Multimodal LLM 전반적인 내용 정리
Contents
GIT
Evaluation
-
https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2
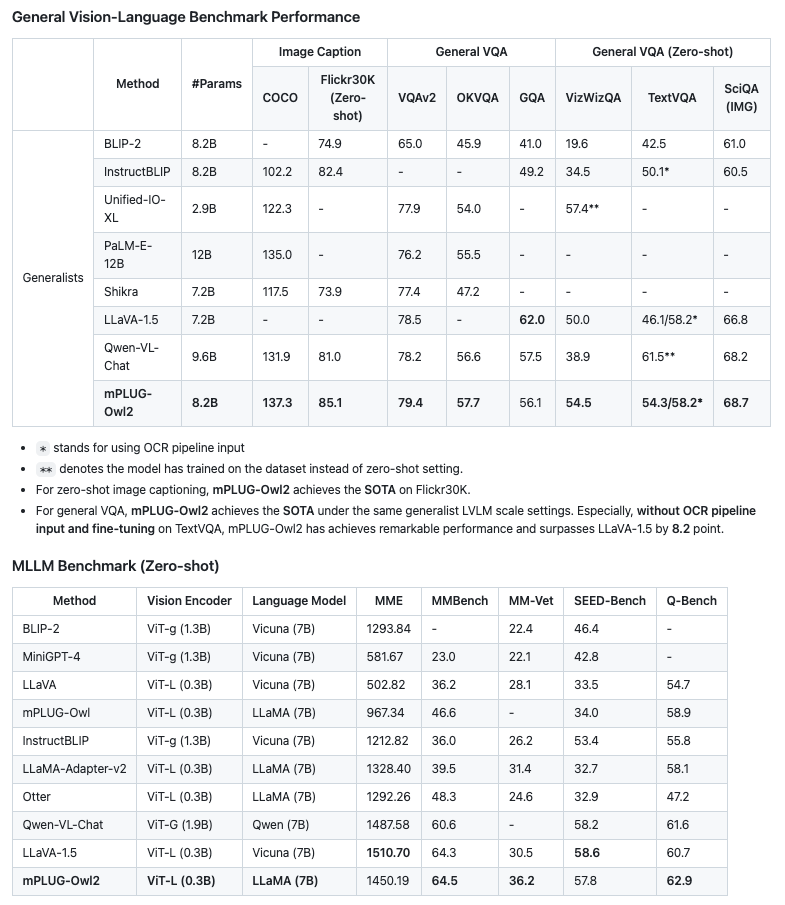
-
LLaMA-VID paper 사진:
주로 저런 N각형 평가를 하는 듯 함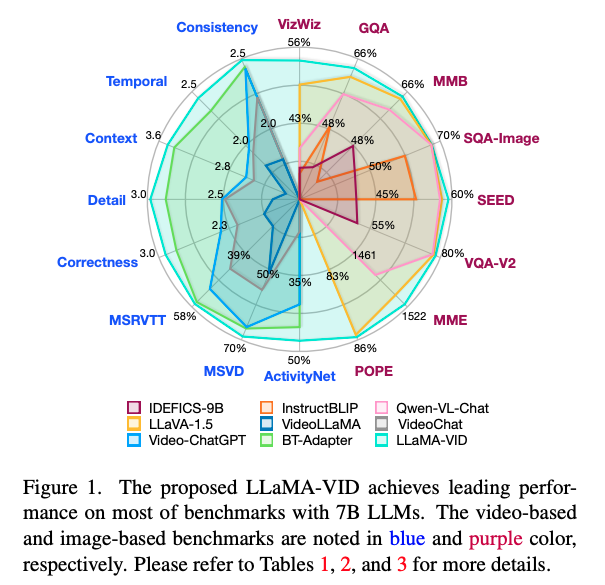
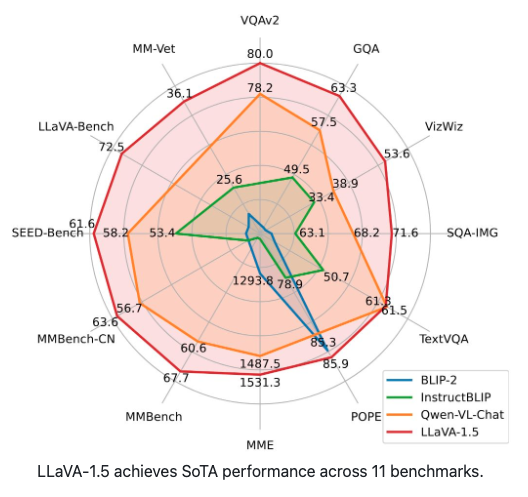
Paper 한줄 요약
Instruction Tuning
DOLPHINS: MULTIMODAL LANGUAGE MODEL FOR DRIVING| arxiv 2312
University of Wisconsin-Madison, NVIDIA, University of Michigan, Stanford University
→ OpenFlamingo 모델에 Grounded Chain of Thought 거쳐서 driving-specific data로 instruction tuning 함.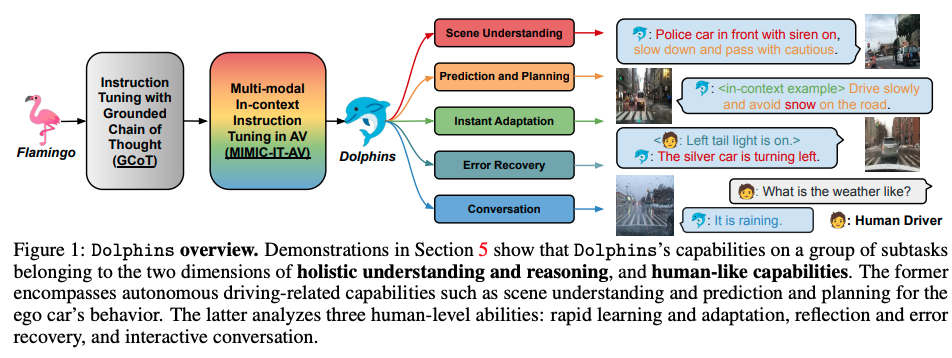
LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models| arxiv 2311
→ 특정 시간 t에서의 text-guided context token과 visual 정보가 많은 content token이 합쳐져 linear projector를 통과해 특정 시간 t의 token을 나타내고 이를 LLM으로 통과시킴.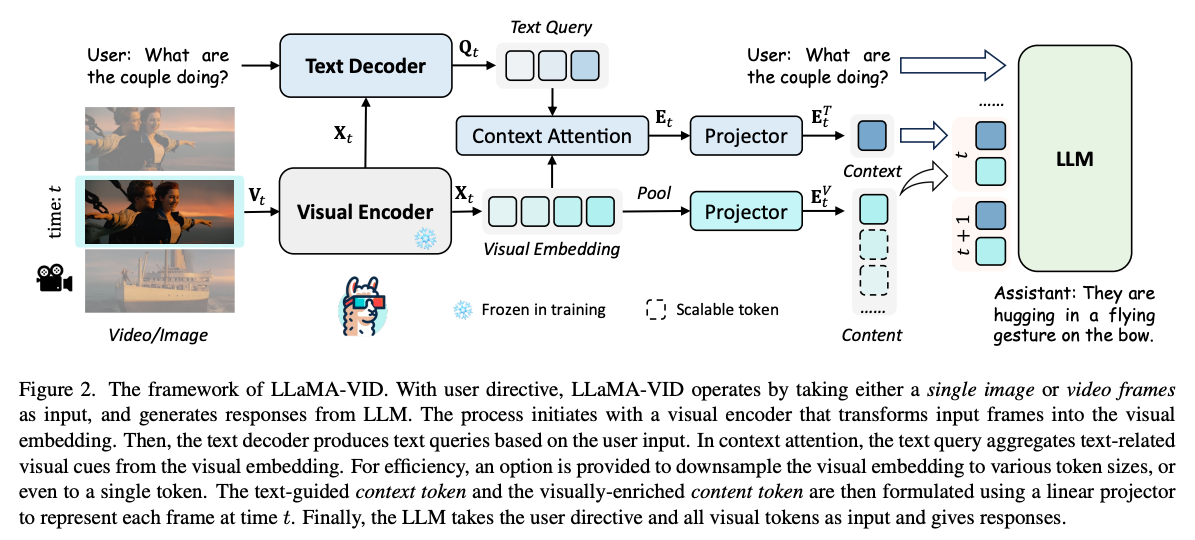
-
LLAVA-PLUS: LEARNING TO USE TOOLS FOR CREATING MULTIMODAL AGENTS| arxiv 2311 | git
Work performed during an internship at Microsoft
→ multimodal instruction-following data로 학습 -
mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration| arxiv 2311 | git -
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions| arxiv 2311 | git
