딥러닝과 다른 머신러닝의 차이,
그리고 딥러닝의 장점이 무엇인지 헷갈리는 경우가 많습니다.
다른 learning method 소개와 더불어 딥러닝이 강력한 이유에 대해 소개하도록 하겠습니다.
Neural Network
신경망이라는 뜻입니다. 모델의 학습과정은 모델의 신경망을 학습시키는 과정에 해당합니다.
그림을 보면 동그라미들이 실선으로 연결되어 있습니다.
그리고 동그라미들이 하나의 묶음으로 모여있고, 이 묶음이 여러개 존재합니다.
그림에서 동그라미는 인공 뉴런(= Perceptron), 실선은 시냅스, 시냅스 층은 layer에 해당합니다.
시냅스는 뉴런과 뉴런 사이를 연결하는데요,
시냅스의 강도, 즉 가중치(=)를 조절하여 원하는 값을 출력하도록 모델이 학습됩니다.

Ways to Learn
시냅스를 학습시키는 방법에는 크게 3가지가 있습니다.
Supervised learning
지도학습은 라벨링된 훈련 데이터를 사용하여 모델이 데이터의 패턴과 관계를 이해하도록 합니다. 예를 들어, 이미지 분류 문제에서, 지도학습 모델은 이미지에 레이블링된 카테고리를 학습합니다. 시냅스의 weight는 레이블링된 값과 출력 사이의 차를 줄이는 방향으로 조정되어 최적의 행동을 학습합니다.
Unsupervised learning
비지도학습은 라벨링되지 않은 훈련 데이터를 사용합니다. 따라서 클러스트링 등을 이용해 스스로 데이터를 라벨링한 다음 학습을 진행합니다. 학습 방법은 Supervised learning과 동일합니다.
Reinforcement Learning
강화학습은 보상과 벌점에 기반하여 에이전트가 문제를 해결하도록 합니다. 에이전트는 행동을 취하고 그 결과로 보상을 받거나 벌점을 받습니다. 예를 들어, 게임을 플레이하는 에이전트는 승리하면 보상을 받고 패배하면 벌점을 받습니다. 시냅스의 weight는 보상을 최대화하는 방향으로 조정되어 최적의 행동을 학습합니다.
Deep Learning vs 다른 Machine Learing
그렇다면 전통적인 머신러닝과 딥러닝의 차이는 무엇일까요?
전통적인 머신러닝은 인간이 설계한 알고리즘을 토대로 데이터의 feature를 추출합니다.
feature의 종류는 인간이 결정합니다.
모델은 feature들의 분포를 학습하여, 분포에 대한 Output classifier 함수를 만드는 것입니다.
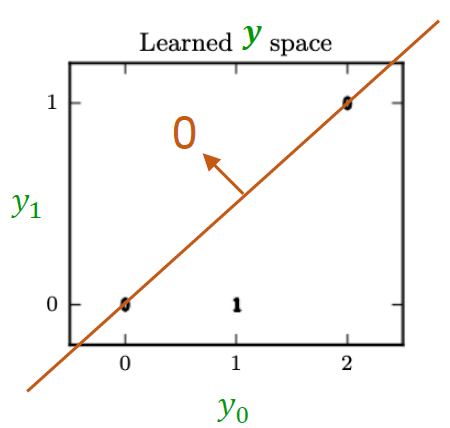
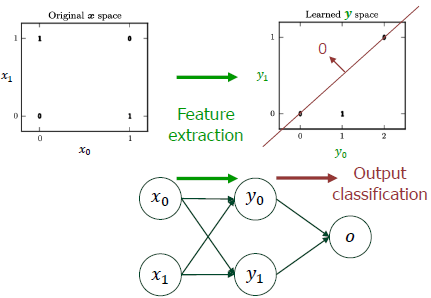
예를 들어 다음과 같은 2차원 space에 feature가 분포되어있다고 가정해보겠습니다.
그림 속 주황색 함수가 바로 output classifier 함수입니다.
함수값보다 작은지 큰지에 따라 데이터의 output이 결정됩니다.
반면에 딥러닝은 feature의 종류를 모델 스스로 결정합니다.
가장 대표적인 딥러닝 모델인 CNN을 예시로 들어보겠습니다.
