
Chapter 6: 정렬 (Sorting)
정렬은 컴퓨터 공학에서 가장 기본적이고 중요한 알고리즘의 하나다.
인터넷 쇼핑을 할 때 가격순으로 정렬하거나, 배달 어플에서 배달비 적은 순, 일할 때 엑셀에서 데이터 정렬 등도 이와 같다.
정렬을 위해서는 사물들을 서로 비교하여야하고 비교할 수 있는 모든 속성이 정렬의 기준이 된다. (오름차순, 내림차순)
01 "정렬이란?"
정렬(sorting)은 순서가 없는 사물들을 순서대로 나열하는 것을 말한다.
정렬은 효율적인 탐색을 위해 사용된다. 정렬되어 있지 않다면 원하는 데이터나 값을 찾는데 많은 시간이 소요될 것이다.
정렬을 위해서 사물들은 서로 비교할 수 있어야 한다. 또한, 비교할 수 있는 모든 속성은 정렬의 기준이 될 수 있다. ex) 영어 사전의 사전식 순서(lexicographical order)
같은 저렬 기준을 사용하더라도 오름차순(ascending order)과 내림차순(descending order)로 나열할 수 있다.
01. 정렬 관련 용어
- 레코드(record): 정렬시켜야 할 대상
- 필드(field): 레코드가 가지고 있는 특징 ex) 상품 레코드의 이름, 가격, 제조연도 등 필드
- 키(key) 또는 정렬 키(sort key): 정렬의 기준이 되는 필드
결국 정렬이란, 레코드들을 키의 순서로 재배열하는 것이다.
알고리즘이 단순하면 일반적으로 비효율적이다.
삽입 정렬, 선택 정렬, 버블 정렬 등이 대표적인 예다.
효율을 높이기 위해서는 복잡한 알고리즘을 사용해야한다.
대표적인 방법으로 퀵 정렬, 기수 정렬, 힙 정렬, 병합 정렬, 팀 정렬 등이 있다.
효율성 외에도 정렬 알고리즘을 분류하는 중요한 특성들이 있다.
그 중에서 안정성 (stability)은 입력 데이터에 같은 킷값을 갖는 레코드가 여러 개 있을 때, 정렬 후에도 이들의 상대적인 위치가 바뀌지 않는 것을 말한다.
제자리 정렬(in-place sorting)은 입력 배열 이외에 추가적인 배열을 사용하지 않는 정렬이다. 효율성이 같다면 안정성을 갖고 제자리 정렬 특성이 있는 알고리즘이 더 우월하다.
02. 정렬의 종류
정렬의 종류는 다양하게 있는데 정렬할 자료들이 어디에 있는지에 따라 내부 정렬(internal)과 외부 정렬(external)로 나눌 수 있다.
내부 정렬은 모든 데이터가 메인 메모리에 올라와 있는 정렬을 의미하고,
외부 정렬은 데이터가 대부분 외부 기억장치에 있고 일부만 메모리에 올려 정렬하는 방법으로 대용량 자료를 정렬하기 위해 사용한다.
(이 책에서는 내부 정렬에 대해서만 다룬다.)
정렬은 1. 두 수의 관계를 이용해서 전체 탐색을 하는지, 2. 전체 수들의 관계를 이용해서 정렬을 하는 것 등 다양하게 있다.
선택 정렬, 삽입 정렬, 버블 정렬 등이 첫 번째에 해당하고,
퀵 정렬, 기수 정렬이 두 번째에 해당한다고 볼 수 있다.
이번 Chapter에서는 각 정렬들의 종류와 방식을 알아보고 그 예시로 숫자 오름차순 배열을 보여줄 것이다.
02 "선택 정렬"
선택 정렬(selection sort)은 가장 단순하고 확실한 방법이다.
리스트에서 가장 작은 숫자를 하나씩 찾아 순서대로 저장한다. 이 과정을 반복하며 이 알고리즘은 단순하지만 한 가지 문제가 있다.
정렬을 위해 입력 리스트 외에 추가적인 리스트가 필요하다. (기존 리스트 + 정리할 리스트)
이 알고리즘을 제자리 정렬로 개선할 수 있는데, 최솟값이 선택되면 이 값을 출력 리스트에 저장하는 것이 아닌 입력 리스트의 첫 번째 요소와 교환하는 것이다.
01. 선택 정렬 알고리즘
만약 n칸의 리스트가 있으면 1. 0부터 n-2번째 인덱스까지 순서대로 대입된다.
이후 2. 최솟값을 찾는 범위는 i+1부터 n-1까지가 된다.
(포화 상태를 방지하기 위해 n번째 칸은 비워둔다.)
이 순서를 코드로 나타내면 아래와 같다.
(마지막 줄 코드는 각 단계에서 리스트가 어떻게 변화되고 있는지 확인하기 위해 추가하였다.)
# 코드 6.1: 선택 정렬 알고리즘 (제자리 정렬 방식)
def selection_sort(A):
n = len(A) # 리스트의 크기
for i in range(n-1): # 1.
min_idx = i
for j in range(i+1, n): # 2.
if A[min_idx] > A[j]:
min_idx = j # min_dex j 로 변경.
A[i], A[min_idx] = A[min_idx], A[i] # A[i]와 A[min_dex] 교환
print("Step %2d = "%(i+1), A) # 단계별 리스트 변화 출력+) 튜플을 이용한 두 변수의 변환
a와 b를 서로 교환하기 위해서는 보통 새로운 변수 t를 사용하여 t=a; a=b; b=t;와 같은 코드를 사용하지만 파이썬은 튜플을 이용하여 더 편리하게 변경할 수 있다.
위 알고리즘을 사용하여 입력 리스트에 대한 테스트 프로그램 처리 결과는 아래와 같다.
# 코드 6.2: 선택 정렬 테스트 프로그램
data = [6, 3, 7, 4, 9, 1, 5, 2, 8, 0]
print("Original :", data)
selection_sort(data)
print("Selection : ", data)
> 출력
Original : [6, 3, 7, 4, 9, 1, 5, 2, 8, 0]
Step 1 = [0, 3, 7, 4, 9, 1, 5, 2, 8, 6]
Step 2 = [0, 1, 7, 4, 9, 3, 5, 2, 8, 6]
Step 3 = [0, 1, 2, 4, 9, 3, 5, 7, 8, 6]
Step 4 = [0, 1, 2, 3, 9, 4, 5, 7, 8, 6]
Step 5 = [0, 1, 2, 3, 4, 9, 5, 7, 8, 6]
Step 6 = [0, 1, 2, 3, 4, 5, 9, 7, 8, 6]
Step 7 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Step 8 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Step 9 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Selection : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]02. 선택 정렬 특징
- 알고리즘은 간단하지만 시간 복잡도가 으로 효율적이지는 않다.
