Cost Function and Backpropagation
주어진 Training set에서, neural network의 파라미터들을 피팅하는 learning algorihtm을 배워보도록 하겠다. 우리가 다뤘던 learning algorithm들 처럼, 먼저 network의 파라미터를 fitting하기 위한 cost fucntion에 대해서 살펴보겠다.
우리의 network가 아래와 같다고 가정하자.
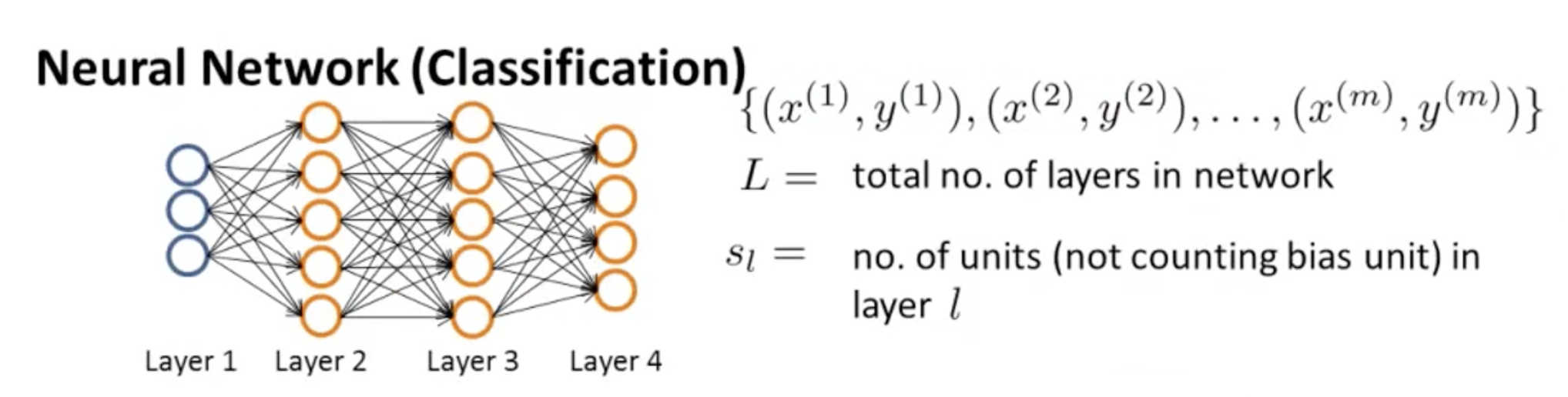
위 그림 오른쪽에 나와있는 기호들을 살펴보자.
우리의 Training set은 x, y의 짝으로 M개의 training examples가 있다.
L은 네트워크의 total number of layers니까 4라고 할 수 있고,
은 bias unit을 제외한 unit의 갯수이다. 여기서 이다.
두 개 타입의 classification에서 어떻게 달라지는지 살펴보자.
먼저 binary classification이다. 이고 이 경우 output unit은 오직 1개이다. 따라서 이고, 이다(L은 Layer의 갯수이고, 이것은 Output layer와 같기 때문이다.).
Multi-class classification에서는 이다. 앞선 예시에서,
을 보았다. 이렇게 multi classification에서는 y가 여러 값이 나올 수 있고, K개의 output units이 있다고 할 수 있다. 따라서 도 이고, 이다. 그리고 이 경우, 항상 우리는 3보다 같거나 큰 K를 갖는다. 이유 생각해보기!
Cost Function
우리가 NN에서 쓰는 Cost function은 logistic regression의 generalization 버전이다. Logistic Regression에서, 우리는 cost function 를 최소화 했어야 했는데, Cost Function 공식은 다음과 같다.
Cost Function of Logistic Regression
Neural network에서 우리의 cost function은, 이것을 K개의 Output에 대해 generalization한 것이 될 것이다. Logistic Regression에서의 는 binary classification을 위한 것이기 때문이다. 따라서 NN에서의 cost function은 다음과 같다.
Cost Function of Neural Network
Backpropagation Algorithm
Cost Function을 minimize할 수 있는 알고리즘인 backpropagation algorithm을 살펴보자.
우리는 Cost Function 를 minimize할 수 있는 를 찾고 있다. Gradient Descent나 advanced optimization algorithm을 사용하기 위해선, cost function 와 편미분 를 계산해야 한다. 여기서 인 걸 기억해야 한다. 과연 는 어떻게 계산할 수 있을까?
먼저 우리는 오직 하나의 training example 가 있다고 가정하자. hypothesis를 계산하기 위해 forward propagation을 적용하자. 이를 나타내면 아래와 같다.
