최적화 용어 정리
Generalization
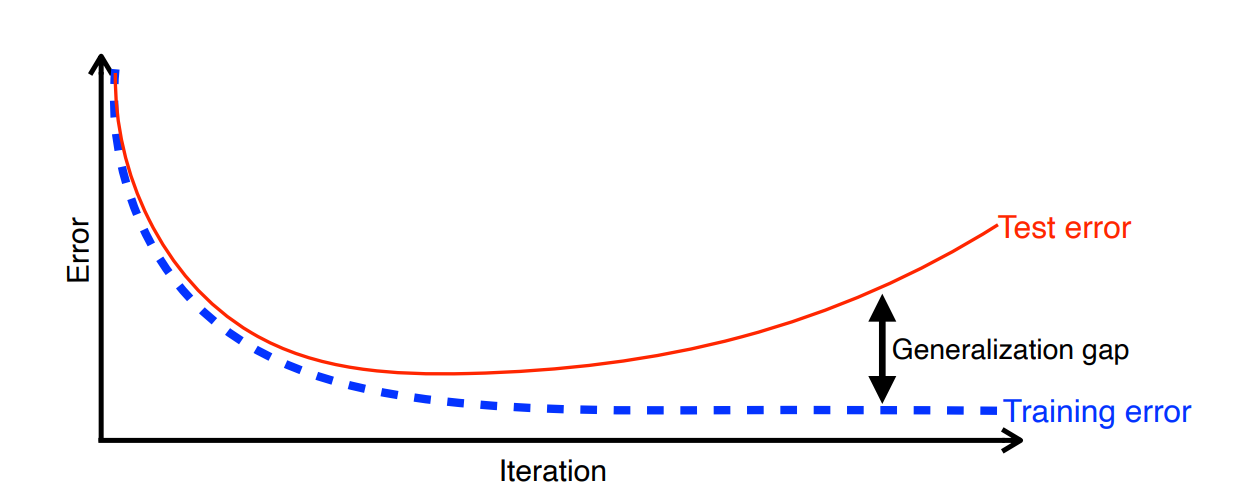
Generalization은 테스트 에러와 학습 에러의 차이를 줄이는 것을 의미한다. 즉 Generalization 성능이 좋다는 것은 테스트 데이터와 학습 데이터의 비슷한 성능을 보장한다는 뜻이 된다. 모델의 성능이 좋은 것과는 다르다. 학습 데이터의 성능이 낮은 경우에는 Generalization이 보장되어도 테스트 데이터 성능이 낮게 나온다.
Under-fitting과 Over-fitting

언더피팅은 학습이 덜되어서 학습 데이터에서도 성능이 안나오는 경우를 말한다. 반면 오버피팅은 학습이 과하게 되어서 학습 데이터의 성능은 매우 잘 나오지만, 테스트 데이터의 성능이 안나오는 경우를 말한다.
cross validation
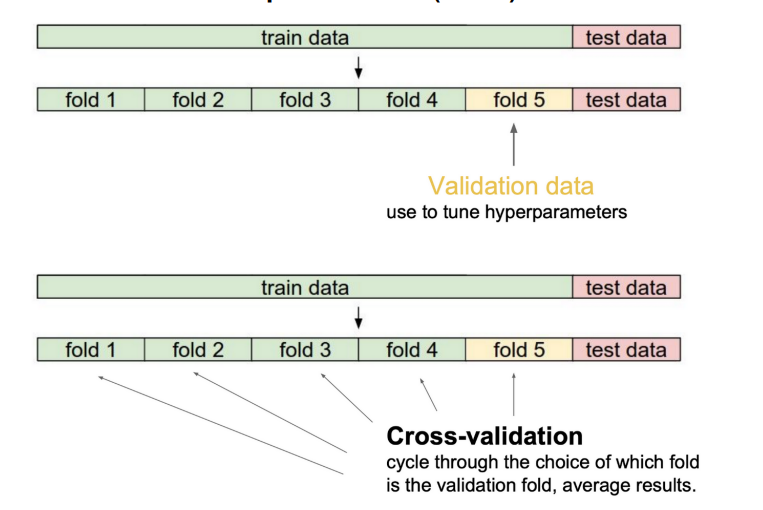
test data는 어떤 경우에도 학습에 사용하면 안된다. 따라서 학습 중 테스트를 하기 위해서는 validation data를 사용한다.
일반적으로 validation data를 제외한 train data로 학습 후에 validation data로 모델의 성능을 평가하는 방법을 반복하여 적절한 하이퍼 파라미터 값을 찾는다. 하이퍼 파라미터 값을 찾으면 전체 train data로 모델을 학습시킨다. 데이터가 많을 수록 학습에 유리하기 때문이다.
bias-variance trade off
Variance는 출력의 일관성, Bias는 출력 평균과 target의 차이를 의미한다.
