안녕하세요. 밍기뉴와제제입니다.
정말 오랜만에 돌아왔습니다. 논문은 여러개 봤는데 리뷰할 정도로 깊게 탐구한 논문이 별로 없어 한동안 글을 안쓰다 이번에 논문 세미나를 하다보니 꼼꼼히 살펴본 논문이 생겼습니다.
이번에 리뷰를 하려는 논문은 'Multi-Modal Fusion Transformer for End-to-End Autonomous Driving '라는 논문입니다. 자율주행에 관한 논문이죠.
이름을 보면 대충 짐작 가시겠지만 이 논문은 multimodal, 두가지 데이터를 처리하는 모델을 설계했습니다. 그리고 Transformer도 이용했다는 사실을 짐작할 수 있습니다.
그러면 지금부터 논문 흐름에 맞춰 리뷰를 해보도록 하겠습니다.
Introduction
이 부분에서는 이전까지 자율주행 모델이 사용한 방식들을 소개 후 저자가 소개하는 모델 'transfuser'에 대해 설명합니다.
한가지 입력값만 받는 모델
이전에 Image-only model과 LiDAR-only model이 등장했고 이는 자율주행의 성능을 올리는데 많이 기여했습니다. 허나 이렇게 한가지 데이터만 입력값으로 사용한 모델은 near-ideal한 움직임을 보이는 객체들만 있는 환경에서 제한된 움직임만 필요한 경로에 주행해야만 높은 성능을 보여준다는 것이었죠. 굉장히 사용하기 까다로웠습니다.
논문에서는 이를 두고 다음과 같이 말했습니다.
adversarial scenarios에서 만족스럽지 못한 성능을 보여준다
여기서 adversarial scenarios는 운전에 변수가 많이 생기는 환경을 말합니다. 예를 들면 비보호 회전을 해야하는 교차로, 랜덤하게 등장하는 자동차와 보행자 등이 운전에 변수를 주는 요소라 볼 수 있죠.
그러면 이런 부분이 왜 낮은 성능이 나오게끔 하는걸까요? 다음의 그림을 보며 설명해 드리도록 하겠습니다.
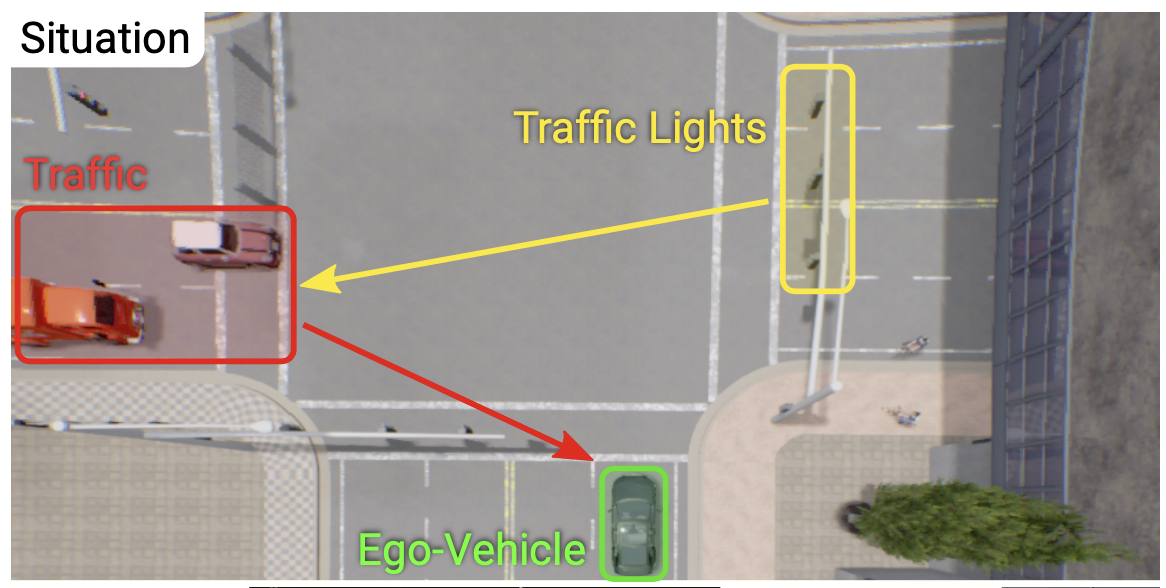
위 사진은 논문에서 말한 adversarial scenarios 중 하나입니다.
여기서 초록색 박스 안에 있는 자동차(Ego-Vehicle)와 왼쪽 도로에서 건너오는 빨간색 박스 속 자동차들(Traffic), 그리고 노란색 박스 안에 있는 신호등(Traffic Lights)이 있습니다. 여기서 Ego-Vehicle이 자율주행을 하는 자동차죠.
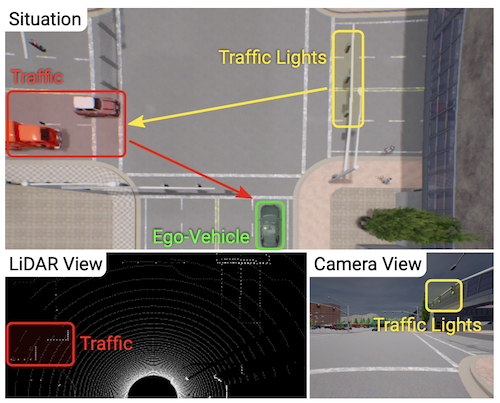
이 상황에서 Ego-Vehicle이 카메라와 LiDAR에서 얻은 데이터를 살펴봅시다. LiDAR의 정의는 다음과 같습니다.
LiDAR : Light Detection And Ranging, 레이저를 발사 후 돌아오는 시간을 계산해 주변 물체를 검출하는 센서
LiDAR는 3D 데이터인 Point Cloud를 생산하며 여기엔 카메라가 관측할 수 없는 넓은 범위에 존재하는 객체에 대한 정보가 포함되어 있습니다. 그림을 보면 카메라 뷰에서 보이지 않는 자동차(Traffic)을 검출했다는 사실을 확인할 수 있습니다.
허나 LiDAR는 카메라가 검출한 신호등을 찾지 못했습니다. 즉, 각 센서별로 얻을 수 있는 정보가 다릅니다.
이러한 상황에서 Image-only 혹은 LiDAR-only model을 사용해 자율주행을 한다고 가정해봅시다.
그러면 아래와 같은 문제가 생길 확률이 높습니다.
- Image-only model : 왼쪽에서 건너오는 자동차들을 고려하지 않고 운전 -> 추돌 사고
- LiDAR-only model : 전방에 있는 신호등의 신호를 고려하지 않고 운전 -> 신호 위반
이건 꽤 큰 단점이죠. 그래서 사람들은 이를 해결하기 위한 방법을 찾고자 했습니다.
두가지 입력값을 함께 사용해보자
사람들은 자율주행 자동차에 있는 센서에 주목했습니다.