: 쉽게 생각해서 0~n-1까지 검사하는 for문 1개, 0~n-2까지 검사하는 for문 1개로 이 된다. - 자료의 구성에 상관 없이 연산의 횟수가 결정된다는 장점이 있다.
이것은 정렬할 리스트의 크기가 정해지면 리스트에 어떤 숫자가들어 있는지와 무관하게 정렬에 걸릴 시간을 예측할 수 있다. - 리스트가 크지 않은 문제라면 충분히 사용할 수 있는 알고리즘이다.
- 안정성을 만족하지 않는다.
- 제자리 정렬로 추가적인 리스트가 필요하지 않다.
03 "삽입 정렬"
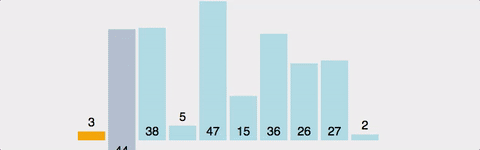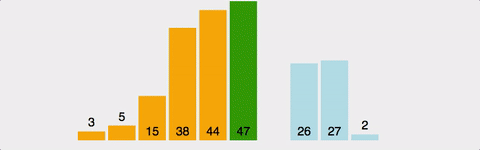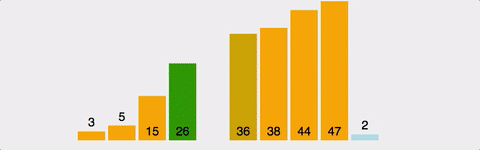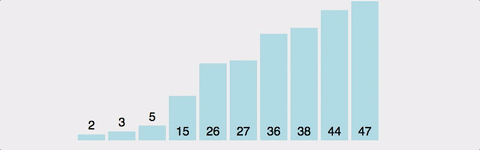
삽입 정렬(insertion sort)은 카드를 정리하는 방법과 유사하다.
카드를 추가로 한장씩 받을 때마다 적절한 위치에 끼워 넣는 것이다.
이 때 끼워 넣는다는 것은 넣을 자리 이후의 숫자들을 한 칸씩 미루고 그 자리에 복사한다는 것이다.
그림으로 나타내면 아래와 같다.
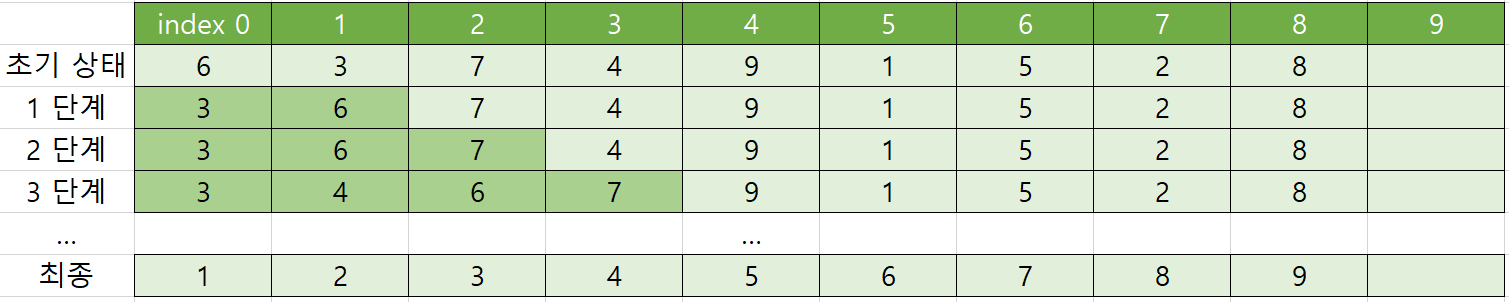
01. 삽입 정렬 알고리즘
삽입 정렬 알고리즘은 비교할 때마다 정렬된 부분의 요소가 크면 그것을 한칸 뒤로 미리 옮겨 놓는 방식으로 정리했다.
예를 들어 3단계처럼 되기 위해서는 2단계에서 List[3]의 요소가 4이고 이것을 List[1]자리로 옮겨야한다.
우선 List[2] 요소인 7과 비교하여 앞으로 옮기고 그 다음 List[1] 요소인 6과 비교하여 앞으로 옮기는 방식이다.
앞의 요소만 뒤로 복사하고 맨 마지막에 삽입할 요소를 찾은 위치에 복사하는 과정이다.
코드로 정리하면 아래와 같다.
# 코드 6.3: 삽입 정렬 알고리즘
def insertion_sort(A):
n = len(A)
for i in range(1, n): # i 범위: 1 ~ (n-1)
key = A[i] # 삽입할 요소를 미리 key에 저장.
j = i-1
while j >= 0 and A[j] > key: # key 앞에 있는 것이 key보다 클 경우
A[j+1] = A[j] # key 뒤로 보내고 (사살상 A[i]자리)
j -= 1
A[j+1] = key # key 앞자리에 key 등록
print("Step %2d = "%(i), A)
data = [6, 3, 7, 4, 9, 1, 5, 2, 8]
print("Original :", data)
insertion_sort(data)
print("Selection : ", data)
> 출력
Original : [6, 3, 7, 4, 9, 1, 5, 2, 8]
Step 1 = [3, 6, 7, 4, 9, 1, 5, 2, 8]
Step 2 = [3, 6, 7, 4, 9, 1, 5, 2, 8]
Step 3 = [3, 4, 6, 7, 9, 1, 5, 2, 8]
Step 4 = [3, 4, 6, 7, 9, 1, 5, 2, 8]
Step 5 = [1, 3, 4, 6, 7, 9, 5, 2, 8]
Step 6 = [1, 3, 4, 5, 6, 7, 9, 2, 8]
Step 7 = [1, 2, 3, 4, 5, 6, 7, 9, 8]
Step 8 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
Selection : [1, 2, 3, 4, 5, 6, 7, 8, 9]02. 삽입 정렬 특징
특징을 정렬하기에 앞서 삽입 정렬의 비교 횟수와 시간 복잡도를 계산해보자.
삽입 정렬은 선택 정렬과 달리 자료가 어떤가에 따라 while문이 한 번만에 끝날 수도, 여러 번 반복될 수도 있다. (어떤 값이 들어 있는가에 따라 처리시간이 달라지는 알고리즘이다.)
-
최선의 경우
입력 리스트가 이미 오름차순으로 정렬된 경우다.
