[논문 리뷰] Efficient Module Based Single Image Super Resolution for Multiple Problems
논문 리뷰 + 구현
안녕하세요. 밍기뉴와제제입니다. 이번에 리뷰할 논문은 'Super Resolution'을 task로 설정한 Efficient Module Based Single Image Super Resolution networks, 줄여서 EMBSR에 관한 논문입니다.
이 논문을 쓴 BMIPL은 EMBSR을 이용해 NTIRE 2018 SR challenge에서 좋은 성적을 거뒀습니다. 자세한 설명은 논문 리뷰에서 하도록 하겠습니다.
그러면 지금부터 논문 리뷰를 시작하겠습니다.
1. Introduction
딥러닝 알고리즘이 이미지 처리에 본격적으로 사용되기 시작하면서 Super Resolution의 성능은 급 향상되었습니다. Super Resolution을 Task로 하는 네트워크는 RCNN, VDSR, SRResNet, EDSR 등이 있는데요, 이중 EDSR은 최대신호 대 잡음비(Peak Signal-to-noise ratio, PSNR)와 구조적 유사도(structural similarity index, SSIM)에서 가장 높은 성능을 기록했고 NTIRE 2017 SR challenge에서 1위를 기록한 네트워크입니다.
NTIRE SR challenge : NTIRE(New Trends in Image Restoration and Enhancement workshop, CVPR workshop중 하나)에 제출된 논문에 설명된 네트워크들로 치뤄지는 대회입니다. 학습과 검증용 데이터셋을 제공해주며 다양한 Track으로 구성되어 있습니다.
(좌 : bicubic downscaling, 중 : 약한 노이즈 + downscaling, 우 : 강한 노이즈 + downscaling)
BMIPL이 참가한 2018년 challenge는 4개의 Track이 있는데 BMIPL은 Track 1~3만 참가했습니다.
Track별 설명과 사진은 다음과 같습니다. 첨부된 사진으로는 크나큰 차이가 보이지 않지만 데이터셋을 직접 다운받아서 확인하시면 눈에 보일 정도의 차이가 보임을 알 수 있습니다.
Track 1 : bicubic downscaling한 이미지를 8배 Super Resolution
Track 2 : 약한 노이즈 + 블러 + downscaling을 적용한 이미지를 4배 Super Resolution
Track 3 : 강한 노이즈 + 블러 + downscaling을 적용한 이미지를 4배 Super Resolution

Track1, 2, 3는 각각 입력값으로 넣어야할 데이터 종류가 다릅니다. 허나 이를 크게 보면 2가지 종류의 데이터로 분류할 수가 있습니다. 바로 '노이즈가 있는 데이터(Track 2, 3)'와 '노이즈가 없는 데이터(Track 1)'입니다. 그래서 BMIPL은 다음과 같이 Track1에서 사용할 해결방식과 Track2, 3에서 사용할 방식을 만들었습니다. 총 2가지 방식으로 Track 1~3의 문제를 해결하는 것이죠.
