머신러닝 알고리즘을 최적화하기 위해서, 다양한 파트에서의 머신러닝 알고리즘 퍼포먼스를 이해하는 방법에 대해 살펴보고, skewed data를 다루는 방법을 알아보도록 하겠다.
Building a Spam Classifier
이번에는 머신러닝 시스템 디자인에 대해 이야기를 나눠보려고 한다. 복잡한 버신 러닝 시스템을 디자인할 때 직면할 수 있는 메인 이슈들에 대해 살펴본 후, 어떻게 머신러닝 시스템을 전략적으로 만들어낼 수 있는지 알아볼 것이다.
Prioritizing what to work on: Spam classification example
Spam Classifier을 빌드하려고 한다.

위 그림의 왼쪽에 있는 이메일은 누가봐도 스팸이고, 오른쪽에 있는 이메일은 스팸이 아니다. 스팸이 있는 것을 1, 없는 것을 0이라고 할 때, supervised learning을 이용하여 어떻게 spam과 non-spam을 구분할 수 있을까?

Supervised learning을 적용하기 위해선, 가장 처음으로 어떻게 를 나타낼 것인가를 선택해야 한다. 여기선 x가 features of email이다. 주어진 features 에 대하여, labels 가 있다. features 는 spam/not spam을 구분할 수 있는 100개의 단어라고 하자.

위 그림의 오른쪽과 같은 이메일을 받았을 때, 이메일을 코드화해서 feature vector로 바꿀 수 있다. features list가 andrew, buy, deal, discount, ..., now라고 할 때, 이 단어들이 이메일에 있는지를 확인하고, feature vector 를 define한다. 여기서의 feature vector 는 왼쪽에 있는 행렬과 같다.
실제로는 수동으로 100개 단어를 뽑기 보단 training set에서 가장 자주 나타나는 단어 n개 (10,000~50,000)를 선택한다.
많은 시간을 쓰지 않고도 어떻게 Spam Classifier의 에러가 적도록 잘 빌딩할 수 있을까?
- 데이터를 많이 모은다 (예: "Honeypot" project)
- Email routing information (from email header) 에 기반한 정교한 feature을 개발한다.
- Email 본문에 기반한 정교한 features를 개발한다. (예: discount와 discounts는 같은 단어로 볼 수 있을까? deal과 Dealer는? 발음에 대한 features는?)
- 의도적으로 철자를 틀리게 쓴 단어를 검출하는 알고리즘을 개선한다. (예: m0rgage, med1cine, w4tches 등)
Error Analysis
에러 분석에 대한 개념을 설명하고, 조직적으로 더 좋은 결정을 할 수 있는 방법을 소개하고자 한다.
머신러닝을 프로젝트를 시작할 때, 추천하는 접근 방법이 있다. 아주 많은 복잡한 features와 복잡한 시스템을 빌딩할 필요가 없다.