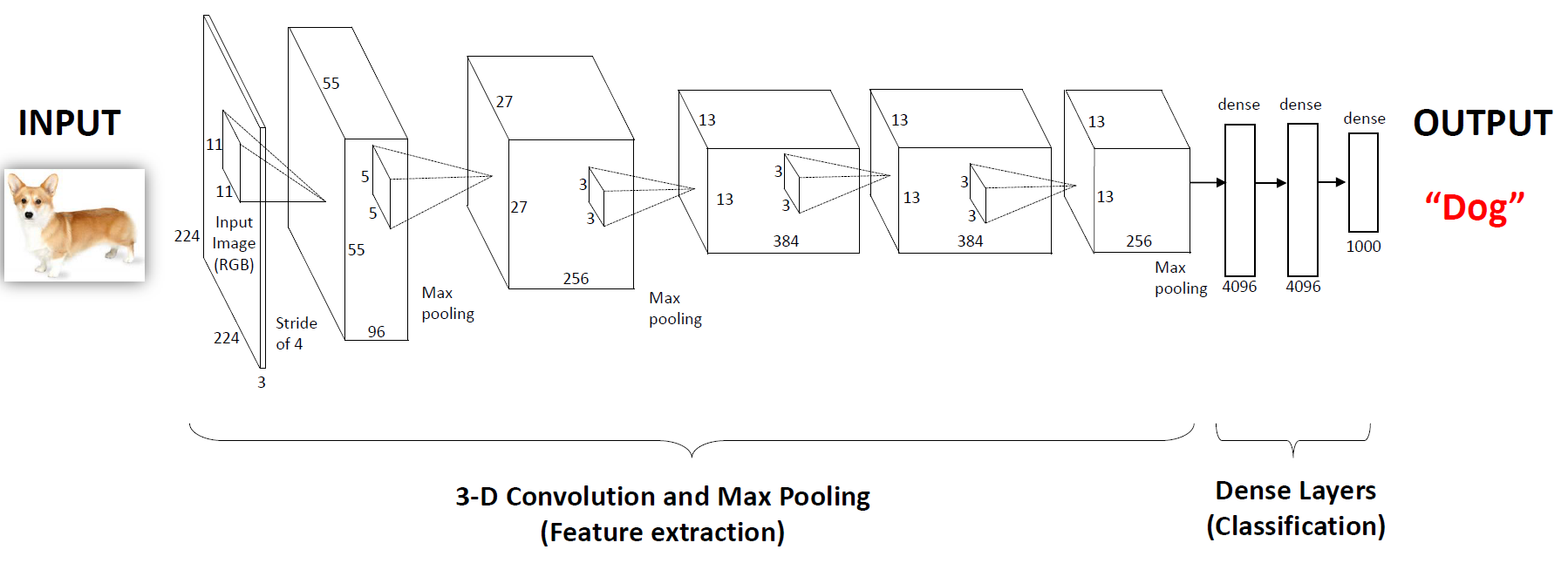
그림을 보면 모델이 Feature extraction 부분과 Classification 부분으로 나눠져 있습니다.
Feature extraction 부분이 바로 deep layer를 거치며 feature를 추출하는 단계이고
Classification 부분이 추출된 feature의 분포를 바탕으로 output을 결정하는 단계입니다.
Classification 부분은 다른 머신러닝 알고리즘과 동일하겠습니다.
이처럼 딥러닝은 feature를 추출하는 단계가 포함된 머신러닝 방법입니다.
Deep Learning 모델의 구조
하나의 인공 뉴런 (One Perceptron)
하나의 인공 뉴런에 대해 예시를 들어보겠습니다.
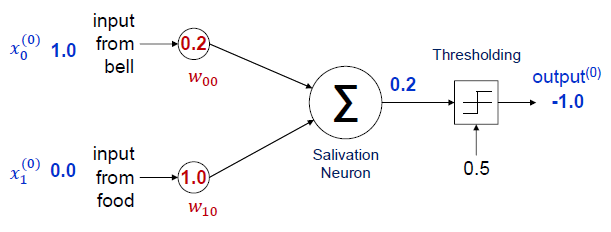
와 은 input 데이터로, Activaton 혹은 feature라고 부릅니다.
이후 을 계산한 다음,
Activation Function에 을 넣어 최종 결과값을 출력합니다.
여기서 는 weight, 는 bias입니다.
weight는 시냅스의 가중치,
bias는 인공 뉴런이 기본적으로 가지고 있던 activation 상수를 의미합니다.