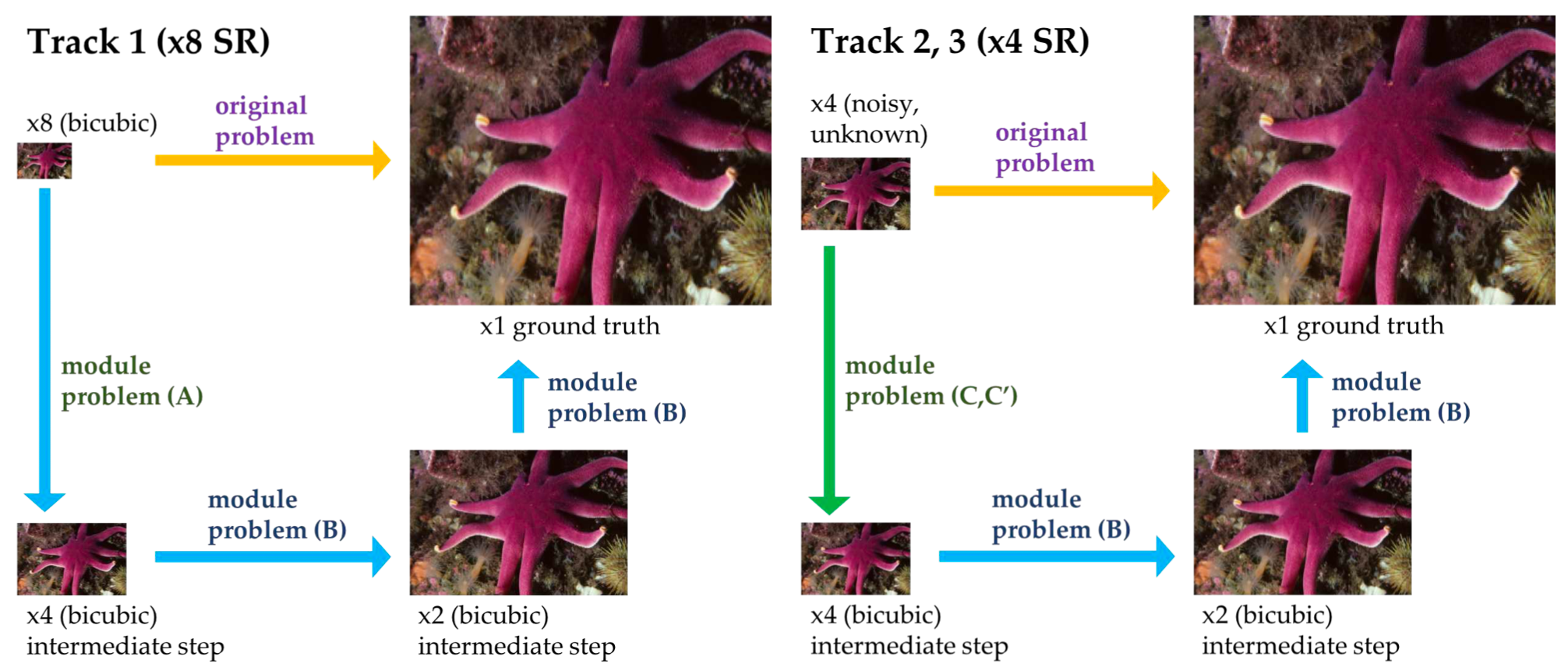
그림을 보시면 아시겠지만 두가지 방식 모두 module problem(B)가 들어가있습니다. 이말은 즉, module problem(B)를 해결하는 네트워크가 같은 종류라는 것이죠.
그렇기 때문에 Track1을 위한 네트워크를 학습시킨 뒤 Track 2,3을 위한 네트워크를 만들 때 Track1의 module problem(B)를 해결하는데 쓰인 네트워크를 재활용할 수 있습니다. 학습시간이 줄어드는 것이죠. 학습시간을 줄일 수 있다는건 크나큰 이점입니다.
그렇다고 Track1의 module problem(B)에 사용한 네트워크를 그대로 Track 2,3에 사용할 수는 없습니다. 왜냐하면 Track2,3의 module problem(B)에 쓰인 네트워크는 Track1의 module problem(B)에 쓰인 네트워크와는 달리 noise가 '줄어든' 이미지를 받기 때문입니다. 이말은 즉, Track1에 쓰인 네트워크를 조금 가공해서 Track 2,3에 써야한다는 말이죠. 이에 대한 설명은 후에 자세히 하도록 하겠습니다.
아무튼, BMIPL은 위와 같이 두가지 접근법으로 Track 1~3을 해결하는 네트워크를 설게하였고 Track1에서 24팀 중 9위, Track2에서 18팀 중 2위, Track3에서 18팀 중 3위를 기록하며 그 우수함을 증명했습니다. 큰 성과라고 할 수 있겠습니다.
2. Method
이제 EMBSR의 구조에 대해 자세히 설명드리겠습니다.
우선 EMBSR은 풀네임에서 확인할 수 있듯 network'들'입니다. 정확히는 2가지 네트워크가 속해있는데요, 간략히 설명드리면 다음과 같습니다.
- EDSR-PP : EDSR을 기반으로 만들어진 네트워크입니다. EDSR에 Pyramid Pooling(PP)이 추가되었으며 Super Resolution을 담당합니다.
- DnResNet : DnCNN을 기반으로 만들어졌습니다. DnCNN에 ResNet에서 쓰인 residual learning을 도입하였고 Denoising / Deblurring을 담당하고 있습니다.
그럼 지금부터 EMBSR을 이용한 네트워크 설게 방식과 EDSR-PP, DnResNet에 대한 자세한 설명을 시작해보겠습니다.
2-1. Modular Approach
Modular Approach은 앞서 보신 그림과 같이 모듈 단위로 문제 해결 방식을 설게하는걸 말합니다. 여기서 모듈은 EDSR-PP, DnResNet와 같은 네트워크를 말하는데요, 커다란 네트워크를 구성하는 부분적인 네트워크를 나타내기 위한 표현방법으로 module을 선택한게 아닌가 싶습니다.
