안녕하세요. 밍기뉴와제제입니다.
오늘부터 공부했던 것을 정리해서 하나씩 올려보고자 합니다. 오래오래 했으면 좋겠습니다. 파이팅~~
이번에는 논문 리뷰를 할건데요, 제가 논문 구현을 하며 사용한 코드와 함께 리뷰를 하고자 합니다. 최대한 직관적으로 만들었기 때문에 이해하는데 도움이 되지 않을까 싶습니다.
Faster R-CNN?
이번에 소개할 논문은 한 사진에 있는 객체들을 찾는데 사용되는 알고리즘 중 하나인 Faster R-CNN입니다.

(Faster R-CNN의 모델 구조. 자세한 내용은 아래에서 다룹니다.)
AlexNet을 시작으로 컨볼루션 네트워크를 모델 설계에 넣은 CNN을 이용한 이미지 분석이 유행하기 시작했습니다. 그 이후로 나오는 컴퓨터비전 관련 논문에 나온 모델은 거의다 CNN기반이라고 할 수 있습니다. 그런데 요즘에 Attention Mechanism 등 다른 방식으로 컴퓨터비전 모델을 만들면서 CNN의 자리가 위협받고 있더군요. 어떻게 될려나요...껄껄.
아무튼, 컴퓨터비전 task에는 CNN을 많이 쓰고있습니다.
근데 얘가 '한 객체만 있는 이미지'를 판별하는 용도로 만들어졌어요. 허씨...그러면 한 사진에 여러개 객체가 있으면 어떻게 하죠?
그래서 만들어진게 R-CNN입니다. 엄청 유명한 논문이죠. R-CNN은 2단계를 거쳐 이미지 내에 있는 객체를 찾아냅니다. 정리하면 아래와 같습니다.
객체 탐지 방법:
-
객체가 있을 장소를 '대략적으로' 파악 -> Region of Interest(RoI) 선별
-
얻어낸 RoI를 CNN으로 판단해 어떤 객체인지, 정확한 위치는 어디인지 등을 판별 -> Object Detection
이렇게 2단계에 걸쳐 물체를 탐지하는걸 '2-stage detector'라고 합니다. 2-stage detector는 2개의 모델을 사용합니다. RoI를 찾는 모델과 RoI를 판단하는 모델 이렇게 2개가 있는 것이죠. 당연히 1-stage detector도 있습니다. 유명한 1-stage detector모델로는 'YOLO'가 있습니다.
R-CNN은 혁명과도 같은 모델이었습니다. 인용 횟수가 17908회(2021/5/12 기준)나 되니 향후 만들어진 Object Detector 모델의 뼈대가 되었다고 볼 수 있습니다.
혁명과 같은 R-CNN이었지만 큰 단점들이 몇가지 있었는데요, 그 중 하나가 찾아낸 영역을 따로 잘라내 CNN에 넣어서 특성을 찾아낸다는 겁니다.
CNN은 학습시킬 가중치 숫자가 적다는 장점이 있지만 연산에 시간이 좀 걸린다는 단점이 있습니다. 그런데 이 작업을 찾아낸 영역마다 수행했으니 정말 많은 시간이 걸렸습니다. 이미지 하나 넣었는데 합성곱 연산은 한 번만 한게 아니었다는 거죠.
그래서 사람들은 이러한 단점을 개선해 'Fast R-CNN'이란게 나왔습니다. 말 그대로 빠른 R-CNN인거죠.
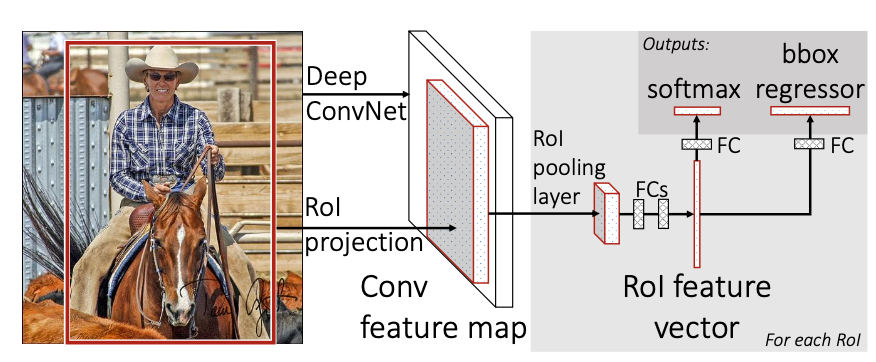
(Fast R-CNN)
Fast R-CNN는 ''어느 지점 까지는 같은 CNN에서 진행하자!'는 방법을 사용합니다. 저는 이걸 한강이 동쪽으로 쭉 흐르다가 탄천으로 빠지는 등 여러가지 작은 강들로 물살이 나뉘는 것에 비유하고 싶습니다.
어느 지점까지는 같은 모델에서 연산을 하니 연산 횟수가 확 줄어들겠죠? 실제로 Fast R-CNN은 Faster R-CNN보다 훨씬 빠른 연산 속도를 보여줬습니다.
허나 Fast R-CNN도 아쉬운 점이 있었습니다. Region Proposal을 할 때 Selective Search라는걸 사용했는데 이 모델은 CPU에서 돌아가서 속도에 한계가 있었습니다.
그래서 '어, 그럼 Fast R-CNN에서 Region Proposal을 하는 부분을 GPU에서 돌아가는 모델로 대체해볼까?'라는 아이디어에서 나온게 RPN(Region Proposal Networks)이고 RPN이 selective search을 대체한 Fast R-CNN이 바로 'Faster R-CNN'이 되겠습니다.
설명 순서는 다음과 같이 진행됩니다.
- 모델의 전체적인 구조
- RPN과 앵커, 훈련 방법, multi task loss
- Detector와 RoI Pooling Layer, 훈련 방법, multi task loss
- Faster R-CNN의 훈련 방법
큰 흐름은 위와 같으니 참고하며 읽으시면 되겠습니다.
전체적인 구조
우선 Faster R-CNN의 전체적인 구조는 다음과 같습니다.
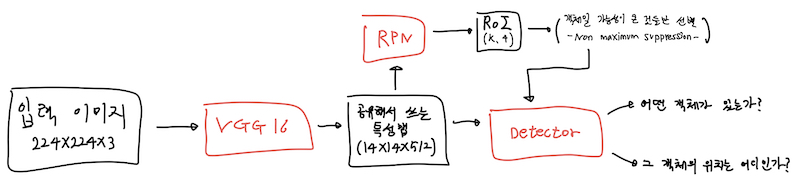
(Faster R-CNN의 구조)
논문에도 구조가 나와있긴 하지만 너무 두루뭉실하여 제가 구현을 통해 이해한 걸 바탕으로 모델 구조를 다시 그려봤습니다.
여기서 빨간 박스는 모델이고 검은 박스는 입, 출력값으로 사용되는 데이터들입니다.
Faster R-CNN의 흐름은 다음과 같이 정리할 수 있겠습니다.
Faster R-CNN의 구조:
- 입력 이미지(224x224x3)을 공유하는 CNN인 VGG16에 넣어 14x14x512의 공유 특성맵 휙득
- 공유 특성맵 14x14x512를 RPN에 넣어 (14x14xK)개의 RoI 휙득.
- 얻은 RoI를 non-maximum suppression (NMS) 기법으로 걸러냄
- 걸러낸 RoI와 공유 특성맵(14x14x512)을 Detector에 넣어 결과 휙득
꼭 입력 이미지가 224x224x3이고 공유 특성맵이 14x14x512일 필요가 없습니다. 저는 공유 CNN으로 VGG16을 사용했기 때문에 입력 이미지를 224x224x3으로 한 것이고 그 결과, 특성맵으로 14x14x512를 얻은겁니다.
Faster R-CNN에서 핵심은 RPN이라고 생각합니다. RPN은 GPU로 사용할 수 있다는 강점도 있지만 사물의 위치를 제안할 때 '앵커(Anchor)'라는 걸 사용하는데 이게 RPN의 핵심이라고 볼 수 있습니다.
RPN에서 얻은 RoI를 NMS로 걸러내는 작업을 한다고 적혀있습니다. 허나 이는 Test, 다시 말해 훈련된 모델을 사용하는 경우만 해당되면 훈련을 시킬 때는 NMS 대신 '이미지의 경계선을 넘지 않는' 모든 RoI를 훈련에 사용합니다. 자세한 내용은 추후 설명해 드리도록 하겠습니다.
RPN과 앵커
앵커는 '닻'이란 뜻입니다. 배가 한 곳에 머무를 때 다른 곳으로 이동하지 않을 용도로 닻을 바닥에 내리죠.
논문에서 말하는 앵커도 이와 비슷한 역할을 합니다.
우선 앵커를 준비해봅시다. 실제로 닻을 여러개 들고다니진 않겠지만 여기서는 여려개의 닻을 준비해야합니다. 논문에선 앵커를 'k'개를 이용하라고 나와있습니다. 우리도 k개를 챙겨봅시다. k개는 앵커의 비(1:1, 2:1 등)와 앵커의 너비(128, 256 등)을 통해 결정할 수 있습니다.
여기서 주목해야할 점이 있습니다. 바로 앵커의 크기입니다. 앵커의 크기는 크기가 줄어든 특성맵이 아닌 '입력 이미지를 기준'으로 크기를 정해야합니다.
앵커를 만들었으니 앵커를 내릴 차례입니다. 앵커는 공유 특성맵(14X14)에다 내립니다. 공유 특성맵은 또다른 컨볼루션 네트워크에 넣을건데 이 때 3X3커널이 14x14 특성맵 위를 슉슉 지나다니죠. 우리는 슉슉 지나다니는 커널 위에서 공유 특성맵을 향해 앵커를 내릴겁니다.

