
안녕하세요. 밍기뉴와제제입니다.
오늘 리뷰할 논문은 Dynamic Head: Unifying Object Detection Heads with Attentions입니다. Object detection에서 객체의 위치, 종류를 판단하는 Head 부분만 따로 설계한 논문입니다. 제목이 상당히 흥미로워 선택하였습니다. 줄여서 Dynamic Head라 부르겠습니다.
Dynamic Head는 CVPR 2021이라는 논문 컨퍼런스에서 발표된 논문입니다. 따끈따끈한 논문이죠. 마이크로소프트에서 발표한 논문이며 아직 구현 코드는 under internal review 단계입니다. 논문을 읽으면서 어떻게 구현했는지 궁금한 부분이 있었는데 확인하지 못해 아쉬웠습니다.
깃허브 링크는 여기입니다.
그럼 지금부터 논문 흐름에 따라 논문 리뷰를 시작하도록 하겠습니다.
Introduction
딥러닝 알고리즘으로 수행하는 이미지 데이터 처리 Task 중 Object detection이 있습니다.
번역하면 '객체 탐지'입니다. 말 그대로 주어진 이미지에 어떤 객체가 어디 있는지(what objects are located at where) 답을 찾는 것이죠.
Object detection을 수행하는 모델, Detector는 오랜 기간동안 발전했고 발전하는 과정에서 공통적인 구조를 지니게 되었습니다.
바로 Backbone + Head 구조입니다.
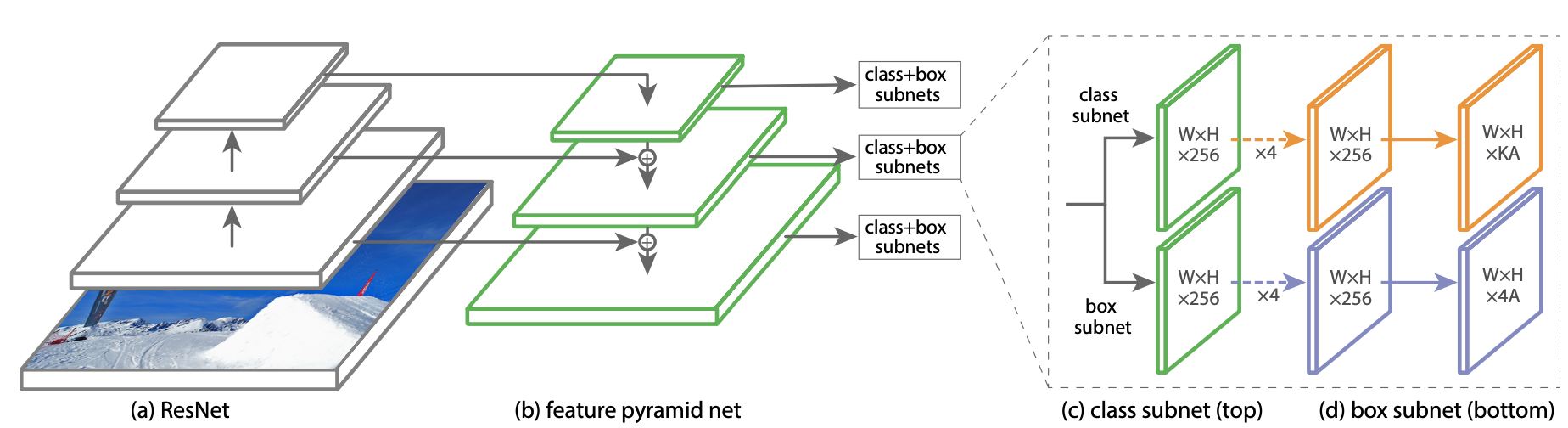
(이미지 출처 : Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.)
위 그림은 RetinaNet의 구조입니다. Backbone + Head의 구조를 깔끔하게 나타내고 있어 가져왔습니다.
여기서 (a)가 Backbone이고 (c)가 Head입니다. Backbone -> Head 순으로 이미지가 처리되며 Bakcbone에서 이미지의 특성을 추출하고 Head에서 객체가 어디있는지, 그 객체의 정체는 뭔지 판단하게 되죠.
그리고 제가 말씀드리지 않은 (b)는 Neck이라는 부분입니다. Neck은 있으면 모델의 성능이 올라가지만 필수적인 부분은 아닙니다. 그렇기 때문에 공통적인 구조에는 포함되지 않습니다.
Head의 차이 == 성능의 차이
Detector의 성능은 '얼마나 Head를 잘 만들었느냐'에 따라 갈립니다.
Head의 성능에 따라 Detector의 성능이 갈리는 경우가 많습니다.
그러면 좋은 Head의 조건은 뭐가 있을까요? 저자는 "The challenges in developing a good object detection head can be summarized into three categories"라 말하며 좋은 Head가 가져야 할 3가지 능력을 말했습니다.
참고 : Backbone은 Classification에 특화된 모델(VGG, ResNet 등)을 공통적으로 사용합니다.
- Scale-aware : Head는 객체의 크기에 관계없이 모델을 감지해야한다.
- Spatial-aware : 어떤 형태로 보여도 같은 객체임을 감지해야한다.
- Task-aware : Bounding box, Center point, Corner point 등 다양한 방식으로 객체를 표현해야한다.
저자는 지금까지 나온 Detector의 Head는 세가지 항목 중 하나만 해결하는데 집중했다고 말했습니다.
세가지 항목을 모두 만족하는 Head가 만들어지지 않았단 것이죠. open problem이 여전히 남아있는 겁니다.
그래서! 저자가 세가지 항목을 모두 만족시키는 Head를 만들었습니다. 바로 Dynamic Head입니다.
어떻게 구현했지?
그러면 어떻게 구현했을까요?
저자는 세가지 항목을 모두 만족시키는 Head, 논문에서 Unified head라 불리는 것을 만드는 방법을 attention learning problem으로 간주했습니다. attention mechanisms을 사용하는 것이었죠.
원래 하나의 full self-attention mechanism으로 구현하고 싶었으나 계산량이 너무 많다는 문제가 있었습니다.