이럴 땐 for문이 번 반복되고 그 안에 while문은 한 번만 처리 되기 때문에 전체 비교 연산은 번 수행된다. -
최악의 경우
역순으로 정렬된 리스트의 경우다.
for문이 번 반복되는데 while문은 i번만큼 반복 처리 되기 때문에 전체 비교 연산의 전체 횟수는 아래와 같다.
따라서 특징으로 되돌아오면
- 입력의 구성에 따라 처리시간이 달라지는데, 최악의 상황에 대한 시간 복잡도가 으로 효율적이지 않은 알고리즘이다.
- 끼워 넣기를 위해 많은 레코드의 이동이 필요하므로 레코드의 크기가 큰 경우 선택 정렬보다도 효율적이지 않다.
- 제자리 정렬이고 안정성도 충족한다.
- 레코드 대부분이 이미 정렬된 경우라면 효율적으로 사용될 수 있다. (최선의 경우)
04 "퀵 정렬"
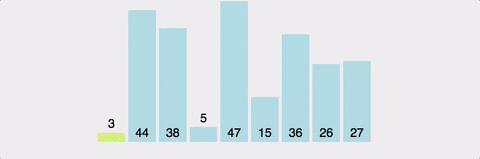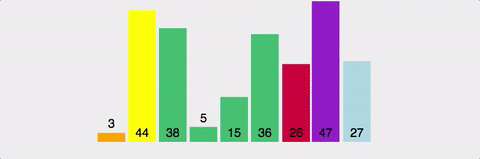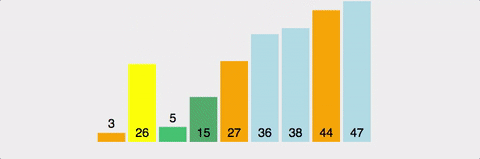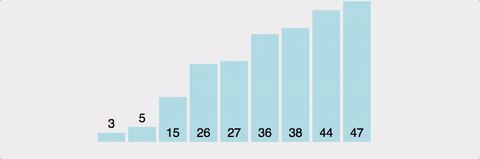
퀵 정렬(quick sort)은 이름에서 예상할 수 있듯이 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법으로 분할 정복 전략을 이용한다. (분할 정복 전략이란 하나의 문제를 둘 또는 여러 개의 작은 부분 문제로 나누고, 부분 문제들을 각각 해결한 다음 결과를 모아 원래의 문제를 해결하는 전략이다.)
퀵 정렬의 아이디어는 기준 (피벗_pivot)을 하나 정해서 기준보다 작은 것은 왼쪽으로, 큰 것은 오른쪽으로 이동시킨다. 나뉜 다음 작아진 문제를 같은 분할 과정을 거쳐 해결하면 된다.
퀵 정렬 알고리즘을 적어본다면,
def quick_sort(A, left, right):
if left < right:
pivot = partition(A, left, right) # 피벗을 기준으로 리스트를 두 부분으로 분할하고 피벗의 위치를 구함.
quick_sort(A, left, pivot-1) # 왼쪽 부분 리스트 (left~pivot-1
quick_sort(A, pivot+1, right) # 오른쪽 부분 리스트 (pivot+1~right)리스트를 피벗 기준으로 두 개의 부분 리스트로 분할하는 작업인 partition() 함수는 어떻게 정의할까?
01. 분할
분할을 할 때 부분 리스트들의 내부가 정렬될 필요는 없이 단지, 피벗을 중심으로 분리만 하면되는데...
이 작업의 아이디어는 탐색-교환 과정을 반복하면 된다.
그림으로 나타내자면, 아래와 같이 정렬할 리스트가 있다.

기준(피벗)은 굵은 테두리로 나타내었고, 입력 리스트 A에서 정렬할 부분의 시작 인덱스를 left로, 마지막 인덱스를 right로 정했다.
그 다음 왼쪽과 오른쪽 부분 리스트를 만드는데 사용되는 low와 high를 배치하는데, low = left+1, high=right로 초기화 된다.
탐색은 low를 오른쪽으로, high를 왼쪽으로 진행하면서 조건에 맞지 않는 요소를 찾는 과정이다.
-
왼쪽 부분 리스트
: A[low]가 피벗 이하이면 왼쪽 부분 리스트에 적합하므로 low를 오른쪽으로 전진시키다가. A[low]가 피벗보다 클 때 멈춘다. -
오른쪽 부분 리스트
: A[high]가 피벗보다 크면 high를 왼쪽으로 전진시키다가 A[high]가 피벗보다 작으면 멈춘다.
처음 세팅에서는 왼쪽 부분 리스트, 오른쪽 부분 리스트 조건이 맞지 않으므로 탐색이 중지된다.
그리고 양쪽에서 조건이 맞지 않는 A[low]와 A[high]를 교환한다.
그럼 아래 그림과 같이 되고

조건들에 만족되므로 다시 탐색을 시작한다.

A[low]는 조건이 맞지 않은 176에서 멈추고, A[high]는 조건이 맞지 않은 159에서 멈춘다.
다시 이 둘을 교환하고 탐색을 진행한다.

왼쪽 부분 리스트 A[low], 오른쪽 부분 리스트 A[high]를 하나씩 각자 방향대로 가다보면 둘의 위치가 바뀌는 부분이 생긴다. 그럼 탐색-교환 과정이 종료된다.

이제 피벗을 이 역전된 부분에 옮기는 작업이 남았다. 피벗을 high의 항목과 교환하면 된다.

피벗 중심으로 리스트를 2개로 나누는 것이 끝이 났고 피벗의 위치도 찾을 수 있게 되었다!
이것을 코드로 작성하면 아래와 같다.
def partition(A, left, right):
pivot = AS[left]
low = left +1
high = right
while (low<high): # low와 high가 역전되지 않는 한 반복
while low <= right and A[low] <= pivot:
low += 1 # A[low] <= 피벗이면 low를 오른쪽으로 진행
while high >= left and A[high] > pivot:
high -= 1 # # A[high] >= 피벗이면 high를 왼쪽으로 진행
if low < high: # 역전이 아니면 두 레코드 교환
A[low], A[high] = A[high], A[low]
A[left], A[high] = A[high], A[left]
return highpartition() 함수는 반드시 피벗의 인덱스를 반환해야한다.⭐
만든 함수를 통해 퀵 정렬 알고리즘을 실행해보자
data = [5, 3, 8, 4, 9, 1, 6, 2, 7]
print("Original :", data)
quick_sort(data, 0, len(data)-1)
print("QuickSort : ", data)
> 출력
Original : [5, 3, 8, 4, 9, 1, 6, 2, 7]
QuickSort : [1, 2, 3, 4, 5, 6, 7, 8, 9]02. 퀵 정렬 특징
퀵 정렬이 얼마나 빠른지 알기 위해서는 비교 연산을 구해보면 알 수 있다.
partition() 함수 안에 있는 비교 연산이 가장 많이 반복될 것이다.