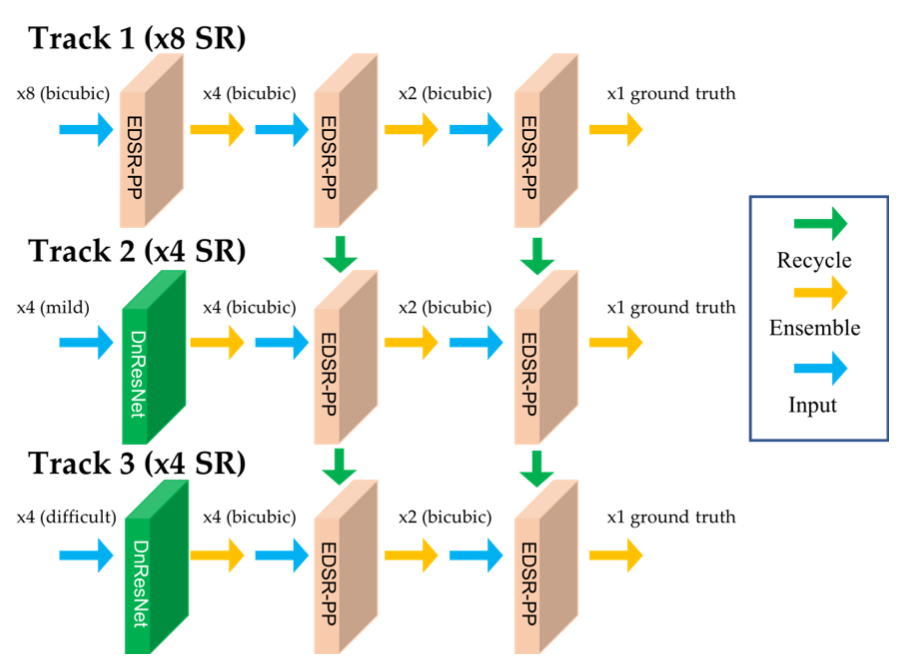
위 그림이 바로 Track별 Modular Approach를 표현한 그림입니다. 앞서 설명했듯 Track1과 Track 2,3에서 사용한 방식이 각각 다르다는 것을 알 수 있습니다.
여기서 Ensemble, Recycle에 대한 설명은 다음과 같습니다.
- Ensemble : 각 모듈에 8종류(이미지 회전 4번 * 좌우 뒤집기 = 8종류)의 입력 이미지를 넣어서 얻을 수 있는 8종류의 output을 하나로 합치는 것을 말합니다. EMBSR은 Ensemble output을 이용해 PSNR에 대한 성능 향상을 이뤄냈습니다.
- Recycle : 말 그대로 모듈을 재사용하는 것을 말합니다. BMIPL은 Track1에서 사용한 EDSR-PP를 Track2에서 사용하고 Track2에서 사용한 EDSR-PP를 Track3에서 사용했습니다. 앞서 말했듯 각 Track별로 받는 input의 종류가 조금씩 다르기 때문에 short fine tuning을 하고 재사용 했습니다. BMIPL은 모듈 재사용 덕분에 5개의 모듈만 학습시켜 Track 1~3을 해결할 수 있었습니다. 5개 모듈만 학습시켜 9개 모듈을 학습시킬 때와 같은 성과를 낸 것이죠.
그리고 Modular Approach의 마지막 부분을 보면 Track 1의 EDSR-PP에서 나온 ensemble output으로 Track 2의 EDSR-PP를 재학습 하고 Track 2의 EDSR-PP에서 나온 ensemble output으로 Track 3의 EDSR-PP를 재학습하니 더 높은 성능이 나왔다고 적혀있습니다.
2-2. SR Module: EDSR-PP (Pyramid Pooling)
이제 EDSR-PP에 대한 설명을 하도록 하겠습니다. 앞서 말씀드렸듯 EDSR-PP는 Super Resolution을 담당하며 EDSR에 Pyramid Pooling을 추가한 네트워크입니다.
