안녕하세요 밍기뉴와제제입니다.
요즘 제가 참여한 활동들이 다 마무리 단계에 들어서면서 스스로 논문 읽기에 대한 열정이 좀 식었다는걸 느꼈습니다. 이러면 안되죠.
그래서 다시 한 번! 스스로 동기부여해서 논문을 읽고 있습니다. 제가 읽을 논문은 아주아주 많이 있으니 이들을 다 읽기 전까진 논문 읽기를 멈추지 않았으면 좋겠습니다. 제발...🙏
오늘 리뷰할 논문은 SSD(Single Shot Multibox Detector)입니다. 정식으로 저널에 실리거나 컨퍼런스에 발표된 논문은 아니지만 인용된 횟수가 16000회를 넘긴 엄청난 논문입니다. 구글에서 인턴십 프로젝트로 시작해 노스캐롤라이나 대학교 채플힐(UNC Chapel Hill)에서 완성된 논문인데요, 참 대단한 사람들입니다. 크으...
논문을 제대로 잘 알지 못하는 저조차도 수월하게 읽은 논문입니다. YOLO와 모델 구조가 상당히 비슷하기 때문에 YOLO를 읽고 SSD를 읽으시는걸 추천드립니다.
그러면 지금부터 논문 리뷰를 시작하겠습니다.
Introduction
여기서는 SSD가 왜 나왔는지 설명해줍니다. Object Detecion을 수행하는 모델 중 Faster R-CNN은 너무 느리고 속도가 빠른 모델도 있는데 그건 성능이 안좋다고 말하며 기존에 존재하는 모델들이 가지고 있는 아쉬운 점들을 말합니다.
아쉬운 점을 모두 설명하고 난 뒤, 우리들이 속도와 성능 모두 최고인 Deep network based object detector를 처음으로 제안했다고 합니다. Faster R-CNN처럼 RoI를 사용하지 않으면서 Faster R-CNN만큼 성능이 좋은 모델을 만들었다고 하는 것이죠.
그리고 Faster R-CNN처럼 RoI를 생성 후 RoI Pooling하는 과정을 제외해 속도도 빨라졌다고 말합니다.
SSD는 backbone에서 추출된 feature map을 head가 처리하는 방식이 아니라 추출 과정에서 생긴 feature map들을 3 x 3 사이즈의 커널을 사용한 Convolutional Neural Network(CNN)로 연산해 해당 feature map에 있는 객체 정보를 얻습니다. 다양한 feature 사이즈에서(논문에서는 multi scale이라고 합니다) 객체 탐지를 수행하기 위함이라고 하네요.
이런 방식으로 객체를 추출한 덕분에, SSD는 상대적으로 낮은 입력 이미지 해상도에서도 좋은 성능과 빠른 속도를 보여줄 수 있었다고 합니다. YOLO는 448 x 448 해상도의 이미지를 사용하지만 SSD는 VGG-16기반이라 224 X 224 해상도의 이미지를 사용하기 때문에 작은 이미지 해상도를 가지고도 성능이 더 잘나온다는 말을 한게 아닌가 싶습니다.
그리고 Introduction의 마지막에 자신들이 기여한 내용(?)을 다음과 같이 요약했습니다.
- YOLO보다 빠르고 Faster R-CNN보다 성능 좋은 SSD를 소개했다
- SSD의 핵심은 커널 사이즈가 작은(3x3) CNN을 사용해 개수가 일정한 Bounding Box의 위치와 클래스 정보를 예측하는 것이다.
- 정확도를 높이기 위해 가로세로 비율(aspect ratio), 크기(scale)에 따라 Bounding box를 여러개(논문에서는 separate라고 말합니다) 예측했다.
- SSD는 사람들이 단순하지만 성능 좋은 모델, 낮은 해상도의 이미지를 가지고도 좋은 성능을 내는 모델, 속도 vs 성능의 trade-off를 개선한 모델을 디자인 하게끔 만들 것이다(논문에서는 lead라고 말합니다)
- 논문의 Experiment 항목에서 다양한 데이터셋(PASCAL VOC, COCO, ILSVRC)을 가지고 속도, 성능을 테스트해봤고 가장 잘나가는(state-of-the-art) 모델들과도 성능, 속도를 비교해봤다.