이렇게 말이죠.
자, 앵커를 내렸습니다. 특성맵에 내려온 앵커는 특성맵의 일부를 감싸겠죠?
RPN은 앵커가 감싼 특성맵의 일부를 보며 이 곳에 물체가 있는지 없는지, 있다면 어디쯤 있을지 추측합니다.
이를 표현하기 위해 컨볼루션 레이어를 거친 특성맵을 1x1 커널의 컨볼루션 레이어 2개에 각각 넣습니다. 논문에서는 이를 'reg layer', 'cls layer'에 넣는다고 말하죠.
각 출력값을 설명하면 다음과 같습니다.
앵커가 k개 있을 때 reg layer, cls layer의 output:
- cls layer : 해당 앵커가 감싼 곳에 물체가 있냐, 없냐를 나타내는 2k개의 output(). 한 앵커에 2개의 출력값이 나오며 이 둘을 softmax해줍니다.
- reg layer : 물체를 감싸는 박스의 4개 좌표를 표현할 수 있는 값(x,y,w,h)인 4k개의 output
이렇게 정리할 수 있겠습니다. RPN의 출력값을 구하는 과정을 그림으로 나타내면 다음과 같습니다.
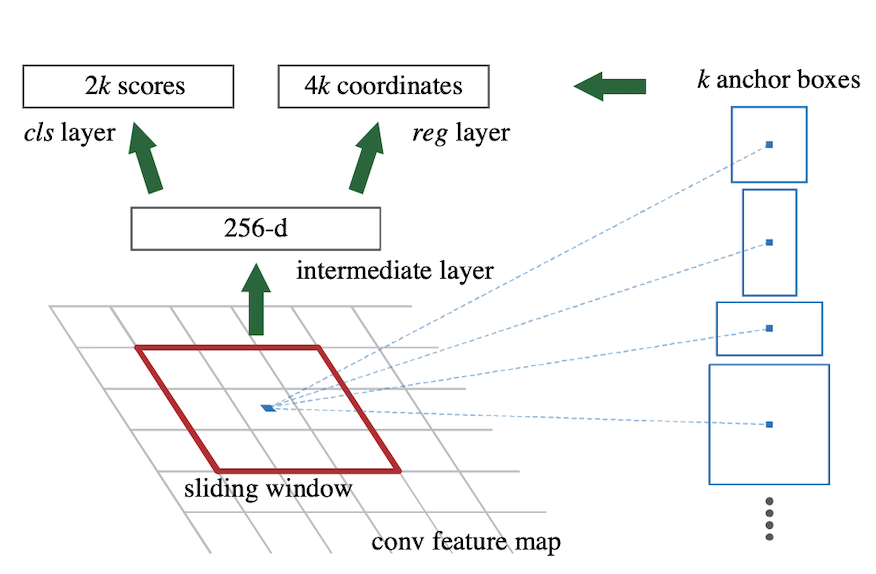
이 과정을 특성맵의 모든 좌표를 돌아다니며 수행합니다. 만약 특성맵이 14x14x512고 앵커 개수(k)를 9개로 한다면 추출한 RoI는 14X14X9 = 1764개가 되는 것이죠.
앵커의 장점은 특성맵의 위치에 따라, 특성맵의 값에 따라 변하지 않기 때문에 계산하기 편합니다. 각 위치에서 '앵커를 기준으로 물체를 판단했을 때' 해당 물체의 위치값이 reg layer의 출력값입니다. 즉, reg layer로 나온 실제 출력값은 (x,y,w,h)가 아닌 (dx, dy, dw, dh)라고 할 수 있고 여기에 앵커의 좌표 (x_a, y_a, w_a, h_a)를 더해 나온 값 (x_a + dx, y_a + dy, w_a + dw, h_a + dh) = (x,y,w,h)라고 할 수 있겠습니다.
그렇기 때문에 물체가 만약 위치가 변한다 해도 우리는 언제나 같은 크기를 지니는 앵커를 들고 해당 위치로 이동해서 앵커를 내린 뒤 앵커를 기준으로 그 물체 위치와의 (dx, dy, dw, dh)를 구하면 되기 때문에 RoI가 달라질 확률이 매우 적다고 볼 수 있겠습니다. 0%라고는 말을 못하겠네요.
RPN 학습시키기
RPN을 학습 시키는 방법은 논문에서도 따로 언급이 되어있습니다. 우선 훈련을 위해 설정하는 수치는 다음과 같습니다.
- learning rate : 60k개의 미니 배치에서는 0.001, 다음 20k개의 미니 배치에서는 0.0001을 사용합니다. 여기서 k = 앵커의 개수 입니다. 즉, 앵커를 9개 사용하는 경우면 60x9 = 540개의 미니배치에서는 0.001의 훈련률을 적용하고 이후 20x9 = 180개의 미니 배치에서는 0.0001을 사용합니다.
- momentum : 0.9를 사용합니다. 일반적으로 0.9를 많이 쓰는걸로 알고 있습니다.
- weight decay : 0.0005를 사용합니다.
- 훈련 범위 : Alternating Training 기준으로 1단계에서는 VGG16의 conv3_1부터 RPN까지, 3단계에서는 RPN만 훈련시킵니다. Alternating Training에 대한 설명은 추후 말씀드리겠습니다.
- 초기화 : RPN에 있는 모든 가중치는 평균 0, 표준편차 0.01의 가우시안 정규 분포를 이용해 초기화합니다. 공유하는 VGG16은 ImageNet을 위해 훈련된 모델을 가져옵니다.
위와 같은데, 여기서 제가 한가지 드는 의문이 있었습니다. learning rate에서 80k개보다 많은 미니배치를 사용하면 훈련률을 어떻게 적용시켜야 하는걸까요? 고민을 많이 해봤습니다. 그래서 제가 떠올린 방안은 60k->20k->60k->20k...와 같이 반복하며 훈련률을 변화시킨다는 것입니다.
그럼 이제 훈련을 해보도록 하죠. 그런데 훈련을 하기 전에 학습에 사용할 앵커부터 선별해야합니다.
학습에 사용할 앵커를 선별하는 과정은 크게 2가지로 나뉩니다.
- Positive, Negative 앵커로 구별
- Positive, Negative 앵커에서 총 256개의 미니배치 앵커 선정
그럼 이제 앵커를 선별하는 과정을 코드와 함께 하나씩 설명해보도록 하겠습니다.
앵커 생성
근데 그 전에 앵커를 만들어야겠죠? 앵커를 한 번 만들어봅시다.
앵커를 만들기 전에 각 앵커가 어디서 만들어지는지 생각을 해볼 필요가 있습니다.
224x224이미지를 입력값으로 받는 VGG16 기준으로, 앵커는 14x14 특성맵 위에서 만들어집니다.
224->14로 16배가 줄어든 것이죠. 즉, 14X14 특성맵의 각 픽셀은 원래 이미지 224x224를 기준으로 16x16을 대표하고 있는겁니다. 예를 들면 특성맵의 (0,0)은 원래 이미지에서(0,0)~(15,15)인 사각형 영역을 대표하는 값인거죠.
아래 그림을 보면 이해하기 쉽지 않을까 싶습니다.
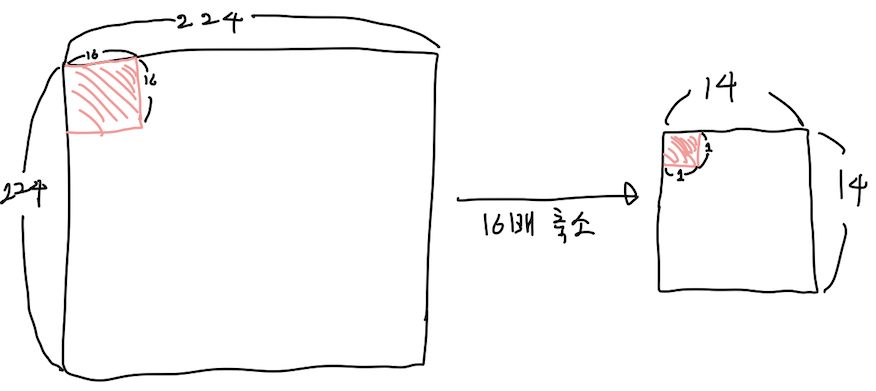
(두 빨간색 영역은 같은 영역을 나타냅니다. 우측 14x14 특성맵에서 (0,0) 픽셀이 원본 이미지의 (0,0)~(15,15) 사각형을 대표하는 값입니다.)
그럼 이를 고려해 앵커의 좌표를 설정해봅시다.
def make_anchor(anchor_size, anchor_aspect_ratio) :
anchors = [] # [x,y,w,h]로 이루어진 리스트
anchors_state = [] # 이 앵커를 훈련에 쓸건가? 각 앵커별로 사용 여부를 나타냅니다.