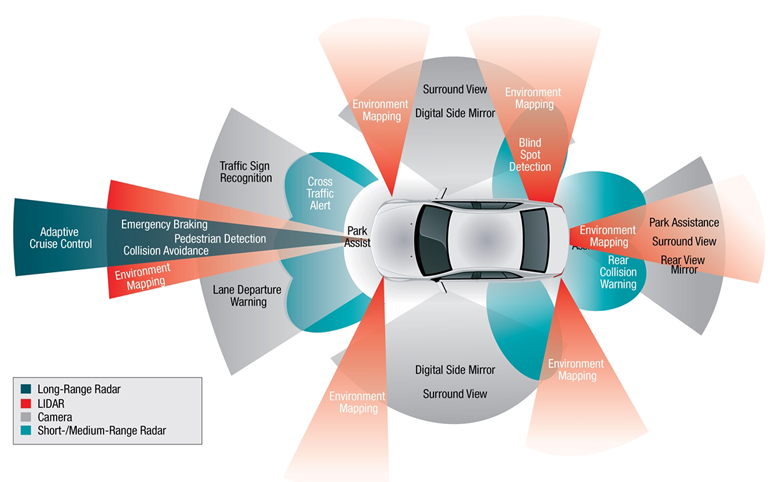
(출처 : https://towardsdatascience.com/how-to-make-a-vehicle-autonomous-16edf164c30f)
위 사진은 자율주행 자동차에 들어있는 센서를 나타낸 그림입니다. 보시면 알겠지만 자율주행 자동차 안에는 수많은 센서들이 들어있습니다.
이렇게 많은 센서를 보고 사람들이 생각한게 있습니다.
"자동차에 있는 두개의 센서를 함께 사용해보는건 어떨까?"
그래서 두가지 데이터를 함께 써보자는 아이디어를 떠올렸죠. 그리고 다음과 같은 질문을 남겼습니다.
- 두가지 데이터를 어떤 방식으로 합쳐서 사용하지?
- 두가지 데이터로 어떤걸 선택하지?
이 질문에 답하기 위해 수많은 논문들이 나왔습니다. 그 중 한가지 논문에 나온 모델 구조에 대해 간단히 소개해드리겠습니다.
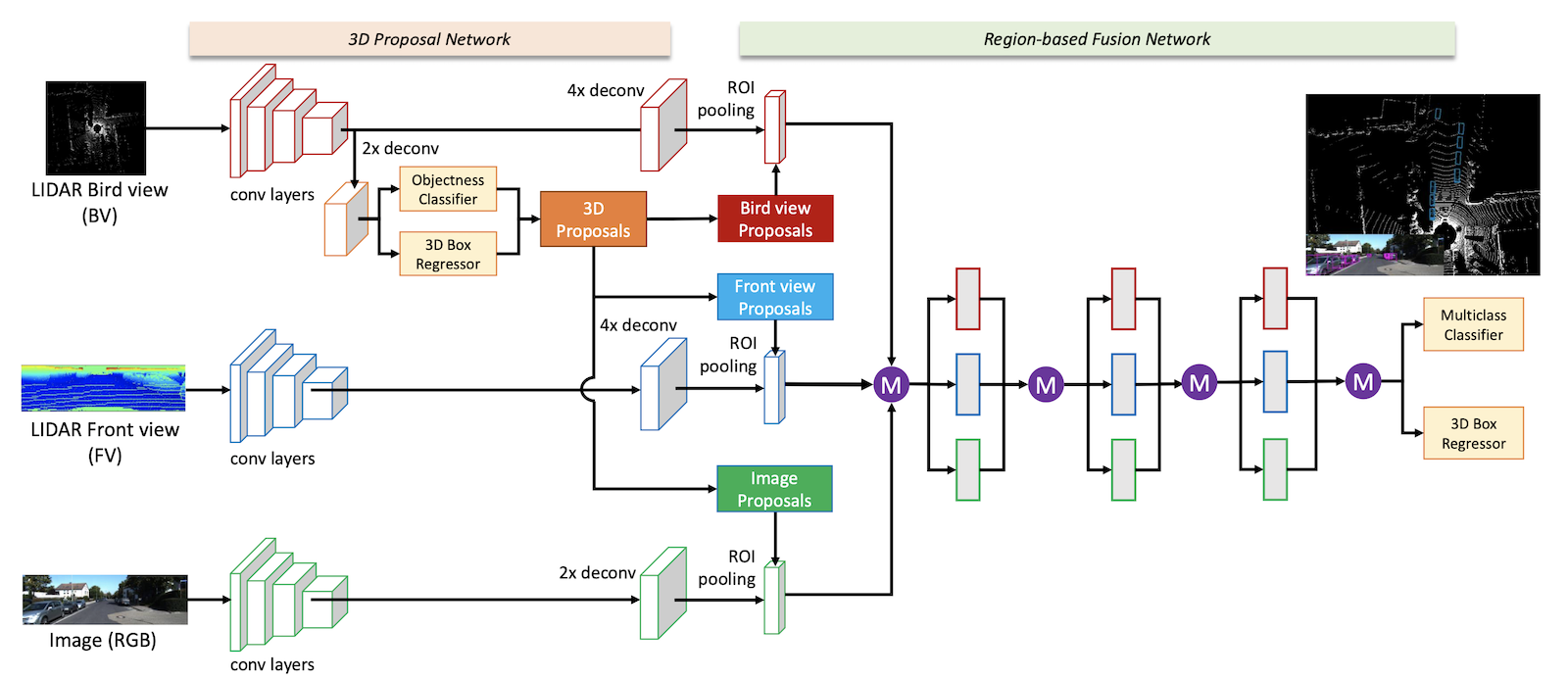
(출처 : Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3d object detection network for autonomous driving. In Proc. IEEE Conf. on Computer Vision and Pat- tern Recognition (CVPR), 2017)
위 그림에 나온 구조가 두가지 데이터를 처리하는 대부분의 모델이 사용하는 구조입니다. 각 데이터별로 CNN에 넣어 특성맵을 추출한 뒤 원소 단위로 평균값을 낸다든지 더한다든지 하는 방식으로 Fusion해 하나의 출력값으로 만드는 방식이죠.
여전히 아쉽다!
두가지 데이터를 이용하는 방식은 한가지 데이터를 사용하는 방식보다 성능이 좋았습니다. 허나 여전히 단점이 있었습니다.
바로 도심 속 운전같이 복잡한 상황에서 운전하기 힘들다는 점이었습니다.
교차로에서 운전할 때를 고려해봅시다. 위에 제가 올린 사진과 같은 상황이죠. 여기서 자율주행을 하는 자동차(Ego-Vehicle)는 왼쪽에서 오는 자동차(Traffic)과 신호등의 신호(Traffic Lights) 사이의 연관성을 고려하며 운전을 해야합니다. 허나 각 데이터별로 특성맵을 추출하면 특성을 추출하는 과정에서 모든 정보를 고려할 수 없게 됩니다.
즉, 모든 정보를 고려하지 않고 얻어낸 정보를 가지고 운전하기 때문에 사고가 날 확률이 높은 것이죠.
이는 데이터의 문제가 아니라 데이터를 처리하는 모델 구조의 문제였습니다.
Transformer
그래서 저자는 Attention mechanism만 사용해 데이터를 처리하는 Transformer를 특성 추출 과정에서 사용하기로 했습니다.
Transformer의 self-attention는 입력 값의 각 원소가 전체적인 입력값의 어느 부분을 더 주목해야 하는지 반영하게 해주니 이를 이용해 이미지와 LiDAR 데이터를 전체적으로 고려하며 특성맵을 추출하는 방식을 생각한 것입니다.
"두가지 데이터를 어떤 방식으로 합쳐서 사용하지?" 에 대한 답변은 Transforemr였습니다.
Single-view image and LiDAR inputs
그리고 "두가지 데이터로 어떤걸 선택하지?"에 대한 답변을 해야합니다.
저자는 이에 "Single-view image and LiDAR를 입력 데이터로 사용한다"고 말했습니다.