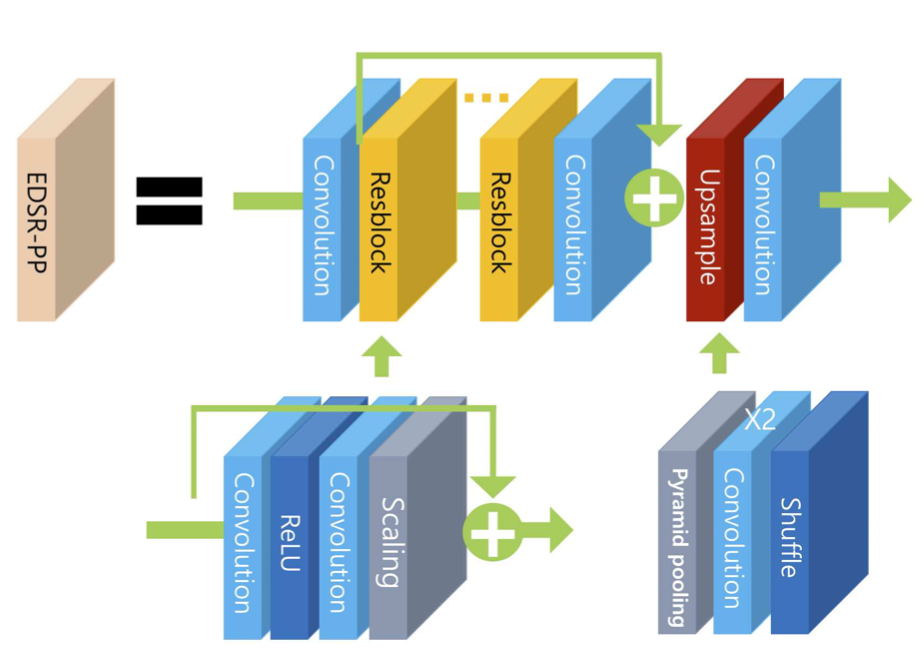
위 그림은 EDSR-PP의 구조를 나타낸 그림입니다. EDSR-PP는 32개의 Residual block이 계속 이어지다 Upsample layer과 Conv layer를 통과하는 구조인데요, Upsample layer에 Pyramid pooling이 포함되어있습니다.
Pyramid Pooling?
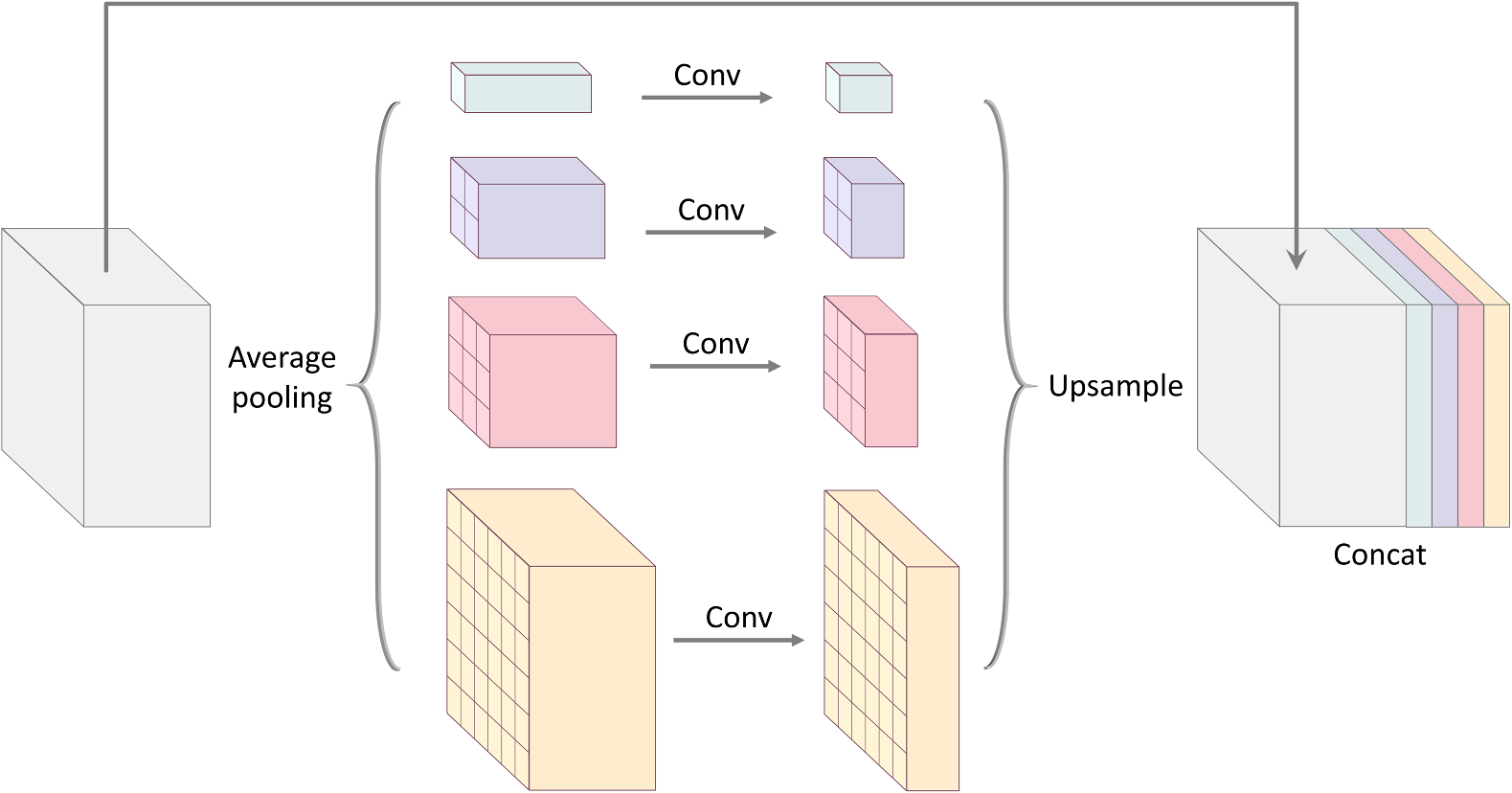
Pyramid Pooling은 average pooling과 Conv layer를 4번 거쳐 총 4가지 scale을 가진 feature map 4개를 생성한 뒤 입력받은 feature map에 이어붙히는(concatenated) pooling 입니다. 그림으로 나타내면 다음과 같습니다. (그림 출처)