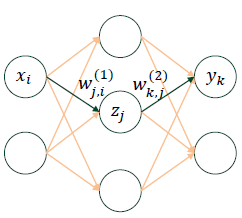
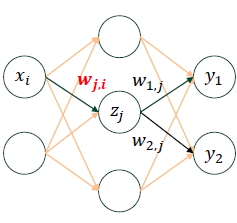
MLP(Multi-Layer Perceptron)
본격적으로 시냅스 층 여러 개를 가지는 딥러닝 모델의 학습을 알아보겠습니다.
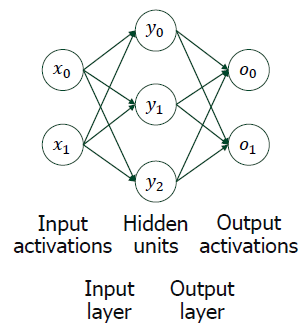
와 은 input activation이고,
그림에서 인공 뉴런(= Perceptron)의 개수는 와 을 제외한 5개입니다.
딥러닝에서 layer라고 부르는 것은 뉴런과 뉴런을 잇는 시냅스 층을 의미합니다.
따라서 그림에서 layer는 2개입니다.
Activation Function이란?
Activation Function의 종류는 다음과 같습니다.

기본적으로 non-linear한 함수들입니다.
Activation Function을 사용하는 이유는 세상에 존재하는 대부분의 문제가
non-linear하기 때문입니다.
Deep learning에서는 수많은 시냅스 층(layer)을 거치며 feature를 추출하는데요,
뉴런과 뉴런 사이를 linear하게 연결하면 feature가 분포하는 space는 동일하게 유지됩니다.
반면에 뉴런과 뉴런 사이를 non-linear하게 연결하면 feature가 새로운 space로 사상됩니다.
즉, space transformation이 발생합니다.
세상에 존재하는 대부분의 문제는 non-linear하기 때문에
linear classifier 함수로 분류할 수 있도록 feature space를 변환해주어야 합니다.
만약 Activation Function이 없다면, 학습을 반복해도 동일한 feature space에 또 다른 linear classifier를 만들 뿐이므로 여러 개의 layer가 무의미해질 것입니다.
따라서 어떻게 공간을 뒤틀어야 feature를 잘 구분할 수 있을지 학습하는 것이 딥러닝이라고 볼 수 있습니다.
아! 문제가 linear하다는 것은 입력 에 대한 출력 가 로 표현되는 것을 의미합니다. 반대로 non-linear하다는 것은 출력 가 에 대한 선형 함수로 표현되지 않는 것을 의미합니다.
모델의 학습
모델의 학습은 Forward 단계와 Backpropagation 단계가 반복되며 진행됩니다.
1. Forward propagation 단계
하나의 인공 뉴런에서 Activation Function까지 거쳐서 나온 result값 기억 나시나요?
이 결과값이 다음 시냅스 층의 새로운 input 값이 되어 Forwarding됩니다.
대규모의 데이터를 빠르게 Forwarding하기 위해 Batch Computing을 이용합니다.
input 데이터를 Batch 단위로 묶어서 한 번에 계산하는 것을 의미합니다.
그리고 여러 개의 Batch로 나눠진 input 데이터 전체를 부르는 단위는 1 Epoch입니다.
Batch 단위로 계산하기 위해 행렬을 사용합니다.

예를 들어 그림과 같은 시냅스 층에 대하여 forward 과정을 거친다면 아래와 같습니다.
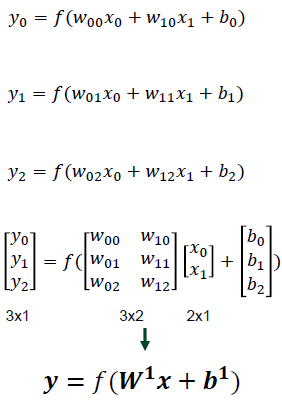
이 y는 다음 시냅스 층의 input 값이 되어 과정이 반복됩니다.
2. Backpropagation 단계
시냅스의 weight와 인공 뉴런의 bias가 업데이트되는 단계입니다.
Cost Function의 값을 최소화하는 방향으로 weight와 bias값이 조정됩니다.
Cost Function의 값을 최적화하는 알고리즘, Gradient Descent 알고리즘을 사용합니다.