이 둘을 사용하겠다는 것이죠.
왜 Single-view image and LiDAR를 선택한 걸까요? 저자는 이 둘이 서로가 서로에게 부족한 점을 채워주는 상호보완성이 있기 때문에 선택했다고 말했습니다.
즉, 이 둘을 입력데이터로 사용해 얻는 정보의 양이 제일 많다고 판단한 것이죠.
Transfuser
이제 저자가 생각해낸 모델을 정리해봅시다.
입력 데이터로 Single-view image and LiDAR를 받아 특성을 추출하는 과정에서 Transformer를 사용해 전체적인 정보를 고려하는 모델
한문장으로 간단히 정리됩니다. 저자는 이렇게 설계된 모델을 Transfuser라고 정의했습니다.
여기까지 모델의 Introduction 부분이었습니다. 깔끔히 쓰고 싶었는데 쉽지않네요. 허허...
그럼 이제 Transfuser가 포함된 자율주행 모델이 만들어지는 과정을 소개한 Method 항목을 소개해 드리도록 하겠습니다.
Method
원래 Releated work를 슥 살펴보고 Method로 넘어가야 하는데 그러면 분량이 너무 많아져서 바로 Method로 건너왔습니다. 저도 자율주행 모델에 대해 잘 감이 안잡힌 상태에서 이 논문을 읽어서 Related work 부분이 논문 이해에 꽤나 도움이 되었습니다. 관심 있으신 분들은 따로 찾아서 읽어보시는걸 추천드립니다.
아무튼, 이제 Method에 대해 설명해 드리도록 하겠습니다.
Method에는 Transformer를 이용해 자율주행 모델을 만드는 일련의 과정이 적혀있습니다.
모델을 만드는 과정은 다음과 같이 3단계로 나눌 수 있습니다.
- Task 설정, 데이터셋 구성(Problem Setting)
- 데이터셋 전처리(Input and Output Parameterization)
- 모델 설계(Multi-Modal Fusion Transformer + Waypoint Prediction Network)
그러면 'Task 설정'부터 설명해 드리도록 하겠습니다.
1. Problem Setting
모델이 해결할 Task를 설정하고 이를 위한 학습법, 그리고 필요한 데이터셋을 설명하는 부분입니다.
저자는 point-to-point navigation를 모델이 수행할 Task로 설정했습니다.
저자는 point to point navigation이 목표지점까지 waypoint를 따라 사고 없이 완주하는 것이라 말했습니다. 여기서 사고는 다른 객체(자동차, 사람 등)과 충돌하거나 교통법규를 어기는 것을 말하죠.
그리고 이를 학습하는 방법으로 imitation learning을 선택했습니다. imitation learning이란 강화학습의 일종인데요, 의미 그대로 해당 task에서 전문가(Expert)가 하는걸 따라하는 학습법입니다.
강화 학습은 학습 주체인 agent와 agent가 행동하는데 규범이 되는 policy, 행동의 결과인 action, action으로 인한 상태 state, 그리고 state에 대한 보상 reward가 있습니다.여기서 보상 reward를 가장 많이 받는 방향으로 학습시키는 것이 목표죠.
reward를 많이 받도록 만드는 방식은 여러가지가 있습니다. 그중 하나가 행동 규범힌 policy를 학습가능한 상태(parameterize)로 만드는 것이죠.
imitation learning도 그 방식을 사용하고 있으며 논문에서는 다음과 같이 설명합니다.
Policy를 Expert의 policy를 따라하게끔 학습하는 것
그런데 여기서 궁금증이 생겼습니다. 왜 imiation learning을 선택한거지? 그래서 찾아봤습니다.
찾아보니까 이렇게 policy를 학습 대상으로 삼아 학습시키는 방식은 고차원 데이터를 처리하고 연속된 action을 해야하는 모델의 학습에 적합하다고 합니다.
이미지라는 고차원 데이터를 처리해 연속된 action이 필요한 운전을 하는 자율주행 모델에 적합한방식이라 선택한게 아닌가 싶습니다.
그러면 이제 저자가 imitation learning을 사용한 학습과정을 설명해 드리도록 하겠습니다.
데이터셋 수집
우선 데이터셋을 수집해야하죠? 학습을 위한 학습 데이터셋과 평가를 위한 테스트 데이터셋이 필요합니다.
데이터셋은 자율주행 오픈소스 시뮬레이터 CARLA(https://carla.org)에 있는 가상 환경에서 수집
합니다. 별다른 이유는 적지 않았지만 아무래도 사고가 날 수 있는 상황에 대한 데이터도 모으기 때문에 그런게 아닌가 싶네요.
여튼, CARLA에 있는 가상환경에서 Expert가 주행하며 데이터를 모읍니다. imitation learning에서 말씀드린 Expert 맞습니다.
Expert는 가상환경을 주행하며 입력 데이터와 출력 데이터를 수집합니다. 그렇게 해서
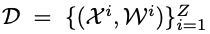
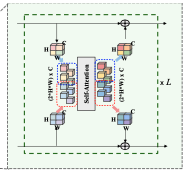
위와 같은 데이터셋 D를 만들어줍니다.
여기서 X는 전면 카메라 이미지와 LiDAR에서 얻은 Point cloud로 구성되어 있습니다. 한 시점(single time step)에 이미지 한장, point cloud 하나가 있는 것이죠.
그리고 W는 T개의 waypoint가 모인 w로 이루어져 있습니다. 즉, 이미지와 point cloud를 하나씩 넣으면 출력값으로 T개의 Waypoint가 나오는 모델을 만들겠다는 뜻이죠.
학습 방법
이렇게 데이터셋을 모았으니 학습을 시켜봅시다. 학습 방식은 다음과 같이 정의할 수 있습니다.
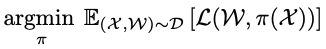
여기서 L은 Loss함수입니다. 그러니까 Expert가 주행한 경로와 우리가 만든 agent의 policy에 따른 action, 다시 말해 우리가 만든 모델이 예측한 주행 경로 사이의 loss가 최소가 되게끔 policy를 학습시키겠다는 뜻이죠.
저자는 이러한 학습 방식을 지도학습의 방식이라고 말했습니다. Expert의 데이터를 label data, 내가 만든 모델의 데이터가 prediction data라고 보면 저자의 말이 이해가 되시지 않을까 싶습니다.
그래서 강화학습은 어떻게 학습 시키는걸까 찾아봤습니다. 강화학습은 데이터셋을 사용하지 않고 학습하기 때문에 매 순간 자기 자신이 만든 state와 reward를 보고 다음 action에 반영하며 점점 높은 reward만 받는 모델로 학습되는 방식을 사용한다는 사실을 알아냈습니다. 지도학습으로만 모델을 학습시켜본 저에게 있어서 강화학습은 상당히 신기한 방식입니다.
자율 주행
저자는 학습 이후 어떻게 자율주행에 사용할지도 설명해 주었습니다.
저자는 모델이 예측한 경로를 inverse dynamics model에 넣어 얻은 action으로 주행을 한다고 말했고 이 때 inverse dynamics model을 PID controller로 구현했다고 설명했습니다.
PID controller는 간단한게 말해 주어진 출력값을 위해 필요한 제어값(가속, 감속, 회전 등)을 구하는 요소라고 보시면 됩니다. 자세한 설명은 여기서 확인하실 수 있습니다.
저자는 이러한 과정을 다음과 같은 식으로 나타냈습니다.