그래서 scale-aware, spatial-aware, Task-aware 별로 self-attention mechanism을 적용하는 방법을 사용했습니다.
그럼 각 self-attention mechanism이 어떤 부분을 강조하는지 알아봅시다.
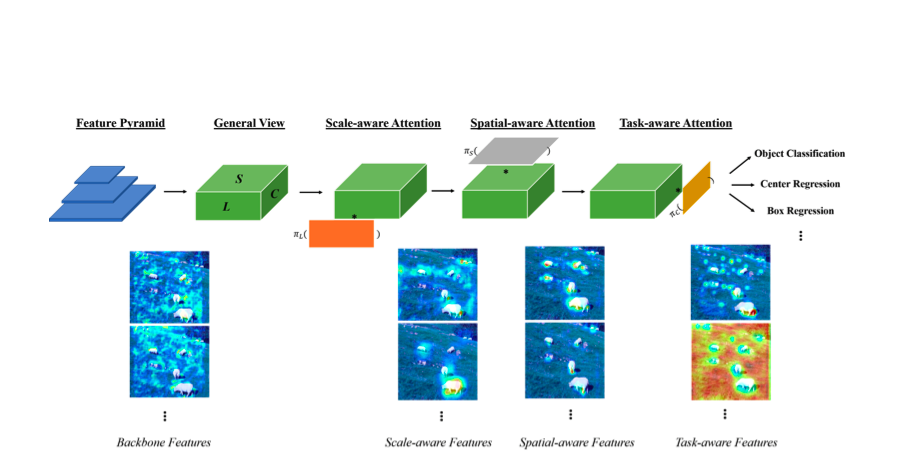
논문의 Introduction에는 나와있지 않는 부분이지만, Dynamic Head는 입력값으로 여러개의 Layer가 있는 Feature Pyramid(Level x Width x Height x Channel)를 3차원 텐서(Level x Space x Channel)로 가공해서 사용합니다.
- Scale-aware attention module : Feature Pyramid의 Level별 텐서를 살펴봅니다. 객체 별로 특성이 잘 추출된 Feature map를 attention합니다.
- Spatial-aware attention module : Feature Pyramid의 Space별 텐서를 살펴봅니다. 위치, 형태에 관계없이 같은 객체라면 드러나는 항상 존재하는 특성이 있습니다. 이를 attention합니다.
- Task-aware attention module : Feature Pyramid의 Channel별 텐서를 살펴봅니다. 각 channel 단위로 객체의 표현 방식(Bounding box 등)을 다르게 하게끔 만들어줍니다. 이 때 표현 방식의 선택 기준은 kernel의 response라고 합니다.
우선 이정도만 살펴보고 조금 있다가 더 자세히 설명드리도록 하겠습니다.
Related Work
여기에는 Scale-awareness, Spatial-awareness, Task-awareness에 대한 자세한 설명이 적혀있습니다. 논문을 인용하며 자세한 설명을 해줍니다. 간단하게 적으면 다음과 같습니다.
-
Scale-awareness : 이미지에 다양한 크기의 객체들이 있을 때도 객체 탐지를 잘하는 것을 말합니다. 많은 연구자들이 공감했고 지금도 공감하는 부분입니다.
논문에는 다양한 크기를 가진 객체를 탐지하기 위해 multi-scale의 Feature map들을 이용하는 Feature Pyramid Network가 나왔고 객체 탐지의 성능을 끌어올렸다.
허나 이런 방식은 서로 다른 scale의 feature map들 사이에 존재하는 gap이 있고 이를 해결하기 위해 여러가지 방법을 사용했다는 내용이 나와있습니다. -
Spatial-awareness : Convolution을 이용한 계산으론 다양한 각도에서 보이는 이미지를 보고 같은 판단을 하는데 제한이 있습니다. 이걸 해결하기 위해 모델의 사이즈를 늘리거나 데이터 증강을 하는 등 여려가지 방법을 제안했지만 계산량이 많아진다는 단점이 있었죠.
그래서 나온 또다른 방식은 엄청나게 많아진 receptive field에서 얻은 정보를 한데 모으는 dilated convolution이나 kernel을 정사각형 대신 픽셀의 패턴을 고려해 조금 흐물흐물한(?) 영역에서 특성을 추출하는 deformable convolution을 사용하는 것입니다. 더 자세한 내용이 논문에 적혀있습니다. -
Task-awareness : 객체를 표현하는 방식에 대하여 말합니다. Detetor의 발전 과정을 말한 뒤 Mask R-CNN을 인용하며 객체의 표현 방식이 성능 향상에 영향을 미친다는 말을 합니다. 그리고 다양한 모델들이 사용하는 다양한 표현 방식을 말합니다. 자세한 내용은 논문에 적혀있습니다.
Our Approach
Dynamic Head를 구현한 방법을 설명하는 곳입니다.
Motivation
우선 모델의 구조는 다음과 같습니다.