피벗을 제외한 모든 요소는 피벗과 반드시 한 번씩 비교되어야하고 전체 요소의 수가 이라면 번 비교가 필요하다.
- 최선의 경우
분할이 항상 리스트의 중앙에서 이루어질 때 최선의 경우다.
부분 리스트의 크기는 레벨에 따라 처럼 절반으로 줄어든다.
이러한 분할은 리스트의 크기가 1이 될 때까지 진행된다.
따라서 순환 호출 트리의 높이는 이 된다.
트리의 각 레벨에서 여러 번의 partition() 함수가 실행되는데 하나의 레벨에서 피벗을 제외한 모든 요소를 비교해야하므로 최대 번의 비교가 필요하다.
따라서 전체 비교 연산은 가 되고 이 된다. - 최악의 경우
리스트가 계속 불균형하게 나누어질 때 최악의 경우다.
이미 정렬된 리스트는 퀵 정렬에서 최악의 입력인데 분할을 할 때마다 남은 요소들이 한쪽에 몰리기 때문이다.
정렬을 위한 순환 호출의 깊이가 이되고 결국 전체 비교 연산의 수는 에 비례하게 된다.
따라서 특징으로 되돌아오면
- 평균적으로 최선의 입력과 비슷한 속도가 나와 복잡도가 가 된다.
- 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환하며, 한번 정렬된 피벗들이 추후 연산에서 제외되기 때문에 속도가 빠르다.
- 퀵 정렬의 성능을 더 개선하기 위해 피벗으로 중간값을 선택하는 방법(median of three)이 많이 사용된다.
+) 분할 정복
분할 정복(divide and conquer)이란? 주어진 문제를 둘 또는 여러 개의 작은 부분 문제들로 나누고, 이들을 각각 해결한 다음 결과를 모아서 원래의 문제를 해결하는 전략이다.
나뉜 부분 문제가 아직 크다면 분할 정복을 부분 문제에 다시 적용한다. 이때 보통 순환 호출이 사용된다.
✨분할 정복 단계
- 분할(divide): 주어진 문제를 같은 유형의 부분 문제들로 분할한다.
- 정복(conquer): 부분 문제들을 해결하여 (부분적인)결과를 만든다.
- 병합(combine): 부분적인 결과들을 묶어 최종 결과를 만든다.
예시 1) 배열의 합 구하기
- 분할(divide): 배열을 계속 반으로 나누고 배열의 크기가 1이 될 때까지 나눈다.
- 정복(conquer): 배열의 크기가 1이면 배열의 합은 배열의 그 요소 자체다.
- 병합(combine): 부분끼리 더해 최종적으로 문제 전체의 해를 구할 때까지 진행된다.
사실 이 문제에서는 그닥 효율적으로 보이지 않는다.
순서대로 8개의 숫자의 합을 더할 때 +연산이 7번 들어가듯, 분할 정복 방법으로 구해도 총 +연산이 7번 들어가기 때문이다.
하지만 정렬이나 탐색과 같은 많은 중요한 문제에서 상당한 효과를 발휘한다.
분할 정복과 축소 정복
때로는 분할 정복을 축소 정복(decrease-and-conquer)과 구분하기도 한다.
축소 정복은 원래의 문제를 나눈 후 해결해야할 부분 문제가 하나만 남는 경우를 말한다.
예를 들어 작은 수에서부터 큰 수를 정렬하려고 하는데 반을 나누어 보니 이미 반은 정렬이 되어 있어 제외한다.
그리고 나머지 남은 반으로 문제가 줄어 원래 문제가 절반 이하로 작어진 하나의 부분 문제로 축소된다.
예시 2) 거듭제곱 구하기
어떤 수 의 거듭제곱인 을 구하는 문제를 분할 정복을 이용해서 해결해 보자.
# 코드 10.1: x의 n 거듭제곱 구하기(억지기법)
def slow_power(x, n): # 반복으로 x^n 구하는 함수
result = 1.0
for i in range(n):
result *= x
return result이 알고리즘은 곱셈이 번 사용되기 때문에 에 비례하는 시간이 걸린다.
이 문제에 분할 정복 (축소 정복) 전략을 적용하면 더 효율적인 알고리즘을 만들 수 있다.
예를 들어, 을 구하면 를 10번 곱할 수도 있지만 로도 구할 수 있다.
이는 로도 구할 수 있다.
따라서, 정리해보면 을 구하는 일반적인 경우를 생각해보면
- 모든 수의 1-거듭제곱은 그 값 자체다.
- 이 짝수면 을 먼저 계산하고, 이 값의 거듭제곱을 구한다.
- 이 홀수면 의 거듭제곱을 구해 를 곱해주면 된다.
(일 때)
(일 때)
(짝수일 때)
(홀수일 때)
# 코드 10.2: x의 n 거듭제곱 구하기(축소정복)
def power(x, n):
if n == 0:
return 1
elif n ==1:
return x
elif n % 2 == 0:
return power(x*x, n//2)
else:
return x * power(x*x, (n-1)//2)slow_power() 함수와 power()함수의 계산 속도를 비교하기 위해 time 모듈을 사용해서 확인해보자.
import time # time 모듈 포함
print(" 억지기법(2**500) =", slow_power(2.0, 500))
print("축소정복기법(2**500) =", power(2.0, 500))
t1 = time.time()
for i in range(100000):
slow_power(2.0, 500) # 억지기법 10만회
t2 = time.time()
for i in range(100000):
power(2.0, 500) # 축소정복기법 10만회
t3 = time.time()
print(" 억지기법 시간... ", t3-t1)
print("축소정복기법 시간... ", t3-t2)
> 출력
억지기법(2**500) = 3.273390607896142e+150
축소정복기법(2**500) = 3.273390607896142e+150
억지기법 시간... 2.74112606048584
축소정복기법 시간... 0.21142888069152832계산 결과 동일하고 속도에서는 확연히 축소 정복 기법이 더 빠른 것을 확인할 수 있다.
- 복잡도 분석
- 억지 기법:
- 분할 축소 기법 :
∴ 분할 축소 기법이 더 빠르다.
예시 3) 정방향 행렬의 거듭 제곱
가 만약 숫자가 아니라 행렬이라면 어떻게 될까?
인 정방형 행렬 의 거듭제곱인 을 구해보자.