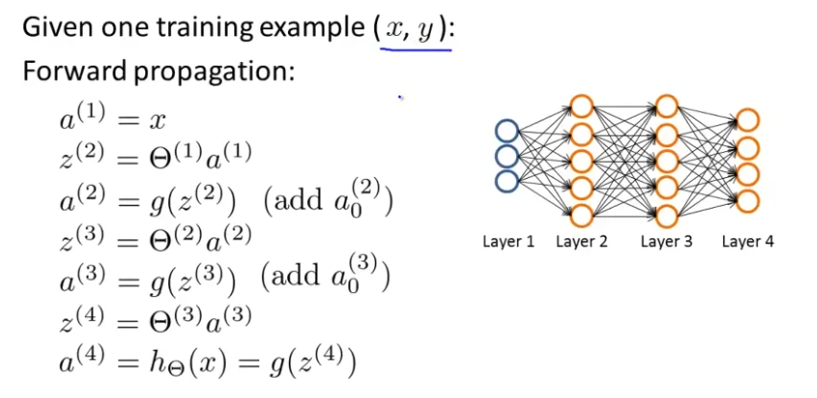
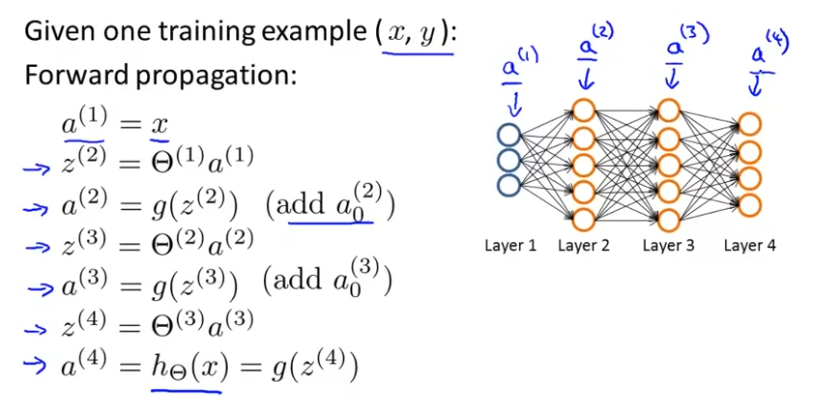
forward propagtion은 Input Layer에서 출발해서 hypothesis를 구할 수 있다.
Backpropagation은 output layer에서 시작한다. Backpropagation algorithm의 intuition은 layer 에 있는 node 의 에러를 나타내는 를 계산하는 것이다. 은 layer 에 있는 번째 activation node인 것을 다시 상기시켜보면, 은 activation 에 있는 에러를 나타낸 다는 것을 알 수 있다. 이 예시에서 를 계산해보면 아래와 같다.

For each output unit (layer L=4)
(단, )
(No because Layer1 is input layer)
로 나타낼 수 있다. 증명 과정은 여기서 다루지 않는다.
이제 한 훈련세트가 아닌 거대한 훈련세트를 가지고 있을 때, 어떻게 backpropagation을 구할 수 있는지를 알아보겠다. Backpropagation algorithm은 다음과 같다.

- Training Set이 로 m개가 있다고 가정하자.
- 모든 에 대하여, 을 만족하게 할 것이다. 결국 이 는 편미분항 을 계산하게 되고, 편미분항을 계산하기 위해서 값들을 저장하는 accumulator가 된다.
- 훈련세트 전체에 대한 for loop를 돈다.
- input layer의 activation인 에 우리의 training example 를 대입한다.
- 인 layer 에 대해서 을 구하기 위해 forward propagation을 수행한다. 은 hypothesis의 출력이 된다.
- 를 이용해서, 를 구한다.
- back propagation algorithm을 사용해서, 를 계산한다. 입력 레이어는 에러와 관련이 없기 때문에 은 고려하지 않는다.
- 편미분항을 축적하기 위해서, 를 수행한다. 를 벡터라고 생각하고, 로 요소를 표현하여 이를 벡터화 시키면 다음과 같다.
- 일 때, 이고, 일 때, 이다. 일 때 bias항에 대응되기 때문에 추가적인 정규화항이 있다.
- 를 계산해보면, 이것는 각 매개변수에 대한 cost function의 편미분과 같다.() 이걸 Graident Descent나 다른 고급 알고리즘에서 사용할 수 있다.
