다. X(남자, 화장품)->Y(1)(남자가 화장품을 검색) 한 데이터가 적어서 단순회귀모델(로지스틱 회귀)은 일반화하는 능력이 떨어져 남자가 화장품을 클릭할 확룰을 제대로 구할 수 없다.
Generalization은 이처럼 드물게 발생하거나 전혀 발생한 적 없는 아이템/특성 조합을 기존 관계로부터 발견하여 일반화 시키는 것을 뜻한다. 이에 대한 예시로는 FM이나 DNN 같은 임베딩 기반 모델을 활용하여 각 feature를 적절히 활용하고 두 feture간 상호작용은 임베딩이 곱해지면서 표현되게 된다. 이러한 모델들의 단점은 일반화가 가능하지만, high-spasity & high-dimensinal 한 데이터로부터 저차원의 임베딩을 만들기 어렵다는 단점이 있다.
Memorization과 Generalization이 가지고 있는 특징을 결합한 모델이 Wide&Deep이고, 이 둘을 결합하여 두가지 문제를 모두 커버한다면 검색 쿼리에 맞는 앱을 추천하는 추천 성능이 더 향상되게 된다.
구조
Wide Component
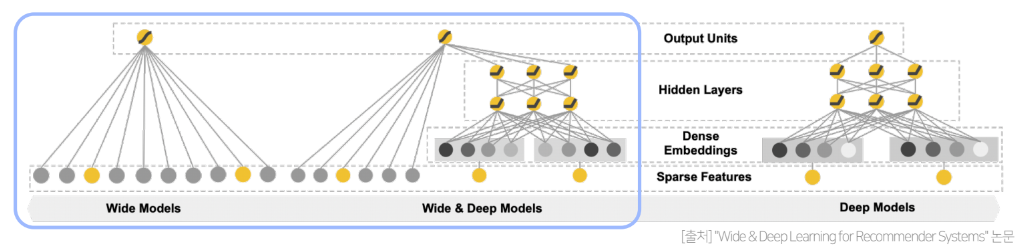
우선 Wide Component부터 보면 로지스틱 회귀모델과 비슷하다.
Genealized Linear Model
n개의 입력변수()가 존재하고 이에 대응되는 n개의 학습파라미터()로 이루어져 있고, 각각의 변수는 모두 선형결합으로 이루어져 있다.
하지만 이렇게 모델링을 할 경우 서로다른 두개의 변수 ()의 상호작용에 대해서 전혀 학습을 할 수 없게 된다.
그렇기 때문에 Wide Component에서는 Cross Product Transformation을 사용한다.
Cross Product Transformation
성별이 여자라는 입력변수와 영어를 사용한다는 입력변수가 동시에 1일 경우, 두 변수의 Cross Product term(성별이 여자면서 영어를 사용하는 변수)을 추가한다는 의미이다. 이러한 Cross Product Term을 일반화 시켜 라고 하는데 여기에 해당되는 weight 들도 모델에 추가되어 학습한다.
단 가능한 모든 변수들 사이의 Cross product term을 모두 구하게 되면 학습할 파라미터가 기하급수적으로 증가하게 된다. 논문에서는 주요 feature 두개에 대한 second order cross product만을 사용한다고 한다.
사실 이부분은 로지스틱 회귀에 2차 Polynomial 항을 추가한 것과 거의 동일하다. 두개의 서로다른 변수 에 해당하는 학습 파라미터 를 정의하여 두 feature의 상호작용을 표현하였는데, 이는 만큼 늘어나게 되어 표현할 수 있는 interaction의 한계가 명확하다고 볼 수 있다.
Deep Component
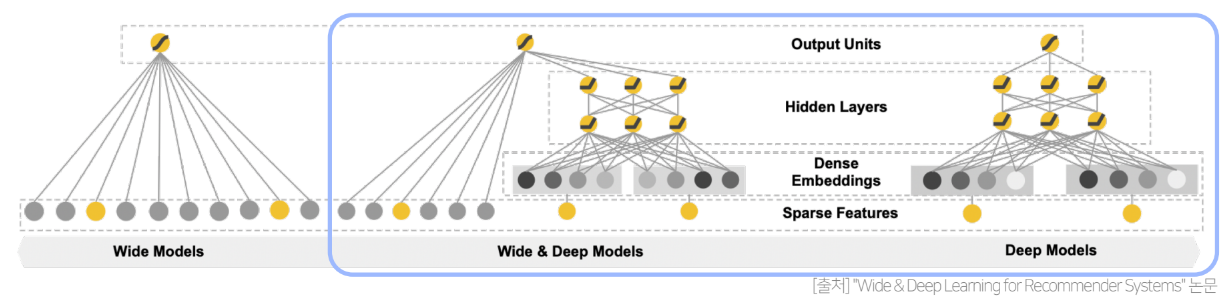
Deep Component 부분은 Feed-Forward Neaural Network를 사용한 것 외에는 큰 특징은 없다.