→ GPT4-V로부터 얻어진 100K high-quality caption을 1.2M개로 확장시킨 SharGPT4V data를 가지고 SFT 했더니 잘 동작함.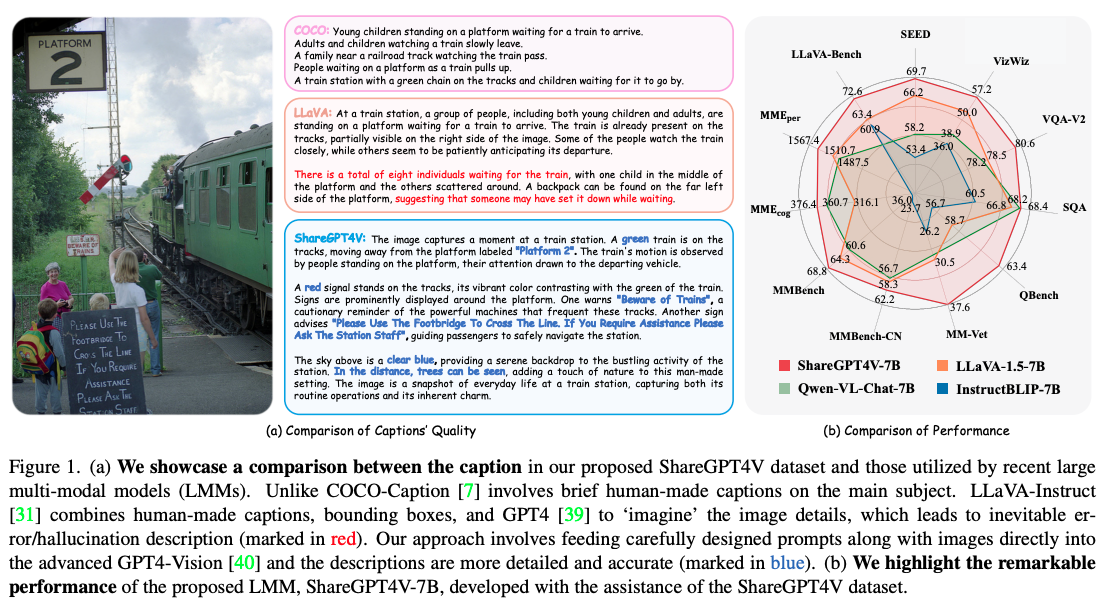
Multimodal Chain-of-Thought
DDCoT: Duty-Distinct Chain-of-Thought Prompting for Multimodal Reasoning in Language Models| arxiv 2310 | proj
→ general multimodal rationales를 생성하기 위한 CoT 진행.
LLM-Aided Visual Reasoning
-
LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing| arxiv 2311 | git | Microsoft
→ multimodal humain-AI interaction을 위한 research prototype으로 visual chatLLaVA+ image segmentationSEEM+ image generation/editingGLIGEN으로 구성 -
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning | arxiv 2309
