Cross-Validation을 이용한 모델 평가
data set을 training data와 test data로 나눈 다음, test data를 이용하여 모델 평가를 하곤 합니다. 하지만 test data가 유난히 training data와 유사하거나 유사하지 않았다면 모델의 성능이 유난히 높거나 낮게 평가될 가능성이 있습니다. 이러한 의존도를 낮추기 위한 방법이 바로 Cross-Validation을 이용한 방법입니다.
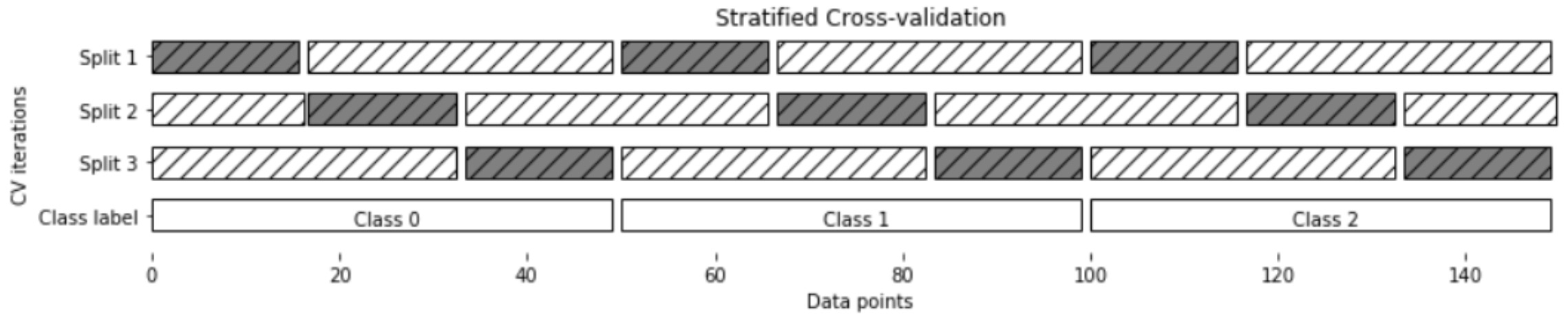
예를 들어 k-fold cross validation이라면 training data를 k로 나눈 다음, for i 1 to k에 대해 iteration을 돌면서 i번째 data set을 test data로, 나머지를 training data로 선택하여 test error와 training error를 계산합니다. 이후 최종 평가를 test data로 진행합니다.

k가 커지면 data set을 매우 잘게 쪼개서 test를 반복하게 되므로 모델에 대한 generalized error를 찾을 수 있고 overfit 여부를 잘 확인할 수 있습니다.
Q: How to Partition Data?
한 partition에 들어가는 data의 class 분포도 균일하도록 합니다.
Naive Bayes
input feature와 각각의 class가 있을 때, input feature와 class사이의 연관 확률을 계산한 모델을 만들어놓고 그 모델에 따라서 특정 input feature 조합에서 확률이 가장 높은 class를 찾아 prediction하는 것이 Naive Bayes 알고리즘입니다.

좀 더 수학적으로 Bayes' Theorem을 이용하여 정리하면, 특정 features가 주어졌을 때 Ci일 확률을 계산하고, 이러한 조건부 확률이 제일 큰 Ci로 prediction하는 알고리즘입니다.
Naive Bayes 알고리즘에서는 input feature들은 Class에 대해 conditionally independent이라고 가정합니다. 독립적일 경우, joint probability 로 계산할 수 있습니다. 따라서 계산하면 다음과 같습니다.

Gaussian Naive Bayes
연속적인 값을 가지는 feature에 대해 적용할 수 있습니다.
조건에 해당하는 해당 feature의 값들에 대해 mean와 standard deviation를 구하고, 아래의 식에 대입하여 를 구합니다.
