
선형회귀
-
입력 변수(또는 특성)와 출력 변수(또는 타깃) 간의 선형적인 관계를 가정
-
각 Feature들에 가중치(Weight)를 곱하고 편향(bias)를 더해 예측 결과를 출력
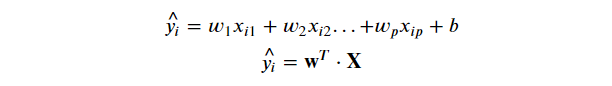
-
모델 - 추론하는 과정은 같음 / 최적화하는 방법만 다른 것 (w를 찾는 과정)
- LinearRegression
- Ridge Regression (L2 규제)
- Lasso(Least Absolut Shrinkage and Selection Operator) Regression (L1 규제)
LinearRegression
-
가장 기본적인 선형 회귀 모델
-
주어진 훈련 데이터를 기반으로 최적의 회귀 계수를 찾는 최소 제곱법(Least Squares)을 사용
-
각 Feauture에 가중합으로 Y값을 추론
-
데이터 전처리
- 범주형 Feature : One Hot Encoding
- 연속형 Feature
- Feature Scaling : 각 컬럼들의 값의 단위를 맞춰줌
- StandardScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # Train set으로 학습 + 변환
X_test_scaled = scaler.transform(X_test) # Test set : train set으로 학습한 scaler 이용해 변환-
weight조회 : 각 feature들에 곱할 가중치들
lr.coef_→
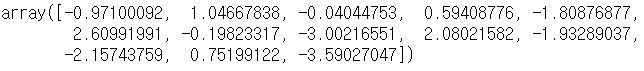
💡 Coeficient의 부호
- 양수: Feature가 1 증가할때 y(집값)도 weight만큼 증가**
- 음수: Feature가 1 증가할때 y(집값)도 weight만큼 감소
- 0에 가까울 수록 y값에 영향을 주지 않고 크면 클수록(0에서 멀어질 수록) y값에 영향을 많이 주는 Feature
-
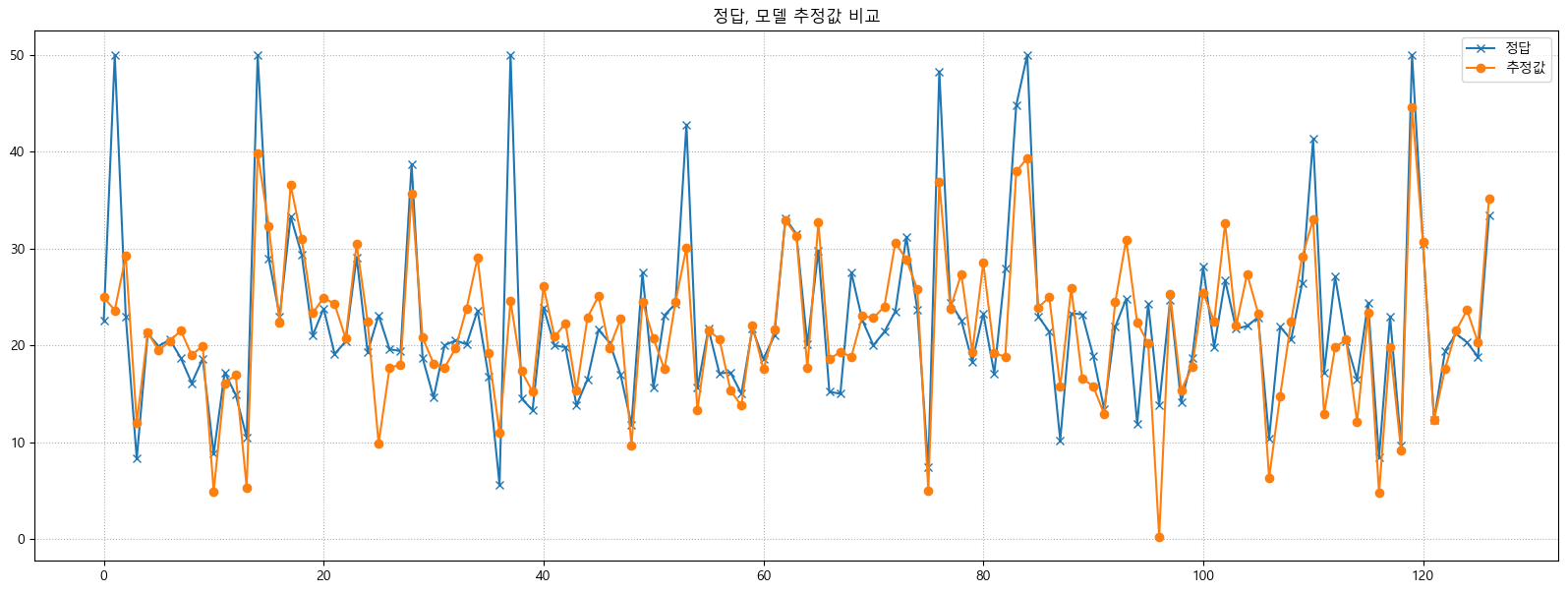
추론 : Train dataset에 대한 선형회귀 추정결과 모델을 이용해 추론
pred_train = lr.predict(X_train_scaled) -
정답, 모델 추정값 간의 차이를 비교
규제(Regularization)
- 모델의 복잡도를 제어하여 과적합을 방지하고, 일반화(generalization) 성능을 향상
- Feature들에 곱해지는 가중치가 커지지 않도록 제한 (0에 가까운 값으로 만들어 줌)
Ridge Regression (L2 규제)
from sklearn.linear_model import Ridge
-
가중치의 크기를 제한하여 가중치의 값이 커지지 않도록 함
→ 모델의 복잡도를 낮추고 모든 특성이 예측에 조금씩 기여
-
모든 특성을 포함하는 모델을 유지하면서 일반화 성능을 개선
-
손실함수(Loss Function)
- 모델의 예측한 값과 실제값 사이의 차이를 정의하는 함수로 모델이 학습할 때 사용
-
손실을 크게 만들어 줌
→ 손실 함수에 가중치의 크기를 나타내는 L2 norm의 제곱을 추가하여 적용
→ 가중치의 크기가 커지는 것을 제한함으로써 모델의 복잡도를 낮추는 역할
→ 노이즈에 민감한 모델을 줄이는 효과
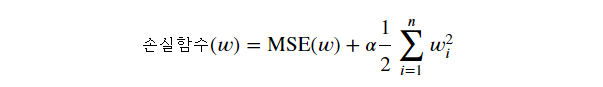
- 규제강도(𝛼)=0 에 가까울수록 규제가 약해짐 (0일 경우 LinearRegression)
- 𝛼 가 커질 수록 모든 가중치가 작아져(0에 가깝게됨) 입력데이터의 Feature들 중 중요하지 않은 Feature의 예측에 대한 영향력이 작아짐
alpha = 1
