인공지능 이론 정리
1.Feature Matching and Fitting
RANSAC (RANdom SAmple Consensus) is a learning technique to estimate parameters of a model by random sampling of observed data.The Algorithm is as f
2.Loss Function and Optimization
How can we tell whether weight of a linear classifier W is good or bad? To quantify a "good" W, loss function is needed.Starting with random W and fin
3.[인공지능] Gradient Descent 알고리즘 이해하기
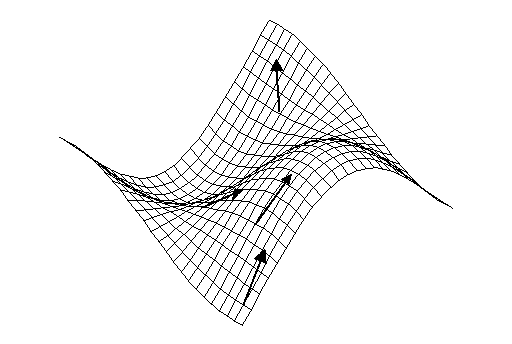
$$∇{A}f(A) = \\begin{bmatrix}{{əf(A)}\\over{əA{11}}} {{əf(A)}\\over{əA{12}}} ...{{əf(A)}\\over{əA{1m}}}\\{{əf(A)}\\over{əA{21}}} {{əf(A)}\\over{əA{22}
4.[인공지능] 딥러닝 이해하기

딥러닝과 다른 머신러닝의 차이, 그리고 딥러닝의 장점이 무엇인지 헷갈리는 경우가 많습니다. 다른 learning method 소개와 더불어 딥러닝이 강력한 이유에 대해 소개하도록 하겠습니다. Neural Network 신경망이라는 뜻입니다. 모델의 학습과정은 모델의
5.[인공지능] Convolutional Neural Network (CNN) 이해하기
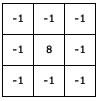
CNN은 너무 유명한 DNN 모델입니다. 아래의 그림은 CNN의 대표적인 모델 AlexNet의 아키텍처인데요, AlexNet을 통해 CNN을 소개하도록 하겠습니다. 구조를 보면, 먼저 Feature extraction 부분에서는 CONV layer + ReLU를 n번
6.[기계학습] Introduction to Machine Learning
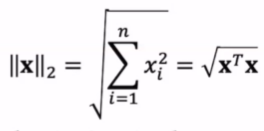
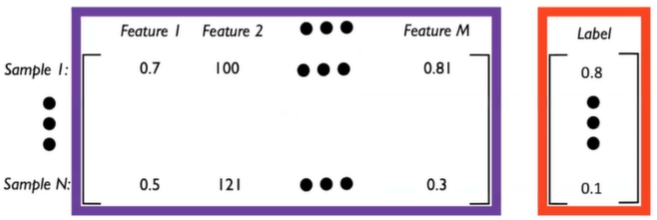
