- 오차역전파가 은닉층의 가중치를 실제로 update시키는 것을 확인하고자 함
- 데이터셋: 광석, 일반 암석에 수중 음파 탐지기를 쏜 후 결과를 모음
- 모델: 음파 탐지기의 수신 결과만을 보고 광적과 일반 암석을 구분하는 모델
import pandas as pd
!git clone https://github.com.taehojo/data.git
df = pd.read_csv('./data/sonar3.csv', header=None)
df.head()
- 60번째 열이 광물의 종류를 나타내므로, 일반 암석과 광물이 몇개인지를 각각 알아보기 위해서는
df[60].value_counts()해야 함 value_counts()는 선택된 열의 각 카테고리별 원소의 개수를 출력한다.

- 1 ~ 60번째 열을 X변수에, 광물의 종류는 y로 저장하기
# iloc는 [행, 열] 형태로 데이터에 접근함.
X = df.iloc[:, 0:60] # [:, 0:60]은 [모든 행, 0부터 59까지의 열]을 뜻함
y = df.iloc[:, 60] #[:, 60]은 [모든 행, 60번째 열]을 뜻함. - 이제 모델을 만들어보자.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, y, epochs=200, batch_size=10)batch_size: 한번에 학습할 데이터 뭉치. 일반적으로 32, 64, 128 등의 값을 많이 사용한다고 함input_dim: 입력 데이터의 특성의 개수 (여기에서는.head()로 출력해봤을 때 봤던 0부터 59까지 60개의 특성이 있으므로 60으로 설정함)

- 결과를 보니 정확도가 100%! 정말 모든 예측을 완벽히 실행하는 모델을 만들어낸 것일까?
과적합(overfitting)
- 정의: 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않는 것을 의미함
- 원인: 층이 너무 많음, 변수가 너무 복잡함, 테스트셋과 학습셋이 중복됨 등등...
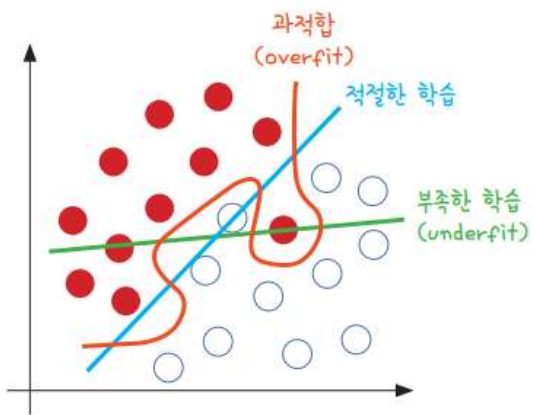
그래프의 빨간 선을 보면, 주어진 샘플에만 너무 최적화되어있어서 새로운 데이터에 적용하면 정확한 분류가 어려워짐
학습셋과 테스트셋 (train set, test set)
- 과적합을 방지하기 위해 취할 수 있는 하나의 방법임
- 데이터셋, 테스트셋을 완전히 구분하고 학습과 동시에 테스트를 병행하며 진행함

- 70개의 샘플로 학습을 진행한 후 이 학습의 결과를 저장한 것이 모델이고, 모델을 다른 셋에 적용할 경우 학습단계에서 각인되었던 그대로 다시 수행함.
