Machine Learning
1.머신러닝, Iris 분석

머신러닝 개요 > 머신러닝 모델 > 알고리즘 : X * n 학습 : n을 찾기 → 내 data(input/output)에 맞춘다. ⇒ 최적의 n을 찾는 알고리즘이 필요 → 최적화 → scikit-learn 모델 = 데이터의 패턴을 수식화 한 함수 데이터를 학습
2.데이터셋 나누기와 모델 검증

train, val → training set / test → test setTrain 데이터셋 (훈련/학습 데이터셋)Validation 데이터셋 (검증 데이터셋) → 하는 중간에 확인Test 데이터셋 (평가 데이터셋) → 마지막에 모델의 성능을 측정하는 용도(한번만
3.데이터 전처리

결측치 처리 제거 (열단위, 행단위) : 관련있는 값들 모두 제거, 행단위가 기본 다른 값으로 대체 가장 가능성 높은 값으로 대체 : 수치형, 범주형 … 결측치 자체를 대체 결측치 제거 결측치인지 여부 확인 dataframe.isnull() ,
4.평가지표
분류(Classification) 평가 지표 다중 분류(Multi class classification) 이진 분류(Binary classification) 양성(Positive): 찾으려는 대상. 보통 1로 표현 음성(Neg
5.과적합 / 일반화

Generalization (일반화)모델이 학습한 패턴과 특징을 이용하여 새로운 데이터에 대한 예측을 수행하는 능력학습 데이터에만 너무 치중되지 않고, 새로운 데이터에도 적용할 수 있는 능력모델이 훈련 데이터셋으로 평가한 결과와 테스트(검증) 데이터셋을로 평가한 결과의
6.그리드서치 / 파이프라인