Machine Learning은 최종 모델이 예측을 위해 사용할 데이터 패턴으로부터 학습하는 알고리즘입니다. 사용하는 데이터의 타입은 Audio, Image, Video, Text 등이 있을 수 있고, 혹은 Multi-modal 데이터를 통해 여러 타입을 복합적으로 사
7.[기계학습] Supervised Learning - Regression
Regression의 목적은 unseen한 example에 대해서 일반화할 수 있는 model을 개발하는 것입니다.Split data into a training set and test set.Train model on training set to try to mini
8.[기계학습] Supervised Learning - Classification: Nearest Neighbor and Decision tree
Classification은 discrete한 value를 prediction하는 것이 목적입니다.Split data into a training set and test set.Train model on training set to try to minimize pred
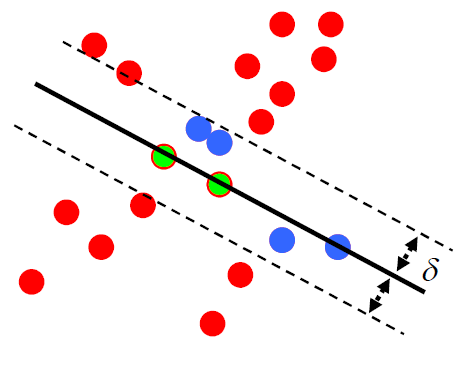
9.[기계학습] Supervised Learning - Classification: Naive Bayes and SVM

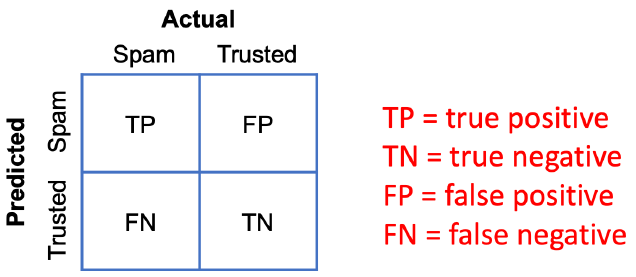
data set을 training data와 test data로 나눈 다음, test data를 이용하여 모델 평가를 하곤 합니다. 하지만 test data가 유난히 training data와 유사하거나 유사하지 않았다면 모델의 성능이 유난히 높거나 낮게 평가될 가능성
10.[기계학습] Unsupervised Learning - Clustering
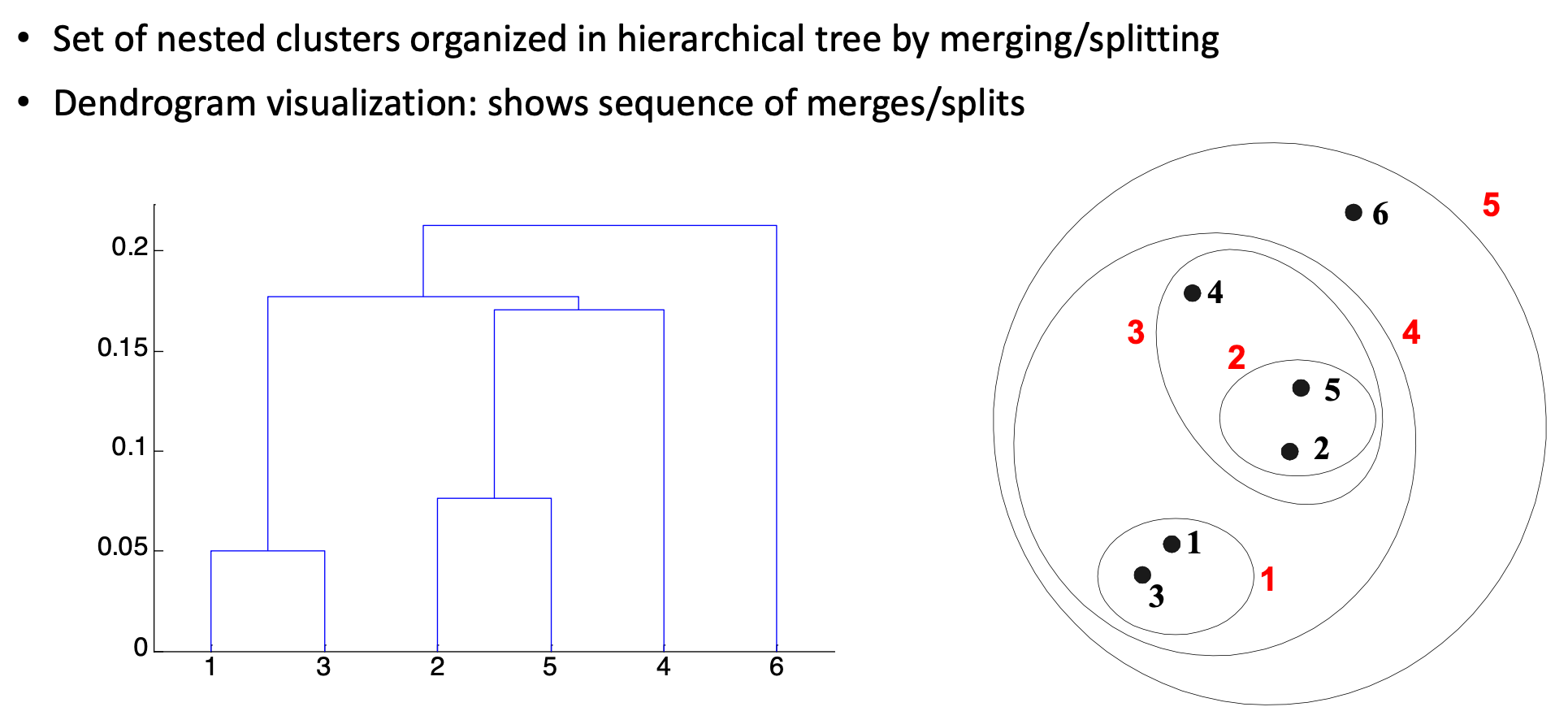
데이터를 labeling하는 작업은 매우 expensive한 작업입니다. 이번에는 Unsupervised Learning으로 데이터를 Clustering하는 방법에 대해 알아보고자 합니다.(ex) K-means algorithm하나의 데이터 포인트는 무조건 하나의 클러