
앙상블 부스팅(Boosting)
- 협업하는 모델
- 여러 개별 모델(약한 학습기)을 결합하여 보다 강력하고 정확한 예측 모델(강한 학습기)을 구축 → 약한 학습기들은 앞 학습기가 만든 오류를 줄이는 방향으로 학습
- 개별 모델들은 성능이 안좋은 모델을 사용해야함, 성능이 좋은 모델을 쓰면 overfitting 발생
GradientBoosting
from sklearn.ensemble import GradientBoostingClassifier- 대용량 정형 데이터에 많이 사용
- 손실 함수(Loss Function)를 최소화하기 위해 경사 하강법(Gradient Descent)을 사용하여 모델을 학습
- 개별모델 - Decision Tree
- 단점 : 훈련시간이 많이 걸리고, 트리기반 모델의 특성상 희소한 고차원 데이터에서는 성능이 안 좋음
- 예측
- 평균으로 예측
- Residual(잔차)을 계산 - 정답과 평균으로 예측한 결과 차이
-
평균으로 추정 → 오차(잔차) 학습
-
앞모델까지 예측한 값 + 학습율(lr) * 잔차 학습값
→ 잔차를 그대로 더하면 overfitting 발생 가능
→ lr 쓰는 이유 = 약한 학습기 쓰는 이유
- 주요 파라미터
- Decision Tree 의 가지치기 관련 매개변수
learning rate: 기본값 0.1, 값이 크면 복잡한 모델 → overfitting 가능n_estimators: decision tree의 개수, 많을 수록 복잡한 모델, 최대한 크게n_iter_no_change,validation_fraction: 훈련 조기종료- 보통 max_depth를 낮춰 개별 decision tree의 복잡도를 낮춤 ( 최대5, 보통 2-3)
위스콘신 유방암 데이터
-
learning rate 변화에 따른 성능변화
-
lr = 0.0001 → 과소적합 발생

⇒ 과소적합 해결 방법 : n_estimators를 증가시키기

-
lr = 0.01
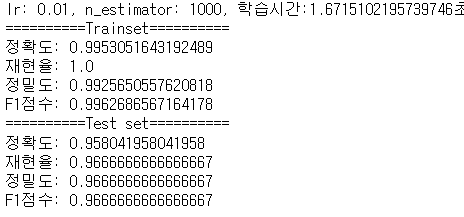
-
lr = 0.1

-
💡 lr를 먼저 조정하는 것 보다, 모델을 미리 많이 만들어 놓고(n_estimators 최대한 크게) lr 조절하는 것이 좋음
XGBoost(Extream Gradient Boost)
-
Gradient Boost 업그레이드 버전
-
Gradient Boost 알고리즘을 기반으로 개선해서 분산환경에서도 실행할 수 있도록 구현 나온 모델
-
설치
-
conda install -y -c anaconda py-xgboost -
pip install xgboost

-
-
개발 방법
-
Scikit-learn 래퍼 XGBoost
from xgboost import XGBClassifier, XGBRegressor- 매개변수
learning_rate: 학습률, 보통 0.01 ~ 0.2 사이의 값 사용n_estimators: week tree 개수- Decision Tree관련 하이퍼파라미터들
앙상블 보팅(Voting)
- 서로 다른 모델을 결합하여 다수결 방식으로 최종 결과를 출력
- 각 모델은 독립적으로 학습되고 예측을 수행
- 장점 : 예측 성능 향상, 과적합 방지, 모델의 안정성 향상
분류
- 비슷한 성능을 내면서 서로 다른 예측하는 것이 많은 모델들을 묶어줄 때 성능이 올라감
- 일반적으로 soft voting 성능이 더 좋음
- hard voting
- 이진분류 - 다수결 방식으로 선택하여 최종 예측을 수행
- 다중 분류 - 최빈값을 선택하거나 빈도가 가장 높은 클래스 선택
- soft voting
- 예측 결과의 확률을 평균하여 가장 높은 확률을 가지는 클래스를 최종 예측으로 선택
VotingClassifier 클래스 이용
estimatorsvoting: 기본값 - “hard”
#각 모델의 Hyper parameter는 최적의 성능을 내도록 튜닝한 값들 이라는 가정
#Voting 앙상블 모델에 추가하는 모델들은 가장 좋은 성능을 내는 hyper parameter를 가진(튜닝이 끝난) 모델을 사용
knn = Pipeline(steps=[('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_neighbors=5))])
svm = Pipeline(steps=[("scaler", StandardScaler()),
("svm", SVC(random_state=0, probability=True))])
rfc = RandomForestClassifier(n_estimators=200, max_depth=3, random_state=0)
xgb = XGBClassifier(n_estimators=500, learning_rate=0.01, max_depth=1, random_state=0)모델들간의 상관관계
-
상관관계가 높은 모델을 앙상블 보팅에 포함시키는 것은 좋지 않음
→ 상관관계가 높음 = 두 모델이 비슷한 예측을 하는 것 → 의미 없음
⇒ 각각 좋은 성능을 내지만 다른 예측을 하는 다양한 모델을 모아서 하는 것이 좋음
# 상관계수
df.corr()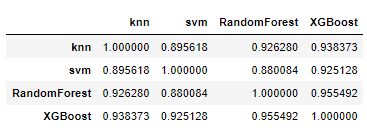
💡 상관계수가 낮은 것 끼리 묶어준다
개별 모델의 성능이 가장 좋은 모델을 기준으로 상관관계(corr)값이 가장 낮은 것을 묶어준다.
# Ordered Dictionary 형태로 묶어준다.
estimators = [
("svm", svm),
("knn", knn),
("random forest", rfc)
]회귀
- 각모델이 값을 추론하면 그 값들의 평균으로 최종 결과를 사용
estimators: 앙상블할 모델들 설정. ("추정기이름", 추정기) 의 튜플을 리스트로 묶어서 전달