방법은 위 그림과 같다. 해석해보자면,
- 빠르게 구현할 수 있는 간단한 알고리즘으로 시작하자. cross-validation data 구현한 후 같은 데이터로 테스트 한다.
- Learning curve를 그려서 데이터를 늘리거나, feature를 늘리거나, 혹은 다른 어떤 방법이 도움이 될지 결정한다.
- Error analysis: 에러를 일으키는 데이터(in cross-validation set)를 수동으로 분석한다. 어떤 종류의 데이터가 일정한 경향의 에러를 발생시키는지 관찰한다.
위 방법을 적용하는 예시를 살펴보자. 예를 들어, 500개 cross-validation data 중 100개 email이 잘못 분류되었다고 하자. 이 100가지 에러를 확인하여 다음과 같은 기준에 의해 분류한다.
- What type of email it is
- What cues (features) you think would helped the algorithm classify them correctly
1.의 경우,
약: 12개
레플리카: 4개
패스워드 해킹: 53개
기타: 31개
로 결과가 나왔다면, '패스워드 해킹'으로 분류된 메일에 대한 classifier 성능을 높이는 방법을 찾도록 하는 것이 가장 효과적이다.
2.의 경우,
의도적인 철자법 오류: 5건
unusual email routing: 16건
unusual punctuation: 32건
이런 경우, unusual punctuation를 찾는 것이 효과적이다.
stemming software을 쓰면, 같은 뜻의 다른 형태의 단어들(discounts/discounted/discounting)을 하나의 단어(discount)로 취급할 수 있다. 이를 통해 error rate가 5%에서 3%로 줄어들 수 있고, 확실하게 우리 모델에 추가할 수 있다. 하지만, universe와 university를 같은 단어로 취급하고, 대문자와 소문자를 구분하려고 한다면, 3%가 아닌 3.2%의 error rate를 얻는 등 꼭 stemming software가 완벽한 건 아니다. 따라서 Error analysis만으로는 stemming을 하는 것이 성능향상에 도움이 될지 알기 어렵기 때문에, 일단 시도해보고 잘 작동하는지 판단하는 것이다.
즉, 우리는 새로운 것을 시도할 수 있고, 우리의 error rate에 대한 numerical value를 얻을 수 있고, 그 value에 따라서 새로운 feature을 적용할지 하지 않을지를 결정할 수 있다. 다시 말해, numerical evaluation (예: cross-validation error)이 필요하다. 즉, stemming을 이용할 때와 이용하지 않을 때의 에러율을 비교하여 결정을 내리면 된다.
Handling Skewed Data
Logistic Regression 강의에서 언급했던 cancer classification의 예를 생각해보자. Logistic regression model
를 이용하여 암이면 , 암이 아니면 으로 결정을 내리도록 시스템을 만들었다. 성능을 테스트 해봤더니 test set에서의 error가 1% 였다. 정확도가 99% 이니, 굉장히 잘 작동하는 알고리즘인 것 같다.
하지만 사실 환자의 0.5%만이 실제로 암이라면? 항상 으로 결정하는 알고리즘만으로도 0.5% 에러율을 달성할 수가 있다. 결국 1% 에러율이 딱히 좋은 성능이 아닐 수도 있다는 말이다.
이 경우, class의 데이터 수가 데이터 수보다 훨씬 적다. 이렇게 class 별 데이터 수 차이가 많이 나는 데이터를 skewed data라고 한다. 이러한 skewed data의 경우, 에러율만으로는 성능을 정확하게 평가하기 어렵다. 이제 이런 skewed data의 경우엔 어떻게 성능을 평가하는지 알아보려고 한다.
Error Matrics for Skewed Classes
에러율 대신 시스템 성능을 평가할 수 있는 metric에는 precision과 recall이 있다.
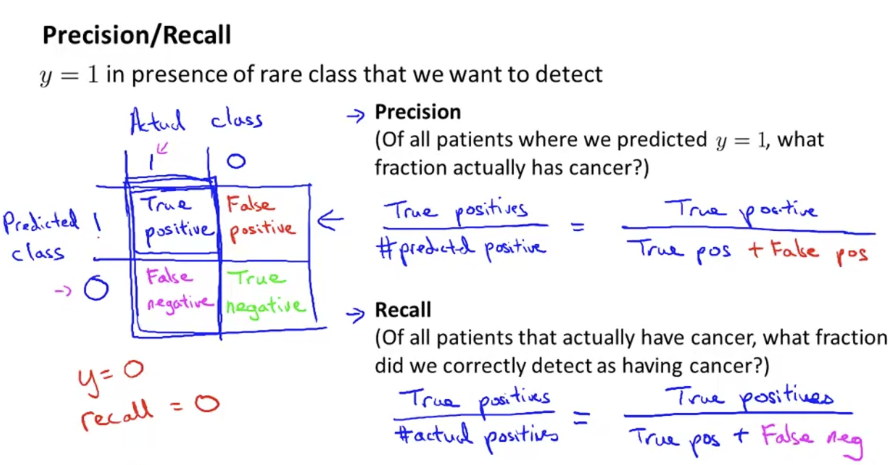
우리가 detect하기 원하는 드문 class를 로 둔다.
-
Precision
로 결정된 환자들 중(predicted y=1), 진짜 암을 가지고 있는 부분은 얼마인가(predicted y=1 && actual y=1)?
-
recall
실제로 암인 환자들 중(actual y=1), 진짜 암을 가지고 있는 부분은 얼마인가(predicted y=1 && actual y=1)?
precision과 recall을 이용하면, classifier가 얼마나 잘 작동하는지 더 잘 알 수 있다. 만약, 계속 아무도 암에 걸리지 않았다고 예측하는, 즉, 을 예측하는 learning algorithm이 있다면, classifier는 recall이 0일 것이다.
만약, 항상 또는 이라고 예측하는 very high precision과 very high recall인 classifier가 있다면, 이건 아주 좋은 classifier임을 알 수 있다.
Trading Off Precision and Recall
많은 상황에서, precision과 recall 사이에 trade-off를 컨트롤하고 싶을 수 있다. 어떻게 그걸 행할 수 있는지와 precision과 recall을 learning algorithm에서 evaluation metric으로 사용하기 위핸 더 실용적인 방법을 소개하려고 한다.
우리가 앞서 배운 precision과 recall의 공식은 다음과 같았다.
Logistic Regression에서 다음과 같았다.