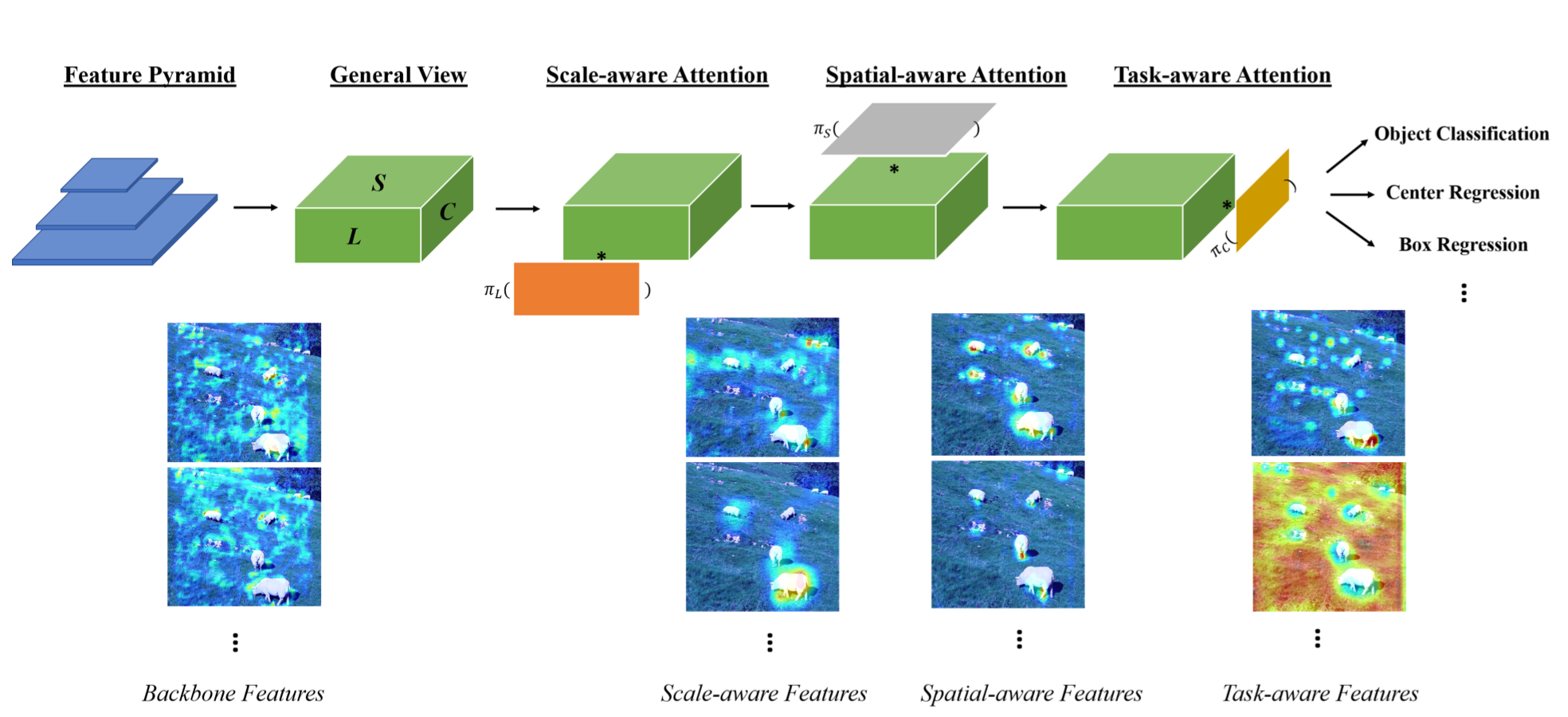
저자들은 Scale-aware, Spatial-aware, Task-aware self-attention을 unified object detection head에서 처리하고 싶었습니다. 위 그림은 저자들의 바램을 달성한 head의 구조입니다.
저 연속된 과정을 한 Block으로 취급하면 unified object detection head가 되는 것이죠.
대략적으로 구조를 설명해드리면 다음과 같습니다.
- Backbone으로부터 Feature Pyramid를 받습니다.
- Feature Pyramid의 즉 중간층(median level)에 있는 사이즈에 맞게 나머지 feature map들의 H x W x C를 늘리거나 줄여 [L x H x W x C] 사이즈의 4차원 텐서 F를 만듭니다.
- H x W = S로 하여 4차원 텐서 F를 [L x S x C] 사이즈의 3차원 텐서 F로 만듭니다.
- F에 Scale-aware self-attention 연산을 적용해 이미지 내에 있는 객체별로 특성이 잘 드러난 level의 feature들을 attention합니다.
- Scale-aware self-attention을 거친 F를 Spatial-aware self-attention 연산을 합니다. 그러면 모든 Feature map의 space에서 공통적으로 드러나는 객체의 특성이 attention됩니다
- Scale-aware self-attention, Spatial-aware self-attention을 거친 F를 Task-aware attention 연산을 합니다. 그러면 F의 channel별로 Bounding box, center point 등 task를 수행하게끔 합니다.
여기서 4~6단계가 'combine multiple attentions on all three dimensions'라고 논문에서 언급하는, 각 측면의 attention을 하나의 head안에서 수행한다는 것이 구현된 부분입니다.
모델 구조를 나타낸 그림 밑에 Backbone Features, Scale-aware Features...등의 이름을 가진 사진들이 있습니다. 이는 각 단계를 거칠 때마다 feature map에 있는 attention을 시각화한 그림입니다.
연산히 진행될 수록 사진 속 객체에 attention 되어있는 모습을 확인하실 수 있습니다.
논문에는 연산이 진행될 때마다 일어난 변화를 다음과 같이 서술했습니다.
Scale-aware Features : 각각 다른 객체의 크기에 sensitive해졌습니다.
Spatial-aware Features : 더 sparse해지고 객체들의 discriminative spatial location에 집중하게 되었습니다
Task-aware Features : 특성맵들이 각 task가 요구하는 것에 맞춰 different activation으로 재구성 되었습니다
Dynamic Head: Unifying with Attentions
수학적으로 표현해봅시다.
우선 self-attention을 어떻게 구현했는지 알아봅시다. 다음과 같습니다.
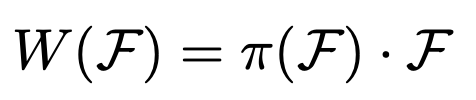
여기서 W(·)가 self-attention이고 π(·)는 attention function입니다. 저자는 attention function을 Fully connected layers로 구현했는데요, 이는 attention function의 naive solution이라고 합니다. 단순하게 구현한 것이죠.
그리고 저자는 앞서 모든 측면(Scale, Spatial, Task)을 한 번에 처리하고 싶었지만 계산량이 너무 많아 하나씩 attention을 적용하기로 했다고 말씀드렸습니다.
이를 식으로 나타내면 다음과 같습니다. 3-sequential attentions를 구현한 것이죠.
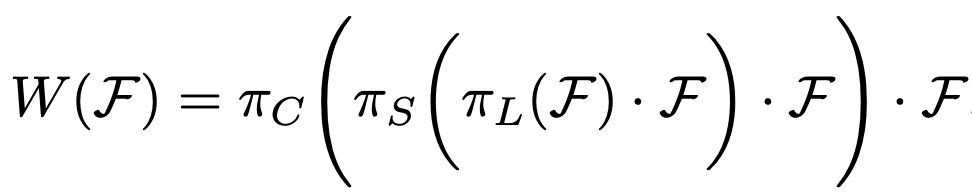
여기서 πL(·), πS(·), 그리고 πC(·)는 각각 Scale-aware, Spatial-aware, Task-aware attention function입니다.