ridge = Ridge(alpha=alpha, random_state=0) # alpha : 규제강도, default : 1
ridge.fit(X_train_scaled, y_train)
print_metrics_regression(y_train, ridge.predict(X_train_scaled))
print("=========================")
print_metrics_regression(y_test, ridge.predict(X_test_scaled))Lasso Regression (L1 규제)
from sklearn.linear_model import Lasso
- 모델의 가중치를 0으로 향하도록 하여 모델의 특성 선택(feature selection) 진행
- 일부 특성의 영향력을 줄여 덜 중요한 특성을 제거하는 효과
- 변수 선택이 중요한 경우나 특성이 많은 데이터셋에서 유용
- 손실 함수에 가중치의 절대값의 합 더함 → 가중치의 크기에 대한 패널티를 부과하며, 가중치가 작아지도록 유도 → 절대값을 사용 ⇒ 가중치가 0이 되는 특성
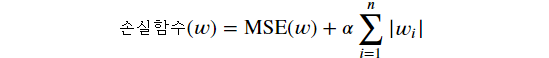
💡 정리
- 일반적으로 선형회귀의 경우 어느정도 규제가 있는 경우가 성능이 좋음
- 기본적으로 Ridge 사용
- Target에 영향을 주는 Feature가 몇 개뿐일 경우 특성의 가중치를 0으로 만들어 주는 Lasso 사용
로지스틱 회귀 (LogisticRegression)
- 입력 변수와 이진 혹은 다중 클래스 사이의 관계를 모델링하며, 각 클래스에 속할 확률을 추정
확률 추정
- 입력 특성(Feature)에 가중치 합을 계산한 값(선형회귀)을 로지스틱 함수를 적용
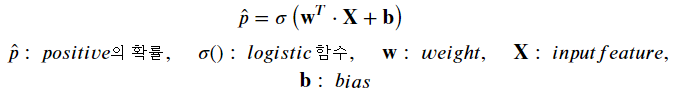
- 로지스틱 함수
-
0과 1사이의 실수를 반환
-
시그모이드 함수(sigmoid function)
-
logistic 함수 시각화
import matplotlib.pyplot as plt import numpy as np def logistic_func(X): return 1 / (1 + np.exp(-X)) X = np.linspace(-10, 10, 1000) y = logistic_func(X)plt.figure(figsize=(13, 6)) plt.plot(X, y, color='b', linewidth=2) plt.axhline(y=0.5, color='r', linestyle=':') # 빨간색 점선 그려주는 것 # plt.axvline(x=5, color='b', linestyle=':') plt.ylim(-0.15, 1.15) plt.yticks(np.arange(-0.1,1.2,0.1)) # y축 눈금 설정 # spine : 그래프 박스선 # set_position : 위치를 정해줌 , left - y축, bottom - x축 ax = plt.gca() ax.spines['left'].set_position("center") # spine 중앙에 위치 ax.spines['bottom'].set_position(('data', 0.0)) # spine 위치를 data=0.0에 맞춤 # ax.spines['bottom'].set_color('blue') # spine 색깔 지정 # 필요없는 spine 지우기 ax.spines['top'].set_visible(False) # 위쪽 spine 안보이게 ax.spines['right'].set_visible(False) # 오른쪽 spine 안보이게 plt.show()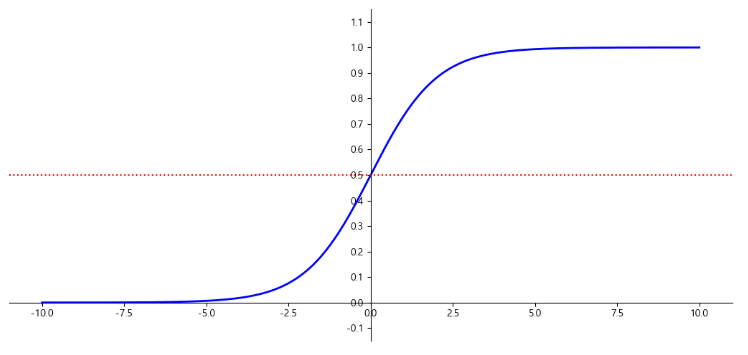