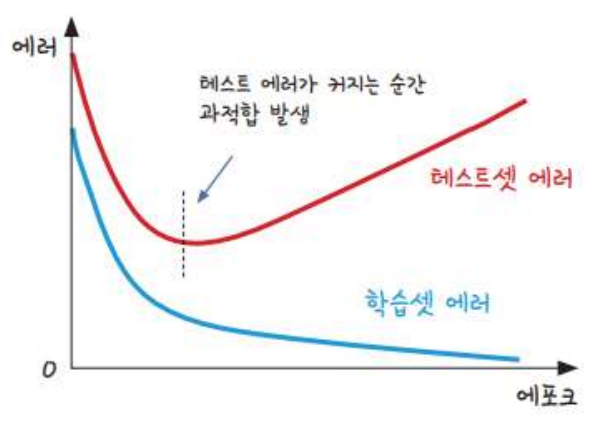
test set으로 실험해서 정확도를 살펴보며 학습이 얼마나 잘 되었는지를 체크할 수 있음.test set의 필요성:test set없이는 학습이 얼마나 진행되었는지만을 파악할 수 있음. 이 경우 새로운 데이터에 적용했을 때 어느정도의 성능이 나올지는 알 수 없음.- epoch를 멈추어야 하는 경우: 학습셋만 가지고 평가하며 층을 더하거나 epoch값을 높여 실행횟수를 늘리면 정확도가 계속해서 올라갈 수는 있음. 그러나 이 정확도가 테스트셋에서도 그대로 나타나지는 않음(과적합). 이 때는 학습을 멈추어야 하며, 이 때의 학습 정도가 가장 적절함
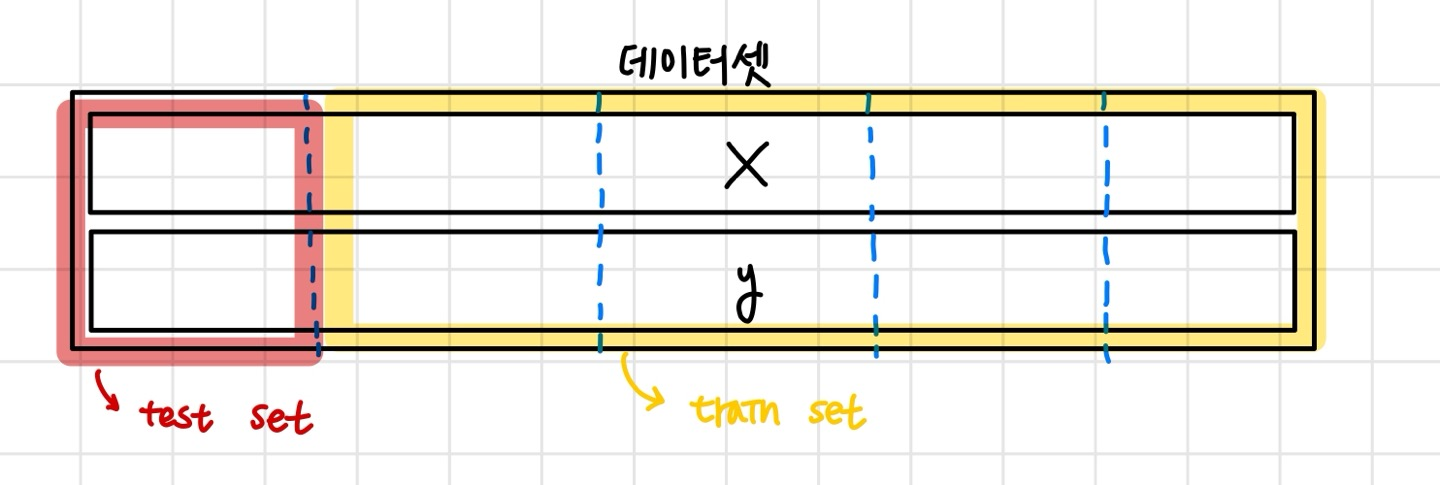
테스트셋, 학습셋 분류하기
!pip install sklearn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, shuffle=True)
# test_size가 테스트셋의 크기(30%)를 의미함. 나머지 70%는 학습셋임.
score = model.evaluate(X_test, y_test) # model.evaluate 함수는 loss, accuracy 두가지를 저장함.
print('Test accuracy:', score[1]) # 그 중 두번째(인덱스로는 1)인 accuracy를 출력함
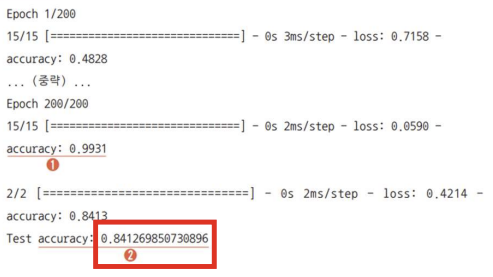
- 첫번째는 train set 정확도, 두번째거는 test set 정확도
성능 개선 방법
- 데이터 추가 (best!)