이 부분을 읽으며 저자들이 논문을 얼마나 대견하게 여기는지 알 수 있었습니다.
The Single Shot Detector (SSD)
여기서는 SSD의 구조, 훈련 방법을 소개해줍니다.
Model
먼저 SSD의 구조에 대해 소개해 드리도록 하겠습니다. SSD는 앞서 말씀드렸듯이 일정한 개수(fixed-size collection)의 Boundig box를 non-maximum suppression(NMS)를 적용해 최종 예측값을 출력하는 객체 탐지 모델입니다.
SSD는 특성 추출을 담당하는 early-stage와 객체 탐지를 담당하는 auxiliary structre가 있습니다. early-stage는 base network라고 부르기도 하는데요, 이는 backbone과 비슷한 역할을 합니다. 저자는 VGG-16을 가지고 early-stage를 만들었습니다.
auxiliary structre는 아래에 있는 3개의 항목을 통해 차례대로 설명해 드리겠습니다.
Multi-scale feature maps for detection
auxiliary structre는 다양한 크기의 특성맵에서 객체를 예측합니다. base network에서 얻어낸 feature map으로 객체를 예측하고 여기에 CNN과 pooling을 적용해 한번 더 특성이 추출된(사이즈가 줄어든) feature map을 얻습니다. 그리고 이를 가지고 객체를 예측하고 더 크기가 줄어든 feature map을 얻고...같은 과정을 여러번 반복합니다.
Convolutional predictors for detection
그러면 객체를 어떻게 예측하는지 알아봅시다. SSD는 객체 p장의 3 x 3사이즈의 커널이 있는 CNN으로 객체를 예측합니다. 그러면 언제나 일정한 사이즈의 예측값이 나오게 되겠죠. 저자는 이를 'produce a fixed set of detection predic- tions using a set of convolutional filters'라고 말했습니다.
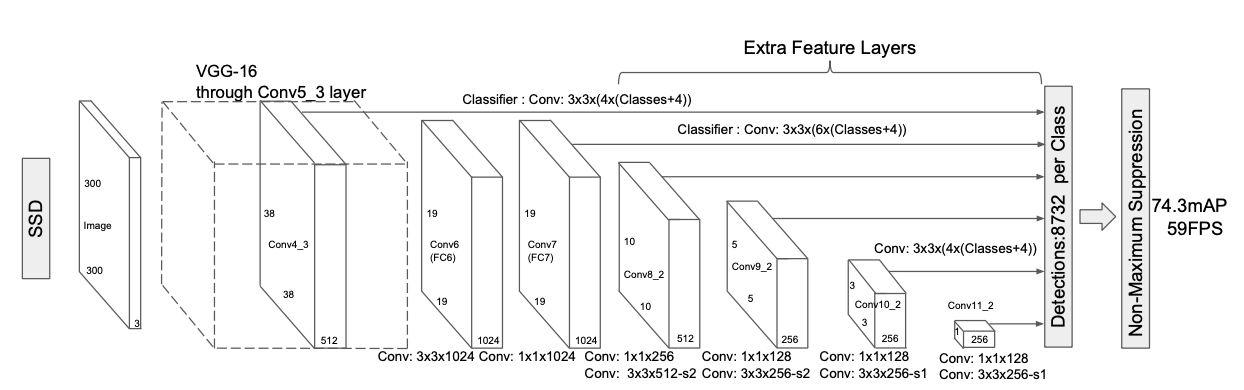
SSD의 구조를 표현한 그림을 보시면 이해가 더 쉬워지실 겁니다.