오직 암이라고 확신이 있을 때만 이라고 예측하길 원한다고 가정하자.

가장 먼저 생각할 수 있는 것은, 위 그림처럼 threshold를 0.5에서 0.7정도로 수정하는 것이다. 또, 암이라고 예측한 결과가 진짜 실제로 암이어야 하기 때문에, Higher precision을 가지고, low recall을 가진다.
이번에는 암인 경우를 간과해버리는 것을 피하길 원한다고 가정하자.(avoid false negatives.)

이런 경우, 위 그림처럼 threshold를 0.5에서 0.3정도로 낮게 수정할 수 있다. 또, 정확하게 암을 가지고 있는 모든 환자들을 항상 higher fraction으로 flagging할 것이기 때문에, Higher recall을 가지고, low precision을 가진다.
이면 1로 예측한다.
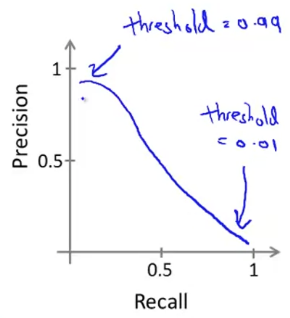
위 그래프는 다양한 그래프로 또 그려질 수 있다. 아래와 같이 말이다.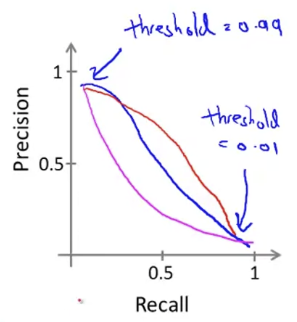
그렇다면 혹시 threshold를 자동적으로 선택할 수 있는 방법이 있을까?
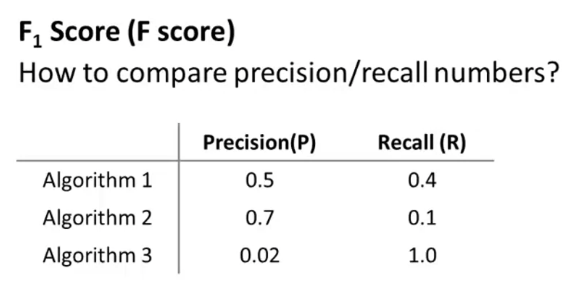
위와 같은 세 가지의 알고리즘이 있고, 각 알고리즘의 precision과 recall threshold는 각각 다르다. 어떻게 최적의 알고리즘을 선택할 수 있을까?
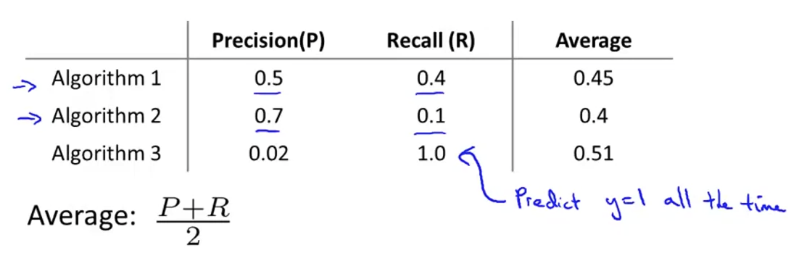
먼저 평균을 내서 결정하는 방법이 있다. 하지만 이 경우, 항상 로 결정하는 알고리즘의 평균이 가장 높은 것을 확인할 수 있다. 따라서 이 방법은 좋은 방법이 아니다.

하지만 F-score를 쓰면 좀 더 합리적인 판단이 가능하다. 만약 P=0 || F=0 이면 F-score는 0이 되고, 완벽한 시스템의 경우 P=1 && F=1 이 되어 F-score가 1이 된다.
Using Large Data Sets
많은 데이터를 가지고 학습을 시키면 learning algorithm은 아주 좋은 퍼포먼스를 보여주었다.
Data For Machine Learning
우리는 다른 learning algorithm을 사용하는 것과 다른 training set을 사용하는 것 중 어떤 것이 더 효과적인지 알아보고 싶다. 사실 2001년에 행해진 Banko and Brill 실험에서 이를 알아보았다. blank에 혼동이 되는 글자들 중 어떤 글자가 들어가야 하는지를 찾는 것이었다.

거의 모든 알고리즘이 training data가 늘어날수록 성능이 향상되어 "약한 알고리즘"도 데이터만 많으면 "강한 알고리즘"만큼의 성능을 내는 것이 가능했다.