- 데이터 증강(이미지를 적절히 수정해서 새로운 데이터인 것처럼 사용)
- sigmoid 함수를 이용해 전체를 0 ~ 1 사이의 값으로 변환
- 데이터에 더 적합한 모델로 변경하기
모델 저장, 재사용
# 저장할 위치/모델이름.hdf5 형식으로 적음
model.save('./data/model/my_model.hdf5')
# 테스트를 위해 모델 삭제하기
del model
# 다시 불러오기
from tensorflow.keras.models import Sequential, load_model
model = load_model('./data/model/my_model.hdf5') - 불러온 모델을 이전의 테스트셋에 적용해보면 정확히 같은 정확도가 나옴을 확인할 수 있음.
K겹 교차 검증(K-fold cross validation)
- 데이터셋을 여러개로 나누어 하나씩 테스트셋으로 사용하고, 그 하나를 제외한 나머지를 모두 합쳐서 학습셋으로 사용하는 방법

- 이 때, 그림에서처럼 다섯등분하는 대상은 X랑 y 둘 다임.
from sklearn.model_selection import KFold
k = 5 # 전체 데이터셋을 다섯개로 나눔
kfold = KFold(n_splits = k, shuffle = True) # 데이터들이 어느 한 쪽으로 치우치지 않도록 shuffle을 True로 설정해서 고르게 나뉘게 해줌
acc_score = [] # 정확도를 기록할 배열을 하나 만듦
for train_index, test_index in kfold.split(X):
X_train, X_test = X.iloc[train_index, :], X.iloc[test_index, :]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
accuracy = model.evaluate(X_test, y_test)[1] # 정확도 구하기
acc_score.append(accuracy) # 미리 만들어둔 리스트에 저장하기
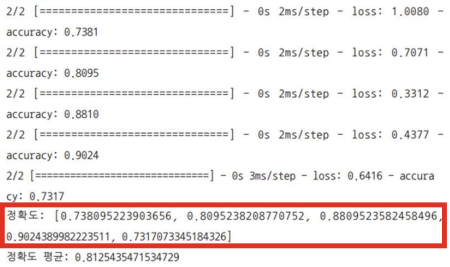
이 때, train set / test set 과 X / y를 헷갈리면 안됨 (사실 내가 헷갈렸어서 정리함) ⭐
- X는 어떤 물체임을 판단하는데에 영향을 미칠 수 있다고 판단하는 다양한 특징들에 대한 정보임. 예를 들어, 강아지 고양이 분류 문제에서는 귀모양, 코모양, 색 등등이 있을 것임. 폐암수술 이후 생존자와 사망자 분류 문제에서는 환자의 흡연여부, 성별, 나이 등등이 있을 것임.
- y는 답안지임. 예를 들어 강아지 고양이 분류 문제에서는 강아지면 0, 고양이면 1, 폐암수술 이후 생존자와 사망자 분류 문제에서는 생존자 0 사망자 1 이런 식으로 정답을 담고 있음. 이 때 튤립, 개나리, 백합 중 어떤 꽃인지 예측하기 문제처럼 y의 분류가 3가지 이상이면 다중분류에 속하며, 이를 숫자로 나타내기 위해 one-hot encoding을 활용함.
- train set과 test set은 X, y를 각각 70:30 정도의 비율로 나눠서 각각 학습을 진행시켜가며 예측값과 정답(y)을 비교하며 정확도를 계산한다.
- train set과 test set의 정확도를 비교하면 학습을 언제 중단해야 할 지 (최적의 epoch), 과적합이 일어나고 있지는 않은지를 확인할 수 있으므로 나눠서 진행함.
- 이 때, 모델이 적절한 epoch를 스스로 판단하도록 할 수는 없을까...? (다음장)