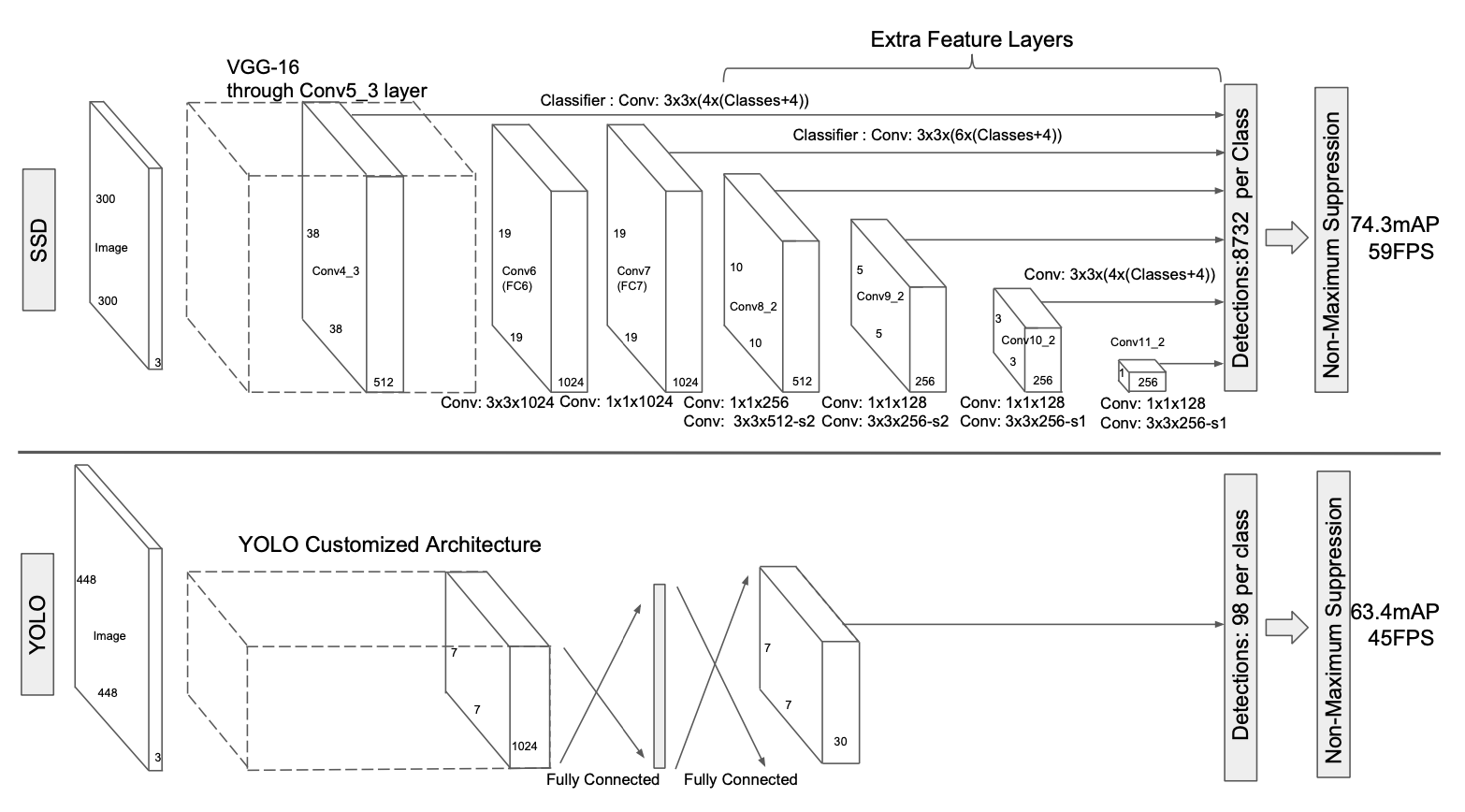
위 그림은 SSD와 YOLO의 구조를 비교한 그림입니다. Base network에서 얻은 Feature map으로 객체를 예측(위쪽 Classifier: Conv)하고 특성 추출(아래쪽 Conv)을 해 크기가 줄어든 Feature map을 얻는데 이 과정을 반복적으로 수행한다는 사실을 알 수 있습니다.