# 앵커 중심좌표 간격
interval_x = 16
interval_y = 16
# 2단 while문 생성
x = 8
y = 8
while(y <= 224): # 8~208 = 14개
while(x <= 224): # 8~208 = 14개
# k개의 앵커 생성. 여기서 k = len(anchor_size) * len(anchor_aspect_ratio)다
for i in range(0, len(anchor_size)) :
for j in range(0, len(anchor_aspect_ratio)) :
anchor_width = anchor_aspect_ratio[j][0] * anchor_size[i]
anchor_height = anchor_aspect_ratio[j][1] * anchor_size[i]
anchor = [x, y, anchor_width, anchor_height]
anchors.append(anchor)
anchors_state.append(1)
x = x + interval_x
y = y + interval_y
x = 8
return anchors, anchors_state
anchor_size = [128, 256, 512] # 논문에서 PASCAL VOC 2007 데이터셋을 사용할 때 지정한 앵커 사이즈를 그대로 사용합니다.
anchor_aspect_ratio = [[1,1],[1,0.5], [0.5,1]] # W*L기준 ratio 리스트입니다.
anchors, anchors_state = make_anchor(anchor_size, anchor_aspect_ratio) # 앵커 생성 + 앵커들의 정보가 모여있는 리스트를 얻습니다.Positive, Negative Anchor
앵커를 생성하였으니 이제 훈련에 사용할 앵커를 구해봅시다. 논문에서는 생성된 앵커에서 Positive, Negative 앵커를 선별한다고 나와있습니다. Positive 앵커와 Negative 앵커를 다음과 같이 정의됩니다.
- Positive 앵커 : Ground Truth Box와 IoU가 0.7 이상이거나 한 지역에서 IoU가 가장 큰 앵커
- Negative 앵커 : Ground Truth Box가 0.3보다 낮은 앵커
(Ground Truth Box는 실제 객체가 있는 영역을 말합니다. )
여기서 IoU는 Intersection-over- Union, 기호로 나타내면 (AnB)/(AuB)입니다. 곂치는 영역이 얼마나 많은가 나타낼 수 있는 수치죠.
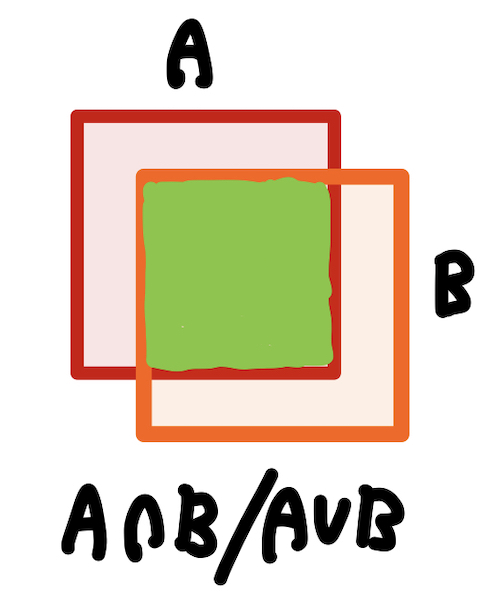
(초록색으로 색칠되어 있는 곳이 A, B 사각형의 IoU 영역입니다.)
다시 말해 Ground Truth Box와 많이 곂치는 앵커는 Positive 앵커고 적게 곂치는 앵커는 Negative 앵커입니다. IoU수치가 0.3~0.7 사이에 있는 앵커들은 학습에 기여하지 않는다고 논문에 나와있습니다. 학습에 좋은 앵커가 아니기 때문이죠.
이를 구현한 코드는 다음과 같습니다.
def align_anchor(anchors_for_Image, anchors_state, Ground_Truth_Box_list):
# 각 앵커는 해당 위치에서 구한 여러가지 Ground truth Box와의 ioU 중 제일 높은거만 가져옵니다.
IoU_List = []
Ground_truth_box_Highest_IoU_List = [] # 각 앵커가 어떤 Ground Truth Box를 보고 가장 높은 IoU를 계산했는지 저장합니다.
for i in range(0, len(anchors_for_Image)):
IoU_max = 0
ground_truth_box_Highest_IoU = [0,0,0,0]
anchor_for_thisImage = anchors_for_Image[i]
anchor_minX = anchor_for_thisImage[0] - (anchor_for_thisImage[2]/2)
anchor_minY = anchor_for_thisImage[1] - (anchor_for_thisImage[3]/2)
anchor_maxX = anchor_for_thisImage[0] + (anchor_for_thisImage[2]/2)
anchor_maxY = anchor_for_thisImage[1] + (anchor_for_thisImage[3]/2)
anchor = [anchor_minX, anchor_minY, anchor_maxX, anchor_maxY]
for j in range(0, len(Ground_Truth_Box_list)):
ground_truth_box = Ground_Truth_Box_list[j]
InterSection_min_x = max(anchor[0], ground_truth_box[0])
InterSection_min_y = max(anchor[1], ground_truth_box[1])
InterSection_max_x = min(anchor[2], ground_truth_box[2])
InterSection_max_y = min(anchor[3], ground_truth_box[3])
InterSection_Area = 0
if (InterSection_max_x - InterSection_min_x + 1) >= 0 and (InterSection_max_y - InterSection_min_y + 1) >= 0 :
InterSection_Area = (InterSection_max_x - InterSection_min_x + 1) * (InterSection_max_y - InterSection_min_y + 1)
box1_area = (anchor[2] - anchor[0]) * (anchor[3] - anchor[1])
box2_area = (ground_truth_box[2] - ground_truth_box[0]) * (ground_truth_box[3] - ground_truth_box[1])
Union_Area = box1_area + box2_area - InterSection_Area
IoU = (InterSection_Area/Union_Area)
if IoU > IoU_max :
IoU_max = IoU
ground_truth_box_Highest_IoU = ground_truth_box
IoU_List.append(IoU_max)
Ground_truth_box_Highest_IoU_List.append(ground_truth_box_Highest_IoU)
# 한 위치에 9개의 앵커 존재 -> 9개 앵커에 대한 IoU를 계산할 때마다 모아서 Positive, Negative 앵커 분류
if i % 9 == 8 :
IoU_List_inOneSpot = IoU_List[i-8:i+1]
for num in list(range(i-8, i + 1)):
if IoU_List[num] > 0.7 or (max(IoU_List_inOneSpot) == IoU_List[num] and IoU_List[num] >= 0.3): # positive anchor
anchors_state[num] = 2
elif IoU_List[num] < 0.3 : # negative anchor
anchors_state[num] = 1
else: # 애매한 앵커들
anchors_state[num] = 0
Ground_truth_box_Highest_IoU_List = np.asarray(Ground_truth_box_Highest_IoU_List)
Ground_truth_box_Highest_IoU_List = np.reshape(Ground_truth_box_Highest_IoU_List, (-1, 4))
return anchors_state, Ground_truth_box_Highest_IoU_List # 각 앵커의 상태, (모든)앵커가 IoU 계산에 참조한 Ground Truth BoxMinibatch Anchor + Multi Task Loss
Positive, Negative앵커를 구했으니 이제 미니배치 앵커를 선별해봅시다.
논문에서는 미니배치 앵커의 선별 방법을 다음과 같이 설명합니다.
'we randomly sample 256 anchors in an image to compute the loss function of a mini-batch'
그렇습니다. 우리는 positive, neagative 앵커에서 총 256개의 앵커를 선별해 훈련에 사용하면 됩니다.
근데, 왜 수많은 앵커 중 256개만 뽑아서 훈련에 쓸까요?
바로 앵커의 구성 때문입니다. 앞서 우리는 Positive, Negative 앵커로 분류하는 작업을 하였습니다. 물체와 얼마나 곂치냐를 기준으로 말이죠. 그런데 사진속에 물체가 차지하는 공간이 꼭 50%인 경우는 거의 없습니다. 어쩌면 엄청 작은 크기로 나온 객체만 있을 수도 있고, 사진 전체를 거대한 객체로 채울 수 있겠죠.
이게 뭐가 문제가 될까요? 우리 인간에게는 문제되지 않습니다. 허나 '훈련이 필요한' RPN에게는 문제가 됩니다. 처음에 초기화된 RPN은 아무것도 모르는 무식의 상태라고 볼 수 있습니다. 그런데 그런 RPN에게 Positive 앵커와 Negative 앵커가 불균형하게 이루어진 앵커를 데이터로 제공한다면? RPN이 좋지 않은 방향으로 학습할 가능성이 큽니다. 대체적으로 Negative 앵커가 많은 경우가 대다수기 때문에 논문에서는 'this will bias towards negative sample' 이라고 말하며 이를 막기 위해 랜덤하게 256개의 앵커를 선별합니다.
256개의 앵커는 Positive 앵커 128개, Negative 앵커 128개로 구성됩니다. 만약 Positive 앵커가 128보다 작다면 부족한 갯수만큼 Negative 앵커로 채웁니다. 좀 불균형한 미니배치가 되긴 하지만 어쩔 수 없습니다. 해당 이미지에선 그게 최선의 미니배치입니다.
이제 Multi Task Loss에 대해 말해보겠습니다. Multi Task Loss는 말 그대로 '여러가지 task를 수행하는 모델에서 나온 손실'입니다. RPN은 두가지 업무(객체일까? 점수 매기기 + 어디쯤 있을까? 위치 제안하기)를 수행하며 앞서 말했듯 두개의 출력값(2k, 4k)이 나온다고 말씀드렸습니다.
우리는 두개의 출력값으로 하나의 합쳐진 loss를 구한 뒤 RPN을 학습시켜야합니다. 따로 따로 학습시킬 수 있긴 하지만 RPN의 두가지 업무가 연관성이 있어서 한번에 학습시키는게 더 성능이 좋습니다. 그리고 사용하는 데이터셋이 같기 때문에 시간적인 면에서도 이득이죠. 그래서 논문의 저자는 RPN을 학습시킬 때 Multi Task Loss를 사용한게 아닐까 싶습니다.
논문의 저자들이 제안한 Multi Task Loss 함수는 다음과 같습니다. 이는 Fast R-CNN의 Multi task loss를 간소화한 버전이라고 보시면 되겠습니다.