- 행렬은 그래프의 인접행렬에서 사용했던 리스트의 리스트로 나타낸다.
- 의 1제곱은 자체다.
- 두 행렬을 곱하는 함수가 추가로 필요하다.
# 코드 10.4: 정방향 행렬 M의 n 거듭제곱 구하기
def powerMat(M, n):
if n == 1:
return M
elif n % 2 == 0:
return powerMat(multMat(M,M), n//2)
else:
return multMat(M * powerMat(multMat(M,M), (n-1)//2)행렬의 크기가 인 것을 고려하면 이 알고리즘의 시간 복잡도는 이다. 행렬의 크기를 무시한다면 복잡도는 이고 억지 기법의 에 비해 훨씬 우월하다.
예시 4) 선택 문제: k번째로 작은 수 찾기
정렬되지 않는 리스트에서 번째로 작은 숫자를 찾는 문제를 생각해보자.
이러한 문제를 선택 문제(selection problem)라한다.
가 1이라면 최솟값을 찾는 문제가 되겠고, 가 이라면 최댓값을 찾는 문제일거다.
이런 경우 리스트를 한번 스캔해서 최솟값이나 최댓값을 찾을 수 있으므로 복잡도가 가 된다.
리스트가 정렬되어 있다면 시간 복잡도는 정렬의 복잡도와 같아 이 된다.
정렬하지 않고 찾는 방법은 분할 정복(축소 정복)을 이용하는 것이 있다.
순서는 아래와 같다.
- 피벗을 하나 선택하고 리스트를 두 부분으로 나눈다.
- 리스트를 정렬하는 것이 아니고 번째로 작은 요소의 위치만 찾으면 된다.
- 피벗의 위치가 pos라 하면 3가지 상황이 발생한다.
Case 1) 가 인 경우: 피벗이 번째로 작은 수다.
Case 2) 인 경우: 답은 반드시 왼쪽 부분 리스트에 있고, 왼쪽 부분 리스트에서 번째로 작은 항목을 찾는 문제로 축소되었다.
Case 3) 인 경우: 답은 반드시 오른쪽 부분 리스트에 있고, 오른쪽 부분 리스트에서 번째 작은 항목을 찾는 문제로 축소되었다.
알고리즘의 구조는 퀵 정렬과 거의 비슷하다. (partition() 함수도 그대로 사용한다.)
# 코드 10.5: 분할정복을 이용한 k번째 작은 수 찾기
def quick_select(A, left, right, k):
pos = partition(A, left, right) # A에서 피벗의 인덱스
if (pos+1 == left+k): # Case 1
return A[pos]
elif (pos+1 > left+k): # Case 2
return quick_select(A, left, pos-1, k)
else: # Case 3
return quick_select(A, pos+1, right, k-(pos+1-left))- 복잡도 분석
- 최선: 첫 분할 결과가 Case1이 되어 바로 선택이 완료되는 경우로 이다.
- 최악: 이미 정렬된 리스트에서 가장 큰 항복을 찾는 경우 이다. 이때는 의 분할이 필요하므로 이다.
- 평균적인 경우 퀵 정렬과 동일하게 로 되기 때문에 정렬을 이용하는 방법보다 훨씬 우월하다.
05 "기수 정렬"
지금까지 다룬 정렬 알고리즘은 리스트의 요소를 '비교'하여 정렬하는 비교 기반 정렬이라 부른다.
기수 정렬(radix sort)은 킷값을 비교하지 않고도 효율적인 비교 기반 정렬들보다 이론적으로 더 빨리 정렬할 수 있다.
기수(radix)란? 숫자의 자릿수를 말한다. (일의 자리수, 십의 자리수, ...)
자릿수의 값에 따라서 정렬하고 단계의 수는 데이터의 전체 자릿수와 같다.
이 정렬은 비교를 하지 않고 배분을 이용해서 정렬한다.
값들을 배분해 놓았다가 순서대로 다시 모으는 것이다.
배분하기 위해서 버킷(bucket)을 사용하고 이것은 큐(queue)구조다.
한 자리 자연수의 정렬은 10개의 버킷을 준비하고 레코드의 값에 따라 버킷에 넣고 빼는 동작을 되풀이 하면 된다.
여러 자리 자연수의 정렬은 어떻게 하면 좋을까?
1의 자리와 10의 자리를 따로따로 정렬을 하는 것이다. 그러면 10개의 버킷만으로도 두 자리 정수를 정렬할 수 있다.
어떤 자리수를 먼저 처리해야할까?
낮은 자리수 부터 처리해야 정렬이 되는 것을 알 수 있다.
여러 자리의 자연수를 정렬하는 일반적인 방법은 아래와 같다.
- 십진법을 사용한다면 버킷 10개가, 2진수라면 버킷 2개가 필요하다.
- 버킷에 먼저 들어간 숫자가 먼저 나와야한다. 따라서 버킷은 큐로 구현된다.
- 버킷에 숫자를 넣은 것은 큐의 삽입(enqueue) 연산에 해당하고, 버킷에서 숫자를 읽는 연산은 큐의 삭제(dequeue) 연산에 해당한다.
01. 기수 정렬 알고리즘
버킷을 큐로 구현하기 때문에 python의 colections 모듈의 deque 클래스를 사용한다.
from collections import deque # collections 모듈의 deque를 사용
def radix_sort(A):
queues = []
for i in range(BUCKETS):
queues.append(deque())
n = len(A)
factor = 1 # 가장 낮은 자리부터 시작
for d in range(DIGITS): # 각 자릿수에 대해 처리
for i in range(n): # 모든 항목을 따라 큐에 삽입
queues[(A[i]//factor)%BUCKETS].append(A[i])
i = 0
for b in range(BUCKETS):
while queues[b]:
A[i] = queues[b].popleft()
i += 1
factor *= BUCKETS # 다음 자리수로
print("step", d+1, A) # 처리과정 출력용 문장위 알고리즘을 테스트 하기 위해 랜덤한 숫자 10개를 만들어 리스트에 넣고 우린 10진법을 이용할 것이기 때문에 BUCKETS = 10, 최대 4자리 수를 정렬할 것이기 때문에 DIGITS = 4로 설정한다.