그렇게 해서 SSD는 총 8732개의 예측값(Bounding box, class score)를 얻는데 이는 YOLO가 예측한 값보다 훨씬 많습니다. 성능이 더 좋을 수 밖에 없다고 생각합니다.
예측한 bounding box의 값은 'kernel이 컨볼루션 연산을 적용한 영역(feature map 내 하나의 픽셀을 말합니다) 내 중심좌표와의 offset'입니다. 값의 크기를 줄이기 위해 이런 방식을 사용한게 아닐까 추측해봅니다.
Default boxes and aspect ratios
앞서 각 영역에 컨볼루션 연산을 적용할 때 p장의 3 x 3사이즈의 커널을 사용한다고 말씀드렸습니다. 즉, 각 영역에서 p개의 값을 추출한다는 뜻이죠. 그러면 p개의 값은 어떻게 구성되어 있을까요?
우선 각 영역에 존재하는 객체가 어떤 객체인지 예측하는 c개의 값이 들어있습니다. 그리고 컨볼루션 연산을 적용한 영역의 중심 좌표와의 x, y offset, 영역의 w, h offset이 들어있습니다. 총 4+ c개의 값이 들어있는 것이죠. 다시 말해 p = c + 4인 것입니다. confidence score가 없다는걸 제외하면 YOLO와 같습니다.
저자는 이 과정을 다양한 사이즈의 feature map에서 수행했습니다. 그러니까 다양한 크기의 bounding box로 객체를 예측하는 것이죠. 효과적인 방식입니다.
Training
YOLO와 비슷한 전략(?)을 취합니다. 바로 실제 객체가 있는 곳에서 예측한 값만 가지고 loss를 계산하는 것이죠.
저자는 훈련 과정을 다음과 같이 다섯 가지로 분류했는데요, 하나씩 설명해 드리도록 하겠습니다.
Matching strategy
앞서 말씀드린 실제 객체가 있는 곳에서 예측한 값만 가지고 loss를 계산하는걸 구체적으로 설명한 부분입니다.
저자는 객체가 있는 곳(=Ground truth box가 있는 곳)에서 값을 예측했다는걸 판단하는 기준으로 jaccard overlap을 선택했고 jaccard overlap이 0.5가 넘는 feature map 속 영역에서 예측한 Bounding box만 loss계산에 사용했습니다. 다시 말해 컨볼루션 연산을 했을 때 객체가 검출될만한 영역에서 나온 Bounding box(matching된 Bounding box)만 loss계산에 사용하겠다는 것이죠.
이렇게 해당 조건을 만족하는 예측값만 loss계산에 사용하면 우리가 원하는 방향에 맞는 것만 loss를 계산해 모델을 학습시킬 수 있어 learning problem을 쉽게 만들어줍니다.
논문에서는 이 방식이 multiple overlapping default boxes를 탐지하는데 좋은 성능을 내게끔 한다고 말했습니다.
Training objective
Loss function을 설명하는 곳입니다. 저자는 MultiBox objective에서 multiple object categories를 추가해 Loss function을 구성했다고 말했습니다. 전체적인 Loss Function은 다음과 같습니다.
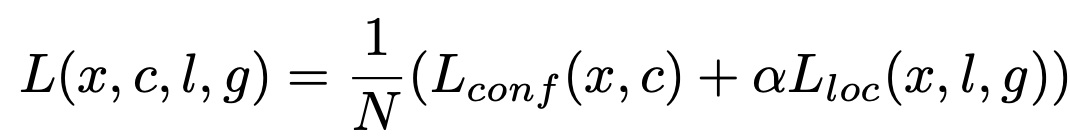
여기서 L_loc와 L_conf는 다음과 같습니다.