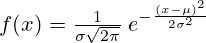
(cf) standard deviation
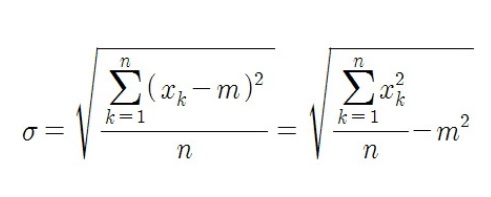
Support Vector Machine
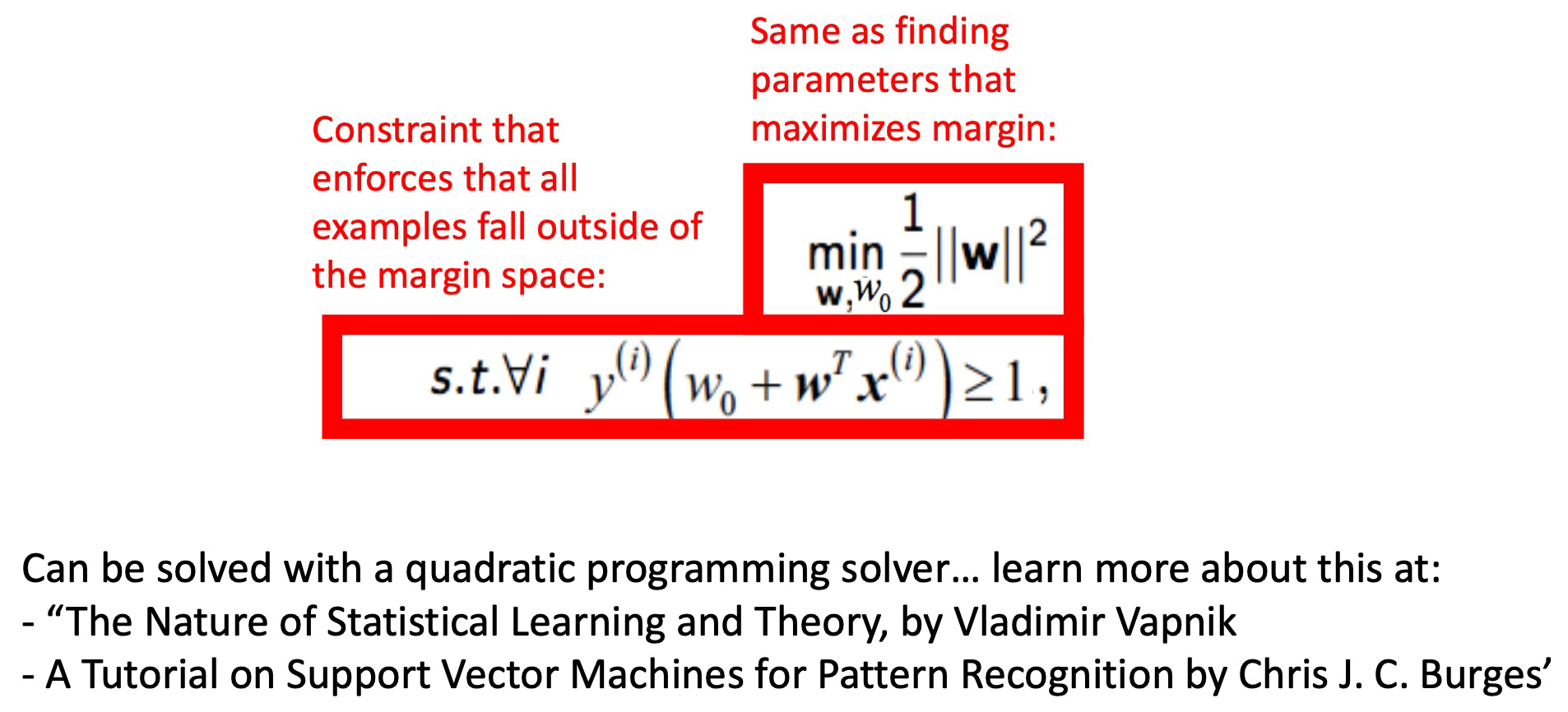
margin width를 최대화하는 hyperplane을 찾는 알고리즘입니다. 아웃라이어에 민감하지 않고, prediction이 매우 빠르고 사용하는 메모리가 적으며 high-dimensional data에서 잘 동작한다는 장점이 있습니다.