앞서 attention function을 Fully connected layers로 구현했다고 말씀드렸습니다.
그런데 다 다른 방식으로 attention function을 구현했습니다. 하나씩 설명해 드리도록 하겠습니다.
Scale-aware Attention πL(·)
우선 Scale-aware attention function πL을 이용한 Scale-aware Self-Attention입니다. 식은 다음과 같습니다.
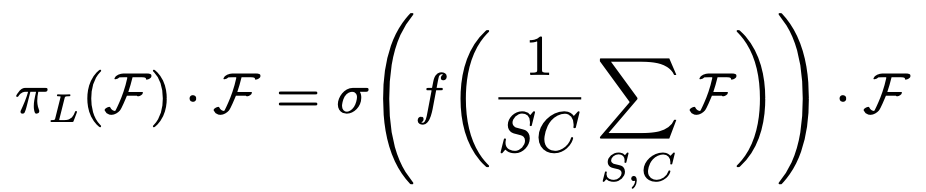
여기서 f(·), σ(x)는 다음과 같습니다.
- f(·) : 1 x 1 convolutional layer로 구성된 선형 함수
- σ(x) : max(0, min(1, x+1 )), hard-sigmoid function
그러면 이제 식을 살펴봅시다.
우선 텐서 F의 Level당 Space, Channel 평균값을 구합니다. (1/SC) * sigma(F)를 말합니다.
그리고 이 평균값을 1 x 1 convolution layer에 넣어 Fully-connected 연산을 한 뒤 hard-sigmoid function에 넣습니다.
hard-sigmoid function : sigmoid의 근사 버전입니다. x < -2.5 혹은 x > 2.5일 때 기울기 = 0이고 -2.5 < x < 2.5면 기울기가 0.2인 함수입니다. 함수의 범위는 -1 <= σ(x) <= 1입니다. 계산량이 줄었기 때문에 훈련 속도가 빨라진다는 장점이 있습니다.
저자는 πL(·)을 사용한 이유를 '의미적 중요성에 기반해 서로 다른 scale의 feature들을 유동적으로 합체하기 위함'이라고 말합니다.
Spatial-aware Attention πS(·)
Scale-aware Attention을 거친 F를 입력값으로 받습니다. 식은 다음과 같습니다.
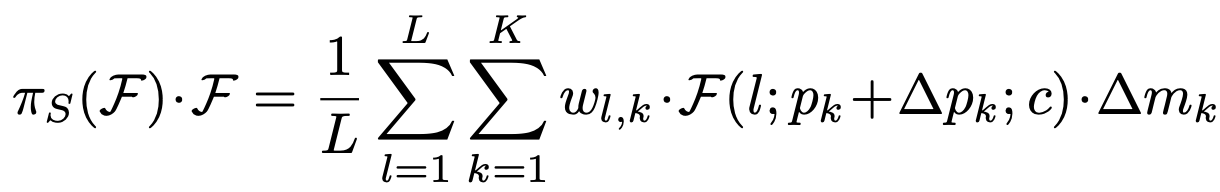
πL보다 식이 복잡한 느낌이 듭니다. 침착하고 하나씩 살펴봅시다.
- K : sparse sampling location의 개수입니다. 임의로 선별한 영역의 개수가 아닌가 싶습니다.
- pk + ∆pk : self-learned spatial offset ∆pk에 의해 옮겨진 위치라고 합니다. 위치를 옮기는 이유는 discriminative region에 집중하기 위해서라고 하네요.
- ∆mk : self-learned importance scalar at location pk라고 합니다.
그리고 ∆pk, ∆mk는 F의 median level에 있는 feature에 의해 학습된다고 합니다
도대체 뭔뜻일까요? 이해가 잘 되지 않습니다.
이 식을 이해하기 위해선 Deformable convolution이 뭔지 알아야 합니다.
Deformable convolution
우선 Deformable convolution의 식은 다음과 같습니다.
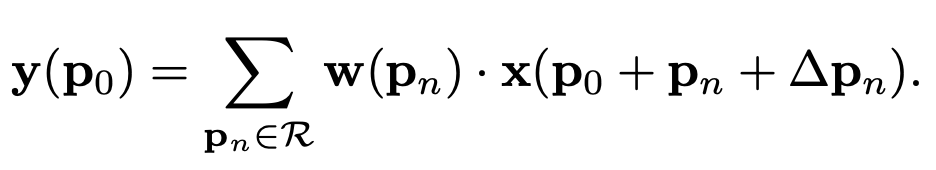
보시면 시그마 안에 있는 식이 πS의 시그마 안에 있는 식과 같은 모양이라는 사실을 알 수 있습니다. 즉, πS는 Deformable convolution을 이용한 것이죠.
그럼 그림을 통해 Deformable convolution이 기존의 convolution 연산과 어떻게 다른지 확인해봅시다.