Grid Search 를 이용한 하이퍼파라미터튜닝 자동화 가장 좋은 성능을 내는 최적의 하이퍼파라미터를 찾는 방법 종류 Grid Search 방식 sklearn.model_selection.GridSearchCV 가능한 모든 하이퍼
7.지도학습 - SVM / KNN
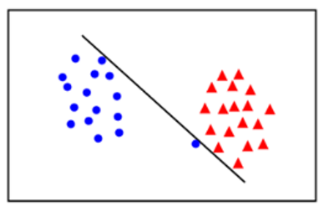
분류를 하기 위한 경계선(결정선)을 찾는 것두 클래스 간의 거리(마진)를 가장 넓게 분리 할 수 있는 경계선이 최적의 분류 선SVM 목표: support vector간의 가장 넓은 margin을 가지는 결정 경계를 찾기Support Vector: 경계를 찾는데 기준(지
8.의사결정나무 / 랜덤포레스트
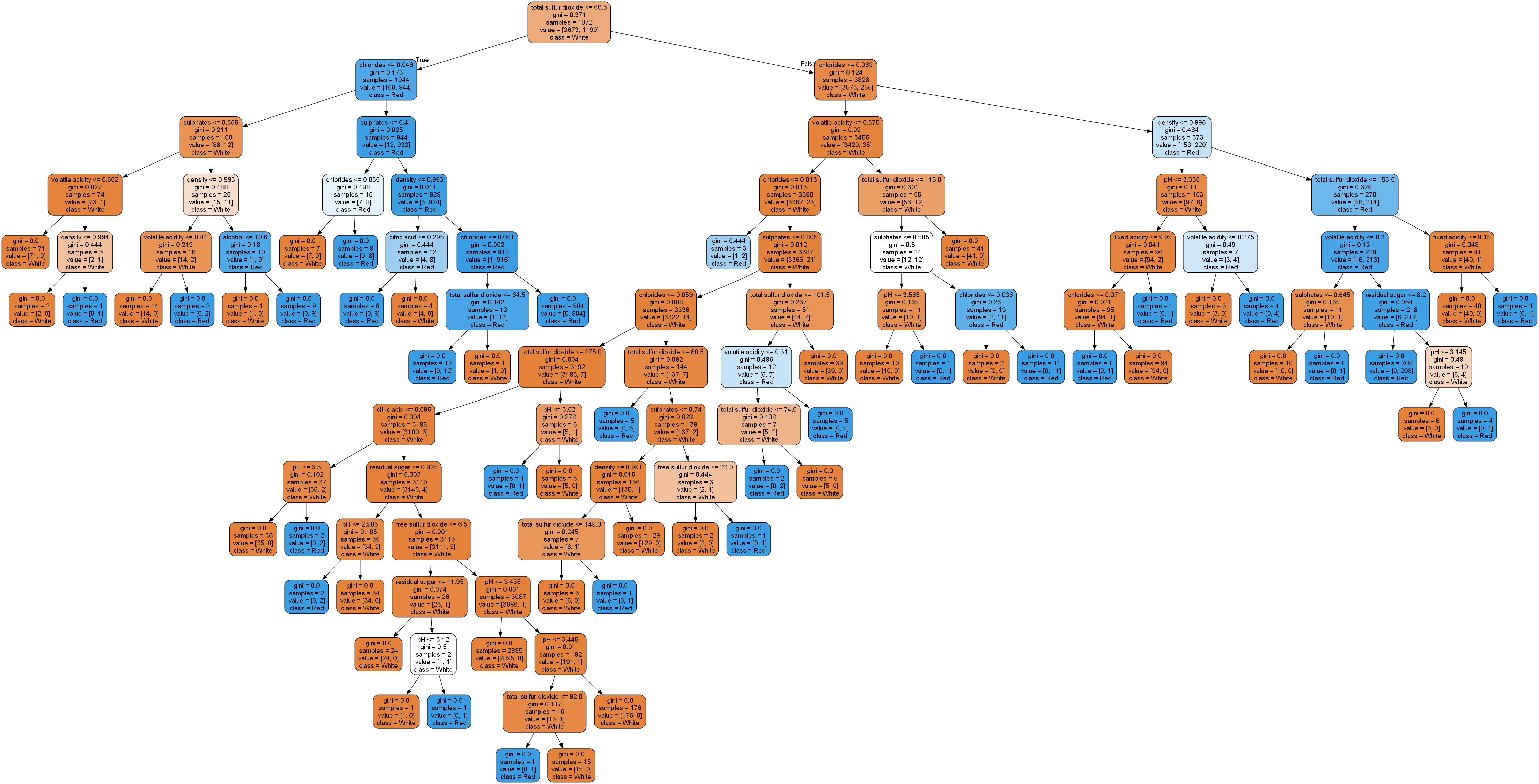
추론 결과를 위해 분기하는 구조가 이진트리(Tree) 구조와 같음분기 기준분류 : 가장 불순도(서로 다른 종류class의 값들이 섞여있는 비율)를 낮출 수 있는 조건회귀 : 가장 오차가 적은 조건, MSE가 가장 낮은 방향White box 모델로 추론 결과에 대한 해석
9.앙상블 - 부스팅(Boosting) / 보팅(Voting)

앙상블 부스팅(Boosting) 협업하는 모델 여러 개별 모델(약한 학습기)을 결합하여 보다 강력하고 정확한 예측 모델(강한 학습기)을 구축 → 약한 학습기들은 앞 학습기가 만든 오류를 줄이는 방향으로 학습 개별 모델들은 성능이 안좋은 모델을 사용해야함,
10.선형회귀 / 로지스틱 회귀 / 경사하강법

선형회귀 입력 변수(또는 특성)와 출력 변수(또는 타깃) 간의 선형적인 관계를 가정 각 Feature들에 가중치(Weight)를 곱하고 편향(bias)를 더해 예측 결과를 출력 모델 - 추론하는 과정은 같음 / 최적화하는 방법만 다른 것 (w를 찾는 과정)