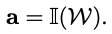
action = PID(예측 경로)인 것이죠. 여기서 action은 agent가 행한 action과 동일한 개념입니다.
Global planner
마지막에 등장하는 문단인데 처음에는 이게 왜 있는건가 싶었습니다.
읽어보니 저자들은 CARLA의 표준 프로토콜을 따르고 목표 지점이 GPS 좌표로 제공되며 목표 지점과 자동차가 안내한 지점이 몇백미터 떨어질 수 있다고 나와있습니다.
다른 부분은 그러려니 하고 읽었는데 마지막 부분 '목표 지점과 안내 지점이 몇백미터 떨어질 수 있다'는 말이 거슬렸습니다. 도대체 뭔 뜻이지?
제가 논문 세미나를 할 때 이 논문을 가지고 했는데요, 이에 관해 세미나 계신 분들께 여쭤보고 답을 들었는데도 이해가 제대로 안되서 구글에 검색까지 해봤습니다.
구글에 검색을 해보니 다음과 같은 글을 발견했습니다.
The global planner plans a global path around obstacles
대충 번역하면 장애물을 돌아가는 global path를 생성하는게 global planner라고 하네요.
아마 목표 지점에 가기 힘들면 그 근처로 안내할 수 있음을 말하고 싶어서 이 부분을 추가한게 아닌가 싶습니다.
여기까지 Problem Setting이었습니다.
2. Input and Output Parameterization
이제 데이터셋을 어떻게 만들었는지? 정확히는 모델의 학습에 사용하기 위해 어떤 작업을 했는지 설명해 드리도록 하겠습니다.
Input Representation
우선 입력 데이터부터 설명해 드리고자 합니다.
입력 데이터는 앞서 말씀드렸듯 전면 카메라 이미지와 LiDAR에서 얻은 Point cloud로 구성되어 있습니다. 카메라 이미지는 2D 데이터고 Point cloud는 3D 데이터라 각자 처리방식이 다릅니다.
-
카메라 이미지
카메라에서 촬영된 이미지는 400X300 사이즈인데요, 여기서 가운데 256X256 영역만 추출해서 사용합니다. 왜냐하면 렌즈 구조상 외곽 이미지는 왜곡 되어있기 때문입니다. 이렇게 256X256X3 사이즈의 데이터를 얻습니다. -
LiDAR Point Cloud
저자는 LiDAR에서 얻은 Point Cloud 중 자동차의 전면 32m, 좌우 측면 각 16m씩 해서 총 32m X 32m 영역만 사용합니다. 그리고 이를 2D 데이터로 변환해주는데요, 한 셀당 0.125m X 0.125m로 해서 256 X 256 픽셀 데이터로 변환해줍니다.
그리고 Point Cloud는 3D 데이터라 높이에 관한 데이터도 있는데요, 저자는 이를 2개의 채널에 담았습니다. 하나는 지면 위(+) 높이 데이터, 다른 하나는 지면 밑(-) 높이 데이터를 담았죠.
이렇게 256X256X2 사이즈의 데이터를 얻습니다.
Output Representation
출력값 양식을 정의하는 부분입니다.
출력값, 즉 waypoint는 BEV space에서 (x,y)의 양식을 지닙니다.
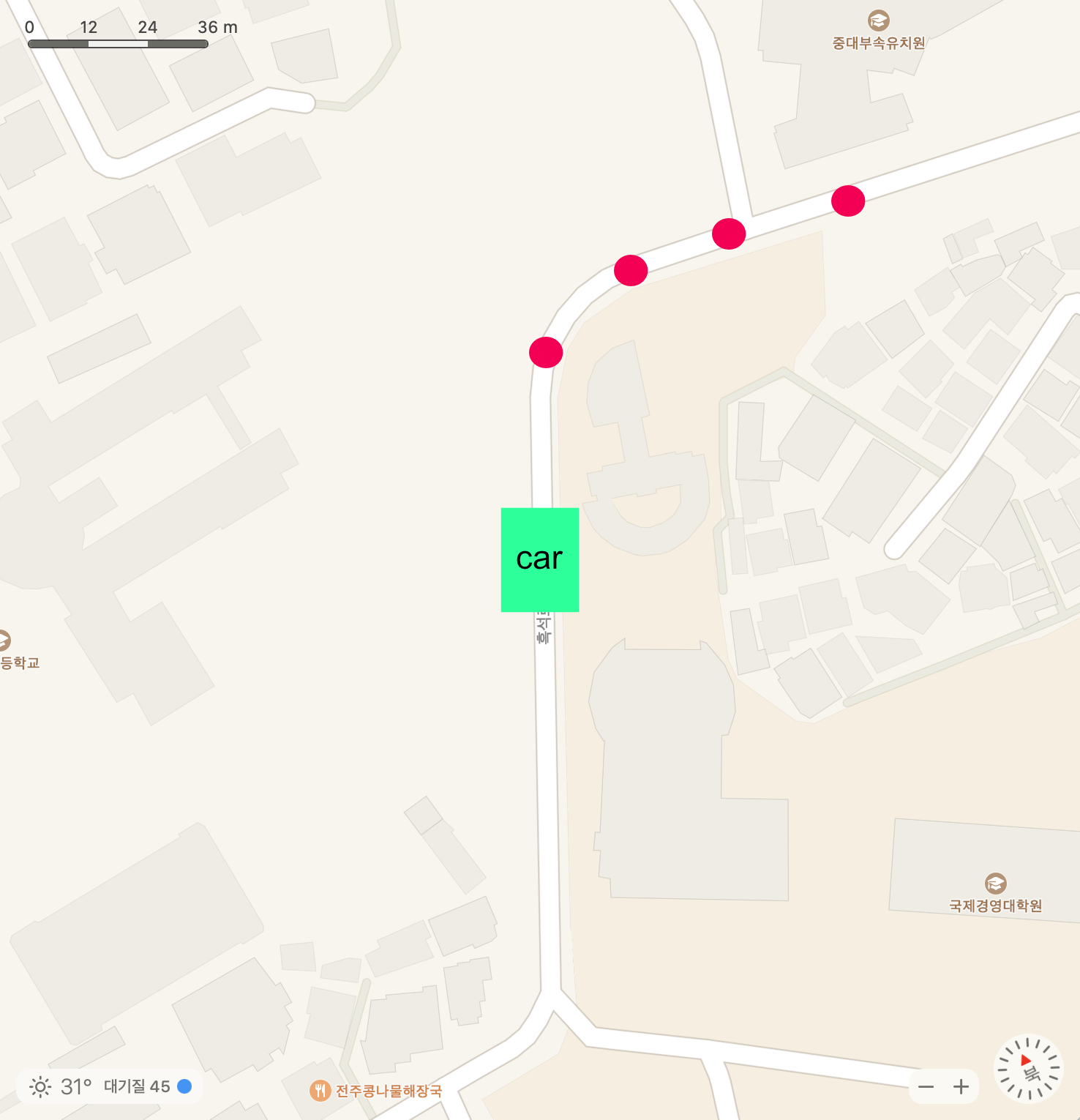
이런 방식으로 나온다는 뜻이죠. 중심에 자동차가 있고 앞에 빨간 점으로 자동차가 이동할 waypoint가 나와 있습니다. 이 때 waypoint의 집합 trajectory는 다음과 같이 정의됩니다.