- variance : 에러, 노이즈를 잘 잡아내는 모델에 데이터를 학습시켜 실제 현상과 관계없는 feature까지 학습하는 경향 (Overfitting)
- bias : 모든 데이터를 고려하지 않아 계속 잘못된 것을 학습하는 경향 (underfitting)
Bias and Variance Tradeoff는 Data에 noise가 있다고 가정할 때, bias와 variance를 모두 줄일 수는 없다는 것이다. 데이터의 규칙성를 정확히 잡아내면서 학습하지 않는 데이터에 대해 일반화를 잘 할 수는 없다.
Bagging and Boosting
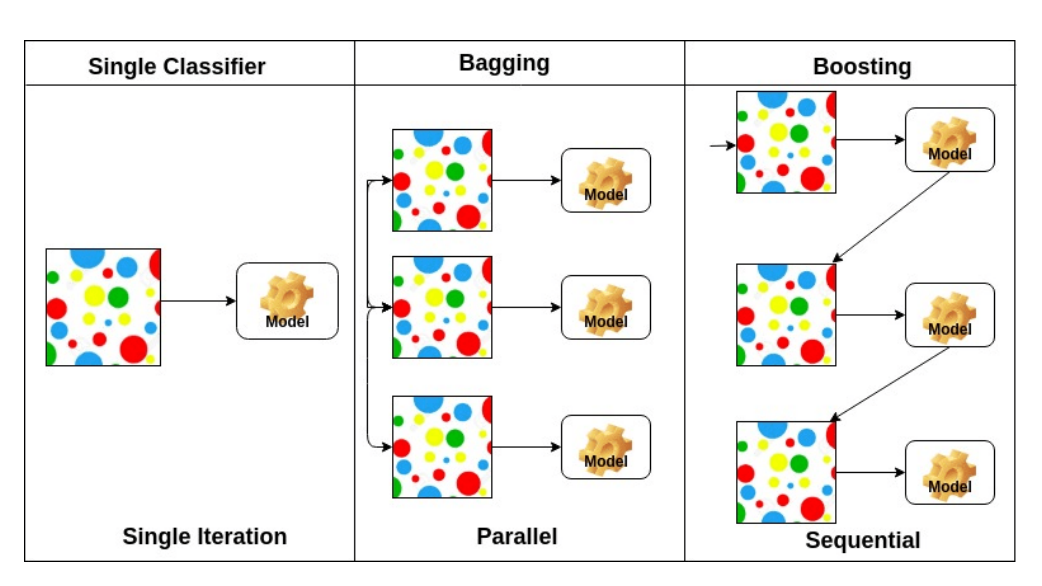
Bagging은 Boostrapping을 사용하여 여러개의 모델을 독립적으로 학습하고 그 결과를 voting, averaging 같은 방식을 사용해 종합하여 사용하는 것을 말한다.
Boostrapping
전체 데이터를 한번에 사용하는 것이 아니라 샘플링하여 여러개의 dataset을 만든다. 샘플링을 할 때는 중복을 허용한다.
Boosting은 일부 데이터에서만 잘 작동하는 weak learner를 여러개 만들어 sequential하게 합치는 방법이다.
Gradient Descent
경사하강법은 데이터 사용 방식에 따라 다음과 같이 나눈다.
Stochastic gradient descent: 1개의 data만 사용하여 gradient 계산Mini-batch gradient descent: batch-size개의 data만 사용하여 gradient 계산Batch gradient descent: 전체 data를 사용하여 gradient 계산
Gradient Descent 적용 방식
Gradient를 사용하여 parameter를 업데이트 하는 방식으로는 크게 2가지 계열로 나눌 수 있다. 이전 gradient값을 활용하는 Momentum 계열과 Parameter의 변화량을 고려하여 Parameter의 업데이트 정도를 조정하는 Adptive 계열이다.