-
LogisticRegression의 손실 함수(Loss Function)
-
Log loss (로그 손실 함수)
-
log(모델이 예측한 정답에 대한 확률) -
실제 클래스 레이블이 1인 경우 : y=1인 경우의 로그 확률(p)에 음의 로그를 취한 값을 계산
-
실제 클래스 레이블이 0인 경우 : y=0인 경우의 로그 확률(1-p)에 음의 로그를 취한 값을 계산
-
손실 값이 낮을수록 모델의 성능이 좋다고 판단
-
다중분류 또는 이진분류에 따라 log loss를 만드는 공식이 다름
- Cross Entropy (크로스 엔트로피 손실)
-
다중분류에 대한 log loss 공식
-
소프트맥스 활성화 함수와 함께 사용
-
모델의 예측 확률과 실제 클래스 레이블 간의 차이를 평가
-
손실 값이 낮을수록 모델의 성능이 좋다고 판단
-
실제 클래스 레이블과 해당 클래스에 대한 로그 확률의 곱을 모든 클래스에 대해 합산한 값
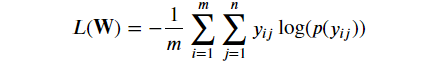
-
- Binary Cross Entropy(이진 크로스 엔트로피)
-
이진분류 추론 결과에 대한 cross entropy 계산
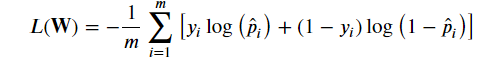
-
- Cross Entropy (크로스 엔트로피 손실)
-
LogisticRegression의 최적화
- 모델이 예측한 결과와 정답간의 차이(오차)를 가장 적게 만드는 Parameter를 찾는 과정
- 분류 문제이므로 Cross entropy(Log loss함수)를 손실함수로 사용
- Cross entropy는 loss의 최소값으로 하는 parameter 찾는 방정식이 없기 때문에 LogisticRegression은 경사하강법을 이용해 최적화를 진행
- LogisticRegression 주요 하이퍼파라미터
penalty: 과적합을 줄이기 위한 규제방식- 'l1', 'l2'(기본값), 'elasticnet', 'none'
C: 규제강도(기본값 1) - 작을 수록 규제가 강하다(단순).max_iter: (기본값 100) - 경사하강법 반복횟수
- 데이터 전처리
- 연속형 Feature - Feature scaling
- 범주형 Feature - One hot encoding
최적화 - 경사하강법
- 최적화 (Optimize)
- 모델의 성능을 최대화하거나 손실을 최소화하기 위해 모델의 매개변수를 조정하는 과정
- 훈련 데이터로부터 모델을 학습하는 과정에서 매개변수의 값을 조정하여 손실 함수를 최소화하거나 성능 지표를 최대화하는 방향
- 주어진 문제에 대해 최적의 솔루션을 찾는 과정
- 최적화 문제
- f(w) : 손실함수
- 손실함수에 어떤 w(파라미터)를 전달했을 때 손실이 가장 적을까를 찾는 것 → 최적화
- 손실함수(Loss Function) = 비용함수(Cost Function), 목적함수(Object Function), 오차함수(Error Function)
-
평가 함수와는 다름
-
모델의 성능을 측정하고 최적화하는 데 사용되는 함수
-
모델이 예측한 값과 실제 값 사이의 차이를 계산하여 모델의 예측 오차를 나타냄
-
목적 : 최적화 과정에서 손실 함수를 최소화하는 방향으로 모델의 매개변수를 조정하고 개선하는 것
Classification(분류) - cross entropy
Regression(회귀) - MSE(Mean Squared Error)
-
- 최적화 문제 해결 방법
- Loss 함수 최적화 함수를 찾는다. - 한번에 찾는거
- Loss를 최소화하는 weight들을 찾는 함수(공식)을 찾는다.