BUCKETS = 10 # 10진법
DIGITS = 4 # 최대 4자리 숫자 정렬
# 리스트 내포(list comprehension)로 랜덤한 수 10개로 이루어진 리스트 생성
data = [random.randint(1, 9999) for _ in range(10)]
print("Original :", data)
radix_sort(data)
print("RadixSort : ", data)
> 출력
Original : [6020, 929, 8928, 2011, 5316, 2833, 6968, 2593, 2016, 2663]
step 1 [6020, 2011, 2833, 2593, 2663, 5316, 2016, 8928, 6968, 929] # 1의 자리 정렬
step 2 [2011, 5316, 2016, 6020, 8928, 929, 2833, 2663, 6968, 2593] # 10의 자리 정렬
step 3 [2011, 2016, 6020, 5316, 2593, 2663, 2833, 8928, 929, 6968] # 100의 자리 정렬
step 4 [929, 2011, 2016, 2593, 2663, 2833, 5316, 6020, 6968, 8928] # 1000의 자리 정렬
RadixSort : [929, 2011, 2016, 2593, 2663, 2833, 5316, 6020, 6968, 8928]02. 기수 정렬 특징
기수 정렬은 자릿수()와 입력 리스트의 크기()만큼 반복된다. 따라서 에 비례하는 시간만큼 걸린다.
따라서 특징은 아래와 같다.
- 아무리 좋은 비교 기반 정렬 알고리즘도 의 복잡도를 가지고 있지만 기수 정렬은 이라는 복자보를 갖는다. 따라서, 시간 복잡도 측면에서 퀵 정렬이나 병합 정렬보다 훨씬 우월하다.
- 정렬에 사용되는 킷값이 자연수로 표현되어야만 적용할 수 있다. 영어 알파벳(문자) 리스트나 영어 단어 리스트는 가능하지만 (아스키 코드로 전환하여 가능), 리스트의 요소가 실수거나 한글, 한자라면 적용이 어렵다.
- 버킷을 위한 추가적인 메모리가 필요하다. 많은 공간을 확보해 놓고 처리시간을 줄이는 방법으로 '공간을 팔아서 시간을 버는 전략'을 사용한 대표적인 알고리즘이다.
+) 공간으로 시간 벌기
공간으로 시간벌기는 메모리를 희생하여 처리시간을 향상시키는 전략이다.
해싱이 이 전략의 대표적인 예인데, 이상적인 경우 시간 복잡도가 로 최강의 탐색이 가능하다.
공간 팔아 시간 벌기
컴퓨터에서 시간과 공간의 효율성은 항상 서로 충돌하는 요소다.
피보나치 수열 문제를 예를 들자면 범위가 정해져 있는 피보나치 수라면 필요한 피보나치 수를 미리 계산해서 저장해 놓고 필요할 때마다 꺼내서 이용하면 어떨까?
공간은 필요한 수 만큼 사용()되어 많이 필요하지만 시간 복잡도는 가 될 것이다.
공간으로 시간 벌기 전략은 기수 정렬 말고도 탐색, 동적 게획법 등 아직 배우지 않은 내용들이 있어 추후에 다시 알아볼 예정이다.
해싱(hashing)
순차 탐색이나 이진 탐색은 탐색 키와 각 레코드를 비교하여 원하는 레코드를 찾았다.
해싱은 탐색키와 레코드를 비교하는 것이 아니라 탐색 키에 어떤 함수를 돌려 레코드가 저장되어야할 위치를 바로 계산하는 것이다.
해싱에서 해싱함수에 의해 충돌(collision), 오버플로(overflow) 등이 발생하여 처리시간도 이상적인 해싱보다 많이 걸리게 된다. 이를 해결하기 위해 개방 주소법(open addressing), 체이닝(chaining)을 이용해 오버플로를 처리하고 효율적인 해싱을 할 수 있게 된다. 개방 주소법을 이용한 방법으로는 선형 조사법, 이차 조사법, 이중 해싱법이 있다.
06 "이 외 다른 정렬들"
01. 버블 정렬(bubble sort)
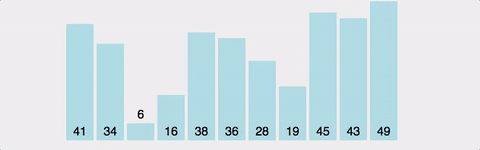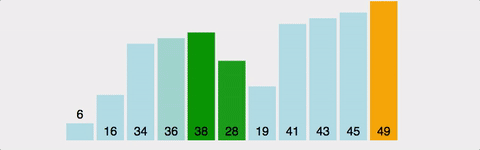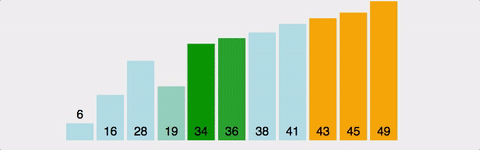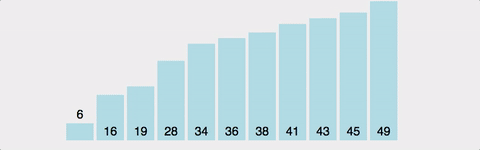
버블 정렬이란? 요소의 이동이 마치 거품이 수면으로 올라오는 듯한 모습과 닮아 지어지게 된 이름이다.
버블 정렬은 선택 정렬과 헷갈릴 수 있지만 위 움짤과 같이 처음부터 순차적으로 요소를 비교하여 정렬하는 방법이다.
1번째와 2번째 원소를 비교하여 정렬하고, 2번째와 3번째, ..., 번째와 번째를 정렬한 뒤 다시 처음으로 돌아가 이번에는 번째와 번째까지, ...해서 최대 번 정렬한다.
아래 예시가 있다.
# 버블 정렬 예시 1)
array = [6, 3, 7, 4, 9, 1, 5, 2, 8, 0]
len_array = len(array)
for j in range(len_array):
for i in range(len_array-1):
if array[i] > array[i+1]:
tmp = array[i]
array[i] = array[i+1]
array[i+1] = tmp
print(array)
# 시간 복잡도 = n^2
> 출력
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]02. 병합 정렬/합병 정렬(merge sort)
병합 정렬이란? 배열의 길이가 1이 될 때가지 2개의 부분 배열로 계속 분할한다.
그 후, 2개의 부분 배열을 합쳐 정렬한다. 모든 부분 배열이 합쳐질 때까지 반복한다.
병합 정렬의 단점은 부분 배열을 위한 추가적인 메모리 공간이 필요하다는 것이다.
최대의 장점은 데이터의 상태에 별 영향을 받지 않는다는 점이다.
03. 힙 정렬(heap sort)
이 책의 Chpater 7. 탐색에서 7-4 "이진 탐색 트리"가 이 정렬을 사용한거다.
힙이란 개념은 힙 트리에서도 사용된다.
정렬 방법은 아래와 같다.
- 원소들을 전부 힙에 삽입한다.
- 힙의 루트에 있는 값은 남은 수들 중에서 최솟값(혹은 최댓값)을 가지므로 루트를 출력하고 힙에서 제거한다.
