
Grid Search 를 이용한 하이퍼파라미터튜닝 자동화
- 가장 좋은 성능을 내는 최적의 하이퍼파라미터를 찾는 방법
- 종류
-
Grid Search 방식
sklearn.model_selection.**GridSearchCV**
- 가능한 모든 하이퍼파라미터 조합을 시도하여 최적의 조합을 찾는 방법
- 장점 : 작은 하이퍼파라미터 공간이거나 탐색해야 할 조합의 수가 적을 때 유용
- 단점 : 하이퍼파라미터 탐색 공간이 커질수록 계산 비용이 크게 증가할 수 있음
- Initializer 매개변수
-estimator: 사용할 머신러닝 모델을 지정
-param_grid: 그리드 서치로 탐색할 하이퍼파라미터 조합을 지정
-cv: 교차 검증을 위한 폴드 수를 지정
-scoring: 모델의 성능을 평가하는 지표를 선택
-n_jobs: 병렬 처리를 위한 CPU 코어 수를 지정
- 메소드
-fit(X, y): 학습
-predict(X): 분류-추론한 class. 회귀-추론한 값
-predict_proba(X): 분류문제에서 class별 확률을 반환
- 그리드 서치 결과 조회
-best_params_: 최적의 하이퍼파라미터 조합을 출력
-best_score_: 최고의 성능 지표 값을 출력
-best_estimator_: 가장 좋은 성능을 낸 모델을 반환
-cv_results_: 그리드 서치의 세부 결과를 데이터프레임 형태로 제공
-
Random Search 방식
sklearn.model_selection.**RandomizedSearchCV**- 하이퍼파라미터 탐색 공간에서 무작위로 조합을 선택하여 탐색하는 방법
- 탐색해야 할 조합의 수가 많거나 하이퍼파라미터의 중요도가 확실하지 않을 때 유용
- 장점 : 그리드 서치보다 계산 비용이 낮고, 하이퍼파라미터 탐색 공간의 크기와 관계없이 탐색이 가능
- 단점 : 최적의 조합을 보장하지는 않으며, 탐색 효율이 그리드 서치보다 낮을 수 있음
-
파이프라인 (Pipeline)
- 머신러닝 작업에서 데이터 전처리, 특성 추출, 모델 학습 등의 단계를 연속적으로 연결하여 효율적으로 처리할 수 있는 방법
- 작업의 흐름을 자동화하고 일련의 단계를 순차적으로 실행하여 중간 결과를 전달하는 기능
- 하나의 흐름으로 묶어주어 코드의 재사용성과 실행의 효율성을 높일 수 있음
- 모델 저장 => Pipeline을 저장
import pickle with open('pipeline_bc.pkl', 'wb') as fw: pickle.dump(pl, fw)
- Pipeline 생성
- (이름, 변환기) 를 리스트로 묶어서 전달
- Pipeline 을 이용한 학습
pipeline.fit()- 각 변환기의 fit_transform()이 순차적으로 실행되고, 결과가 다음 단계로 전달됩니다.
- 마지막 단계가 추정기(모델)일 경우, 마지막 단계의 fit()만 호출합니다.
- 이를 사용하여 파이프라인의 모든 단계를 학습 데이터에 적용하여 모델을 학습합니다.
pipeline.fit_transform()- fit()과 동일한 역할을 수행하지만, 마지막 단계에서도 fit_transform()이 실행됩니다.
- 주로 전처리 작업 파이프라인(모든 단계가 변환기)일 때 사용됩니다.
- 모든 단계의 fit_transform()이 순차적으로 실행되고, 최종 변환된 결과가 반환됩니다.
- 마지막이 추정기(모델) 일 경우
- 추정기(모델)을 이용하여 입력 데이터 X에 대한 결과를 예측합니다.
- 모델 앞에 있는 변환기들을 이용하여 입력 데이터를 변환(transform)한 후, 변환된 데이터를 추정기로 전달하여 예측 결과를 반환합니다.
- predict() 메서드는 클래스 레이블을 반환하며, predict_proba() 메서드는 각 클래스에 속할 확률을 반환합니다.
GridSearch에서 Pipeline 사용
💡 프로세스이름__하이퍼파라미터 형식으로 지정
- Pipeline 생성
- GridSearchCV의 estimator에 pipeline 등록
- 차원 축소
- feature selection : 남길 컬럼과 제거할 컬럼을 선택
- feature extraction : 계산을 통해서 feature 개수를 줄임
from sklearn.decomposition import PCA #차원 축소 -> feature를 줄여준다.
pca = PCA(n_components=2) # feature를 몇개로 줄일지 -> feature extraction 방식
X_trained_pca = pca.fit_transform(X_train)# GridSearchCV생성
# key: 하이퍼파라미터 이름 (파이프라인에등록한이름__하이퍼파라미터이름)
# value: 후보-리스트
params = {
"pca__n_components":[5, 10, 15, 20, 25],
"svm__C":[0.001, 0.01, 0.1, 0.5, 1],
"svm__gamma":[0.001, 0.01, 0.1, 0.5, 1]
}
gs = GridSearchCV(pl2, # 모델->pipeline
params,
scoring='accuracy',
cv=4,
n_jobs=-1
)
gs.fit(X_train, y_train)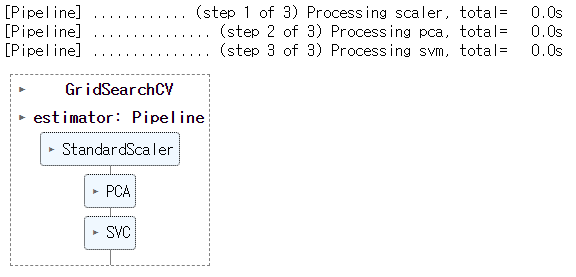
ColumnTransformer
: 하나의 데이터셋을 구성하는 feature들(컬럼들) 마다 다른 전처리를 해야 하는 경우 사용
- 수치형 컬럼의 경우 스케일링을 적용하고, 범주형 컬럼의 경우 원-핫 인코딩을 적용해야 할 수 있음
- 환 작업은 주로 scikit-learn의 변환기(Transformer) 객체로 구성되며, 각 변환 작업은 이름, 변환기, 적용할 컬럼으로 구성된 튜플로 정의됨
- 장점 :
- 다양한 열 유형에 맞게 각각 다른 전처리 작업을 적용할 수 있습니다.
- 변환 작업과 해당 열을 매핑하여 한 번에 여러 열을 처리할 수 있습니다.
- 전처리 과정을 단일 객체로 관리하여 코드의 가독성과 재사용성을 향상시킵니다.
sklearn.compose.ColumnTransformer
- 변환기(transformer)와 변환할 열(columns)을 매핑하는 방식으로 사용
- 변환 작업(Transformer)과 해당 열을 매핑하여 전처리 과정 정의
- 각 변환 작업은 이름, 변환기, 적용할 열로 구성된 튜플 형태로 정의
- fit_transform() 메서드를 사용하여 전처리 수행
- transformer : list of tuple - (name, transformer, columns)로 구성된 tuple들을 리스트로 묶어 전달
- remainder='drop' : 지정한지 않은 컬럼을 어떻게 처리할지 여부 (제거가 디폴트값)
sklearn.compose.make_column_transformer
- 좀 더 간편하게 ColumnTransformer를 생성하는 함수
- 각 변환 작업과 해당 열을 인수로 전달하여 ColumnTransformer 생성
- make_column_transformer 함수는 ColumnTransformer 객체 반환
- fit_transform() 메서드를 사용하여 전처리를 수행
