데이터를 labeling하는 작업은 매우 expensive한 작업입니다. 이번에는 Unsupervised Learning으로 데이터를 Clustering하는 방법에 대해 알아보고자 합니다.
Partitional Clustering
(ex) K-means algorithm
하나의 데이터 포인트는 무조건 하나의 클러스터에만 속하게 됩니다. (= non-overlapping subsets으로 분류됨)
K-means Clustering
- 랜덤하게 각 cluster의 중심을 정한다.
- 데이터를 가장 가까운 cluster로 배정한다.
- 같은 cluster 멤버들의 평균점으로 cluster의 중심을 재할당한다.
- cluster의 중심이 수렴할 때까지 이 과정을 반복한다.
1번에서 어떻게 cluster의 중심을 초기화하느냐에 따라 성능이 좌지우지된다는 것이 이 알고리즘의 단점입니다. 또한, cluster의 density/size/globular shape에 있어서도 robust하지 않은 단점이 있습니다.
Hierarchical Clustering
tree 구조의 cluster로 구성되어 계층적인 구조를 가지게 됩니다.
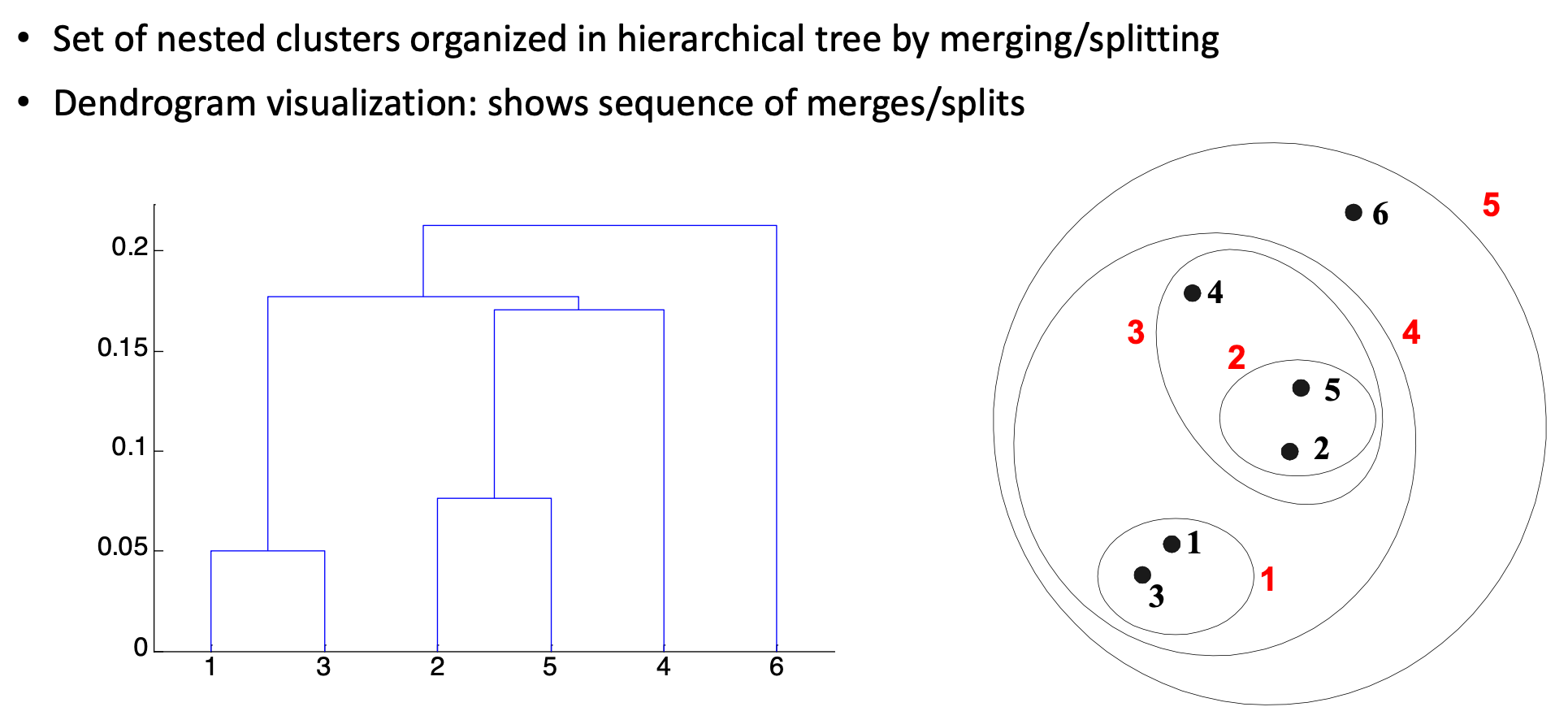
Q: How to Measure Inter-ClusterDistance?
A: Agglomerative Clustering에서 merge하기 위해 distance를 구할 때,
1. minimum distance를 이용하면 아웃라이어에 sensitive하다는 단점이 있지만, 타원형이 아닌 shape도 handle 가능하다는 장점이 있습니다.
2. maximum distance를 이용하면 상대적으로 아웃라이어에 덜 sensitive하다는 장점이 있지만, large cluster를 잘려진 형태로 도출하는 경향이 있습니다.
3. Group average
4. distance between centroids