- 힙이 빌 때까지 2의 과정을 반복한다.
사실 선택 정렬과 거의 같은 알고리즘으로. 단지 가장 큰 원소를 뒤로 보내는 데에 단순히 매번 쭉 돌면서 알아내느냐 힙을 사용하여 알아내느냐가 유일한 차이점이다.
힙정렬은 추가적인 메모리를 전혀 필요로 하지 않는다는 점과, 최악의 경우에 의 성능을 내는 퀵정렬과 달리 항상 정렬의 성능을 발휘하는 장점이 있다.
하지만 실제 코드를 짜서 비교를 해 보면 퀵정렬이 힙정렬보다 일반적인 경우에 빠르게 동작한다.
04. 트리 정렬(tree sort)
트리 정렬이란? 이진 탐색 트리를 만들어 정렬하는 방식이다.
힙 정렬과 비슷해 보이지만 차이가 있는데, 정렬될 자료의 각 원소 크기에 따라 부모 노드의 왼쪽 자식이 되느냐 오른쪽 자식이 되느냐가 갈린다는 차이가 있다.
정렬 방법은 아래와 같다.
-
정렬될 배열의 맨 첫 값이 루트 노드가 된다.
-
다음 값부터는 기존 노드 값과 비교한다.
루트 노드에서 출발해서 추가될 노드 값이 기존 노드 값보다 작은 경우는 왼쪽 자식을, 기존 노드 값보다 크거나 같을 경우는 오른쪽 자식을 찾는다.
내림차순은 반대로 기존 노드 값보다 크면 왼쪽, 작거나 같으면 오른쪽을 찾으면 된다. -
위 2에서 해당 방향의 자식 노드가 없으면 그 방향의 자식 노드로 추가한다.
있으면 그 방향의 자식 노드로 가서 크기를 비교하고 위 2와 같은 방법으로 해당 방향의 자식 노드가 있으면 계속 그 방향으로 가서 조사하고 없으면 그 방향의 자식 노드로 추가한다. -
모든 값이 노드로 추가되었으면 해당 트리를 중위 순회 방식으로 순회하여 그 순서대로 값을 정렬해 나간다.
최대값과 최소값을 탐색할때 매우 강력하다. 단, 입력값이 적은 것이 아니라면 추천하지 않는다.
05. 칵테일 정렬(cocktail sort)
칵테일 정렬이란? 버블 정렬의 파생형으로 세이커 정렬(shaker sort)라고도 한다.
홀수 번째 돌 때는 앞부터, 짝수 번째는 뒤부터 훑는 정렬. 당연하겠지만 이 쪽은 마지막과 처음이 번갈아가며 정렬된다.
제일 처음에 하나, 제일 뒤에 하나, 다시 제일 앞에 하나, 또 제일 뒤에 하나를 정렬하면서 마치 정렬하는 과정이 앞뒤로 마구 흔드는게 칵테일을 마구 흔들어 섞는것과 비슷해보인다 하여 칵테일(혹은 이름을 합쳐서 칵테일 셰이커) 정렬이라는 이름이 붙었다.
이 외에도 다양한 정렬들이 많다...w(゚Д゚)w
07 "Python의 정렬함수 활용하기"
파이썬으로 프로그램을 개발하다가 정렬이 필요하면 파이썬에서 제공하는 정렬함수를 이용하면 된다.
list의 sort() method
파이썬에서 리스트는 배열로 사용하는 것 외에도 정렬에도 사용된다. 리스트 정렬을 위해 sort() 메서드를 제공하는데, 예시를 보자.
data = [6,3,7,4,9,1,5,2,8]
data.sort()
print(data)
> 출력
[1, 2, 3, 4, 5, 6, 7, 8, 9]위는 data라는 리스트를 sort() 메서드를 이용해서 오름차순으로 정렬하는 코드였다.
만약, 내림차순으로 정렬하고 싶다면 소괄호 안에 reverse=True로 설정하면 된다.
data = [6,3,7,4,9,1,5,2,8]
data.sort(reverse=True)
print(data)
> 출력
[9, 8, 7, 6, 5, 4, 3, 2, 1]python의 내장 함수 sorted()
파이썬의 내장 함수인 sorted() 함수를 이용해서도 정렬할 수 있다.
위에서 리스트의 메서드였던 sort()는 원래 리스트가 정렬되어 반환되었다. sorted()함수는 새로운 리스트로 정렬된 데이터를 반환한다는 것이 특징이다. (원래의 리스트는 수정되지 않는다.)
data = [6,3,7,4,9,1,5,2,8]
result = sorted(data)
print(f'origin: {data}\nresult: {result}')
> 출력
origin: [6, 3, 7, 4, 9, 1, 5, 2, 8]
result: [1, 2, 3, 4, 5, 6, 7, 8, 9]이 내장함수도 sort() 메서드와 동일하게 reverse=True로 설정하면 내림차순으로도 정렬할 수 있다.
result = sorted(data, reverse=True)*팀 정렬 (Tim sort)
파이썬 정렬 함수인 sorted()함수와 리스트의 sort() 메서드는 팀 정렬이라는 알고리즘을 사용한다.
팀 정렬이란? 삽입 정렬과 병합 정렬에 기반을 둔 하이브리드 알고리즘으로, 파이썬 언어에서 사용하기 위해 구현한 정렬 방법이다.
이 알고리즘은 복잡한데, 우선 런(run)이란 개념을 사용해서 입력 데이터를 순서대로 스캔하면서 오름차순이나 내림차순으로 구성된 데이터 묶음을 찾고 이들을 스택에 저장한다.
이때, 내림차순의 데이터는 순서를 뒤집어야겠죠?
런이 준비되면 스택의 런에 대해 조건에 따른 병합을 진행한다.
런이 특정한 크기보다 작으면 삽입 정렬을 사용하고, 그렇지 않으면 병합 정렬을 이용하는데 최종적으로 스택의 런이 하나가 될 때까지 반복한다.
팀 정렬은 성능 향상을 위해 다양한 최적화 기법들을 사용한다.
예를 들어, 두 개의 런 A와 B를 병합하려 할 때, A의 어떤 원소에 해당하는 위치를 B에서 찾기 위해 이진 탐색을 사용하고, 한쪽 런의 항복이 일정 횟수 이상으로 연속적으로 선택되어 병합되면 데이터를 묶음으로 한꺼번에 옮기는 방법도 이용한다.
따라서, 여태 배운 어떤 얼고리즘보다 복잡한 방법이다.
하지만 정렬된 데이터에 대해서는 복잡도 , 최악의 경우에서도 복잡도 를 보장하여 퀵 정렬보다 우수하면서도 안정성을 충족한다.