EDSR-PP는 Pyramid Pooling에 사용한 Pyramid scale을 1 × 1, 2 × 2, 3 × 3, 4 × 4 로 설정했습니다. 즉, average pooling을 통해 1 × 1, 2 × 2, 3 × 3, 4 × 4 크기의 특성맵을 추출, upsampling하고 입력 특성맵과 합치는 것이죠.
2-3. Denoising / Deblurring Module: DnResNet
다음으로 Denoising / Deblurring을 수행하는 DnResNet에 대해 설명해 드리겠습니다. DnResNet는 앞서 간단히 말씀드렸듯 DnCNN에 residual learning을 도입한 네트워크입니다.
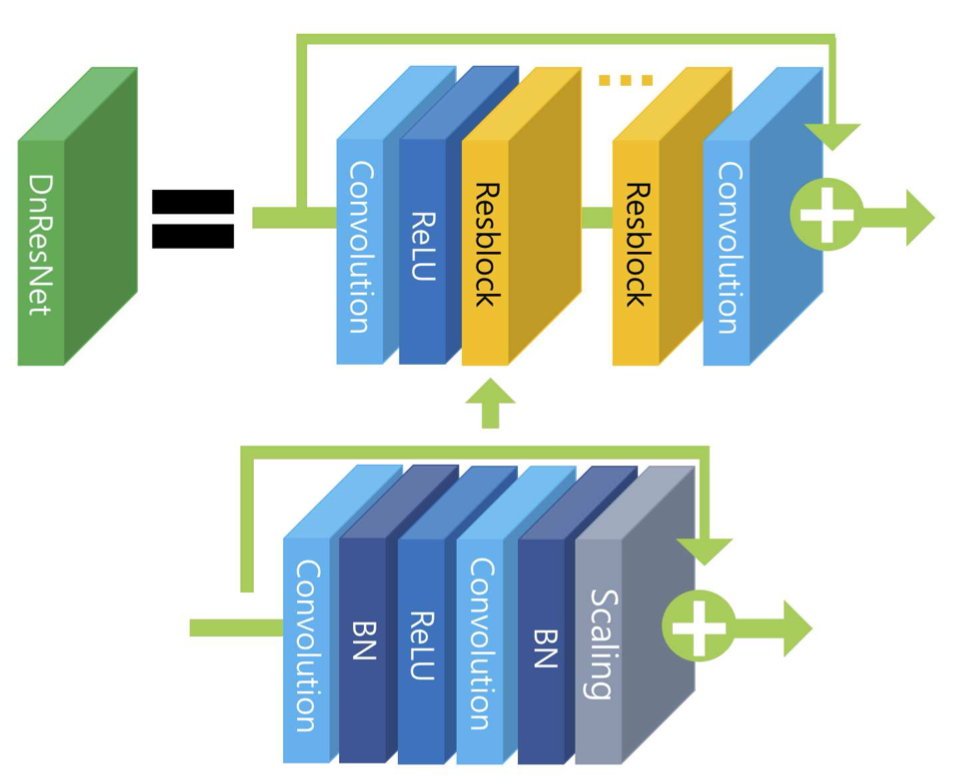
구조는 위와 같습니다. DnCNN에 있던 Conv Layer를 모두 Resblock으로 대체하였고 Conv layer의 channel 개수를 64개에서 128개로 늘렸습니다.