Backpropagation in Practice
지금까지 미분을 계산하기 위해서 Neural Network에서 forward propagation과 backpropagation을 어떻게 해야하는지 살펴보았다. 하지만 back propagation은 알고리즘으로서 많은 디테일과 구현하기 어려운 것들을 가지고 있다. 그리고 back propagation의 하나의 단점은 미묘한 버그를 가지는 많은 방법이 있다는 것이다. 따라서 gradient descent나 다른 알고리즘을 작동시킨다면, 이게 잘 작동하는 것처럼 보일 수 있다. cost function 가 gardient descent의 모든 interation에서 줄어들기 때문이다. 하지만 결과적으로 높은 레벨의 error을 가지는 neural network를 마무리 짓게 될 것이다. 그럼 어떻게해야할까? gradient checking을 이용해볼 수 있다. gradient checking을 이용하면, back prop에서 buggy implementation 문제들을 아주 많이 줄일 수 있다.
Gradient Checking
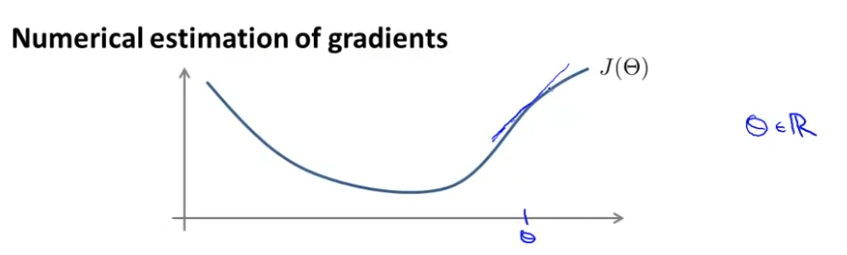
다음과 같은 cost function 가 있다고 가정하자. 그리고 다음과 같은 지점에서 를 가진다고 가정하자. 이 함수의 지점에서 도함수를 알기 위해선, slope의 tangent값과 같다.
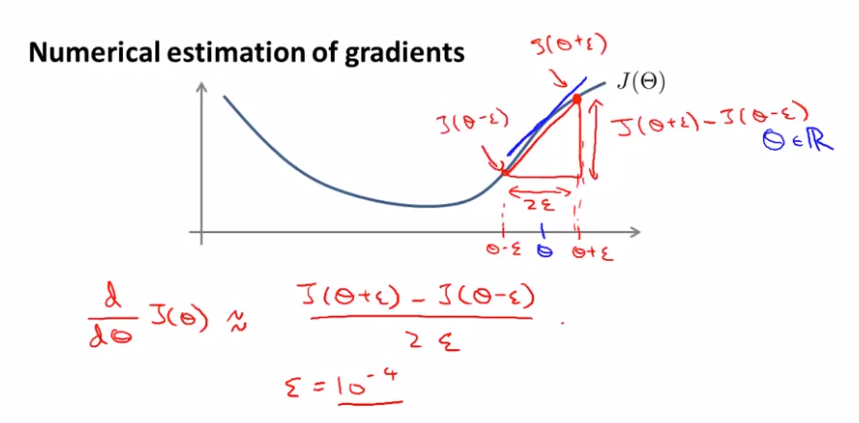
수학적으로 도함수의 근사치를 알아내보자. 에서 아주 작은 숫자 만큼 좌우로 떨어져있는 지점이 있다고 하자. 이 두 지점을 연결한 것이 빨간색 선이다. 도함수와 도함수의 근사치를 꽤 잘 맞는 것을 확인할 수 있다.
이제 parameter vector 에 대해서 살펴보자.

각 편도함수 는 위처럼 근사치를 얻을 수 있다.
Random Initialization
gradient descent나 advanced optimization algorithms를 사용할 때, 우리는 initial value 를 선택해야한다.!
먼저, 모든 에 대하여, 만약 을 모두 0으로 초기화, 즉, 모든 weight들을 0으로 초기화 하게 되면 어떨까?