뭔가 많습니다. 논문에 나와있던 내용 + 제가 개인적으로 이해한 내용을 한데 정리해봤습니다. 그럼 하나씩 살펴보도록 하겠습니다.
-
i : minibatch anchor index입니다. 미니배치에 있는 앵커의 인덱스 넘버입니다.
-
Ncls : Lcls를 normalize하기 위해 쓰는 값입니다. 논문에서는 미니배치 사이즈를 쓴다고 하네요. 그러니 Ncls = 256입니다.
-
Nreg : Lreg를 normalize하기 위해 쓰는 값입니다. 논문에서는 number of anchor locations라고 나와있습니다. 앵커위치의 갯수? 바로 앵커 개수입니다. 그러니 제가 만든 모델의 경우에는 Nreg = 1764인 것이죠.
-
pi, pi : 앞서 RPN이 앵커를 기준으로 객체 여부를 판단한다고 말씀드렸죠? 이 때 판단한 값이 pi입니다. 그리고 pi은 객체 여부를 판단할 때 사용한 앵커가 positive면 1, Negative였으면 0이 됩니다.
-
ti, ti : 처음에 뭔 소리인가 싶었습니다. 그런데 Fast R-CNN의 Multi task loss를 보고 오시면 이해가 쉬우실 겁니다. 위 그림에서도 나와있듯 ti = [tx, ty, tw, th]고 ti = [tx_star, ty_star, tw_star, th_star]입니다. 이를 구하는 방법은 앵커를 기반으로 추측한 RoI, 추측의 기반이 된 앵커, 앵커와 가장 IoU가 높던 Ground Truth Box의 (x,y,w,h)를 열심히 빼고 나누고 로그값을 구하는 겁니다. 아마 제가 작성한 코드를 보면 이해하기 쉬우실 겁니다.
-
Lcls : 객체 판별 task에 대한 loss입니다. 두 종류의 아웃풋(객체냐? 아니냐?)을 갖고 loss를 구하는 것이기 때문에 2종류의 output에 대한 log loss를 구하면 됩니다.
-
Lreg : 객체 영역 박스에 대한 loss입니다. 위에서 말했듯 ti, ti*을 구한 뒤 smooth_L1 함수로 loss를 구한 뒤 합친 값입니다.
이제 구현한 코드를 보며 다시 설명해보도록 하겠습니다. 저는 RPN 모델 클래스를 따로 만들며 클래스의 멤버 변수로 앵커들을 저장한 뒤 클래스 내부에서 미니배치 선별과 loss구하는걸 함께 진행했습니다. 그리고 출력값으로 2k, 4k개의 값을 얻는다고 했는데 저는 이를 [앵커 개수, 2], [앵커 개수, 4]와 같이 가공해서 출력하도록 만들었습니다.(별다른 가공 작업이 없으면 출력되는 값의 형태는 [1,14,14,18], [1,14,14,36]의 텐서입니다.)
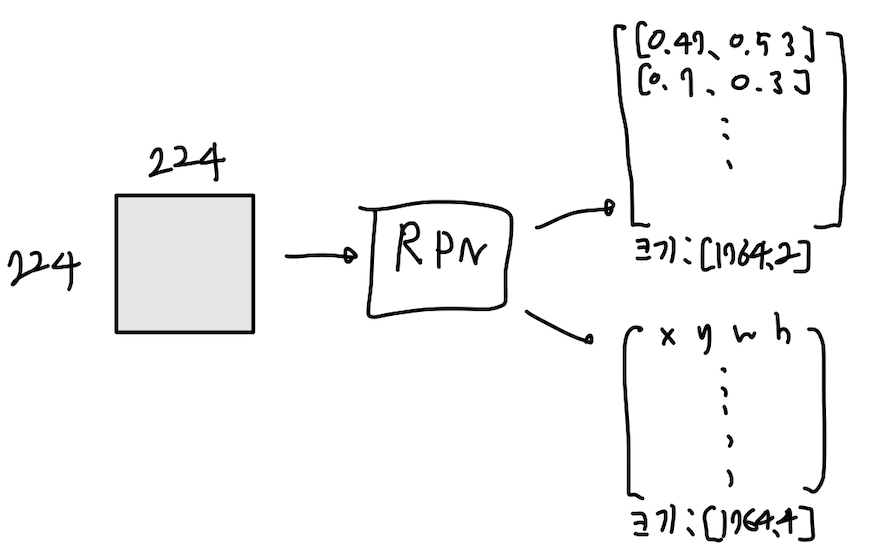
이렇게 말이죠. 이러하다는 가정하에 아래 코드를 읽으시면 됩니다.
그리고 multi_task_loss()부터 함수가 시작되니 multi_task_loss()의 첫번 째 코드부터 읽으셔야 합니다.
def get_minibatch_index(self, cls_layer_output_label):
# 라벨값을 받아 미니배치 앵커를 선별합니다.
# positive 앵커의 cls label은 [1.0, 0.0], Negative Anchor는 [0.0, 1.0]로 설정했습니다.
# 만약 둘다 아닌 앵커의 cls label은 [0.5, 0.5]입니다.
index_list = np.array([])
index_list = np.zeros(1764) # 각 앵커가 미니배치 뽑혔나 안뽑혔나 표현하는 리스트입니다.
index_pos = np.array([])
index_neg = np.array([])
# cls_layer_output_label을 보고 긍정, 부정 앵커를 분류합니다.
for i in range(0, 1764):
if cls_layer_output_label[i][0] == 1.0 : # positive anchor
index_pos = np.append(index_pos, i)
elif cls_layer_output_label[i][0] == 0.0 : # negative anchor
index_neg = np.append(index_neg, i)
# Positive앵커가 128개보다 적은 경우를 대비했습니다. 만약 128개보다 적으면 몽땅 minibatch에 넣어줍니다.
max_for = min([128, len(index_pos)])
ran_list = random.sample(range(0, len(index_pos)), max_for)
for i in range(0, len(ran_list)) :
index = int(index_pos[ran_list[i]])
index_list[index] = 1
# positive 앵커에서 선별 후 채워야할 갯수만큼 negative 앵커에서 선별합니다.
ran_list = random.sample(range(0, len(index_neg)), 256 - max_for)
for i in range(0, len(ran_list)) :
index = int(index_neg[ran_list[i]])
index_list[index] = 1
return index_list # (1764,1) <- 1,0으로 이루어진 boolean 넘파이 배열을 반환합니다. def multi_task_loss(self, cls_layer_output, reg_layer_output ,cls_layer_label, reg_layer_label, minibatch_index_list, anchor_optimize_list):
# label은 (1764,2)와 (1764,4)임
tensor_cls_label = tf.convert_to_tensor(cls_layer_label, dtype=tf.float32)
tensor_reg_label = tf.convert_to_tensor(reg_layer_label, dtype=tf.float32)
# loss 계산(Loss 텐서에서 미니배치에 해당되는 애들만 걸러내야 합니다.)
Cls_Loss = tf.nn.softmax_cross_entropy_with_logits(labels=tensor_cls_label, logits = cls_layer_output) # (1764,1) 텐서
Cls_Loss = tf.reshape(Cls_Loss, [1764, 1])
filter_x = tf.Variable([[1.0],[0.0],[0.0], [0.0]])
filter_y = tf.Variable([[0.0],[1.0],[0.0], [0.0]])
filter_w = tf.Variable([[0.0],[0.0],[1.0], [0.0]])
filter_h = tf.Variable([[0.0],[0.0],[0.0], [1.0]])
x = tf.matmul(reg_layer_output,filter_x)
y = tf.matmul(reg_layer_output,filter_y)
w = tf.matmul(reg_layer_output,filter_w)
h = tf.matmul(reg_layer_output,filter_h)
anchor_Use = copy.deepcopy(anchor_optimize_list)
anchor_tensor = tf.convert_to_tensor(anchor_Use, dtype=tf.float32)
x_a = tf.matmul(anchor_tensor,filter_x)
y_a = tf.matmul(anchor_tensor,filter_y)
w_a = tf.matmul(anchor_tensor,filter_w)
h_a = tf.matmul(anchor_tensor,filter_h)
x_star = tf.matmul(tensor_reg_label,filter_x)
y_star = tf.matmul(tensor_reg_label,filter_y)
w_star = tf.matmul(tensor_reg_label,filter_w)
h_star = tf.matmul(tensor_reg_label,filter_h)
# 텐서 로그는 ln밖에 없어서 ln10을 구한 뒤 나누는 방식으로 log10을 구합니다.(로그의 밑변환 공식)
denominator = tf.math.log(tf.constant(10, dtype=tf.float32))
t_x = tf.math.divide(tf.subtract(x, x_a), w_a)
t_y = tf.math.divide(tf.subtract(y, y_a), h_a)
t_w = tf.math.divide(tf.math.log(tf.math.divide(w, w_a)), denominator)
t_h = tf.math.divide(tf.math.log(tf.math.divide(h, h_a)), denominator)
t_x_star = tf.math.divide(tf.math.subtract(x_star, x_a), w_a)
t_y_star = tf.math.divide(tf.math.subtract(y_star, y_a), h_a)
t_w_star = tf.math.divide(tf.math.log(tf.math.divide(w_star, w_a)), denominator)
t_h_star = tf.math.divide(tf.math.log(tf.math.divide(h_star, h_a)), denominator)
# non Positive한 앵커들에 대한 reg 라벨값을 [0,0,0,0]으로 만들어서
# 연산 결과 log(음수) -> -inf가 되어버렸습니다. 이들을 0으로 만들어줍니다.
t_w_star = tf.where(tf.math.is_inf(t_w_star), tf.zeros_like(t_w_star), t_w_star)
t_h_star = tf.where(tf.math.is_inf(t_h_star), tf.zeros_like(t_h_star), t_h_star)
# (1764,1)에 해당하는 t_x, t_y...을 구했습니다. 여기서 미니배치에 해당되는 애들만 걸러냅니다.
# 미니배치에 해당되는 애들만 0이 아닌 값으로 만들기. 미니배치 리스트는 미니배치에 해당되는 인덱스는 1이고 나머지는 다 0이니까 tf.math.multiply를 사용해 원소별 곱을 해주면 미니배치에 해당되는 값들만 얻을 수 있다.