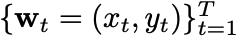
앞서 데이터셋을 구성할 때 T개의 waypoint 예측값이 모인 데이터셋을 만든다고 말씀드렸는데요, 저자는 T를 4로 정의했습니다. 왜 T를 4로 정의했냐면 예측 궤적을 가기 위한 제어값을 얻는 PID controller가 요구하는 waypoint의 default number가 4라서 T를 4로 설정했다고 말했습니다.
여기까지 Input and Output Parameterization였습니다.
3. 모델 설계
다음으로 모델의 구조에 대해 설명해 드리고자 합니다.
모델의 구조는 크게 두 가지로 나눌 수 있습니다. 하나는 Multi-Modal Fusion Transformer고 다른 하나는 Waypoint Prediction Network입니다.
Multi-Modal Fusion Transformer는 저자가 새로운 제안한 Transfuser를 말하는 것이구요, Waypoint Prediction Network는 Transfuser에서 얻은 값을 가지고 경로를 예측하는 모델입니다.
우선 Transfuser부터 먼저 설명해 드리도록 하겠습니다.
1. Multi-Modal Fusion Transformer(Transfuser)
Transfuser는 다음과 같은 구조를 가지고 있습니다.
제가 Trnafuser는 특성을 추출하는 과정에서 Transformer를 이용해 전체 데이터를 고려하는 모델이라고 말씀드렸는데요, 이 그림을 보시면 "아...이런 뜻이구나" 이해하시지 않을까 싶습니다.
여기서 눈여겨볼 항목은 당연히 저자가 강조한 Transformer를 이용해 전체 데이터 정보를 각 특성맵에 반영해주는 부분입니다.
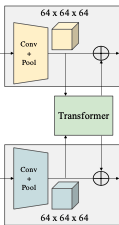
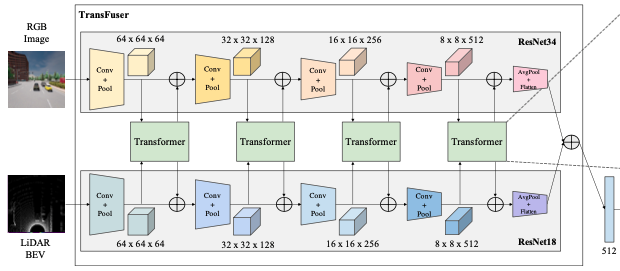
이 부분을 말하는 것이죠. 아래 그림은 윗 그림에서 Transformer 부분을 강조한 그림입니다.
여기서 진행되는 연산의 순서를 말씀드리면 다음과 같습니다.
- Conv + Pool 연산으로 특성맵 추출
- 추출한 특성맵의 사이즈를 8 X 8로 압축 후 Transformer에 입력값으로 보냄
- 각 데이터에서 보내준 8 X 8 크기의 특성맵 2개를 합체 = 16 X 8 사이즈의 특성맵 생성
- 16X8 벡터를 Positional Embedding 후 Linear layer를 이용해 자동차의 현재 속도를 Embedding vector에 projection
- Transformer에 넣어 self-attention 연산 => Embedding vector내 원소별로 전체 데이터(이미지 + LiDAR)에 대한 Attention이 반영됨. 사이즈는 16 X 8로 같음
- Attention이 반영된 Embedding vector를 Image, LiDAR별로 나눔 -> 8 X 8 사이즈의 벡터가 2개 생성
- 8 X 8 사이즈의 벡터를 압축하기 전의 크기로 scale up
- 원래 특성맵과(1에서 추출한 특성맵) element-wise summation(원소끼리 더함)
코드로 나타내면 상당히 간단해집니다.

아무튼 간단해집니다.
여튼, 이런 과정을 총 4번 반복합니다. 더 해도 안된다는 법은 없는데 저자는 4번 반복하라고 말했습니다.
4번 반복한 뒤 마지막에 Average Pooling + Flatten연산을 해서 1 X 1 X 512 벡터를 2개 생성합니다. 이미지에서 얻고 LiDAR에서 얻으니까 총 2개를 얻는 것이죠.
이 2개의 벡터를 element-wise summation해서 하나의 1 X 1 X 512 벡터로 만들어줍니다.
이렇게 우리는 최종 출력값 1 X 1 X 512 벡터를 얻었습니다. 이제 Waypoint Prediction Network를 확인해보도록 합시다.
2. Waypoint Prediction Network
앞서 우리는 Transfuser에서 1 X 1 X 512 사이즈의 벡터를 얻었습니다.
이 벡터는 Waypoint Prediction Network에 쓰입니다.
Waypoint Predictoin Network는 다음과 같은 구조를 가지고 있습니다.
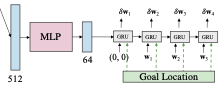
보시면 MLP와 GRU로 이루어졌다는 사실을 확인하실 수 있습니다.
-
MLP
MLP는 3개의 Linear Layer로 이루어져 있습니다. MLP는 입력값으로 들어오는 1 X 1 X 512 사이즈의 벡터를 1 X 1 X 64 벡터로 압축해줍니다. 계산의 효율성을 위해 줄여주는 겁니다.
코드는 다음과 같습니다.

-
GRU
GRU는 RNN에서 많이 쓰였던 LSTM을 개선한 알고리즘 입니다. 시계열 데이터를 처리하는데 적합한 알고리즘이죠. 이걸 레이어 형식으로 추가했습니다.
GRU는 현 시점의 입력 데이터와 hidden state를 받아 연산을 처리합니다. waypoint prediction network에서는 자동차의 좌표와 목표 지점의 좌표를 더한 값을 입력 값으로 하였습니다. 이 때 좌표의 단위는 gps입니다.
여기서 흥미로운 점이 있습니다. 바로 첫 시점의 입력 데이터 중 자동차의 좌표가 (0,0)이라는 점입니다. 이는 자동차가 좌표계의 원점에 있다고 가정했기 때문입니다.
그러니까 입력 데이터를 넣는 시점에서 자동차의 위치가 x = (0,0)에 있다고 보는 것이고 (0,0)를 기준으로 향후 4 time의 waypoint를 예측하는 것이라 보시면 되겠습니다.
다시 본론으로 돌아옵시다. 입력 데이터를 알아봤으니 이제 hidden state로 넘어가야죠. hidden state는 앞서 얻은 1 X 1 X 64 벡터로 초기화해줍니다. 우리가 입력 데이터로 얻은 특성을 hidden state를 초기화하는데 사용하는 겁니다.
이렇게 입력값을 넣어주면 출력값이 나올겁니다. 이 출력값을 Linear layer에 넣으면 현 시점의 자동차에서 움직여야할 좌표 dx가 생성됩니다.
이 dx에 기존 자동차의 좌표 x에 더하면 이제 다음 시점에 이동할 waypoint가 되는 겁니다.
이 waypoints는 다음 시점에서 현재 좌표가 되겠죠? next_x = x + dx인 겁니다.
여튼 이 과정을 4번 반복해 waypoint 4개를 얻습니다.
Plus : PID controller
모델의 구조에는 없지만 자율주행을 수행하기 위해 꼭 있어야할 PID controller입니다.
앞서 예측한 경로를 PID controller에 넣어 주행에 필요한 제어값을 얻는다고 말씀드렸습니다.
실은 그 이상으로 설명드릴게 없습니다. 그러니 여기서는 구현된 코드를 보여드리고 넘어가도록 하겠습니다.

코드의 return 부분을 보시면 운전에 필요한 데이터들이 나와있습니다. steer는 차를 얼마나 회전할지 나타낸거고 throttle는 엔진에 들어갈 공기량을 제어하니까 가속을 얼마나 할지 나타낸거고 brake는 감속을 얼마나 할지 나타내는 것이죠.