Resblock에 대한 추가적인 이야기
DnResNet의 residual block은 EDSR의 residual block과 굉장히 유사합니다.
EDSR은 SRResNet의 resblock에서 BN(Batch Normalization)을 빼고 0.1 Scaling을 추가했으며 그 결과, Super Resolution의 성능과 학습의 수치 안정성(numerical stability)이 증가했습니다. 그런데 DnResNet은 EDSR의 resblock에서 다시 BN을 추가했는데요, 그 이유는 resblock에 BN을 유지하는게 denoising and deblurring에 이점이 있음을 발견했기 때문입니다.
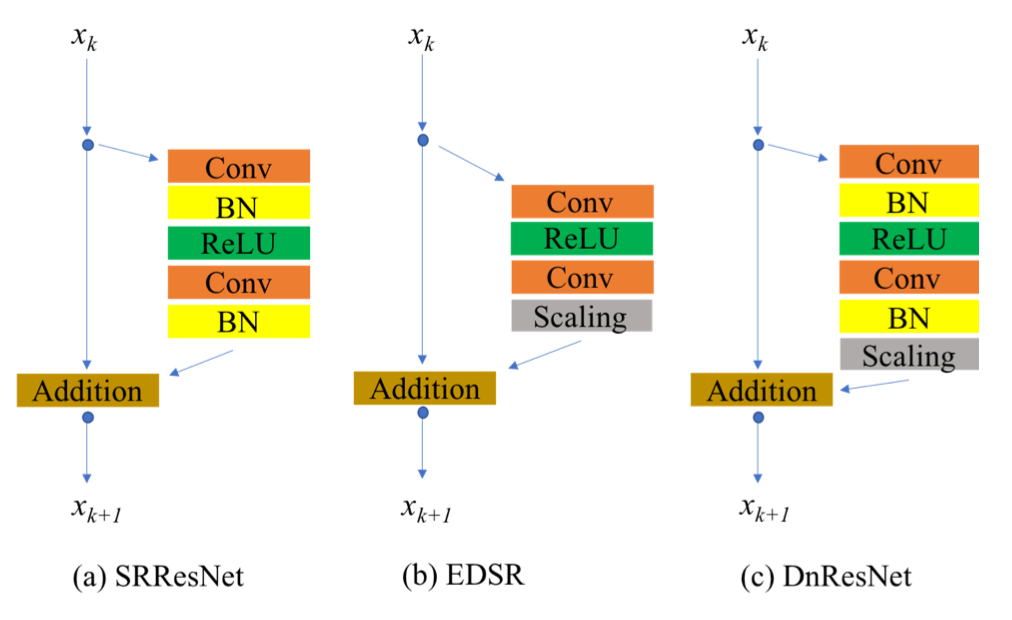
DnResNet은 Conv layer대신 Residual block을 사용한 덕분에 denoising and deblurring에서 더좋은 성능을 보여줬다고 합니다.
3. Experiment
학습 방법과 성능 측정 결과가 나와있는 부분입니다.
3-1. Dataset
BMIPL은 논문에서 수행한 실험에 쓰인 모델들을 모두 NTIRE 2018 challenge에서 제공하는 DIV2K으로 학습시켰습니다. 앞서 말씀드렸듯 DIV2K는 Track1, 2, 3을 위한 학습, 검증용 데이터셋이 들어있습니다. Track별로 제공되는 입력 데이터의 종류가 다르며 출력 데이터(라벨 데이터)는 노이즈가 없는 2K해상도의 이미지입니다. Track별로 제공되는 입력 데이터를 설명하면 다음과 같습니다.
- Track 1 : 8배 bicubic downsampling된 이미지
- Track 2 : 4배 downsampling + unknown blur kernels and mild noise가 적용된 이미지
- Track 3 : 4배 downsampling + with unknown, difficult blur kernels and noise가 적용된 이미지
각 Track별로 학습용 이미지 800장과 검증용 이미지 800장을 제공하며 2K이미지 역시 800장입니다.
3-2. Training and Alignment
학습에 사용한 hyper parameter를 정리하면 다음과 같습니다.