minibatch_index_tensor = tf.convert_to_tensor(minibatch_index_list, dtype=tf.float32) # 텐서로 변환
minibatch_index_tensor = tf.reshape(minibatch_index_tensor, [1764, 1])
# 다 곱해서 미니배치 성분만 남기기
t_x_minibatch = tf.math.multiply(t_x, minibatch_index_tensor)
t_y_minibatch = tf.math.multiply(t_y, minibatch_index_tensor)
t_w_minibatch = tf.math.multiply(t_w, minibatch_index_tensor)
t_h_minibatch = tf.math.multiply(t_h, minibatch_index_tensor)
t_x_star_minibatch = tf.math.multiply(t_x_star, minibatch_index_tensor)
t_y_star_minibatch = tf.math.multiply(t_y_star, minibatch_index_tensor)
t_w_star_minibatch = tf.math.multiply(t_w_star, minibatch_index_tensor)
t_h_star_minibatch = tf.math.multiply(t_h_star, minibatch_index_tensor)
# non-Positive한 앵커에 대한 라벨값에 대해 계산한 것과 곱하기 연산을 하면 nan이 나옵니다.
# 이들을 모두 0으로 만들어줍시다.
t_w_minibatch = tf.where(tf.math.is_nan(t_w_minibatch), tf.zeros_like(t_w_minibatch), t_w_minibatch)
t_h_minibatch = tf.where(tf.math.is_nan(t_h_minibatch), tf.zeros_like(t_h_minibatch), t_h_minibatch)
t_w_star_minibatch = tf.where(tf.math.is_nan(t_w_star_minibatch), tf.zeros_like(t_w_star_minibatch), t_w_star_minibatch)
t_h_star_minibatch = tf.where(tf.math.is_nan(t_h_star_minibatch), tf.zeros_like(t_h_star_minibatch), t_h_star_minibatch)
Cls_Loss_minibatch = tf.math.multiply(Cls_Loss, minibatch_index_tensor)
# 각 성분별로 1764개분 Loss를 다 합친 4개의 값이 나왔습니다.
# X성질에 대한 Smooth L1. huber_loss에서 delta = 1로 하면 smooth L1과 같습니다.
# 미니배치 성분만 뽑아내서 미니배치가 아닌 인덱스의 값은 0인데 Smooth L1에서 |x| < 1이면 0.5*x^2니까
# 0이 나오며 이는 loss에 어떠한 영향을 미치지 않습니다.
x_huber_loss = tf.compat.v1.losses.huber_loss(t_x_star_minibatch, t_x_minibatch)
y_huber_loss = tf.compat.v1.losses.huber_loss(t_y_star_minibatch, t_y_minibatch)
w_huber_loss = tf.compat.v1.losses.huber_loss(t_w_star_minibatch, t_w_minibatch)
h_huber_loss = tf.compat.v1.losses.huber_loss(t_h_star_minibatch, t_h_minibatch)
# 한 번에 더하니까 에러가 발생해 tf.math.add로 두개씩 더해줍니다.
Reg_Loss = tf.math.add(x_huber_loss, y_huber_loss)
Reg_Loss = tf.math.add(Reg_Loss, w_huber_loss) # (x_huber_loss + y_huber_loss) + w_huber_loss
Reg_Loss = tf.math.add(Reg_Loss, h_huber_loss) # (x_huber_loss + y_huber_loss + w_huber_loss) + h_huber_loss
# Normalize를 위해 곱해주는 상수입니다.
N_reg = tf.constant([1.0/1764.0])
N_cls = tf.constant([10.0/256.0]) # lambda도 곱한 값
loss_cls = tf.multiply(N_reg, tf.reduce_sum(Cls_Loss_minibatch))
loss_reg = tf.multiply(N_cls, Reg_Loss)
loss = tf.add(loss_cls, loss_reg)
if self.training_count >= 60000 and self.training_count <= 80000:
div_constant = tf.constant([1.0/10.0])
loss = tf.multiply(loss, div_constant)
elif self.training_count > 80000 :
self.training_count = 0
return loss코드가 좀 깁니다. 노트북으로 실행해봤는데 연산량을 견디지 못해 주피터 노트북과 파이썬 커널의 연결이 끊기는 현상이 발생해 학회에서 제공하는 서버 컴퓨터로 테스트해봤는데 잘돌아갔습니다.

학습 시간도 꽤 준수한데 어...성능은 별로였습니다. 저는 이를 데이터 전처리에서 온 문제라고 생각합니다.
왜냐하면 데이터 전처리 과정에서 positive앵커가 negative앵커보다 훨씬 적게 나왔기 때문입니다.
확인해본 결과, positive 앵커가 많아야 50개 정도 나오는 걸 관찰했고 이러한 미니배치 세트가 5011개나 있었고 이를 이용해 반복 학습을 했기 때문에 안좋은 방향으로 학습이 되었습니다.
그래디언트 적용 코드도 올리고 싶었으나 그러면 분량이 너무 길어져 올리지 못했습니다.
전체 코드를 보고 싶으시면 저의 github repository에서 확인할실 수 있습니다.
RPN으로 만든 RoI를 Fast R-CNN의 Detector로
자, 우리는 RPN을 훈련시켰고 여기서 RoI를 얻었다고 가정해봅시다. 그럼 이제 Detector에 RoI를 전달해야겠죠?
그런데 훈련을 시키냐, 테스트를 해보냐에 따라 RoI를 Detector에 전달하는 방식이 다릅니다. 앞서 간단히 설명드린 부분입니다. 이번에 더 자세히 다뤄보도록 하죠. 상황에 따른 전달 방식을 정리해보면 다음과 같습니다.
RoI를 Detector에 어떻게 전달하냐면...
- Training time : 이미지의 경계선에 걸치지 않은 RoI를 제외하고 detector에 모두 전달해줍니다.
- Testing Time : 선별한 RoI 중 object score(cls layer의 output)이 0.7 이상인 것을 선별한 뒤 상위 N개의 RoI만 Detector에 전달합니다. 이러한 기법을 nms(non-maximum suppression)라고 합니다.
이와 같은 차이가 있습니다.
근데, 왜 Training time에는 nms을 적용하지 않는걸까요? 이는 Fast R-CNN도 RoI에 대한 학습을 해야하기 때문입니다. Fast R-CNN도 Multi Task Loss를 사용하는데 RoI에 대한 학습을 수행합니다. 만약 훈련할 때 nms로 RoI를 거르게 되면 Fast R-CNN은 걸러진 RoI에 대해서만 학습하게됩니다. 그렇기 때문에 훈련할 때는 nms를 사용하지 않습니다.
이를 코드로 표현하면 다음과 같습니다. 우선 Training Time일 경우입니다.
def get_nonCrossBoundary_RoI(RPN_Model,image_list, anchor_optimize_list_forAllImage) :
nonCrossBoundary_RoI_forAll_Image = []
for i in tqdm(range(0, len(image_list)), desc = "get_nonCrossBoundary_RoI") :
image = np.expand_dims(image_list[i], axis = 0)
_, reg_output = RPN_Model(image, anchor_optimize_list_forAllImage[i])
nonCrossBoundary_RoI_inImage = []
for j in range(0, len(reg_output)) :
x = reg_output[j][0]
y = reg_output[j][1]
w = reg_output[j][2]
h = reg_output[j][3]
if((x - (w/2) >= 0) and (y - (h/2) >= 0) and
(x + (w/2) <= 224) and (y + (h/2) <= 224)):
nonCrossBoundary_RoI_inImage.append(reg_output[j])
nonCrossBoundary_RoI_forAll_Image.append(nonCrossBoundary_RoI_inImage)
return nonCrossBoundary_RoI_forAll_Image이 과정을 모든 이미지에 대해 수행하면 Detector훈련을 위한 RoI 데이터셋이 만들어집니다.
넘파이가 아닌 리스트로 저장한 이유 :
Detector에 사용할 RoI는 이미지마다 갯수가 다릅니다. 각 이미지에 대한 reg_layer_output은 [1764, 4]로 균일하겠지만 각 이미지에서 이미지의 경계를 넘지 않는 RoI, nms를 통과한 RoI의 개수는 일정한 경우는 매우 드뭅니다. 그래서 리스트 안에 리스트를 저장하는 방식으로 데이터셋을 만들었습니다.
Test할 때 사용하는 nms는 다음과 같습니다. 이 때 object score를 기준으로 RoI를 선별하기 때문에 cls_layer의 출력값도 매개변수로 받습니다.
def get_mns_RoI(cls_output, reg_output):
cls_output_np = cls_output.numpy()
mns_RoI_list = []
for i in range(0, len(cls_output_np)):
if cls_output_np[i][0] > 0.7:
mns_RoI_list.append(reg_output[i])
return mns_RoI_listDector
이제 Detector로 왔습니다. 이는 Fast R-CNN의 Detector와 같습니다. 우선 모델의 구조를 살펴봅시다.