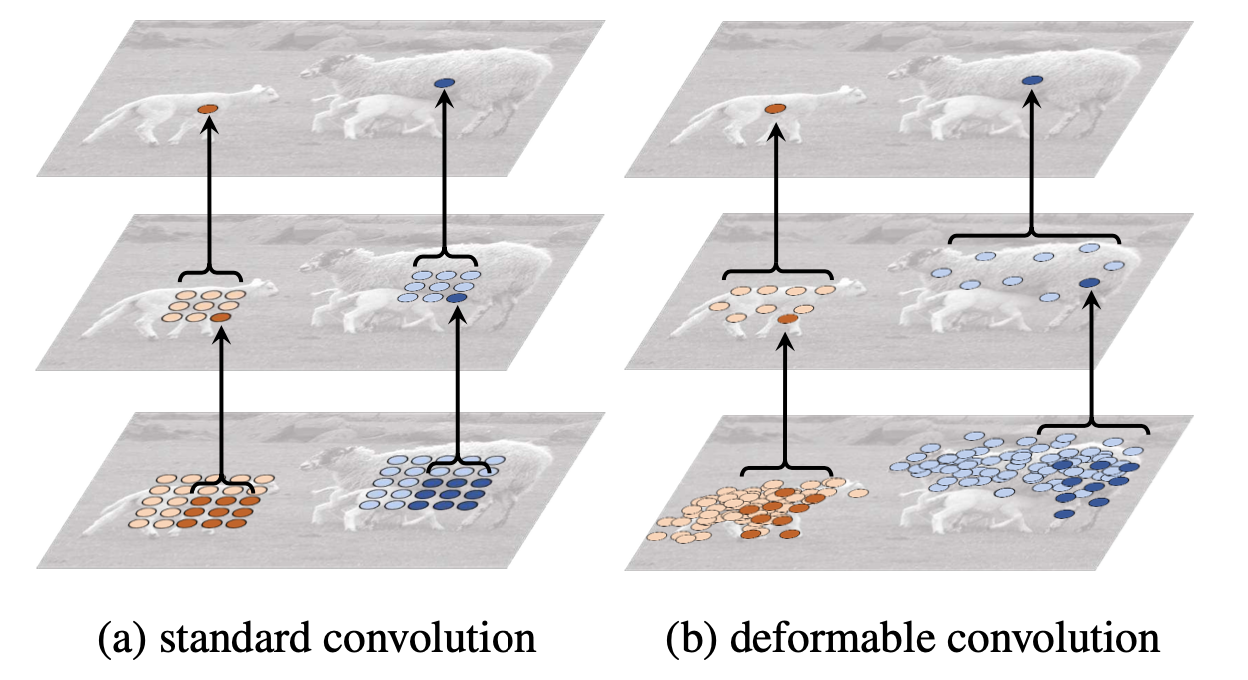
진한 점을 주목합시다. 일반적 convolution(a)를 보시면 연산 끝에 추출된 특성은 각 객체의 중점이 아닌 다른 곳에 있지만 Deformable convolution(b)를 보시면 커널부터 정사각형이 아닌 다른 흐물흐물한 모양으로 변형된(Deformable) 모양을 지녔고 연산 결과, 객체의 중점에 있다는 걸 확인할 수 있습니다.
즉, Deformable convolution은 자체 학습되는 offset ∆pk에 의해 특성을 추출할 객체의 모양에 맞게 kernel이 변형되어 객체를 모두 포함한 영역에서 특성을 추출하는 연산을 하는겁니다. 이는 곧 객체의 모양에 관계없이 객체의 특성을 추출할 수 있게 되고 곧 성능향상으로 이어지죠.
그래서 저자는 πS(·)에서 Deformable convolution을 사용한게 아닌가 추측됩니다.
다시 πS(·)로 돌아옵시다. 저자는 πS(·)를 사용한 이유로 'spatial location과 feature level 양쪽에서 계속 공존하는 차별적인 영역에 집중하기 위함'이라고 말했습니다.
논문에 나온 내용을 직역한건데 자연스럽지 못한 번역이 되었습니다. 조금 더 자연스럽게 적어보면 다음과 같습니다.
"위치, level에 관계없이 공통적으로 드러나는 객체의 특징을 강조하기 위해 사용"
만약 자동차를 촬영할 때, 어떤 각도에서 찍어도 자동차만이 갖고 있는 고유한 특징이 사진에 담깁니다. Spatial-aware Attention는 그런 고유한 특징을 강조하는 연산을 하는겁니다.
Task-aware Attention πC(·)
마지막 Self-Attention입니다. Scale-aware Attention과 Spatial-aware Attention을 거친 F를 입력값으로 받으며 식은 다음과 같습니다.
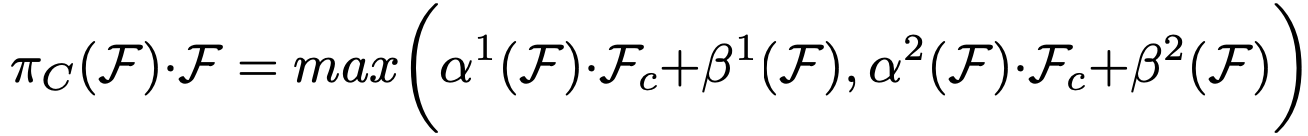
- Fc : c번 째 Channel에 해당하는 F의 feature slice입니다.
- [α1, α2, β1, β2]T = θ(·) : activation thresholds를 제어하는 hyper function입니다.
θ(·)는 [L x S 차원에 대한 global average pooling -> 2개의 fully connected layers -> normalization layer -> shifted sigmoid function]순으로 연산을 수행하는 함수로 구현되었습니다.
shifted sigmoid function에 의해 출력값의 범위는 [-1, 1]이 됩니다.
저자는 πC(·)를 사용한 이유로 'joint learning을 가능하게 하고 객체의 각자 다른 표현 방식을 일반화하기 위함'이라고 말했습니다. πC(·)는 유동적으로 적절한 channel of feature들을 ON, OFF합니다. πC(·)를 거친 channel of feature에는 bounding box, center point, classification 등 각 task에 대한 값이 담겨있습니다.
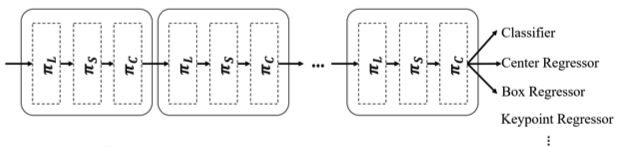
Attention Block을 여러번 사용
앞서 Dynamic Head는 말씀드린 세가지 Self-Attention function을 연속적으로
위와 같이 처리한다고 말씀드렸습니다. 마찬가지로 Attention Block W(F)도 W(W(F))와 같이 사용할 수 있으며 실제로 저자는 이 방식으로 Attention Block을 여러번 사용했습니다. 이를 "stack multiple πL,πS,and πC blocks together"라고 말했죠.
이 그림을 보시면 왜 Stack이라 표현했는지 이해하실 수 있을겁니다.
그림으로 Attention Block 표현
πL(·), πS(·), 그리고 πC(·)가 연속적으로 연산되는 Attention Block을 그림으로 나타냈습니다.