- 미니배치 사이즈 : 16
- 패치 크기 : 48×48(패치 단위로 Super Resolution을 수행합니다.)
- 에포크 횟수 : 300(retraining인 경우 100)
- 학습률 : 1~100 에포크에는 0.0001, 101~300 에포크에는 0.00001
각 네트워크를 300에포크로 학습시킬 때마다 3일씩 걸렸다고 합니다. Modular Approach에 따르면 총 5개의 모듈을 학습시키니 학습에 최소 15일이 걸렸음을 알 수 있습니다.
그리고 BMIPL은 Tracks 2, 3의 입력 데이터셋과 ×4 bicubic downsampled ground truth images(DIV2K 사이트에서 제공합니다)이 제대로 align되어있지 않았다는 사실을 발견해 따로 alignment를 수행했습니다.
논문에서 alignment는 학습 중에 네트워크가 관리해야만 하는 사항이지만 직접 데이터를 align하면 성능 향상에 도움이 된다고 나와있습니다. 성능 향상을 위해 따로 alignment를 수행한게 아닌가 추측해봅니다.
BMIPL은 MATLAB의 image processing toolbox에 있는 image registration을 이용해 Tracks 2, 3의 입력 데이터셋과 ×4 bicubic downsampled ground truth images의 align을 수행했습니다. translation motion만 했다고 하네요.
그리고 sub-pixel accuracy를 위해 Bicubic interpolation을 수행했습니다.
3-3. DIV2K Validation Set Results
여기서는 DIV2K에 있는 검증 데이터셋으로 수행한 실험들의 결과를 설명합니다.
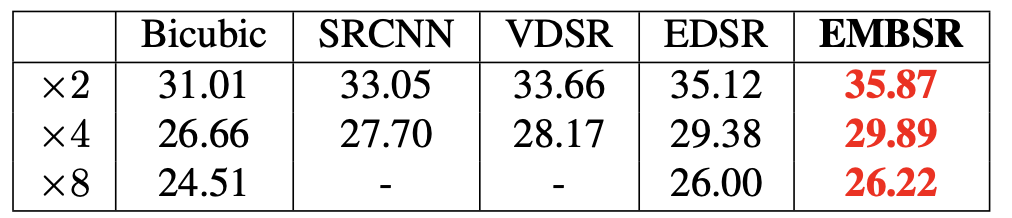
우선 PSNR의 측정 결과입니다.(단위는 dB입니다.) 여기서 EMBSR은 EDSR-PP기반의 EMBSR을 말합니다. 즉, EDSR-PP의 성능이 나타난 테이블이라 볼 수 있습니다.
표를 보니 EMBSR이 가장 높은 성능을 기록했습니다.

다음으로 직접 데이터셋 align을 수행했을 때 성능 변화를 나타낸 표입니다. align을 수행했을 때 많은 성능 향상이 일어났다는 것을 확인할 수 있습니다. 그리고 여기서 주목할 점이 또 있습니다. 바로 EMBSR의 DnResNet가 논문이 쓰일 당시 가장 성능이 좋은 denoising / deblurring method였던 DnCNN을 이겼다는 것입니다.
3-4. Results of NTIRE 2018 SR Challenge
NTIRE 2018 SR Challenge에서 EMBSR 기반 네트워크의 성적을 좀더 자세히 살펴보는 항목입니다.
Track 1
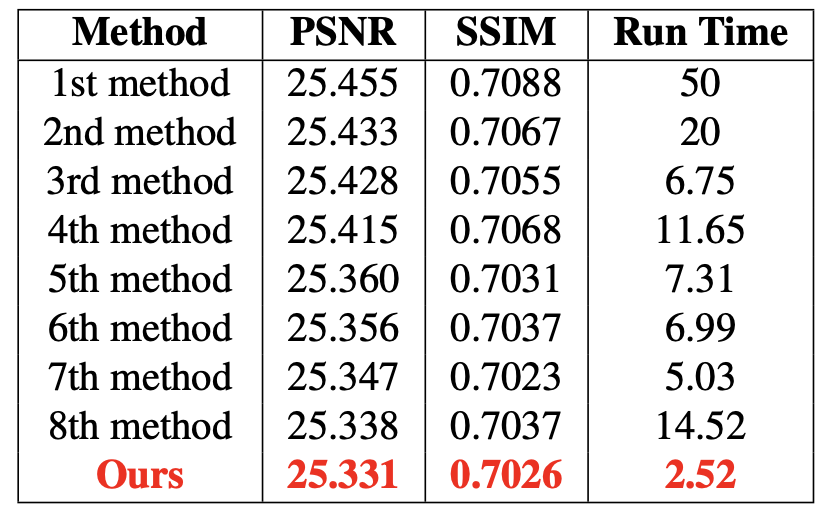
우선 노이즈 없는 이미지를 8배 Super Resolution하는 Track1입니다. PSNR 25.331, SSIM 0.7026, 실행시간 2.52 sec을 기록했습니다.