그런데 낯선 데이터가 하나 있습니다. 바로 metadata입니다. 슥 살펴보니 steer, throttle, brake만으로 설명이 안되는 정보를 보충 설명해주는 데이터인듯 합니다. 아마 저자가 실험했을 때 제어값의 정보 부족으로 좀 애먹었던게 아닌가 싶네요. 제 추측입니다.
여기까지 모델의 구조를 살펴봤습니다.
Experiment
이제 실험 부분을 설명해 드리고자 합니다.
여기서는 실험 세팅(experimental setup), 성능 비교(Results), 입력 데이터간 상호보완성 비교(Attention Map Visualizations), 구성 요소를 하나씩 빼면서 성능 확인(Ablation Study) 순으로 내용이 전개됩니다.
1. 실험 세팅(experimental setup)
여기서는 성능 측정을 위해 모델이 해야할 task와 이를 위해 필요한 데이터셋, 평가 지표와 성능을 비교할 모델을 소개하고 있습니다.
Task
모델이 수행할 task는 다양한 주행 환경에서 제한 시간 안에 운전 규정을 시키며 주행하는 것입니다.
여기서 주행 경로는 gps좌표 형식의 waypoint의 집합으로 제공되며 주행 도중에 일정 확률로 자동차나 보행자가 등장할 수 있고 차선 변경, 회전 등 주행 중에 충분히 일어날 수 있는 상황도 경로에 포함되어 있습니다.
앞서 논문에서 말한 '복잡한 운전 상황'속 주행 성능을 평가하는거라 생각하시면 됩니다.
Dataset
데이터셋을 모으는 방법이 적혀있습니다.
앞서 말씀드렸듯 Expert가 CARLA에 있는 가상환경에서 주행하며 데이터를 모은다고 말씀드렸습니다. 여기서 더 자세히 써보도록 하겠습니다.
CARLA에는 주행을 할 수 있는 8개의 Town이 있습니다. 8개의 가상환경이 있는 것이죠. 각 town의 특성은 다음과 같습니다.

각자 특성을 가지고 있죠. Expert는 여기서 Town 01, 02, 03, 04, 06, 07, 10에 사전 정의된 경로들을 달리며 학습용 데이터셋을 수집합니다.
그리고 학습용 데이터셋으로 모델을 훈련시키고 난 뒤 Town05에서 주행 성능을 평가합니다.
Town05는 1차선부터 n차선, 그리고 일반도로부터 고속도로까지 다양한 도로가 있기 때문에 주행 성능을 평가하는 맵으로 선정했다고 말했습니다.

Town05에 깔려있는 도로를 나타낸 사진입니다. 다양한 도로로 구성되어 있음을 확인할 수 있습니다.
저자는 어떠한 주행 경로에서 성능을 평가하는지도 설명했습니다. 저자는 단거리 경로와 장거리 경로를 각 10개씩 뽑았고 이를 Town05 Short, Town05 Long이라 이름 지었습니다. 특징은 다음과 같습니다.
- Town05 Short : 주행 거리 100~500m, 교차로 3개
- Town05 Long : 주행거리 1~2km, 교차로 10개
그리고 주행 중에 자동차나 사람이 등장할 수 있다는 공통점이 있습니다.
마지막으로 날씨입니다. 맑은 날 주행하는거랑 비오는 날에 주행하는건 난이도가 어느정도 차이가 나는데요, 저자는 동적인 객체와 신호등에 대한 주행 성능 평가에 집중할 것이기 때문에 날씨는 '항상 맑음'으로 고정한다고 말했습니다.
개인적으로 아쉬운 부분이었습니다. 날씨도 변수를 줘서 실험을 했으면 더 좋지 않았을까 생각합니다.
Metrics
구글에 검색해보니 '측정 수단'이라는 뜻으로 해석됩니다. 즉, 평가지표입니다.
저자는 평가 지표로 RC, DS, Infraction Count를 선택했습니다. 하나씩 설명해 드리도록 하겠습니다.
- RC(Route Completion) : 주행 경로를 몇%나 주행했는지 나타내는 수치입니다.
- DS(Driving Score) : RC에 infraction multiplier를 곱한 값입니다. 여기서 infraction multiplier는 객체와의 충돌, 경로 이탈, 차선 침법, 신호 위반을 설명하는 수치라고 합니다.
- Infraction Count : 따로 설명은 해놓지 않았지만 사고 종류별 발생 횟수를 측정한게 아닐까 싶습니다.
Baselines
Transfuser가 포함된 자율주행 모델과 성능을 비교할 모델을 적어놓았습니다. 5개의 모델과 비교합니다.
모델 종류는 다음과 같습니다.
- CILRS : 카메라 이미지만 입력값으로 받으며 navigational command의 통제 아래 자율주행을 수행합니다.
- LBC : 원래 Bird's view image와 front image를 받았는데 논문(LBC)의 저자가 왼쪽 45도, 오른쪽 45도 각도에서 찍은 전면 카메라 이미지와 target heatmap을 입력값으로 받는걸로 바꿨습니다.
- AIM : 전면 카메라 이미지만 입력데이터로 받습니다. 단일 입력값을 받는 모델 중 가장 성능이 좋습니다.
- Late Fusion : 이제부터 두가지 입력값을 함께 처리하는 모델입니다. Late Fusion은 image와 LiDAR에서 얻은 값을 각각 Convolution Layer로 특성맵을 뽑아낸 후 element-wise summation해줍니다.
- Geometric Fusion : image와 LiDAR에서 얻은 값을 각각 Convolution Layer로 특성맵을 뽑을 때마다 서로 projection해 서로의 정보를 반영합니다. 이렇게 뽑은 두 특성맵을 element-wise summation 해줍니다.
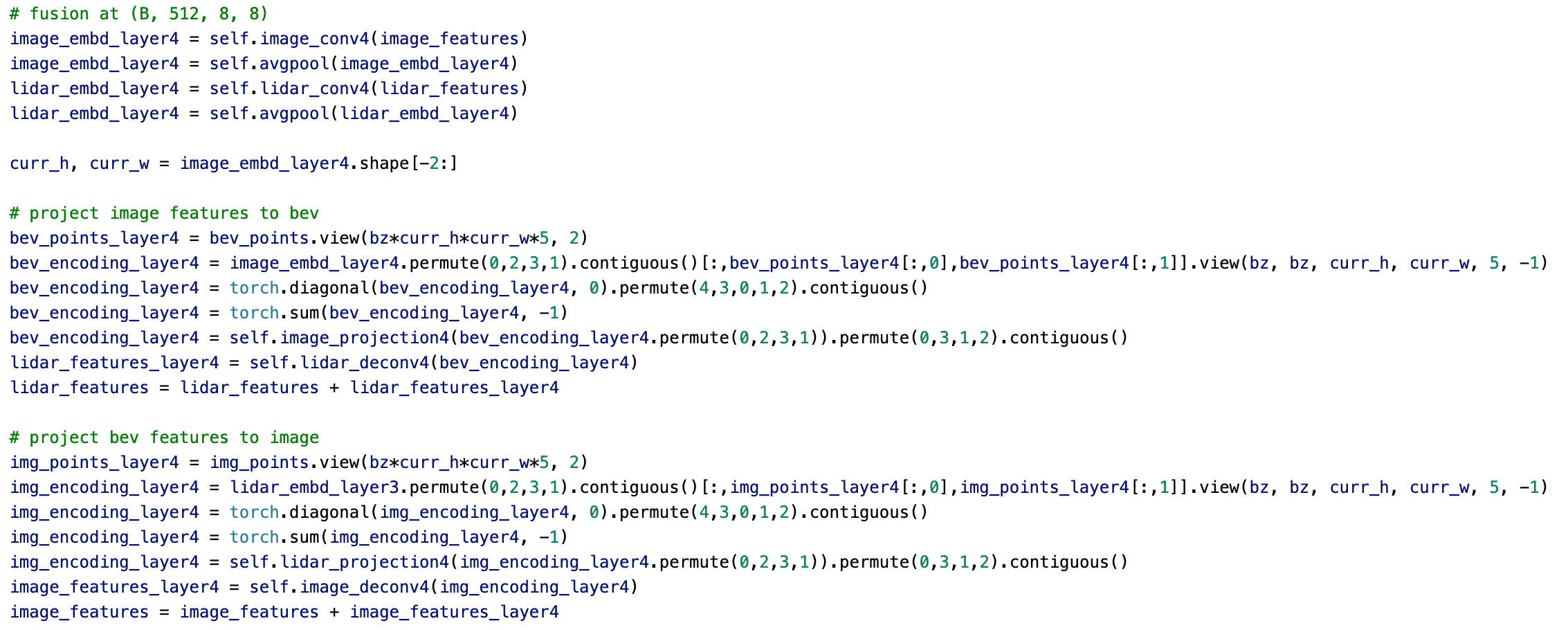
위 사진은 구현코드입니다. 보시면 각자 특성을 추출 후 서로 projection하는걸 확인하실 수 있습니다.