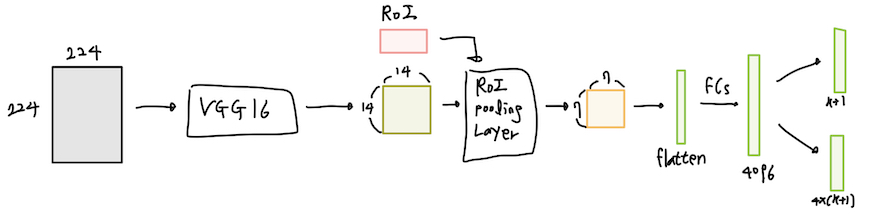
위와 같습니다. 하나씩 살펴볼까요?
- 224x224x3 크기의 원본 이미지를 VGG16에 넣어 14x14x512 공유 특성맵을 얻습니다.
- 14x14x512 공유 특성맵과 RoI를 RoI Pooling Layer에 넣어 7x7x512 특성맵을 얻습니다.
- 7x7x512 특성맵을 일렬로 펼친 뒤(Flatten) 4096개의 가중치를 지닌 2개의 FC(Fully Connected Layer)에 넣습니다.
- FC의 출력값을 각각 Classify Layer, bbox Layer에 넣어 각각 k + 1, 4x(k+1)개의 출력값을 얻습니다.
이렇게 4단계로 분류할 수 있겠네요. 여기서 말하는 k는 데이터셋에 존재하는 객체의 개수입니다.
제가 사용한 PASCAL VOC 2007 데이터셋은 총 20종류의 클래스가 있었으니 k=20입니다. 여기에 아무것도 없는 background 클래스도 고려하면 Detector는 21종류의 Classify 출력값을 얻어야합니다. 고로 출력값의 크기는 [21, 1], [84, 1]이 되겠습니다. 그리고 [21, 1]는 클래스 분류 출력값의 사이즈이므로 softmax 활성화 함수로 처리해주는 과정을 거쳐야합니다.
1단계는 앞서 RPN을 설명할 때 말씀드렸습니다. 그러니 바로 2. RoI Pooling Layer부터 살펴봅시다.
RoI Pooling Layer
앞서 Fast R-CNN이 R-CNN에서 개선된 부분으로 '어느 지점까지는 같은 CNN을 통과하다 일정 단게부터는 각 RoI별로 연산을 수행한다'고 말씀드렸습니다. 여기서 '각 RoI별로 연산'하는 task를 수행하기 위해 만들어진게 RoI Pooling Layer입니다.
RoI Pooling Layer는 특성맵에서 해당 RoI에 해당되는 영역을 추출해 원하는 사이즈로 pooling 해줍니다. 이 때 RoI는 원본 이미지 대비 특성맵의 줄어든 정도만큼 줄입니다. 예를 들면 224x224에서 64x64인 RoI는 14x14에선 4x4인 것이죠.
논문에 의하면 특성맵에서 (w,h)크기를 지닌 RoI를 7x7로 pooling 하기위해 pool_size를 (w/7, h/7), strides도 (w/7, h/7)로 하는 max pooling을 수행하라고 나와있습니다. 허나 제가 예로 든 4x4 RoI는 7x7보다 작습니다. 그러면 어...어떻게 max pooling을 하죠?
저는 고민에 빠졌습니다. 열심히 구글에게 물어봤고, 저와 같은 고민을 했던 사람이 몇분 계셨습니다. 한 분은 pooling 대신 resizing으로 해결하시고 다른 분은 RoI의 각 픽셀을 7x7로 키운 다음 7x7로 max pooling하는 방식을 사용하셨습니다.
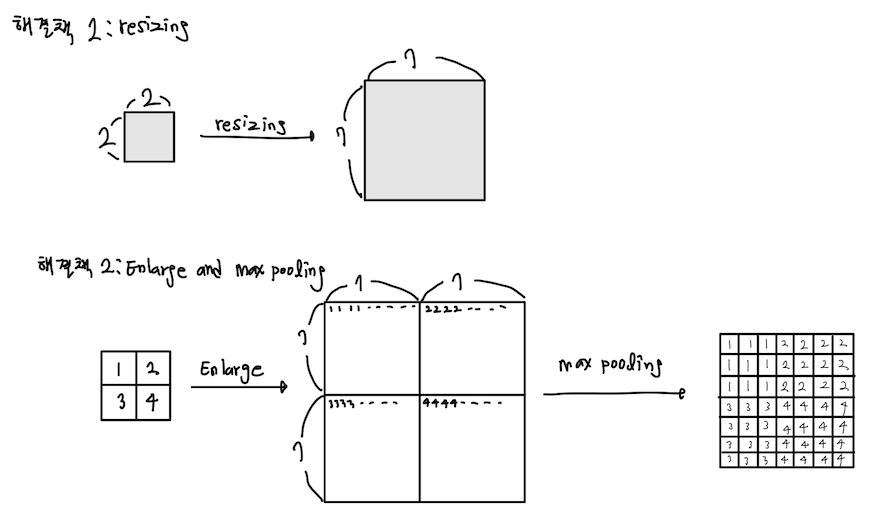
위와 같이 말이죠. 정확도는 두 번째 방식(각 픽셀을 7x7로 키우고 7x7로 max pooling)이 더 좋아보입니다. 아무래도 해당 영역에서 논문에서 사용한 max pooling을 이용해 각 픽셀 영역을 대표하는 값을 구했으니 말이죠. 허나 구현하는데 큰 어려움이 있었습니다. enlarge를 하는 과정에서 그레디언트를 전달할 때 필요한 정보들(이 출력값이 나올 때 각 레이어의 가중치가 기여한 정도)이 사라지더군요. 그래서 일단은 resizing을 사용하기로 했습니다.
두 번째 아이디어의 출처는 여기입니다.
RoI Pooling Layer의 정방향 연산에 해당하는 코드는 다음과 같습니다. 풀링 레이어는 가중치가 없기 때문에 학습 대상에 해당되지 않습니다.
def call(self, image, RoI_inImage): # shared FeatureMap (1,14,14,512)와 입력 이미지에 있는 RoI 리스트를 입력으로 받습니다.
RoiPooling_outputs_List = [] # 특성맵의 RoI 부근을 잘라낸 뒤 7*7로 만들어낸 것들을 모으는 리스트입니다.
# 이미지의 각 RoI 영역에서 7*7 크기의 특성맵을 얻어냅니다.
for i in range(0, len(RoI_inImage)):
# 224 -> 14로 16배 줄어들었으니 이에 맞춰 RoI도 줄인다.
# RoI 양식이(x,y,w,h)였는데 이를 (r,c,w,h)로 바꿔준다. r,c는 왼쪽 위 좌표(min x, min y)고 w,h,는 RoI의 너비, 높이다.
r = RoI_inImage[i][0] - RoI_inImage[i][2]/2
c = RoI_inImage[i][1] - RoI_inImage[i][3]/2
w = RoI_inImage[i][2]
h = RoI_inImage[i][3]
# 1/16배로 만들기
r = round(r / 16.0)
c = round(c / 16.0)
w = round(w / 16.0)
h = round(h / 16.0)
image_inRoI = image[:, c:c+h, r:r+w, :] # RoI에 해당되는 부분을 추출합니다.
image_resize = tf.image.resize(image_inRoI, (self.pool_size, self.pool_size)) # 7*7로 resize해줍니다.
RoiPooling_outputs_List.append(image_resize) # 리스트에 추가합니다.
# RoiPooling_outputs_List는 (1,7,7,512) 텐서들로 이루어진 리스트가 되었습니다.
# 이를 텐서 밑에 텐서와 같이 밑에 붙히는 방식으로 쫘라락 붙혀 하나의 텐서로 만들어줍니다.
final_Pooling_output = tf.concat(RoiPooling_outputs_List, axis=0)
# 통합한 텐서를(1,RoI 개수,7,7,512)로 reshape 후 반환합니다.
final_Pooling_output = tf.reshape(final_Pooling_output, (1, len(RoI_inImage), self.pool_size, self.pool_size, self.nb_channels))
return final_Pooling_outputDetector의 정방향 연산
RoI Pooling Layer의 출력값은 (1,RoI 개수,7,7,512) 텐서입니다. Fast R-CNN을 보면 한 RoI에 대해서 연산을 진행 후 출력값을 얻는다고 나와있습니다. 즉, 우리는 (1,RoI 개수,7,7,512) 텐서에서 (1,7,7,512)씩 떼서 [Flatten + FCs]로 구성된 네트워크에 넣어줘야 합니다.
저는 RoI Pooling Layer에 넣어 얻은 값을 Flatten Layer에 넣어 한줄로 쫘라락 나열하고 7x7x512개씩 나눈 뒤 하나씩 FCs에 넣었습니다.
코드로 표현하면 다음과 같습니다.
final_Pooling_output = self.RoI_Pooling_Layer(shared_output, RoI_list) # 공용 레이어와 RoI를 넣어 (1, RoI 개수, 7,7,512) 텐서를 얻습니다.
flatten_output_forAllRoI = self.Flatten_layer(final_Pooling_output) # Flatten으로 한줄 세우기 = '(7*7*512) * RoI 개수' 길이의 한줄 텐서가 나옵니다.
flatten_perRoI = tf.split(flatten_output_forAllRoI, num_or_size_splits = len(RoI_list)) # 힌줄 텐서를 (1, 7*7*512)개씩 분리합니다.