3-Layer로 구성되어있고, 각각의 Layer에 대해서는 ReLU함수를 사용하였다. 또한 연속형 변수는 그대로 사용하고 카테고리형 변수는 피쳐 임베딩 후 전체를 Concat 하여서 최종 클릭율을 예측하고 있다.
이렇게 Wide 와 Deep을 합쳐서 (그림의 가운데) Wide&Deep모델이 완성된다.
전체 구조
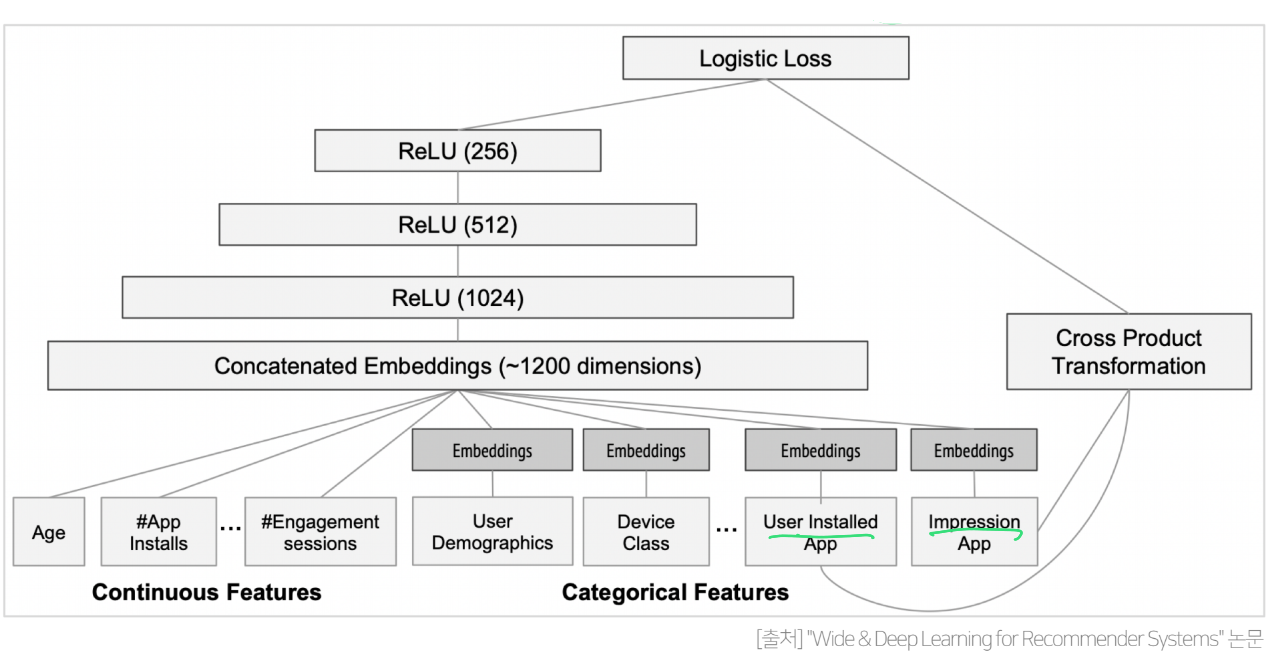
Wide&Deep 모델의 수식은 다음과 같다
이 수식에서 왼쪽 부분이 Wide Component를 나타내고, 오른쪽 부분이 Deep Component를 나타낸다.
Wide Component 부분에서 는 주어진 n개의 변수를 의미하고, 는 n개의 변수 사이의 Cross Product Transformation을 의미한다. 이때 논문에서는 모든 Cross product Transformation가 아니라 유저가 설치한 앱(User Installed App)과 현재 CTR 예측할 앱(Impression App)의 Cross Product만을 사용한다.
Deep Component 부분은 단순히 MLP를 일반화하여 표현한 것이다.
식을 전체적으로 본다면 Wide Component와 Deep Component를 더한뒤 bias를 더하고 sigmoid를 취해 최종 예측값을 도출하는 형태이다.
결론
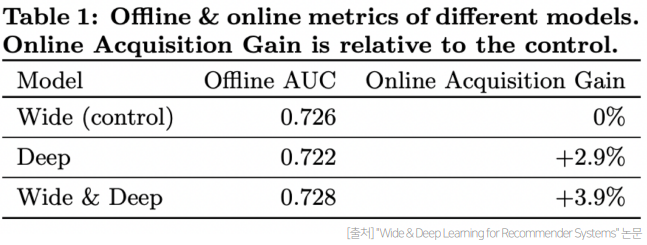
Wide 모델은 Offline Test에서, Deep 모델은 각각 Online Test에서 더 좋게 나와 서로 다른 양상을 보이지만, 두 개 모델을 결합하여 만든 Wide & Deep 모델은 Online/Offline모두 좋은 성능을 보인다. 이를 통해 두 모델이 성공적으로 결합된 것을 알 수 있다.
