이번엔 적절한 feature의 선택 방법과, 이를 이용한 강력한 학습 알고리즘을 만들어 보고, polynomial regression을 다루면서 linear regression을 이용해서 복잡한 비선형 함수에도 적용해보려고 한다.
Feature 새롭게 정의하기.
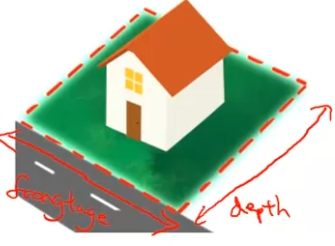
집값 예측 hypothesis는 다음과 같다.
hθ(x)=θ0+θ1×frontage+θ2×depth
frontage는 X1이라고 하고, depth는 X2라고 하자.
그리고 새로 AreaX를 정의하자. X=frontage×depth가 된다. 이는 집의 넓이이기 때문에 feature 하나만 가지고 이렇게 가설 함수를 새로 정의할 수 있다.
hθ(x)=θ0+θ1×X
이렇게 새롭게 정의해도 좋다.
Polynomial Regression
feature을 선택하는 것과 밀접하게 관련된 것으로 Polynomial Regression이 있다.
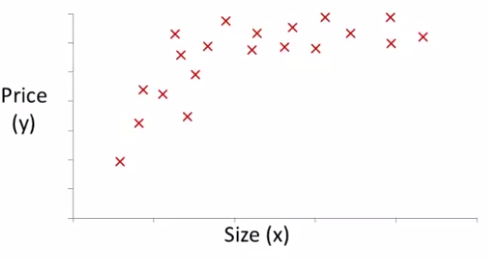
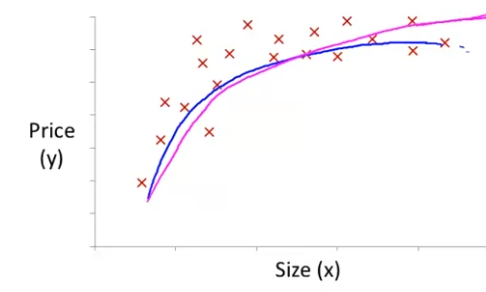
다음과 같은 집 값 data set이 있다고 가정하자.
직선은 이 data set을 표현하기 어려울 것 같으므로, 2차식 모델로 표현할 것이다.
θ0+θ1×x+θ2×x2
하지만 이는 적절치 않다. 집의 크기는 커지는데, 가격은 점점 떨어질 것이기 때문이다.
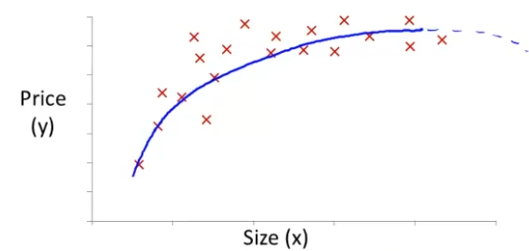
따라서 3차식 모델로 표현해보고자 한다.
θ0+θ1×x+θ2×x2+θ3×x3
그러면 이렇게 잘 나타낼 수 있다.
위 식은
hθ(x)=θ0+θ1×x+θ2×x2+θ3×x3
=θ0+θ1×(size)+θ2×(size)2+θ3×(size)3
와 같아지므로, feature을
x=(size)
x2=(size)2
x3=(size)3
로 나타낼 수 있다.
이렇게 feature을 선택했을 때는 feature scaling이 무엇보다도 중요해진다.(size) 범위가 1~1000이면, (size)2의 범위는 1~106이 되고, (size)4의 범위는 1~109가 된다. 결국 이 세개의 feature는 매우 다른 범위를 가지므로 feature scaling이 꼭 필요하게 된다.
Feature 선택하는 또 다른 방법
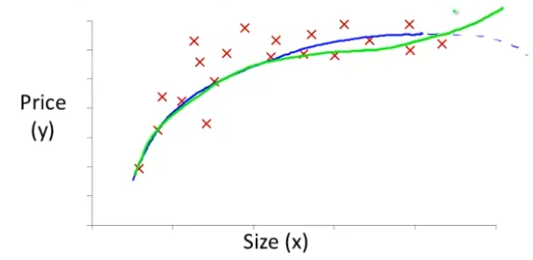
마지막으로 feature을 이루는 다양한 방법을 보여주는 예제를 들어보자. 위에서 hθ(x)=θ0+θ1×x+θ2×x2+θ3×x3으로 hypothesis를 결정하고 feature을 결정했지만, 다음과 같이도 가능하다.
hθ(x)=θ0+θ1×(size)+θ2×(size)
왜인지는 루트함수의 그래프 모양을 생각해보면 된다. 이 곡선은 갈수록 핑크색 그래프와 같은 형태를 띈다.