
Pandas
: 행과 열로 이루어진 데이터들의 처리를 지원하는 라이브러리데이터 구조
- Series : 1차원 형태로 방향인 하나인 데이터구조 (인덱스+값)
- DataFrame : 2차원형태로 행,열 2방향으로 이루어진 데이터구조 (X축,Y축의 표형태)
- 1차원의 Series들이 모여서 2차원의 DataFrame을 이루게 됨
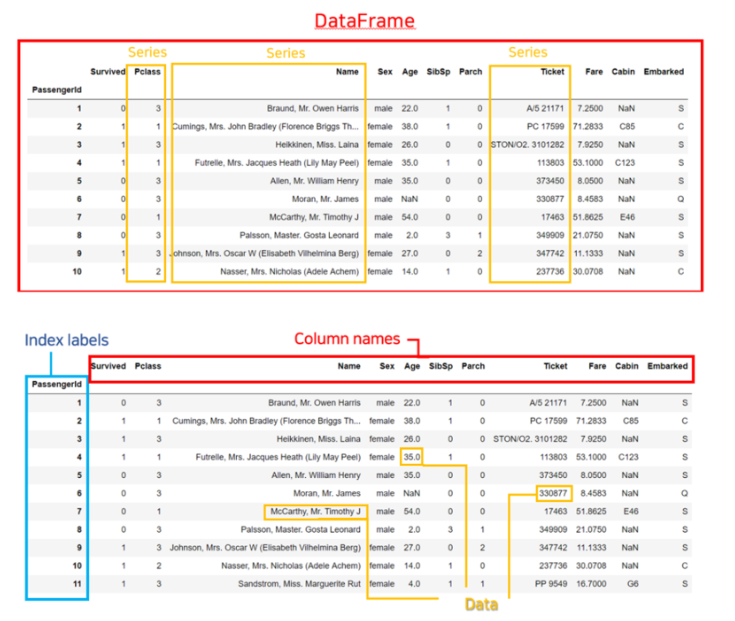
pd.Seires
-
시리즈 생성하기
import pandas as pd # 방법1. 리스트를 이용하여 시리즈 생성 ## 인덱스 지정 안하면, 인덱스번호 자동 생성 s = pd.Series([값1,값2,...], index=[인덱스1,인덱스2,...]) # 방법2. 딕셔너리를 이용하여 시리즈 생성 s = pd.Series({'인덱스1':값1, '인덱스2':값2, ...}) type(s) #pandas.core.series.Series -
시리즈 이름, 인덱스 이름 지정
시리즈.name = ‘시리즈이름’: 시리즈 이름 설정시리즈.index.name = ‘인덱스이름’: 인덱스 이름 설정시리즈.index = 리스트: 인덱스 변경
-
데이터 변경/추가/삭제
시리즈['인덱스'] = 값: 데이터 변경시리즈['새인덱스'] = 새값: 데이터 추가del 시리즈['인덱스']: 데이터 삭제
-
시리즈 연산
- 사칙연산 가능
- 시리즈끼리 연산 시, 인덱스가 같은 것끼리 연산
- BUT 인덱스가 다른 것들은 연산 불가(NaN, Not a Number)
-
시리즈 인덱싱, 슬라이싱
- Indexing :
시리즈[인덱스 번호]또는시리즈[인덱스명] - Slicing :
시리즈[인덱스 처음번호 : 끝번호](끝번호 포함x) 또는시리즈[인덱스 처음이름 : 끝이름](끝이름 포함) - 시리즈.index 와 시리즈.values 도 인덱싱, 슬라이싱 가능
- Indexing :
pd.DataFrame
- DataFrame 생성하기
import pandas as pd # 방법1. 리스트를 이용하여 데이터프레임 생성 ## 설정한 위치 그대로 생성 p = pd.DataFrame([[값11,값12,...], [값21,값22,...], ...], index=[인덱스1, ...], columns=[칼럼명1, ...]) # 방법2. 딕셔너리를 이용하여 데이터프레임 생성 ## 각 칼럼에 대한 데이터가 위에서 아래로 생성 p = pd.DataFrame({'칼럼1':[값들,...], '칼럼2':[값들,...]}, index = [인덱스1,,,]) 데이터프레임.T: 전치행렬 (행.열 전환)pd.read_csv(’파일경로/파일이름.확장자’, encoding='인코딩방식', index_col='인덱스로 사용할 컬럼명'): csv파일을 불러와서 데이터프레임으로 출력encoding = ‘cp949’또는‘euc-kr’: 한글 문자 전용 인코딩 방식index_col = ‘칼럼명’: 인덱스 컬럼 설정
- 데이터 추가/삭제
데이터프레임['새로운칼럼명'] = [값들]: 새로운 칼럼 추가del 데이터프레임명['칼럼명']: 칼럼(열) 삭제데이터프레임명.drop('인덱스/칼럼 이름', axis=0, inplace=False): 행 또는 열 삭제- axis = 0 (행 삭제, 디폴트), 1(열 삭제)