비록 9위를 했지만 1위와 PSNR은 0.124 dB, SSIM은 0.0062밖에 차이나지 않습니다. 그리고 실행속도는 상위 9개 중에 가장 빠르다는 걸 알 수 있습니다.

위 그림은 Track1의 결과를 표가 아니라 정성적 결과(qualitative results)로 나타낸 겁니다. EDSR보다 EMBSR의 PSNR이 더 높게 나왔다는걸 확인할 수 있습니다.
Track 2
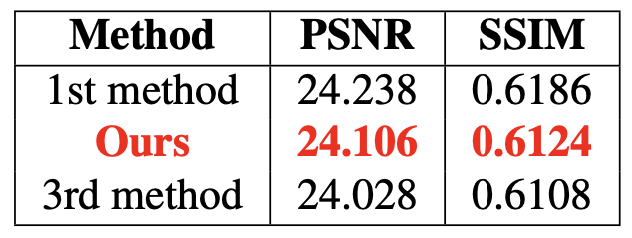
약한 노이즈 + 블러 + downscaling을 적용한 이미지를 4배 Super Resolution하는 Track2에서는 PSNR 24.106, SSIM 0.6124을 기록하며 18팀 중 2위를 기록하였습니다. 정성적 결과로 나타내면 다음과 같습니다.

여기서도 EMBSR이 EDSR보다 성능이 좋습니다.
Track 3
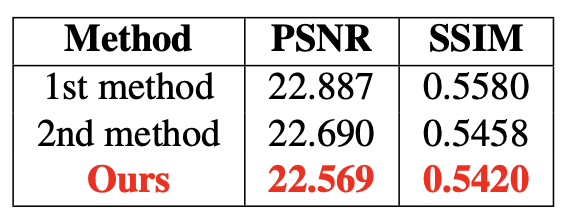
강한 노이즈 + 블러 + downscaling을 적용한 이미지를 4배 Super Resolution하는 Track3에서는 PSNR 22.569, SSIM 0.5420을 기록하며 18팀 중 3위를 기록하였습니다. 정성적 결과로 나타내면 다음과 같습니다.

여기서도 EMBSR이 EDSR보다 성능이 좋습니다.
정성적 결과들을 보시면 알겠지만 Track 2, 3에서 EDSR로 얻은 사진들이 노이즈와 블러로 인한 왜곡이 지워지지 않았음을 알 수 있습니다. 이를 통해 EDSR이 다양한 Super Resolution의 task에서 제대로 작동하지 않음을 알 수 있습니다. 허나 EMBSR로 만든 네트워크는 Track 2, 3에서 노이즈와 블러가 상당히 지워진 결과값을 출력한다는 사실을 확인할 수 있고 Track 1역시 Super Resolution을 훌륭히 수행했다는 것도 보실 수 있습니다.
즉, 다양한 Super Resolution task에서 제대로 작동한 것입니다. BMIPL은 modular approach가 주어진 상황에 맞는 적절한 네트워크를 구성하게 해줬기 때문에 이와 같이 다양한 문제에서 모두 좋은 성능을 보여줬다고 판단했습니다.
4. 결론
결론에서는 '결론'이라는 이름에 충실하게 앞서 말했던 것들을 한데 요약한 내용이 적혀있습니다.
리뷰 후기
이렇게 리뷰 논문이 끝이 났습니다. Super Resolution을 구현한 논문을 이렇게 본격적으로 읽어본건 이번이 처음인데요, 상당히 흥미가 갑니다.
그리고 이렇게 네트워크를 모듈로 취급하고 모듈 단위로 설명하는 것도 신기했습니다. 논문을 읽으며 이번학기에 배운 자동제어와 통신공학에서 배운 것들이 계속 떠올라 더 수월하게 논문을 읽을 수 있었습니다. 전혀 생각지도 못한 부분에서 이렇게 도움을 받을줄은 몰랐네요.
좋은 논문이었습니다.
그러면 다음 논문리뷰에서 뵙겠습니다.