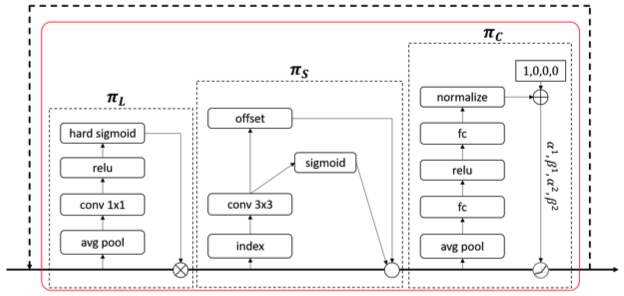
시각적으로 쉽게 이해할 수 있게 만들어놨습니다.
그런데 저는 πC(·)는 여전히 제대로 이해하지 못해 구현 코드를 찾아보려고 했는데요, 코드가 비공개 상태라 확인하지 못했습니다. 내부적 심사를 거치는 중이라고 하네요.
Generalizing to Existing Detectors
기존에 존재하는 Detector에 Dynamic Head를 적용하는 방법이 나와있습니다.
One-stage Detector, Two-stage Detector별로 각각 다른 적용 방법이 있습니다.
One-stage Detector
간단합니다. 기존에 있는 head를 제거한 뒤 Backbone에 Dynamic Head로 만들어진 one unified branch를 연결해줍니다. Attention Block을 여러번 사용할 수 있기 때문에 Attention Block이 아니라 one unified branch로 표현했습니다.
그림으로 나타내면 다음과 같습니다.
그냥 Attention Block을 여러번 연결했습니다. 저자는 기존에 있던 One-stage Detector과 비교했을 때 매우 심플하며 성능도 상승했다고 말했습니다.
그리고 객체의 표현방식이 다양한데 Dynamic Head는 다양한 객체의 표현방식(Task)에 flexible하다며 다양한 model에서 쓰일 수 있음을 말했습니다.
Two-stage Detector
다양한 객체 표현 방식을 지원해주던 One-stage Detector와는 달리 Two-stage Detector에서는 Bounding box만 지원합니다.
이유는 따로 적혀있지 않았지만 Two-stage Detector에 Dynamic Head를 적용할 때는 Spatial-aware attnetion을 하고 RoI Pooling으로 객체별 pooling을 거친 뒤 Task-aware attention을 거치는데 RoI Pooling까지 연산을 수행하였는데 center point나 corner point로 표현할 이유가 없으니 bounding box만 지원한다고 말하는게 아닌가 생각됩니다. Bounding box가 Mask Representation같은걸 제외하면 객체에 대해 가장 많은 정보를 표현을 해주잖아요.
Two-stage Detector에서 Dynamic Head를 사용한걸 그림으로 나타내면 다음과 같습니다.

Experiment
Experiment는 Dynamic Head를 사용함으로써 성능이 얼마나 향상되는지, Dynamic Head에 있는 어떤 Attention function이 성능 향상에 어떻게, 얼마나 기여하는지 등을 살펴보는 부분입니다.
Ablation Study
πL(·), πS(·), πC(·)를 제거하며 성능을 비교하고 각 Self-attention function이 어떤 역할을 하고있는지 살펴보는 부분입니다.
우선 성능 비교표는 다음과 같습니다.
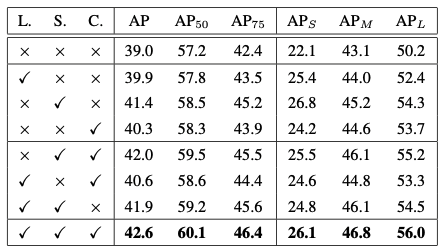
우선 πL(·), πS(·), πC(·)중 하나만 들어가도 성능이 올라간다는 사실을 확인할 수 있습니다. 그 중 Spatial-aware Attention을 담당하는 πS(·)이 가장 높은 성능 상승을 이끌었습니다. 저자는 이 현상의 원인으로 "3개의 Attnetion function 중 πS(·)의 dominant dimensionality 때문"이라 말하고 있습니다.
Effectiveness on Attention Learning
Scale-aware Attention, Spatial-aware Attention에 대해 조금 더 자세히 알아봅시다.
Scale-aware Attention πL(·)
우선 πL(·)입니다. 저자는 πL(·)가 기여하는 바를 보여주기 위해 'trend of the learned scale ratios'라는 걸 보여줍니다.
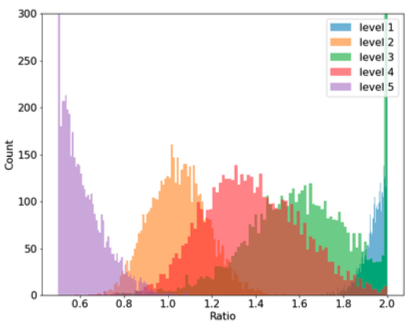
이게 바로 'trend of the learned scale ratios'입니다. 이는 각 level에 있는 feature map의 값들에 대한 scale ratio의 분포도를 나타내고 있습니다.
scale ratios는 '학습된 고해상도 가중치를 저해상도 가중치로 나눈 값'을 말합니다. 따로 저해상도에 대한 가중치와 고해상도에 대한 가중치를 구현해놓은게 아닌가 싶습니다.
이 그래프에서 봐야할 부분은 가장 고해상도 feature map에 있는 Scale ratio(보라색 막대그래프 집합)가 저해상도 feature map쪽으로 가도록 규제 되었다는 것, 가장 저해상도 feature map에 있는 Scale ratio(파란색 막대그래프 집합)가 고해상도 feature map쪽으로 가도록 규제 되었다는 것입니다.
이게 뭔 뜻이냐면, 보라색 그래프의 Scale ratio가 0.6보다 작은 값에 집중적으로 모여있는걸 보시면 이해하실 수 있습니다. 보라색 그래프는 가장 해상도가 높은 feature map을 말하며 여기 있는 feature map의 scale ratio가 소수에 몰려있다는건 해상도가 높은 feature map이 저해상도에 조금 더 가중치를 둔다는 뜻으로 해석할 수 있습니다.
