CNN은 너무 유명한 DNN 모델입니다.
아래의 그림은 CNN의 대표적인 모델 AlexNet의 아키텍처인데요,
AlexNet을 통해 CNN을 소개하도록 하겠습니다.

구조를 보면, 먼저 Feature extraction 부분에서는 CONV layer + ReLU를 n번 반복하고 Max pooling을 해주는 단계를 m번 반복합니다. 이후 Classification 부분에서 dense layer(= FC layer)를 통과하여 추출된 feature의 분포에 대한 output classifier 함수를 생성합니다.
CONV layer
FC layer와 다르게 뉴런들이 fully connected되지 않습니다.
CONV Layer는 뉴런과의 connection 수가 적을 뿐만 아니라
connection간에 weight를 공유하므로 메모리 측면, 계산 측면에서 모두 효율적입니다.
CONV layer에는 다음과 같은 Filter(= Kernel)이 존재합니다.

Filter가 아래와 같이 input 데이터를 슬라이딩하며
weight와 input값을 곱하여 모두 더한 값을 최종 output으로 선택합니다.

input은 5X5 행렬이었는데, output은 3X3이 되었습니다.
이 문제를 해결하기 위해 아래와 같이 input에 zero padding을 주어 크기를 유지합니다.
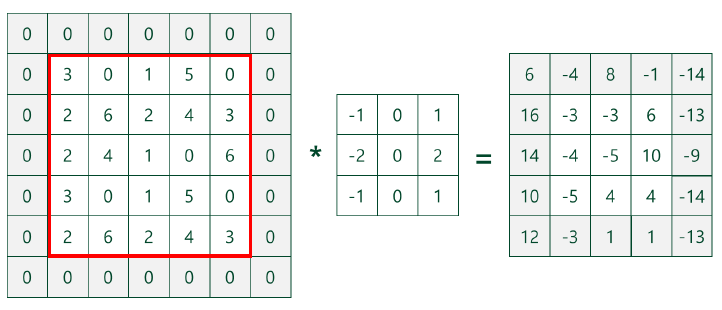
CONV layer에서는 Convolution Filter에 기술된 방식으로 feature를 추출합니다.
예를 들어 아래와 같은 Filter가 있다고 가정해보겠습니다.
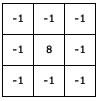
이 Filter는 가운데 pixel의 값을 높이고, 주변 pixel의 값을 낮추는 역할을 합니다.
이 Convolution Filter와 비슷한 분포를 가지는 input pixel에 대해선 더 큰 반응이 오고, 다른 분포에 대해선 작은 반응이 오겠죠?
따라서 위의 Filter에 대해서는 아래와 같은 결과가 도출됩니다. Filter에 기술된 것처럼 해당 CONV layer는 Edge feature를 추출합니다.

이전 포스트에서 딥러닝은 feature을 스스로 추출한다고 말씀드렸는데요,
이와 같이 CONV layer에서는 Convolution Filter에 기술된 방식으로 feature를 추출하므로
모델은 학습을 통해 feature를 잘 추출해내는 Convolution Filter를 찾게 됩니다.
3D Convolution
CNN은 이미지 프로세싱에 탁월한 모델인데요, 컬러 이미지는 R-G-B 3차원으로 표현되므로
input이 3D인 3D Convolution에 대해 알아보겠습니다.
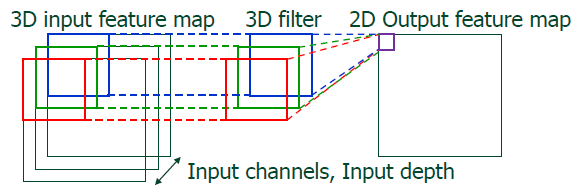
input 이미지가 3차원이므로, Filter도 3D filter가 필요합니다.
Filter의 각 차원은 다른 값을 가지며 3개의 값을 모두 더하여 최종 output을 계산합니다.

코드로는 다음과 같습니다.

따라서 Filter가 K개면 Output feature map의 차원(= Output channel)도 K개가 됩니다.
하나의 Filter 당 하나의 feature map이 나오기 때문입니다.
요약하자면 Filter Size , stride , zero padding ,
input feature map size , output feature map size 에 대하여 아래와 같습니다.
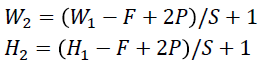
Pooling (Subsampling)
non-linear한 down-sampling을 해주는 단계입니다.
그림처럼 2X2 max pooling 연산(stride 2)을 해주게 되면 각 영역에서 가장 큰 값을 선택하여 feature map의 사이즈를 줄여줍니다.

max pooling 연산을 해주는 이유는 feature map size를 줄여 연산량과 용량을 줄이고, 노이즈에 더 강해지도록 만들기 위해서입니다.
대표적으로 translation invariance가 가능합니다.
translation invariance: input의 위치가 달라져도 output이 동일한 값을 갖는것
사물 인식 알고리즘에서는 고양이의 위치가 변하여도 똑같이 고양이라고 분류해야하는데요,
위치가 바뀌면 당연히 output에서 해당 feature에 대한 연산결과의 위치도 바뀌기 때문에
CNN 네트워크 자체는 translation invariance하지 않습니다.
아래와 같이 객체의 이동 전후 결과값이 다르게 나타납니다.
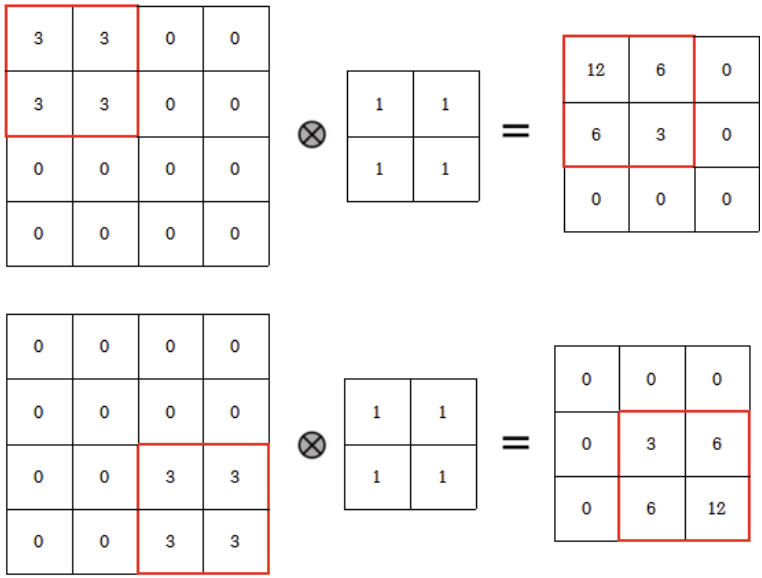
하지만 max pooling 연산을 적용하면 객체의 이동 전후 모두 max pooling을 적용한 연산 결과가 같게 나타납니다. 객체의 이동에 강인해지는 효과를 가집니다.
지금까지 CNN 모델에 대해 소개했습니다.
다음은 AlexNet 이외의 CNN 모델에 대해 알아보겠습니다.
감사합니다.