반면에 데이터셋이 커질수록 계산량이 커지며, non-linear classification을 하기 위해서는 soft-margin value에 굉장히 민감하다는 단점이 있습니다. 또한 엄밀한 확률적인 분석은 어렵다는 단점이 있습니다.
Hard-Margin Classification은 Linearly separable할 때 데이터간의 margin width를 최대화하는 방식이라면, Soft-Margin Classification은 Non-Linearly separable할 때 예외처리를 하고 margin width를 최대화하는 방식입니다.
Soft-Margin Classification
slack variable을 추가로 도입하여 w와 slack variable을 동시에 최적화하는 문제로 만든 것이 soft-margin classification 문제입니다.
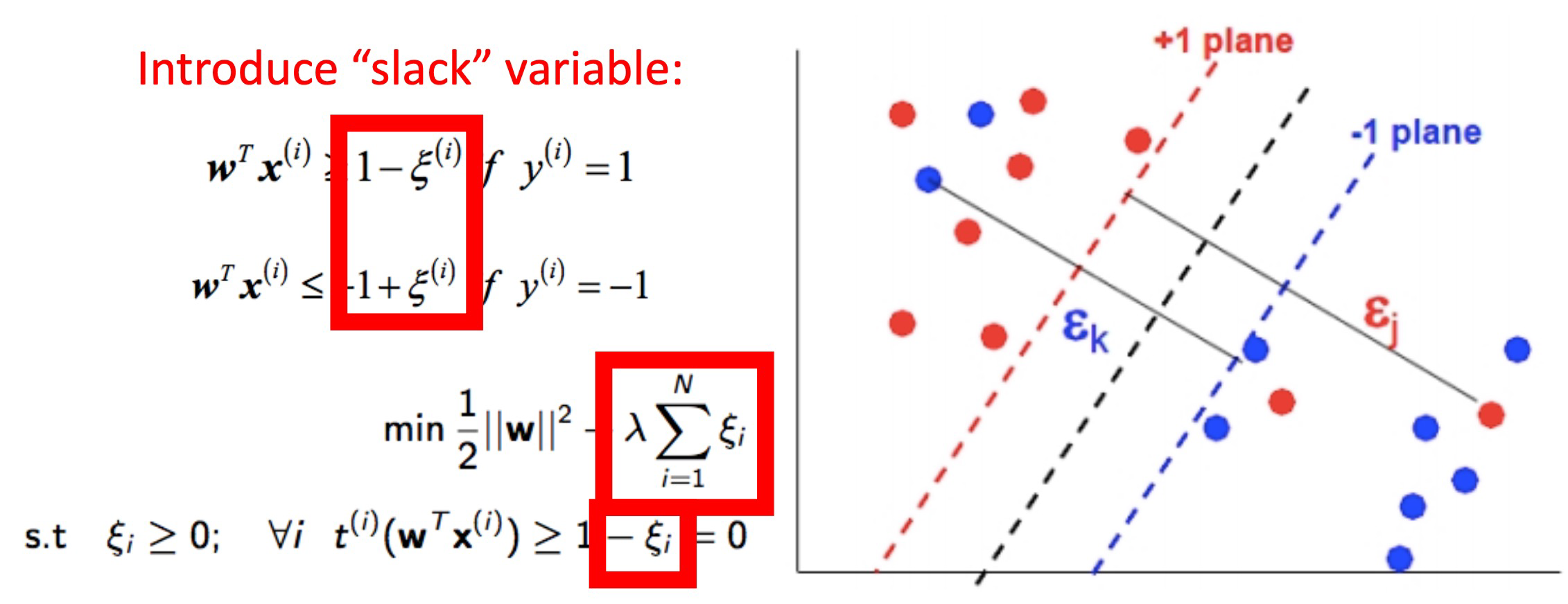
Q: 완전히 non-linearly separable한 경우는?
A: Kernelized SVM을 사용할 수 있습니다. 이는 데이터를 linearly separable한 공간으로 맵핑하고 separable한 hyperplane을 찾은 다음에 역함수를 통과시켜 분류하는 방법입니다.