이 반대도 해당됩니다. 파란색 그래픽을 나타내는 하늘색 그래프는 가장 해상도가 낮은 feature map을 말하는데 이 feature map의 Scale ratio가 높다는 뜻은 고해상도에 더 많은 가중치를 둔다는 뜻입니다.
count는 뭘 카운트했냐면 이미지 숫자를 카운트 했습니다. 저자는 COCO val2017 subset에 있는 모든 이미지를 테스트해 추출된 특성맵이 각각 어떤 해상도에 가중치를 더 뒀는가 scale ratio를 통해 확인했습니다.
원래 해상도가 다른 Feature map들을 같이 이용하면 해상도 차이에서 오는 gap이 있었는데 πL(·)을 사용하면 고해상도 feature map은 저해상도에 더 가중치를 두고, 저해상도 feature map은 고해상도에 더 가중치를 두면 그 gap을 줄일 수 있습니다.
논문에는 이를 'smooth the scale discrepancy form different feature levels'로 표현했습니다.
Spatial-aware Attention πS(·)
이제 πS(·)를 살펴봅시다.
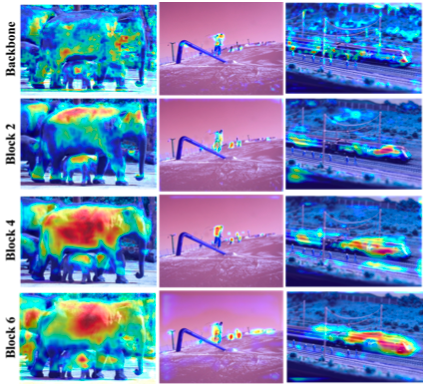
위 자료는 각 연산을 수행한 이후 attention을 시각화한 자료입니다. attention을 하기 전(Backbone)에는 굉장히 노이즈가 많은 상태입니다. 제대로 attention을 하지못한 것이죠.
하지만 Attention을 거칠 수록 사진 속 객체에 attention이 되는걸 보실 수 있습니다. Block2는 [πL(·) -> πS(·) -> πC(·)]를 두번 거친 뒤 attention을 나타낸 사진이고 Block4는 4번, Block6은 6번 거친 사진입니다.
저자는 위와 같은 시각화는 spatial-aware attention learning의 효과를 잘 증명하고 있다고 말하는데 음...결국 Scale 측면에서도 attention을 거쳤을텐데 이걸 spatial-aware attention의 성능을 나타낼 자료로 과연 적절한지 잘 모르겠습니다. 차라리 [πS(·) -> πC(·)]만으로 이루어진 연산을 여러번 거치며 생긴 feature map을 보여줬으면 어땠을까 싶습니다.
Efficiency on the Depth of Head
여기서는 [πL(·) -> πS(·) -> πC(·)]로 이루어진 Dynamic head를 쌓은 개수와 이에 따른 성능을 표로 나타냈습니다.
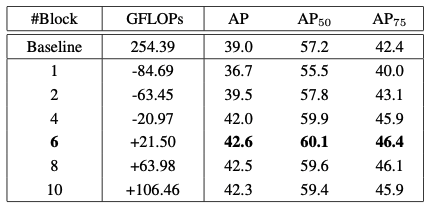
이게 바로 Dynamic head 개수에 따른 성능을 표로 나타낸 자료입니다. 원래 Detector인 Baseline과 Baseline의 Head를 Dynamic head로 바꾼 뒤 Dynamic head 개수(1, 2, 4, 6, 8, 10)의 성능이 나와있습니다.
GFLOPs : GIGA FLoating point Operations Per Second의 줄임말이며 계산량을 나타냅니다.
여기서 주목할 점은 Dynamic head를 2개만 쌓았는데도 Baseline의 성능을 넘겼다는 것입니다.(39.0 -> 39.5)
그러면서 계산량은 -63.45만큼 줄어들었죠.
그러면 가장 성능이 높을 때는 언제일까요? 표에 글씨체가 강조된 부분이 보이실겁니다. 바로 Dynamic head를 6개 쌓았을 때 가장 성능이 잘나옵니다. 그보다 많이 쌓으면 오히려 역효과인듯 합니다.
6개 쌓았을 때 가장 높은 성능을 보여주지만 계산량이 Baseline보다 21.5만큼 늘어났습니다. 허나 논문에서 21.5만큼 늘어난걸 무시할만한 수치라고(negligible) 말한걸 보니 크게 부담될 일은 아닌가 봅니다.
Generalization on Existing Object Detectors
Dynamic head를 다양한 Detector에 적용하고 성능 변화를 비교해봅시다.
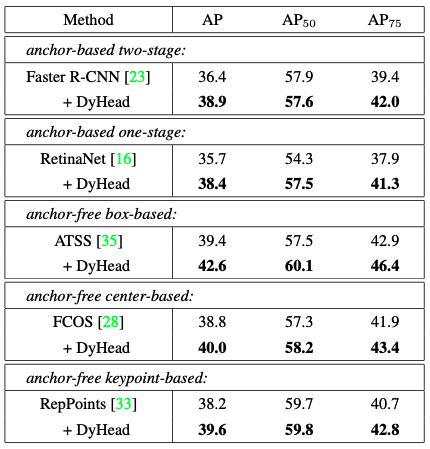
다양한 방식으로 task를 수행하는 여러가지 Detector에 Dynamic head가 추가되자 모두 성능 향상을 이뤄냈습니다. 신기합니다. 1.2~3.2의 AP 향상이 있습니다.
저자는 이에 대해 "our dynamic head significantly boosts all popular object detectors by 1.2 ∼ 3.2 AP. It demon- strates the generality of our method."라고 말했습니다.
Comparison with the State of the Art
여기서는 여러가지 Detector들과 Backbone + Dynamic head로 이루어진 Detector간의 성능을 비교합니다. 여러가지 Backbone을 사용하며 성능을 비교하기도 합니다.
저자가 선택한 Backbone은 ResNet-50, ResNet-101, ResNeXt-101이고 ResNet-101, ResNeXt-101을 Backbone으로 사용할 때는 2x training schedule로 훈련시켰습니다.