momentum 계열
-
Momentum
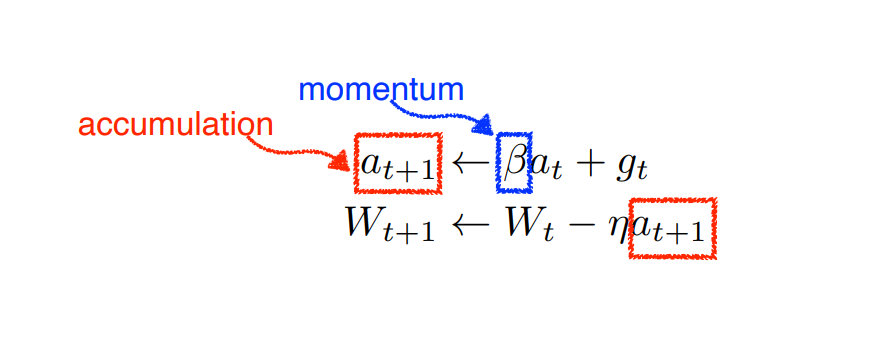
이전의 gradient를 활용한다. Batch마다 gradient값이 달라져도 어느정도 학습을 보장할 수 있다. -
Nesterov accelated gradient

Momentum은 관성때문에 local minimum에 정확히 도달하기까지 오래 걸린다. 따라서 현재 Momentum 방향으로 1 step 가서 gradient를 계산한다.
adaptive 계열
-
Adagrad
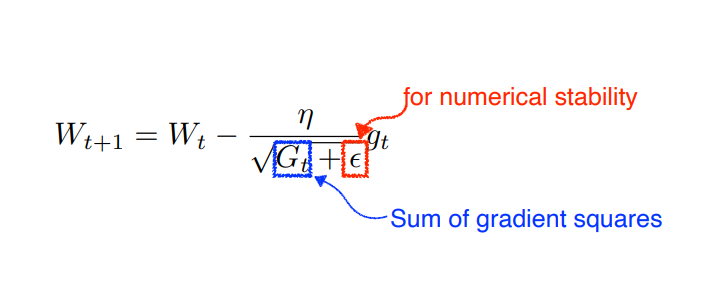
현재까지의 parameter 변화량을 G에 저장한다. 많이 변화된 parameter는 조금 변화하고, 적게 변화한 parameter는 많이 변화한다. -
Adadelta
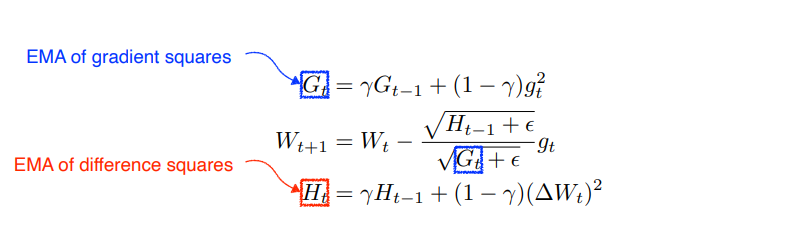
Adagrad는 G의 값이 계속 커져 무한대가 되면 학습이 안된다는 단점이 있다. Adadelta는 이 단점을 보완하기 위해 일정 크기의 과거 변화량만 고려한다. Adadelta는 learning rate가 없다. -
RMSprop
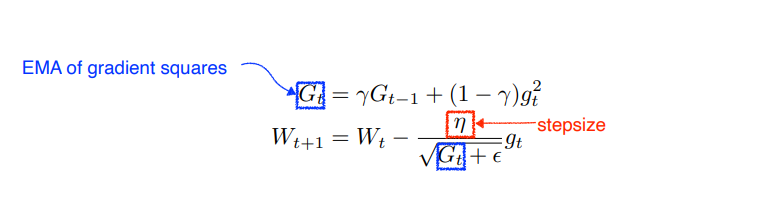
일정 크기의 과거만 고려하는 것은 Adadelta와 같으나 step size가 있다. -
Adam
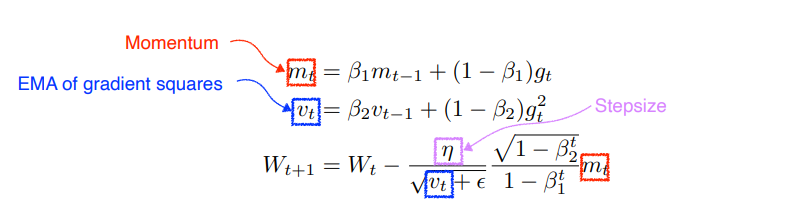
일반적으로 가장 많이 사용하는 Optimizer이다. Adaptive 방식과 Momentum 방식을 합쳐서 사용한다.
Optimizer 차이
선형 회귀 문제에서 같은 모델과 데이터를 사용하고, Optimizer만 다르게 사용하였을 때 차이는 다음과 같다.