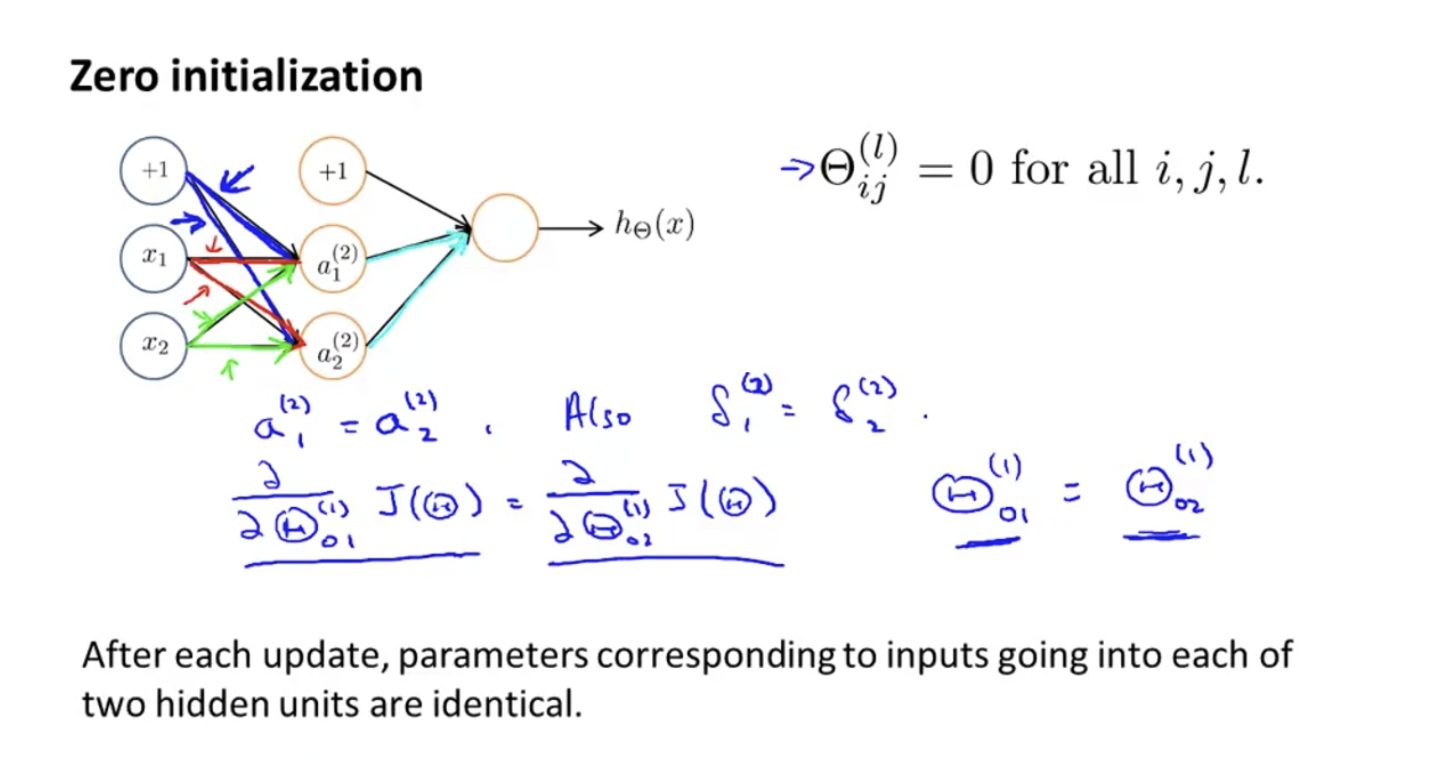
같은 색으로 표시된 간선들은 같은 값을 가지므로 가 되고, 가 된다. 따라서, 각 업데이트 마다, 같은 input 에서 나온 weight들은 같다. 이것은 올바른 값이 아니다. 따라서 neural network에서 weight들은 0으로 초기화하면 제대로 작동하지 않는다. 따라서 random initialization을 사용한다.
앞선 문제를 the problem of symmetric ways라고 부르는데, 이제 사용할 Random initialization은 symmetric breaking을 어떻게 수행하는지를 보여준다.

각 parameter들은 랜덤으로 부터 사이의 값 중 하나로 초기화된다.
이 방법을 이용하면 gradient descent나 advanced optimization algorithms를 사용할 때, initial value 를 잘 선택할 수 있다.
Putting It Together
이제 앞서 배웠던 모든 것들을 이용해서 어떻게 neural network learning algorithm를 구현하는지 알아보자.
0. 먼저, network architecture을 선택한다.