Cooperate with Different Backbones
Backbone 종류에 따른 [Backbone + Dynamic head] Detector와 다른 모델들의 성능을 비교하였습니다. 다음과 같은 결과가 나왔습니다.
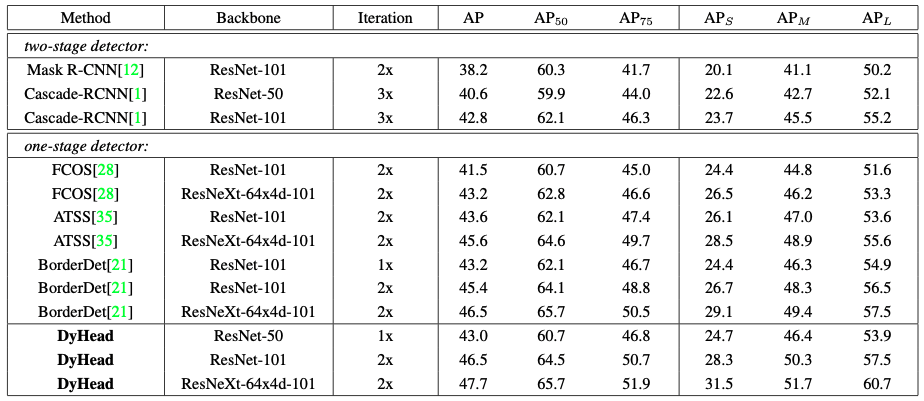
모든 부분(객체 크기별 정확도, IoU에 따른 정확도, 전체적인 정확도)에서 ResNext101 + Dynamic head Detector가 가장 좋은 성능을 보여주고 있습니다.
그리고 가장 높은 성능이 나온 ResNext101 + Dynamic head Detector를 현재 가장 좋은 성능을 보여주는 Detector들과 성능을 비교했을 때 결과도 논문에 있습니다.
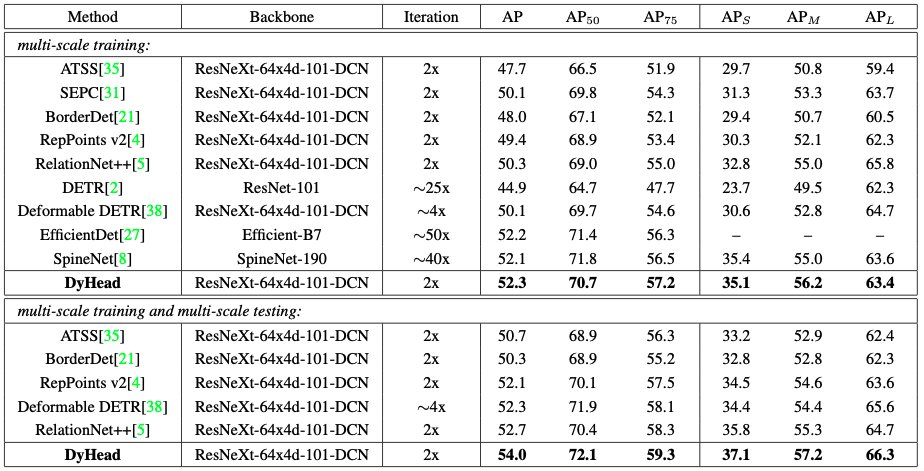
앞서 보여드린 표와 같이 ResNext101 + Dynamic head Detector가 모든 부분에서 가장 높은 성능을 보여주고 있습니다.
Conclusion
결론입니다.
저자는 scale-aware, spatial-aware, and task-aware attention을 하나의 framework에 담은 head를 구현했습니다. 이는 다양한 Detector에 적용할 수 있고 적용할 때마다 성능이 올라가는 모습을 보여줬습니다.
Dynamic head와 같이 head 설계, 훈련에 attention mechanism을 사용한 것을 두고 더 관심 가져볼만한 흥미로운 방향을 제시했다고 말하기도 했습니다.
그리고 마지막으로 Dynamic head와 같이 attention을 head에 사용할 때 더 발전시킬 수 있는 항목을 두가지 제시했습니다.
-
모든 측면을 attention(full-attention)하는 model을 쉽게 훈련시키고 계산의 효율을 증가시키는 것.
(앞서 저자가 이를 구현하고 싶어했으나 계산의 cost가 너무 많아 시도하지 못했다고 말했습니다.) -
체계적으로 더 다양한 측면의 attention을 head에 넣어 성능을 향상시키는 것.
발전시킬 수 있는 두 가지 측면을 말하며 Conclusion이 끝납니다.
후기
긴 리뷰가 끝났습니다. 최근에 나온 논문이라 리뷰글도 없어 이해하는데 쉽지 않았는데 그래도 어느정도 이해하고 블로그에 리뷰를 쓰면서 점점 논문을 깊게 이해할 수 있었습니다.
아이디어가 좋은 논문이었다고 생각합니다. 그저 Head만 갈아끼워도 더 좋은 성능을 낼 수 있다고?
신기했습니다. 근데 생각해보니 현존하는 Detector들이 거의 다 같은 Backbone을 쓰고 Head에서 차별성을 보이니 흠...사실상 모든 논문들이 Head만 갈아끼워도 더 좋은 성능을 낼 수 있다는걸 보여주는 거네요.
그래도 아무튼, 이렇게 다양한 Detector에 사용할 수 있는 Head는 처음 봤습니다.
지금 구현 코드가 내부적 심사를 거치고 있어 비공개 상태인데 얼른 심사를 통과하고 코드가 공개되었으면 좋겠습니다.
그러면 저는 여기서 글을 마무리하고 다음 리뷰에서 찾아뵙겠습니다.

지나가다가, 논문 정리된 글을 읽었는데 개인적인 생각과 논문 내용을 잘 정리해주셔서 너무 감사합니다.
GFLOPS는 아마 "GPU FLoating point Operations Per Second" 가 아닌, "GIGA FLoating point Operations Per Second" 일 것입니다. ㅎ GPU연산량이 워낙 많아서, Giga 단위를 기본으로 쓰더라구요. 트랜스포머 때문에 요즘엔 TFLOPS도 자주 보이네요.
좋은 글 감사합니다!