- inplace = True (자동 업데이트)
- 데이터프레임 속성 확인
데이터프레임.shape: 행,열 개수 확인데이터프레임.values: 데이터프레임의 데이터 값만 확인데이터프레임.index: 인덱스만 확인데이터프레임.columns: 컬럼명만 확인
- 데이터프레임 연산
- 인덱스랑 컬럼명이 다르면 연산 불가
- 인덱스가 같으면 같은 컬럼명의 데이터들 끼리만 연산
- 데이터프레임 인덱싱, 슬라이싱
- 데이터프레임의 기본적인 열 접근은 컬럼명으로, 행 접근은 슬라이싱 문법으로 접근함
데이터프레임[칼럼명]: 열 인덱싱 (시리즈 형태)데이터프레임[[칼럼명들]]: 열 인덱싱 (데이터프레임 형태)데이터프레임[처음 인덱스 번호/이름 : 끝 인덱스 번호/이름]: 행 인덱싱 (슬라이싱 문법 사용!!)- loc(location), iloc(integer location)를 이용한 인덱싱은 한 번에 행과 열에 대한 모두 접근 가능 (기본적으로 행에 먼저 접근)
데이터프레임명.loc[행이름[, 열이름]]데이터프레임명.iloc[행번호[, 열번호]]
- 블리언 인덱싱(Boolean Indexing) : numpy의 array와 동일하며 데이터프레임에서 특정한 조건에 맞는 데이터에만 접근하기 위한 인덱싱 방식
- ex.
df[df[’점수’]==0]: 점수 칼럼이 0인 데이터
- ex.
- 데이터프레임 관련 함수들
데이터프레임.sort_index(axis=0, ascending=True): index 또는 칼럼 기준 정렬- axis = 0 (인덱스 기준 정렬, 디폴트), 1 (칼럼명 기준 정렬)
- ascending = True (오름차순, 디폴트), False (내림차순)
데이터프레임.sort_values(by='칼럼명', axis=0, ascending=True): 값 기준 정렬- axis = 0 (칼럼명 기준 행방향, 디폴트, by=’칼럼명’ 일 때 사용), 1 (인덱스명 기준 열방향, by = ‘인덱스명’ 일 때 사용)
- by = [칼럼명들] : 기준 칼럼 여러개 가능
데이터프레임.sum/mean/max/min/count(axis=0): 합계/평균/최대/최소/개수- axis = 0 (행방향, 디폴트, 각 칼럼에 대한 결과), 1 (열방향, 각 인덱스에 대한 결과)
데이터프레임.info(): 데이터프레임에 대한 전체적인 정보 출력데이터프레임.value_counts(): 특정 칼럼에 있는 데이터들의 유니크 값과 그 개수들 출력데이터프레임.apply(적용할 함수, axis=0): 행 또는 열에 복잡한 처리 및 연산을 한 번에 진행해주는 함수- apply함수 사용을 위해서는 사전에 사용자 정의 함수가 선언되어 있어야 함(우리가 만든 사용자 정의 함수의 로직에 따라서 적용시켜주기 때문!)
- 사용자 정의 함수에 입력되는 매개변수는 apply함수 바로 앞의 변수가 들어오게 됨
pd.concat([병합할 시리즈/데이터프레임들], axis = 0): Series나 DataFram을 병합데이터프레임.groupby('칼럼명'): 데이터를 그룹별로 묶어서 집계를 낼 수 있게 해주는 함수- 엑셀의 피벗테이블과 기능 유사

개발, 분석 배운 내용 정리하기!