Classify_layer_output = []
Reg_layer_output = []
# (1, 7*7*512) 텐서씩 Detector에 넣어서 출력값을 얻습니다.
for i in range(0, len(flatten_perRoI)):
flatten_output = flatten_perRoI[i] # flatten된걸 하나씩 꺼냄
Fully_Connected_output = self.Fully_Connected(flatten_output) # FCs로 만들기
# 객체 분류 레이어, 박스 회귀 레이어
cls_output = self.Classify_layer(Fully_Connected_output)
reg_output = self.Reg_layer(Fully_Connected_output)
Classify_layer_output.append(cls_output)
Reg_layer_output.append(reg_output)
# 얻어낸 출력값들을 하나의 리스트에 모아 반환합니다.
return Classify_layer_output, Reg_layer_outputDetector 훈련시키기
앞서 우리는 Detector의 출력값 Classify_layer_output, Reg_layer_output을 얻었습니다. 이제 모델을 훈련시켜봅시다.
Detector를 훈련시키는 방법은 RPN과 비슷합니다. 우선 사전에 알아둬야할 정보는 다음과 같습니다.
- learning rate : 30k개의 미니배치에서는 0.001로, 이후 10k의 미니배치에서는 0.0001로 하고 이를 반복한다고 합니다. 저는 다 0.001로 했습니다.
- momentum : 0.9를 사용합니다.
- weight decay : 0.0005를 사용합니다.
- 훈련 범위 : Fast R-CNN 논문에 따르면 VGG16의 conv3_1부터 훈련시키면 된다고 나와있습니다. conv3_1 ~ FCs까지 훈련시키고
- 초기화 : Classify layer는 평균이 0, 표준편차가 0.01인 가우시안 정규 분포로, bbox layer는 평균이 0, 표준편차가 0.001인 가우시안 정규 분포를 사용해 초기화합니다.
그럼 이제 훈련 방식에 대해 얘기를 해보도록 하겠습니다.
Detector는 매 이미지마다 RoI 미니배치를 선별해 훈련에 사용합니다. 이 때 미니배치에 들어갈 RoI의 개수를 정하는 방식이 꽤 인상깊었습니다. 논문에서는 이미지 N장마다 R개의 RoI를 선정해 훈련에 사용한다고 나와있었습니다. 즉, 한 장마다 R/N개의 RoI를 미니배치로 선정해 Detector 훈련에 사용하는 것이죠. 저자는 R = 128, N = 2로 하는걸 권장했습니다. 그러면 한 장마다 64개의 RoI를 미니배치로 선별해 훈련시키게 됩니다.
자, 우리는 한 이미지에서 64개의 RoI를 뽑으면 된다는걸 알았습니다. 그러면 의문이 드는게 있습니다. 어떻게 64장의 RoI를 뽑으면 될까요? 논문의 저자는 다음과 같은 기준을 제시했습니다.
RoI 선별
- Ground Truth Box와 IoU가 0.5 이상인 RoI 16개(25%) -> [u ≥ 1]인 RoI
- Ground Truth Box와 IoU가 [0.1, 0.5) 인 RoI 32개(75%) -> [u = 0]인 RoI
위와 같이 64개의 RoI를 선별하면 됩니다. 이제 Multi Task Loss 함수에 넣어 Loss를 구하면 됩니다. Fast R-CNN의 loss는 다음과 같습니다.
참고 : Fast R-CNN의 Loss는 이미지에 대한 Loss가 아닌 이미지 내 RoI에 대한 Loss입니다.
그러므로 RoI별 Loss를 구해 평균을 낸 뒤 그래디언트를 구해야합니다.
def multi_task_loss(self, Classify_layer_output_list, Reg_layer_output_list, Cls_label_minibatch, Reg_label_minibatch, obj_RoI_num):
Loss_final = 0
for i in range(0, len(Reg_label_minibatch)) :
cls_loss = tf.nn.softmax_cross_entropy_with_logits(labels = Cls_label_minibatch[i], logits=Classify_layer_output_list[i])
loss = cls_loss # cls_loss가 loss에 들어간다는 걸 나타내기 위해 이 코드를 추가함
if i < obj_RoI_num: # IoU > 0.5인 RoI들
# (1,84)에서 해당 클래스에 해당하는 값을 얻어야한다(예 : '자동차'객체에 대한 박스 위치 추측값)
# 논문에서 (x,y,w,h)에 대한 smooth l1을 구하라길래 ground_truth_box를 (x,y,w,h)로 바꿔주고자 한다
Reg_label = Reg_label_minibatch[i]
class_index = tf.argmax(Cls_label_minibatch[i]) # 라벨값의 원-핫 인코딩에서 가장 큰 값의 인덱스 = 클래스의 인덱스에 해당.
label_forCalc = np.zeros((1, 84))
label_forCalc[0][4*class_index] = Reg_label[0] + Reg_label[2]/2
label_forCalc[0][4*class_index + 1] = Reg_label[1] + Reg_label[3]/2
label_forCalc[0][4*class_index + 2] = Reg_label[2] - Reg_label[0]
label_forCalc[0][4*class_index + 3] = Reg_label[3] - Reg_label[1]
label_forCalc_tf = tf.convert_to_tensor(label_forCalc, dtype=tf.float32)
filter_for_predbox = np.zeros((1, 84))
filter_for_predbox[0][4*class_index] = 1.0
filter_for_predbox[0][4*class_index + 1] = 1.0
filter_for_predbox[0][4*class_index + 2] = 1.0
filter_for_predbox[0][4*class_index + 3] = 1.0
filter_for_predbox_tf = tf.convert_to_tensor(filter_for_predbox, dtype=tf.float32)
Reg_layer_output_list[i] = tf.math.multiply(Reg_layer_output_list[i], filter_for_predbox_tf)
reg_loss = tf.compat.v1.losses.huber_loss(label_forCalc_tf, Reg_layer_output_list[i]) # (x,y,w,h) 각 성분에 대해 smoothL1(ti −vi)한 값을 다 더한게 나온다.
loss = tf.add(cls_loss, reg_loss)
if i == 0:
Loss_final = loss
else :
Loss_final = tf.add(Loss_final, loss)
N_batch = tf.constant([1.0/len(Reg_label_minibatch)])
Loss_mean = tf.multiply(Loss_final, N_batch)
return Loss_mean # 64개 미니배치로 얻은 로스의 평균값 이렇게 Loss를 구했으니 그래디언트를 적용해야하는데...한가지 고민에 빠졌습니다.
어떻게 그래디언트를 VGG16에 역전파하지?
일반적인 Max Pooling Layer라면 축소된 출력값까지 전파된 그래디언트는 아래 그림과 같이 역전파 됩니다.

Max pooling을 통해 가장 큰 값만 정방향 연산으로 흘러갔고 출력값에 기여했으니 그대로 전달된 가장 큰 값이 1의 그래디언트를 갖게 되지요. 그런데 RoI Pooling Layer는 어떻게 역전파 해야되는걸까요? 논문에서는 다음과 같은 식을 써라고 말합니다.
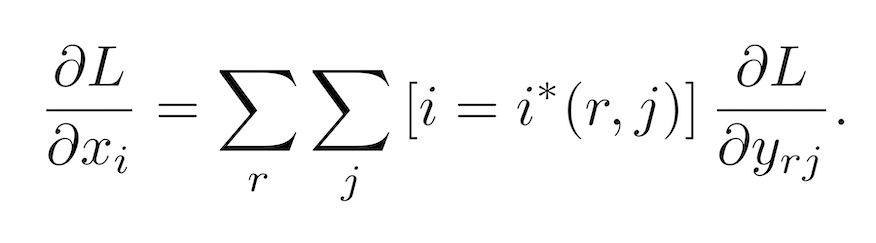
여기서 r은 미니배치 RoI의 개수, j는 각 RoI에서 얻은 출력값의 개수입니다. 저는 r은 64, j = 2로 해석했습니다. 그래서 저는 위 식을 다음과 같이 해석했습니다.
각 RoI에 대해 전파된 그래디언트를 한데 모아 VGG16에 전달한다
여기서 한데 모은 그래디언트는 미니배치에 속한 64개분의 그래디언트를 의미합니다.
그런데 앞서 Loss를 구하는 과정에서 미니배치에 대한 로스를 구하기 위해 64로 나눴던 기억이 있습니다.
그래서 저는 한데 모은 그래디언트를 (기존에 구한 그래디언트) * 64로 구했습니다.
이렇게 우리는 Detector까지 훈련시켜봤습니다. 그럼 Faster R-CNN을 훈련시키는 방법을 알아보도록 하겠습니다.
훈련은 에포크 = 1로 진행해봤습니다.

에포크 한 번에 3시간 17분...뭔가 잘못된겁니다.
어디서 연산 시간을 줄일 수 있을까요?
성능은 어...테스트하지 못했습니다. 앞서 말했듯 제대로 훈련되지 않은 RPN이 생성한 RoI를 nms로 걸러내니 살아남은 RoI가 하나도 나오지 않았기 때문입니다. 흑흑.
Faster R-CNN을 훈련시키기
슬픈 결과는 뒤로 하고, 이제 논문에서 언급한 훈련 방식에 대해 설명해 드리도록 하겠습니다.
논문에서는 Faster R-CNN을 훈련시키는 3가지 방법을 제시하고 있습니다.
- Alternating training : RPN과 Detector를 번갈아가며 훈련시키는 방법입니다. 논문의 저자는 이 방식을 사용했고 저도 이 방법으로 Faster R-CNN을 훈련하기로 계획했습니다. 훈련 방식이 꽤나 까다롭다는 단점이 있지만 Approximate joint training으로 훈련시킬 때보다 성능이 더 좋다는 장점이 있습니다.
- Approximate joint training : RPN과 Detector를 통합해 한번에 훈련시키는 방법입니다. 이 때 Loss는 RPN과 Detector의 Loss를 합친 값입니다. Alternating training에 비해 훈련 시간이 줄어든다는 장점이 있지만 훈련된 모델의 성능이 Alternating training으로 훈련할 때보다 정확도가 낮다는 단점이 있습니다.