- Feature와 sample 수가 많아 질 수록 계산량이 급증
- 최적화 함수가 없는 Loss함수도 있다.
- 경사하강법 (Gradient Descent) - 조금씩 조금씩
- 손실 함수의 기울기(그레이디언트)를 계산하여 기울기가 감소하는 방향으로 매개변수를 업데이트하는 방법
- Loss 함수 최적화 함수를 찾는다. - 한번에 찾는거
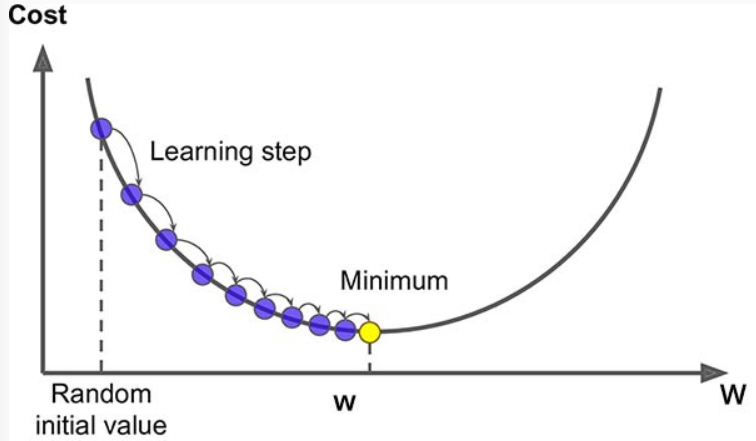
경사하강법 (Gradient Descent)
-
다양한 종류의 문제에서 최적의 해법을 찾을 수 있는 일반적인 최적화 알고리즘
-
손실함수를 최소화하는 파라미터를 찾기위해 반복해서 조정
-
파라미터 벡터 W에 대해 손실함수의 현재 gradient(기울기) 계산
-
gradient가 감소하는 방향으로 벡터 W 조정, 0이 될 때 까지 반복
-
gradient - 양수 : loss와 weight가 비례 관계, loss를 더 작게 하려면 weight가 작아져야 함
-
gradient - 음수 : loss와 weight가 반비례 관계, loss를 더 작게 하려면 weight가 커져야 함
-
-
최적의 매개변수 값을 찾음
- 초기화: 매개변수를 임의의 초기 값으로 설정합니다. 예를 들어, 선형 회귀 모델의 경우 가중치(w)와 편향(b)을 무작위로 초기화합니다.
- 예측과 손실 계산: 현재 매개변수 값을 사용하여 모델을 통해 예측을 수행하고, 예측 값과 실제 값 간의 손실을 계산합니다. 손실 함수는 모델의 성능을 측정하는 지표로, 일반적으로 평균 제곱 오차(Mean Squared Error, MSE)를 사용합니다.
- 기울기(그레이디언트) 계산: 손실 함수를 매개변수로 편미분하여 각 매개변수에 대한 기울기를 계산합니다. 기울기는 손실 함수의 변화량을 나타내며, 매개변수의 조정 방향과 크기를 결정합니다.
- 매개변수 업데이트: 계산된 기울기를 사용하여 매개변수를 업데이트합니다. 업데이트는 기존 매개변수에서 학습률(learning rate)을 곱한 값만큼 조정됩니다. 학습률은 매개변수 업데이트의 속도를 조절하는 하이퍼파라미터로, 작은 값은 안정적인 수렴을 보장하지만 느리게 수렴할 수 있고, 큰 값은 빠른 수렴을 위해 사용되지만 수렴하지 않을 수 있습니다.
- 종료 조건 확인: 수렴을 확인하고 종료 조건을 만족하면 알고리즘을 중단합니다. 종료 조건은 일정한 반복 횟수나 손실 값의 변화량이 미미한 경우 등으로 설정될 수 있습니다.
-
파라미터 조정 - 학습률 (Learning rate)
- 기울기에 따라 이동할 step의 크기
- lr 작게 잡으면 - 최소값에 수렴하기 위해 많은 반복을 진행해야해 시간이 오래걸림
- lr 크게 잡으면 - 큰 값으로 발산하여 최소값에 수렴하지 못하게됨