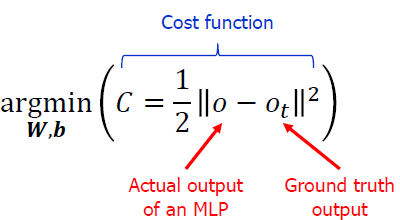
Cost Function의 형태는 다음과 같습니다.
AI 모델이 출력한 결과와 Ground Truth(= ideal output)의 차이를 기반으로 한 Function입니다.
learning rate를 𝜂라고 할 때 업데이트 된 weight와 bias는 다음과 같습니다.
= - 𝜂·
= - 𝜂·
Gradient Descent 알고리즘을 이용하여 gradient 방향으로 weight와 bias를 이동시켜
Cost Function 값을 최소화하는 weight와 bias를 찾습니다.
하나의 Batch에 대한 Forwarding이 끝나면, Backpropagation 단계를 거치며 weight와 bias를 업데이트합니다. 따라서 Batch 1개 당 업데이트 된 weight와 bias가 1개씩 나옵니다.
지금부터 Backpropagation 식을 유도해보겠습니다.
하나의 인공 뉴런에 대한 는 다음과 같습니다.

계산해보면 Ground Truth인 는 상수이므로 = 이고
o는 Activation Function 에 대하여 ,
는 에 대한 함수 이므로 = ·=입니다.
따라서 = 에 대하여 = () · · 입니다.
우리는 층이 여러개이기 때문에, 와 사이의 관계를 유도해보겠습니다.
Activation Function 에 대하여 는 다음과 같습니다.
Cost Function은 다음과 같습니다.
먼저 = () ·
정리하면 다음과 같습니다.
= () ·
다음으로 = () · = () ·
는 에 대한 함수이므로
= () · · · ·
정리하면 다음과 같습니다.
= · · · · 다.
= * 이라고 하면,
= ·
= ·
마찬가지로 = * 이라고 하면,
= · · ·
= · ·
= · ·
따라서 위의 식을 적용하여 이전 layer의 error를 backpropagate하며 모든 layer의 error를 구하여 weight gradient를 구하고, weight를 업데이트해줍니다.
에 다음과 같이 2개가 연결되어 있다면 와 가 모두 에 영향을 줍니다.
따라서 Cost Function은 다음과 같이 계산해주어야 합니다.

따라서 정리하면 식은 다음과 같습니다.
= · ·
Deep Neural Network
뉴런과 뉴런 사이의 결합이 어떻게 이뤄지냐에 따라 다음과 같이 분류할 수 있습니다.
모든 뉴런들이 연결된 Fully-Connected Network는 Dense Network, Feed Forward Network라고도 불리며, CNN으로 유명한 Convolutional Neural Network도 있습니다.
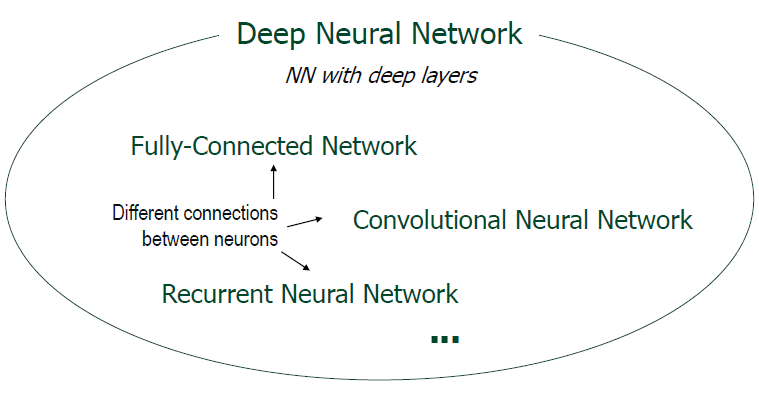
모두 feature extraction 단계를 거쳐 feature를 추출한 다음 output을 도출하는 과정을 거치는 DNN (Deep Neural Network)입니다.
Layer를 깊게 쌓는 이유
이론적으로는 layer가 적어도 hidden unit 속 perceptron의 수가 충분하다면 모든 문제를 풀 수 있습니다. 시냅스 층을 깊게 쌓는 이유는 무엇일까요?
그 이유는 바로 효율성 때문입니다.
문제를 푸는데 필요한 hidden unit의 개수는 2개 n개 로
n개의 layer를 쌓는다면 필요한 hidden unit의 개수가 크게 줄어듭니다.
