
한국제조데이터 인공지능학회 KSMA
국비 확보를 위해선 4가지만 기억하세요! 박민원 단장의 원포인트 레슨!!서마터한 슥대리 미래산업 전문가https://www.youtube.com/watch?v=Hn2srCvFac4총장님의 국비확보 강의
배치 사이즈 선택 기준
배치 크기 선택의 기준:일반적으로 32, 64, 128과 같은 크기가 많이 사용되며, 문제의 크기, 데이터의 양, 모델 구조, 하드웨어(GPU/TPU) 등의 요소에 따라 적절한 배치 크기를 선택해야 합니다.작은 배치 크기는 더 나은 일반화 성능을 얻을 수 있지만, 큰
텐서는 3D차원만 입력으로 받는가?
PyTorch에서 입력 오류는 주어진 모델이나 연산이 특정 차원을 필요로 할 때 발생할 수 있습니다. 그러나 3D 텐서가 아니라고 해서 반드시 오류가 발생하는 것은 아닙니다. PyTorch에서는 모델의 구조와 레이어에 따라 요구되는 입력 텐서의 차원이 다릅니다.Full
핀터레스트에서 사용하는 기술
https://www.blossominkyung.com/recommendersystem/pixie#83ed0ed7-d795-41e2-8925-ee4b31c4599e
GNN에서 logit을 임베딩 벡터로 보는 이유는?
네, GNN(Graphe Neural Network)에서 소프트맥스 전에 나오는 로짓(logit) 값을 임베딩 벡터로 볼 수 있습니다. 특히 GNN 모델의 출력은 각 노드에 대한 예측 값으로, 이 로짓은 노드의 임베딩을 나타낸다고 할 수 있습니다.왜 GNN에서 로짓을
logit이 뭐야?
로짓(logit)은 소프트맥스(Softmax) 또는 시그모이드(Sigmoid) 함수에 입력되는 원시 예측 값입니다. 로짓은 모델의 마지막 레이어에서 나오는 값으로, 아직 확률로 변환되지 않은 상태의 점수입니다. 쉽게 말해, 로짓은 소프트맥스나 시그모이드 함수에 들어가기
Haystack
Haystack은 PDF와 같은 문서에서 정보를 추출하고, 질문-응답(QA) 시스템을 구축하기 위한 오픈 소스 NLP 프레임워크입니다. 주로 기업이나 연구에서 문서 기반 검색 및 QA 시스템을 구현할 때 사용됩니다. Haystack은 최신 Transformer 기반 모
활성화 함수가 없으면 미분이 불가능한가?
활성화 함수가 없더라도 미분은 가능합니다. 그러나 활성화 함수가 없는 신경망은 단순히 선형 변환만을 수행하는 모델이 되어, 비선형성을 잃게 됩니다. 이 경우, 신경망의 각 레이어는 하나의 선형 방정식으로 나타낼 수 있으며, 레이어가 아무리 깊어져도 결국 하나의 선형 변
ViT에서 Linear Projection은 결국 one layer Neural Network가 아닌가?
네, 맞습니다! Linear Projection은 본질적으로 하나의 층을 가진 신경망(one-layer neural network)와 같은 역할을 합니다. 이를 조금 더 구체적으로 설명하면:수학적 구조:Linear Projection은 선형 변환을 통해 입력 벡터를 다
Vision Transformer에서 Linear Projection을 하는 이유는?
고정된 차원의 임베딩 벡터로 변환하여, 일관된 입력을 제공하기 위해서Linear Projection은 주로 입력 데이터를 고정된 차원의 임베딩 벡터로 변환하기 위해 사용됩니다. 이를 통해 다양한 차원이나 구조를 가진 데이터를 Transformer와 같은 신경망 모델에서
기존 Transformer의 입력에서는 입력값에 Normalization을 안하는데 Vision Transformer에서는 특히 Normalization을 하는 이유가 있을까?
Vision Transformer(ViT)에서 Normalization(주로 Layer Normalization)을 사용하는 이유는 이미지 데이터의 특성과 Transformer 구조의 차이에 기인합니다. 기존 Transformer에서 입력값에 직접적으로 Normaliz
Imagenet으로 Pretraining된 모델을 Fine Tuning 해보는 것을보며 Fine Tuning에 대해 이해하기
ImageNet으로 사전 학습된 모델을 fine-tuning하는 방법은, 사전 학습된 모델을 새로운 데이터셋에 맞춰 조정하는 과정입니다. 사전 학습된 모델이 ImageNet과 같은 대형 데이터셋에서 이미 학습된 가중치를 사용하기 때문에, fine-tuning은 더 작은

추천시스템 학회
Recommender System (추천 시스템)RecSysThe ACM Conference Series on Recommender SystemsRecSys 2020 accepted papers매년 9~10월 개최2007년부터 시작되었으며, 음악, SNS, 이커머스 등

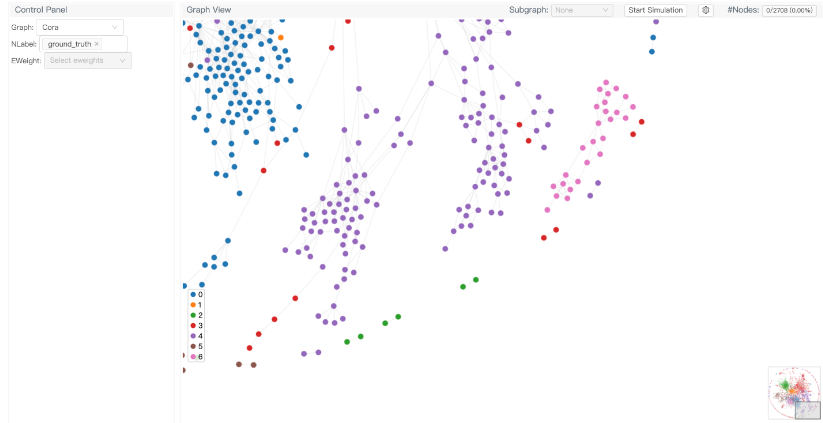
Cora 데이터셋을 불러올때, 노드의 특징벡터를 정규화해서 불러온다.
L2 정규화는 특징 벡터가 서로 다른 스케일을 가지는 문제를 해결하는 데 유용합니다. 이를 통해 모델이 다양한 범위의 입력값을 쉽게 학습할 수 있게 되며, 특히 다음과 같은 장점을 가집니다:수렴 속도 향상: 정규화된 특징을 사용하면 모델이 더 안정적으로 학습할 수 있고

GNN 레이어는 몇개를 쌓을까?
일반적인 구조는 2-3개첫번째 레이어는 각 노드의 이웃 노드의 정보를 통합하여 노드의 임베딩을 학습두번째 레이어는 더 벌리 있는 도드들 간의 관계를 학습하는데 도움을 줌더 쌓지 않는 이유오버스무딩 문제over smoothing : GNN이 너무 많은 레이어를 쌓았을 때