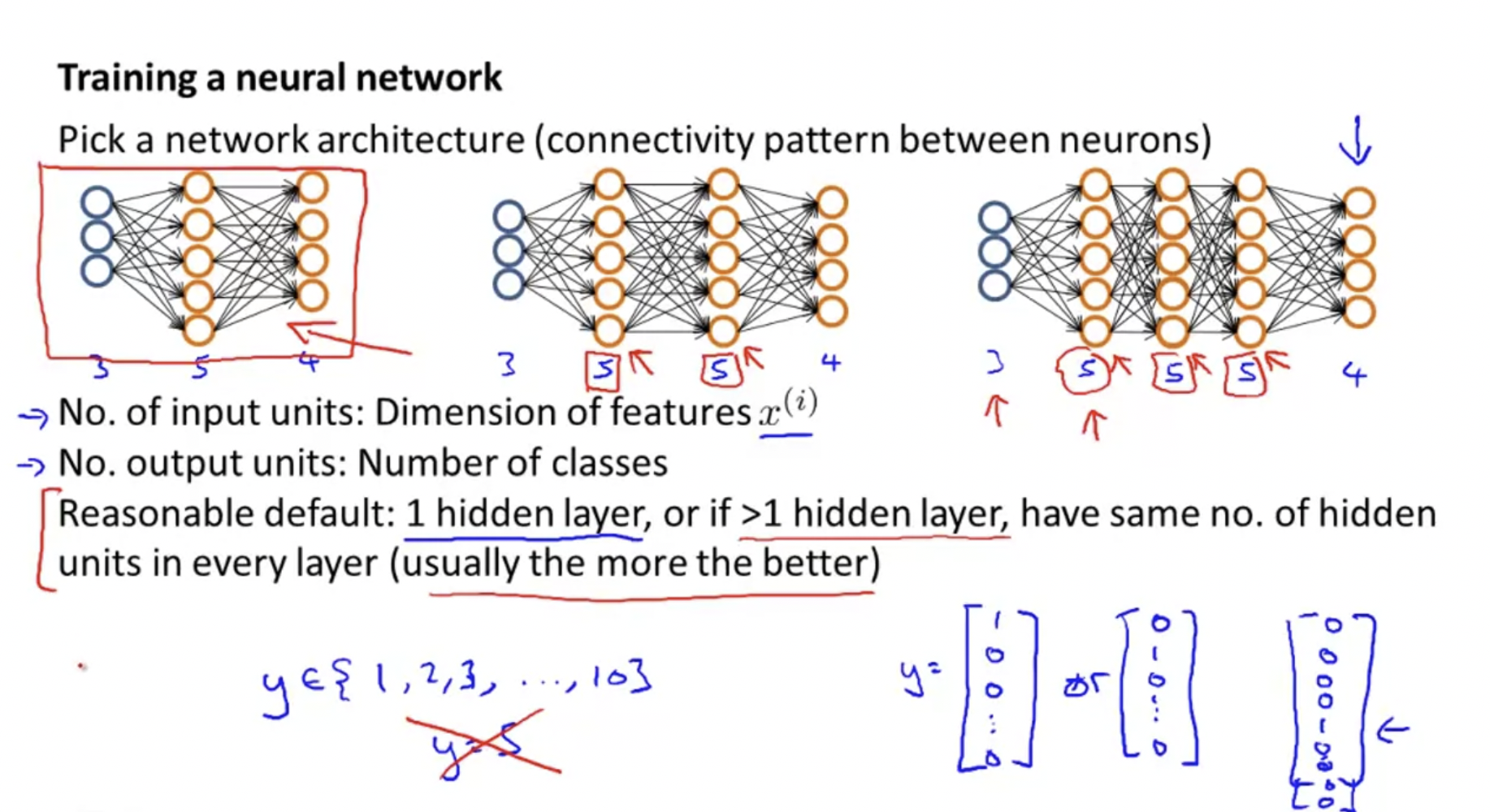
각 layer에 얼마나 많은 hidden units이 있는지 그리고 얼마나 많은 layer를 가질 것인지를 따져서 선택한다.
-
Number of input units = dimension of features
-
Number of output units = number of classes
-
Number of hidden units per layer = usually more the better (must balance with cost of computation as it increases with more hidden units)
-
Defaults: 1 hidden layer. If you have more than 1 hidden layer, then it is recommended that you have the same number of units in every hidden layer.
기억해야할 점은, 만약 일 때, 이것은 벡터로 이렇게 나타낼 수 있다.
1. Random Initialization을 통해 weight를 초기화한다.
2. forward propagation로 를 구한다.
3. cost function 를 구하는 코드를 구현한다.
4. backpropagation으로 partial derivatives 을 구한다.
5. gradient checking을 통해 backpropagation이 잘 작동하는지 확인한다. 그 뒤에 꼭 gradient checking code를 disable한다. 왜냐하면, gradient checking code는 연산속도가 느리기 때문이다.
6. gradient descent나 built-in optimization function을 사용해서 cost function을 minimize한다.
Application of Neural Networks
NN의 응용사례를 하나 살펴보자.
Autonomous Driving
자동차가 스스로 운전하는 자율주행은 NN을 사용한다.