복잡한 레코드의 정렬
만약 정렬해야되는 대상이 정수나 실수가 아닌 2차원 점의 위치나 3차원 점의 위치면 어떨까?
아래 예시용 점들의 리스트가 있다.
data = [(62, 88, 81), (50, 3, 31), (86, 53, 42), (73, 47, 4), (89, 9, 8), (47, 88, 55), (19, 18, 20), (15, 1, 88), (90, 6, 60), (41, 92, 19)]data의 각 항목은 점의 좌표 를 나타내고 파이썬의 튜플로 저장되어 있다.
하나의 레코드에 3개의 필드가 있으므로 정렬을 위해서는 기준을 정해야 한다. 아래는 정렬 기준 예시다.
기준 1) 값의 오름차순으로 정렬
기준 2) 값의 내림차순으로 정렬
기준 3) 크기의 오름차순으로 정렬. (크기 = )
방법 1) 정렬 함수 사용
파이썬의 정렬 함수는 정렬의 기준을 지정하기 위해 키워드 인수 key를 제공한다.
key에 정렬 기준을 반환하는 함수를 지정하는데 아래 예시와 같이 레코드에서 키를 반환하는 함수를 만들고 키워드 인수로 해당 함수를 사용해서 나타내면 된다.
def keyfunc(p): # 레코드 p에서 키를 반환하는 함수
return p[0] # p의 첫 번째 요소 p[0](x값) 을 키로 반환
print("data :", data)
x_inc = sorted(data, key=keyfunc)
print("x_inc :", x_inc)
> 출력
data : [(62, 88, 81), (50, 3, 31), (86, 53, 42), (73, 47, 4), (89, 9, 8), (47, 88, 55), (19, 18, 20), (15, 1, 88), (90, 6, 60), (41, 92, 19)]
x_inc : [(15, 1, 88), (19, 18, 20), (41, 92, 19), (47, 88, 55), (50, 3, 31), (62, 88, 81), (73, 47, 4), (86, 53, 42), (89, 9, 8), (90, 6, 60)]방법 2) lambda 함수를 이용한 키 지정
위 함수를 만드는 방법보다 간단한 방법이 있다.
바로 람다 함수(lambda)를 이용하는 것이다.
람다 함수 또는 람다식은 def 키워드로 작성되지 않고, lambda란 키워드로 만드는 특별한 함수다.
이름이 없는 한줄짜리의 함수를 만들어 함수 호출에서 인수로 전달할 때 매우 유용하다.
인자(argument) : 식(expression)
→ 기준 1에 대한 람다 함수
람다 함수는 보통 함수로 저장하지 않고 바로 사용하는데 앞에서 설명한 keyfunc() 함수를 따로 만들어 사용하는 경우와 동일하게 동작한다.
x_inc_lam = sorted(data, key=lambda p: p[0])
print("data :", data)
print("x_inc_lam :", x_inc_lam)
> 출력
data : [(62, 88, 81), (50, 3, 31), (86, 53, 42), (73, 47, 4), (89, 9, 8), (47, 88, 55), (19, 18, 20), (15, 1, 88), (90, 6, 60), (41, 92, 19)]
x_inc_lam : [(15, 1, 88), (19, 18, 20), (41, 92, 19), (47, 88, 55), (50, 3, 31), (62, 88, 81), (73, 47, 4), (86, 53, 42), (89, 9, 8), (90, 6, 60)]기준 2(값 내림차순)에 대한 코드도 작성해보면
y_dec_lam = sorted(data, key=lambda p: p[1], reverse=True)
print("data :", data)
print("y_dec_lam :", y_dec_lam)
> 출력
data : [(62, 88, 81), (50, 3, 31), (86, 53, 42), (73, 47, 4), (89, 9, 8), (47, 88, 55), (19, 18, 20), (15, 1, 88), (90, 6, 60), (41, 92, 19)]
y_dec_lam : [(41, 92, 19), (62, 88, 81), (47, 88, 55), (86, 53, 42), (73, 47, 4), (19, 18, 20), (89, 9, 8), (90, 6, 60), (50, 3, 31), (15, 1, 88)]기준 3(크기 오름차순)을 위해서는 제곱근을 구해야하기 때문에 math 모듈의 sqrt() 메서드를 이용한다.
따라서 아래와 같이 작성할 수 있다.
import math
magni = sorted(data, key=lambda p: math.sqrt(p[0]**2 + p[1]**2 + p[2]**2))
print("data :", data)
print("magni :", magni)
> 출력
data : [(62, 88, 81), (50, 3, 31), (86, 53, 42), (73, 47, 4), (89, 9, 8), (47, 88, 55), (19, 18, 20), (15, 1, 88), (90, 6, 60), (41, 92, 19)]
magni_lam : [(19, 18, 20), (50, 3, 31), (73, 47, 4), (15, 1, 88), (89, 9, 8), (41, 92, 19), (90, 6, 60), (86, 53, 42), (47, 88, 55), (62, 88, 81)]이를 keyfunc() 함수를 만들어 표현한다면 아래와 같다.
def keyfunc3(p):
return math.sqrt(p[0]*p[0] + p[1]*p[1] + p[2]*p[2])
magni = sorted(data, key=keyfunc3)
print("data :", data)
print("magni :", magni)
> 출력
data : [(62, 88, 81), (50, 3, 31), (86, 53, 42), (73, 47, 4), (89, 9, 8), (47, 88, 55), (19, 18, 20), (15, 1, 88), (90, 6, 60), (41, 92, 19)]
magni : [(19, 18, 20), (50, 3, 31), (73, 47, 4), (15, 1, 88), (89, 9, 8), (41, 92, 19), (90, 6, 60), (86, 53, 42), (47, 88, 55), (62, 88, 81)]후기
정말이지 정렬을 정리하는데 (라임 보소) 2주가 넘게 걸렸다,,,
그만큼 정렬의 종류도 다양하고 알고리즘을 만드는 예시를 이해하는 등 오랜 시간이 걸렸는데
사실 약속이 정말 많았다 ㅎ
이렇게 시리즈 출간을 할 수 있게 되서 너무나 다행이다~!
요즘 다들 일하는 시간에 아버지 사무실로 나와서 공부를 하니깐 확실히 집에만 있을 때보다 공부도 잘 되고 아침 시간을 허비하지 않게되어 너무 좋다 ㅎㅎ
정렬을 C언어로도 배워 포인터의 개념과 더해져 잘 이해하고 싶다. (이건 아마 추석 이후에 할 예정!)
앞으로 더 힘내서 책을 완독해보자!

참고