2. 실험 결과(Results)
실험 결과는 다음과 같습니다.
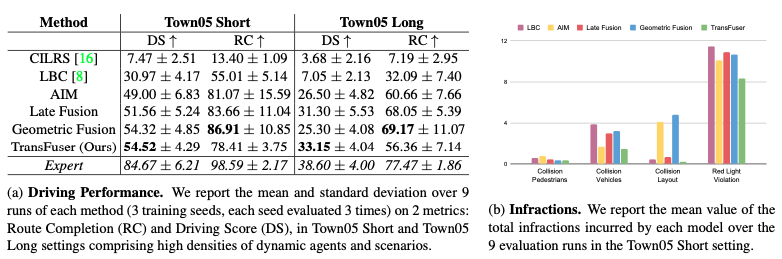
왼쪽 사진은 Short, Long 경로에서 모델별 RC, DS를 나타낸거고 오른쪽 사진은 사고율을 나타낸 겁니다.
Driving Performance
우선 왼쪽 표에 대해서 설명을 해드리도록 하겠습니다.
여기서 눈여겨볼 부분은 한가지 입력값을 받는 CILRS, LBC, AIM보다 두가지 입력값을 받는 Late Fusion, Geometric Fusion, Transfuser의 성능이 더 좋다는 겁니다. 두가지 입력값을 쓰기만 해도 한가지 입력값을 쓰는 것보다 성능이 좋다는 사실을 알 수 있습니다.
그리고 또다시 눈여겨볼 부분은 Transfuser가 Late Fusion, Geometric Fusion보다 RC는 낮은데 DS가 높다는 것입니다. 즉, Transfuser는 주행 거리는 짧지만 안전운전을 더 잘한다는 뜻이죠.
저자는 이를 보고 'Late Fusion, Geometric Fusion는 안전하게 운전하는 것보다 목표 지점에 가는데 중점을 뒀기 때문에 이런 결과가 나왔다'고 말했습니다.
그리고 Expert의 점수도 나와있는데요, Expert도 장거리 운전에서는 그리 좋지 못한 성적을 얻었습니다. 신기합니다.
Infraction
모델별 평균 사고율이 나옵니다. 초록색 막대가 Transfuser인데요, 모든 사고 항목에서 가장 낮습니다. 그런데 빨간불 신호 위반에서 다른 모델보다 낮긴 하지만 그래도 다른 사고 항목에 비하면 굉장히 높은 수치를 보입니다. 왜 그런걸까요?
Limitations
여기선 모델의 한계점에 대해 저자가 얘기하는 부분입니다. 저자는 모델의 한계점으로 빨간불 신호 위반의 확률이 높은 것을 꼽았습니다.
높은 신호위반 확률을 보이는 이유는 성능 평가를 위해 주행하던 경로에서 신호등이 카메라 구석에 찍혔는데 이 때문에 신호등의 빨간 불빛을 감지하기가 힘들어 빨간불에서 정차하지 않고 주행하는 일이 많았다고 합니다.
그리고 이러한 문제를 해결할 additional supervision을 기대해본다고 말했습니다.
3. Attention Map Visualizations
여기서는 카메라 이미지와 LiDAR point cloud간 상호보완성을 보여줍니다.
어떻게 보여주냐면 교차로에서 신호대기중인 차량에서 얻은 이미지, Point cloud를 Transfuser로 특성을 추출하는 과정에서 self-attention을 통해 나온 16X8 사이즈의 벡터를 통해 설명합니다.
여기서 반은 이미지쪽 벡터고 나머지 반은 LiDAR쪽 벡터입니다. 여기서 각각 자동차와 신호등에 대한 정보가 담긴 부분만 추출해 서로 얼마나 attention을 했는지 확인해봅니다. attention이 반영된 정도는 각 요소별 곱해진 score를 보고 알 수 있죠.
그렇게 attention된 정도를 확인한 결과, 다음의 사실을 알 수 있었습니다.
- 이미지 토큰의 62.75%가 attention을 가장 많이 한 5개의 token이 LiDAR에서 나온 토큰
- LiDAR 토큰의 78.45%가 attention을 가장 많이 한 5개의 token이 이미지에서 나온 토큰
여기서 토큰은 transformer에 입력값으로 들어가는 데이터 단위를 말합니다. 출력값 역시 토큰의 집합이죠. 토큰을 데이터로 바꾼 뒤 읽으셔도 의미의 차이는 없을듯 합니다.
아무튼, 이렇게 서로 상호보완하는 부분이 많습니다. 특성을 추출할 때 상대 데이터를 많이 고려한다는 뜻이죠.
4. Ablation Study
여기서는 Transfuser의 Transformer에 대해 값을 수정해가며 성능의 변화를 관측한걸 얘기합니다. 저자는 Town05 Short에서 성능 평가를 했는데요, 성능표는 다음과 같았습니다.
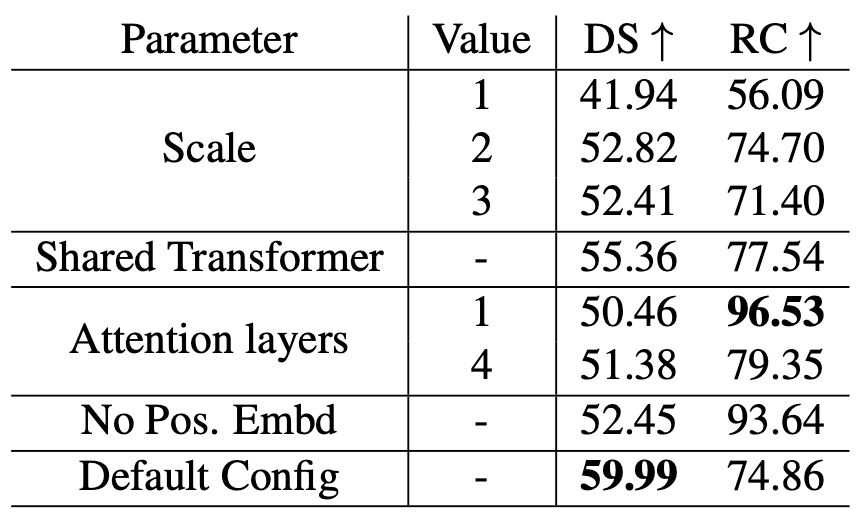
하나씩 설명해드리도록 하겠습니다.