따라서 layer가 2개라면 hidden unit이 너무 많이 필요하여 학습이 불가능하지만
layer를 깊게 쌓으면 필요한 hidden unit의 개수가 작아져 효율적인 학습이 가능합니다.
DNN 학습 과정
L번째 layer에 대한 결과값을 라고 하면 다음과 같습니다.
앞서 을 아래와 같이 유도했었는데요,
* 유도 과정 (이전 내용 참고)
= () · · · ·
유도 과정을 참고하여 일반화 공식을 유도해보겠습니다.
L번째 layer의 input이 이고, 이 바로 이기 때문에
다음으로 이 이므로
마지막으로 이 이고, 이 이므로
정리하자면 다음과 같습니다.
이 상수이므로, 는 element wise의 곱이며
나머지는 벡터 내적 연산입니다.
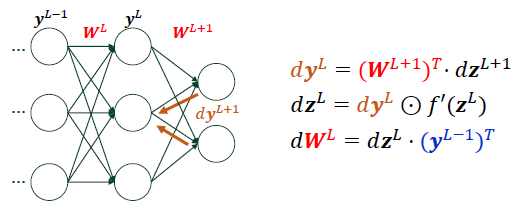
이렇게 구한 gradient를 이용하여 𝜂 연산으로 weight를 업데이트하면 됩니다.
initial point 잡는 방법
Gradient Descent 알고리즘으로 weight의 최적해를 찾아가므로, local minima 문제에 빠지지 않기 위해서는 weight 초기값을 잘 설정해주는 것이 중요합니다.
주의할 점은 weight 초기값을 0으로 설정하면 안됩니다.
-
Activation Function이 tanh 혹은 ReLU인 상황을 생각해보겠습니다.
아래의 그림에서 으로
z가 모두 0이 나오게 되며, ()
tanh와 ReLU 모두 input이 0이면 output이 0이므로 y를 포함한 최종 output으로 계속 0이 나오게 됩니다.
이때 는 이기 때문에 에서 는 항상 0이 됩니다.
결과적으로 weight값이 0에서 벗어나지 못하는 문제가 발생합니다. -
Activation Function이 Sigmoid인 상황을 생각해보겠습니다.
아래의 그림에서 으로
z가 모두 0이 나오게 되며, ()
Sigmoid(0) = 0.5이므로 y를 포함한 최종 output으로 계속 0.5가 나오게 됩니다.
이때 는 이기 때문에 sigmoid 미분 라 하면
따라서 weight 행렬의 column이 계속 같은 값을 가지게 됩니다.
결과적으로 weight가 sub-optimal한 값으로 수렴하게 되어 최적의 weight값을 찾지 못하게 됩니다.

이러한 이유로 보통 small random number로 초기화하여 학습을 시작합니다.
Input Encoding
이미지 프로세싱과 관련된 모델은 input 데이터로 이미지를 넣어주어야 합니다.
이미지를 넣어주는 대표적인 방법에는 Coarse-resolution이 있습니다.
120 X 128 pixel의 이미지가 있을 때, 30 X 32 pixel의 이미지로 줄어셔 넣어주는 방법입니다. 오리지널 이미지를 summary하여 넣어주는 것이므로, 연산량이 줄어들어 복잡도가 줄어들기 때문에 학습을 효율적으로 할 수 있습니다.
Output Encoding
output을 표현하는 대표적인 방법에는 하나의 output에 여러 개의 threshold 값을 주거나, 여러 개의 output에 하나의 threshold 값을 주는 방법이 있습니다.
예를 들어 4가지 옵션 중 하나를 표현해야 한다면 (ex 오른쪽, 왼쪽, 위, 아래)
- 0.25, 0.5, 0.75의 threshold 값을 가지는 0~1사이의 output값을 이용하거나
- 각 옵션마다 하나의 output을 만들고, 해당하는 옵션은 1, 나머지는 0으로 표현하는 방법이 있습니다. (ex 1, 0, 0, 0) 혹은 가장 큰 값을 가지는 옵션을 output으로 선택하는 방법이 있습니다. (ex 0.9, 0.4, 0.1, 0.1 -> 0.9 옵션 선택)
2번째 방법은 one-hot encoding이라고 부릅니다.
지금까지 딥러닝 개론과 DNN 학습 과정에 대해 알아봤습니다.
다음은 대표적인 DNN 모델에 대한 소개로 돌아오겠습니다.
감사합니다.