- Non-approximate joint training : 제가 Alternating training위주로 본다고 제대로 확인하지 못했습니다 ㅠㅠ
저자는 첫 번째 방식만 훈련에 사용했습니다. 제가 듣기로는 두번 째 방식을 추천하지만 시간이 없어 첫번 째 방식만 사용했다고 하네요. 저는 시간이 많았는데 두번 째 방식에서 어떻게 해야 두 모델의 Loss를 합쳐 역전파 시킬지 몰라 첫 번째 방식을 사용했습니다. 그러면 첫 번째 방식, Alternating training에 대해 좀더 자세히 설명해 드리도록 하겠습니다.
Alternating training
논문에서 자세히 훈련법이 나와있는 유일한 훈련법입니다. 총 4단계에 달하며 다음과 같습니다.
- ImageNet을 위해 훈련된 VGG16을 가져와 RPN과 연결한 뒤 함께 훈련합니다.
- 훈련된 RPN에서 얻은 RoI로 Detector를 훈련합니다. 이 때 Detector가 얻는 14x14x512 특성맵은 1단계에서 훈련한 VGG16이 아닌 또다른 VGG16에서 추출합니다. 즉, 이 때 까지는 RPN과 Detector는 다른 VGG16을 사용합니다.
- 2단계에서 훈련한 VGG16을 RPN과 연결해 또다시 훈련합니다. 이 때 부터 VGG16을 공유하기 시작합니다. 이 때 훈련 대상은 RPN에 한정합니다. VGG16은 훈련하지 않습니다.
- 3단계에서 얻은 RPN으로 RoI를 추출한 뒤 Detector를 훈련합니다. 이 때 훈련 대상은 Detector(FCs)에 한정합니다.
이를 그림으로 나타내면 다음과 같습니다.

코드로는 다음과 같이 나타냈습니다.
def four_Step_Alternating_Training(RPN_Model, Detector_Model, image_list, cls_layer_label_list, reg_layer_label_list, anchor_optimize_list_forAllImage, Reg_labels_for_FastRCNN, Cls_labels_for_FastRCNN, EPOCH): # 두 모델을 받아 훈련시킴
# 각자 독립된 상태에서 훈련시킵니다.
for i in range(0, EPOCH) : # RPN 훈련
RPN_Model.Training_model(image_list, cls_layer_label_list, reg_layer_label_list, anchor_optimize_list_forAllImage, 1)
# 훈련시킨 RPN에서 Detector훈련에 필요한 데이터 휙득
# RoI는 경계선만 넘지 않으면 다 사용합니다.
nonCrossBoundary_RoI_forAll_Image = get_nonCrossBoundary_RoI(RPN_Model, image_list)
for i in range(0, EPOCH) : # Detector 훈련
Detector_Model.Training_model(image_list, nonCrossBoundary_RoI_forAll_Image, Reg_labels_for_FastRCNN, Cls_labels_for_FastRCNN, 2)
# Detector_Model의 VGG를 RPN에 이식(레이어 공유 시작)
RPN_Model.conv1_1 = Detector_Model.conv1_1
RPN_Model.conv1_2 = Detector_Model.conv1_2
RPN_Model.conv2_1 = Detector_Model.conv2_1
RPN_Model.conv2_2 = Detector_Model.conv2_2
RPN_Model.conv3_1 = Detector_Model.conv3_1
RPN_Model.conv3_2 = Detector_Model.conv3_2
RPN_Model.conv3_3 = Detector_Model.conv3_3
RPN_Model.conv4_1 = Detector_Model.conv4_1
RPN_Model.conv4_2 = Detector_Model.conv4_2
RPN_Model.conv4_3 = Detector_Model.conv4_3
RPN_Model.conv5_1 = Detector_Model.conv5_1
RPN_Model.conv5_2 = Detector_Model.conv5_2
RPN_Model.conv5_3 = Detector_Model.conv5_3
for i in range(0, EPOCH) : # RPN 훈련
RPN_Model.Training_model(image_list, cls_layer_label_list, reg_layer_label_list, anchor_optimize_list_forAllImage, 3)
# 훈련시킨 RPN에서 Detector훈련에 필요한 데이터 휙득
nonCrossBoundary_RoI_forAll_Image = get_nonCrossBoundary_RoI(RPN_Model, image_list)
# RPN의 VGG16을 Detector의 VGG16 부분에 이식
Detector_Model.conv1_1 = RPN_Model.conv1_1
Detector_Model.conv1_2 = RPN_Model.conv1_2
Detector_Model.conv2_1 = RPN_Model.conv2_1
Detector_Model.conv2_2 = RPN_Model.conv2_2
Detector_Model.conv3_1 = RPN_Model.conv3_1
Detector_Model.conv3_2 = RPN_Model.conv3_2
Detector_Model.conv3_3 = RPN_Model.conv3_3
Detector_Model.conv4_1 = RPN_Model.conv4_1
Detector_Model.conv4_2 = RPN_Model.conv4_2
Detector_Model.conv4_3 = RPN_Model.conv4_3
Detector_Model.conv5_1 = RPN_Model.conv5_1
Detector_Model.conv5_2 = RPN_Model.conv5_2
Detector_Model.conv5_3 = RPN_Model.conv5_3
for i in range(0, EPOCH) : # Detector 훈련
Detector_Model.Training_model(image_list, nonCrossBoundary_RoI_forAll_Image, Reg_labels_for_FastRCNN, Cls_labels_for_FastRCNN, 4)
return RPN_Model, Detector_Model논문에는 모델 구조 외에 실험을 통한 성능 증명 부분이 있지만 그 부분은 스킵하도록 하겠습니다.
리뷰 + 구현 후기
드디어 리뷰가 끝났습니다. 저의 첫번 째 리뷰가 끝이 났습니다. 허나 구현은 끝나지 않았습니다. 버그...버그를 확인해야합니다. Loss를 구하긴 했지만 이걸 가중치에 적용해야 의미가 있는건데 무수히 많은 버그가 발생할거라 생각됩니다.
Faster R-CNN의 구현 코드를 작성할 때까지 거진 1달 반이라는 시간이 걸렸습니다. 일단 논문을 이해하는데 오래 걸렸습니다. 저는 올해 3월 중순까지만 해도 논문의 ㄴ자만 봐도 벌벌 떨며 '아, 다음에 봐야지' 하며 계속 미루고 있었어요. 그러다가 '난 대학원에 갈거니까 들어가기 전에 논문 구현 해보면 좋지 않을까?'하는 마음에 교내 논문 구현 스터디에 들어갔는데 어...그 뱁새가 황새 쫓다가 다리 찢어지는게 뭔 심정인지 알겠더라구요.
스터디에 계시던 분들이 '2stage논문을 구현하고 1stage 논문을 구현해볼까요?', 'Faster R-CNN이 중요한 논문이니 이거 구현해보죠'라는 말을 하실 때마다 '띠요용~?'하며 미친듯이 구글링만 했던 기억이 납니다. 그렇게 논문 읽기를 시작하게 되었죠.
그렇게 R-CNN이 뭔지 알게 되고, 더 나아가 Fast R-CNN, Faster R-CNN을 읽은 뒤 YOLO, VGG, AlexNet 등 여러 유명한 논문들을 읽어보며 자신감을 쌓고난 뒤, 나름 패기롭게 논문 구현을 시작했습니다. 어...박살났습니다.
데이콘, 케글 등에서 입문자용 대회만 참가하며 기초적인 모델 설계만 하던 제가 논문 구현을 위한 모델을 설계하는건 쉽지 않았습니다. 구현 코드를 봐도 이해가 하나도 안되더라구요. 설상가상으로 저는 텐서플로우를 쓰는데 텐서플로우로 만든 코드는 1.x버전 코드라 제가 작성하는 코드 스타일이랑 많이 달랐고 파이토치는 어...그냥 읽기만 했어요. 저에겐 너무나도 낯선 코드들이었습니다.
그래서 제가 내린 결론은 '일단 만들면서 이리저리 박살나며 수정해가자'는 거였어요. 그렇게 매일 stackoverflow, github와 vscode를 끼고 살았습니다. 그렇게 하면서 코드를 몇번 갈아엎다보니 뭔가 만들어졌습니다. 텐서플로우도 커스텀 모델, 레이어, 로스함수를 만들 수 있다는 사실도 이번에 처음 알았습니다. 생각하면 텐서플로우도 결국 파이썬 모듈 중 하나니까 상속해서 저만의 모델을 만들면 되는 거였는데...허허
여튼, 그렇게 하다보니 지금의 코드가 나왔습니다. 뭐든 부딪히며 배우니까 되긴 되더랍니다. 물론 지금 결과가 완벽한 결과는 아니겠지만 음...
좀 얘기가 길었네요. 처음으로 구현하고 리뷰한 논문이라 뿌듯한 마음에 이리도 길게 쓴듯 합니다.
제 눈에는 흠잡을데 없는(없었으면 하는) 리뷰글이지만 저는 확인하지 못한 결점이 있으리라 생각됩니다. 이글을 보신분 중 결점을 발견하셨으면 따끔한 피드백 해주시면 감사하겠습니다.
그럼 다음 논문에서 뵈요~~
- 21.5.25 : 계속해서 버그가 나타나 끝없는 수정을 거듭하다 드디어 '훈련'이 되는 모델로 만들었습니다.
그런데 데이터 전처리 방식에 의해 제대로 된 훈련을 하지 못해 성능이 아주 좋지 않습니다.
어떻게 수정하면 좋을지 고민이 큽니다. 흠...