- Scale : Transformer 이후 Fusion 횟수를 나타냅니다. 원래 4번 Fusion했는데 이 횟수를 줄여보며 성능을 비교해봤습니다. Scale이 1이면 마지막에 추출한 feature map(8X8X512)에서만 fusion하고 2면 16X16X256 feature map과 8X8X512 feature map에서 fusion하는거죠.
- Shared Transformer : 원래 각 사이즈의 특성맵마다 다른 Transformer를 사용합니다. 그러면 모든 특성맵에서 다같은 Transformer를 사용하면 어떻게 될까요? 성능이 떨어졌습니다. 저자는 각 convolution layer에서 얻은 특성맵이 갖고 있는 성질이 다 다르기 때문에 각기 다른 Transformer에서 처리해야 한다고 말했습니다.(different convolutional layers in ResNet learn different types of features due to which each transformer has to focus on fusing different types of features)
- Attention layers : 원래 각 Transfomer에는 8개의 Attention layer가 있습니다. 이를 1개, 4개로 만든 뒤 성능을 측정해봤습니다.
- No Pos. Embd : Transformer에 넣기전에 Positional Embedding을 안했을 경우입니다.
이렇게 각 요소를 제거한 뒤 성능을 비교했습니다. Scale을 제외한 나머지 부분에서 하나의 공통점이 있는데요, 바로 RC는 증가하지만 DS가 떨어졌다는 점입니다.
저자는 이를 보고 'Attention횟수가 많아질 수록 더 조심히 운전하게 된다'고 말했습니다.
Conclusion
논문의 결말입니다. 저자는 앞서 말한 것을 conclusion에서 총체적으로 정리했습니다. 그리고 마지막에 자신들이 만든 모델에 다른 센서의 입력값을 추가해서 쓰거나 다른 AI task에 사용할 수 있다고 말하며 논문을 끝냈습니다.
후기
이렇게 길고 긴 논문 리뷰가 끝났습니다. 최선을 다해 리뷰해봤는데 미숙한 부분이 많았습니다. 이런식으로 데이터를 받아서 처리하는 모델도 처음 접했고 자율주행 task를 수행하는 모델도 처음이라 읽는데 많은 시간이 걸렸습니다. 그래도 리뷰하고 나니 뿌듯하네요.
3주 뒤에 다른 논문을 세미나에서 발표하는데 그 논문도 velog에 올릴 계획입니다. 개강이 얼마 남지 않은 시기라 쓰기 힘들겠지만 하...할 수 있겠죠?
마지막으로 제가 이 논문을 읽고 느낀점을 쓰고자 합니다. 제가 느낀 점은 다음과 같습니다.
-
두 종류의 입력값을 특성 추출 과정에서 반영함으로써 안전한 운전을 구현했다는 사실이 흥미로웠다.
-
허나 Transformer가 전체 입력값을 모두 고려하며 계산하기 때문에 연산량이 좀 많을텐데 실시간으로 판단이 필요한 운전에서 이런 점이 부담이 되지 않을까 싶다.
-
추후 주행 속도도 개선하며 안전운전을 추구하는 모델이 나왔으면 좋겠다.
그리고 제가 이걸 세미나에서 발표했을 때 교수님께서 "꼭 두가지 데이터를 사용했어야 했을까, LiDAR에서 얻은 정보를 사용할 때 2D 데이터로 변환하는 과정에서 많은 데이터 손실이 있을텐데 그걸 감수하면서까지 사용할 이유가 있을지 모르겠다, 차라리 시야각이 넓은 이미지를 사용하면 데이터 손실도 없이 사용할 수 있지 않을까" 라고 저에게 말씀하셨습니다.
실은 저는 입력값에 대한 어떠한 의문도 가지지 않았는데 교수님의 말씀을 듣고 의문이 들었습니다. 실제로 표를 봤을 때
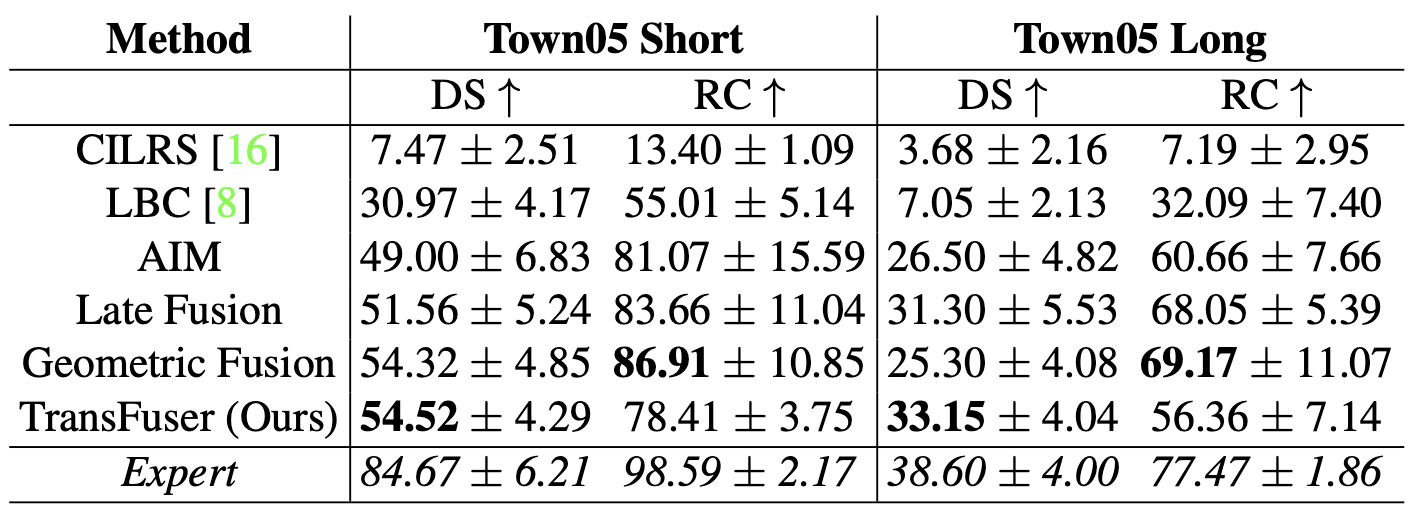
여기 보시면 한가지 입력값만 받는 AIM과 두가지 입력값을 받는 Late Fusion, Geometric Fusion, Transfuser의 성능차이가 크게 없다는 사실을 확인할 수 있습니다. 물론 장거리 주행에서는 DS에서 차이가 나긴 하지만 다들 점수가 낮기 때문에 큰 상관은 없다고 생각합니다.
아무튼, 많은 공부가 되었고 재밌게 읽은 논문이었습니다. 다음 논문 리뷰에서 뵙겠습니다!

꼼꼼한 논문 리뷰 잘 보았습니다. 저도 논문 리서치 중인데, 논문 리뷰는 이렇게 하는 것이군요.ㅎㅎ 본받아서 저도 열심히 조사해야겠어요. 감사합니다:)