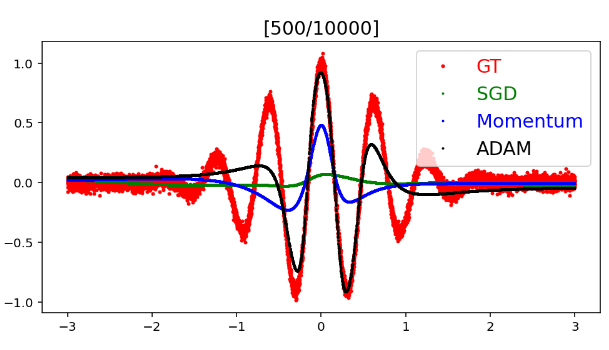
500번째 학습에서 Adam 방식을 거의 원래 그래프와 일치한다. 이를 통해 Adaptive 방식과 Momentum 방식을 모두 사용하는 것이 얼마나 효율적인지 알 수 있다.
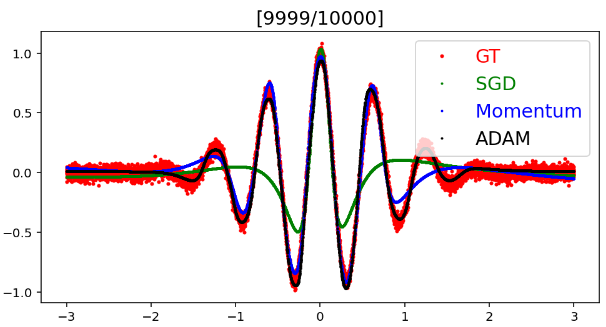
반면 SGD는 학습의 마지막까지 연속함수를 제대로 근사하지 못한다. Momentum이 SGD보다 학습이 잘 된 이유는 이전 Gradient를 사용하기 때문에 한번에 더 많은 데이터를 보고, 업데이트 하는 효과가 발생하기 때문이다. SGD는 입력된 batch만 활용하기 때문에 그래프의 일부분만 업데이트되어 더 느리다.
물론 학습을 더 진행하면 SGD가 다른 방식보다 더 좋은 성능을 낼수도 있다. 그러나 학습 속도에 있어 SGD와 Adam, Momentum은 큰 차이가 있다. 모델의 성능이 안나올 때는 모델의 문제도 있지만 Optimizer의 문제일 수도 있음을 고려해야 한다.
Reaularization
학습 데이터가 아닌 test에서도 성능이 잘 나오도록(generalization 성능을 좋게 한다.) 학습을 방해하는 규제를 걸어 오버피팅을 방지한다.
Early stopping
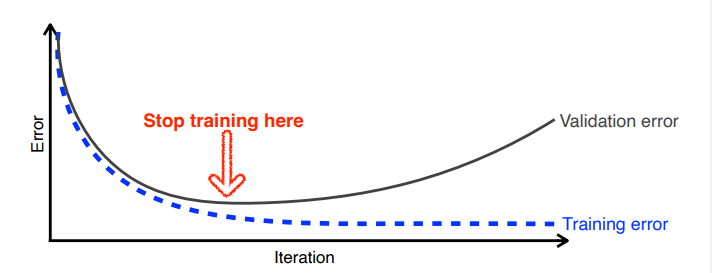
validation error가 증가하기 시작하면 학습을 중지한다.
Parameter norm penalty (weight decay)
smooth함 함수일수록 generalizatin 성능이 좋다고 가정한다. 따라서 모델의 표현력을 제한하기 위해(파라미터를 0에 가깝게 만든다.) parameter 크기에 패널티를 부여한다.
특정 가중치만 커지는 경우도 오버피팅을 유발할 수 있다. 크기가 큰 가중치면 더 큰 패널티를 받도록 설계하여 특정 값이 커지는 것도 방지한다.
Data augmentation
딥러닝에서 오버피팅을 방지하는 가장 쉬운 방법은 데이터의 양을 늘리는 것이다. label-preserving transform을 사용해 가지고 있는 데이터를 늘려 학습에 사용한다.
Noise robustness

위와 같이 모델의 input과 weight에 노이즈를 넣어 흔들어주면 테스트 성능이 좋아진다고 한다.
Label smoothing

train data의 두 데이터를 다양한 방식으로 섞어서 data로 사용한다. 구현 난이도는 높지 않은데 성능이 좋아져 많이 사용한다고 한다.
Dropout
Weight를 일정 확률로 0으로 만든는 기법이다. 수학적 증명은 되지 않았지만, 사용하면 성능이 좋아지는 것이 확인되었다.
Batch normalization
Batch 단위로 데이터를 feeding하면 batch마다 데이터 분포가 달라진다. 이를 batch별로 normalization하여 input data의 분포를 일정하게 맞추는 것을 batch normalization이라고 한다. 일반적으로 batch normalization을 사용하면 성능이 좋아진다.
참고
- bias-variance tradeoff : https://bywords.tistory.com
- bagging과 boosting : https://www.datacamp.com
- batch normalization : https://gaussian37.github.io/dl-concept-batchnorm/