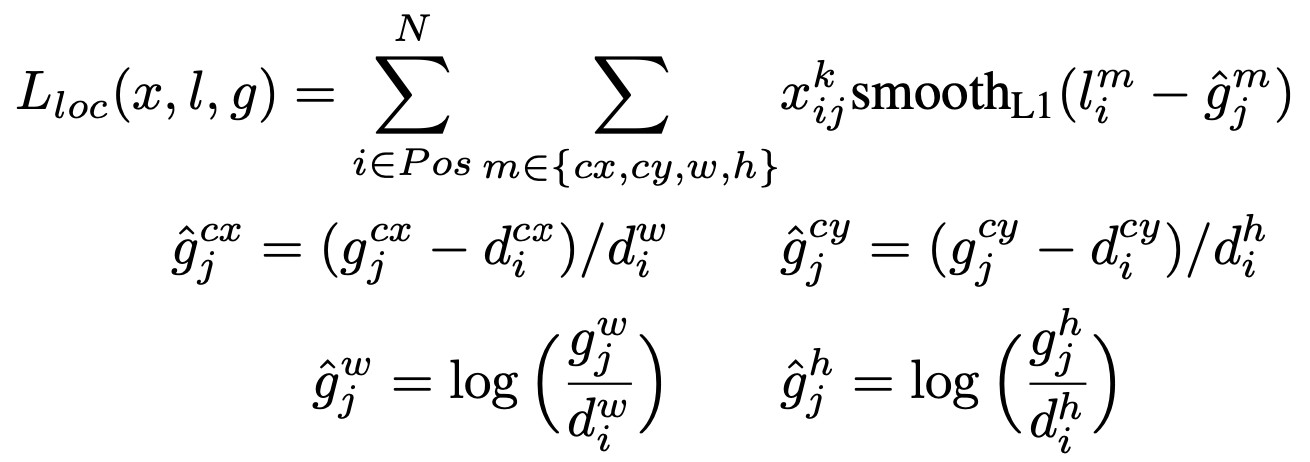
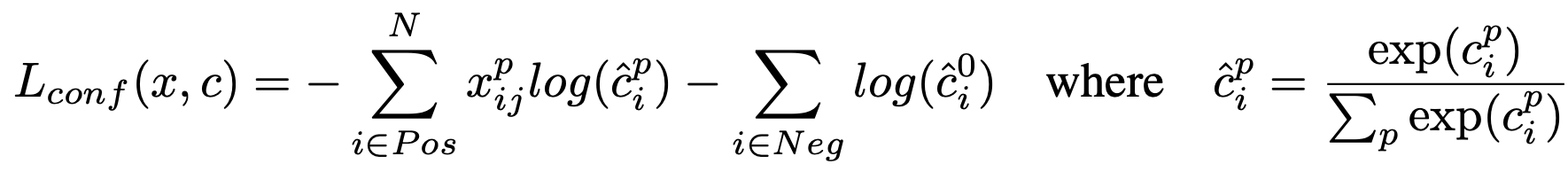
L_conf에서 (x_ij)^p는 1아니면 0인 값이고 'p 카테고리의 Ground Truth box와 matching 여부'를 나타낸다고 합니다. 저자는 Matching strategy를 통해 모든 예측값의 (x_ij)^p를 합쳤을 때 1이 넘어가게끔 만들었습니다. 여기서 p카테고리의 p는 3 x 3 사이즈의 커널 p개로 컨볼루션 연산을 할 때 p와 같습니다.
즉, matching인 Bounding box하고만 loss를 계산하겠다는걸 수학적으로 나타낸 것이죠.
그리고 L_loc에서 l은 예측한 Bounding box, g는 Ground truth box를 말합니다. L_loc를 계산할 때는 컨볼루션 연산을 적용한 영역을 나타내는 [x, y, w, h]와 각 영역을 기반으로 예측한 bounding box [x, y, w, h], 그리고 Ground truth box의 [x, y, w, h]가 필요합니다.
Ground truth box의 [x, y, w, h]는 그대로 사용하고 컨볼루션 연산을 적용한 영역과 이를 기반으로 예측한 Bounding box를 가지고 (g_j)^cx, (g_j)^cy, (g_j)^w, (g_j)^h를 만들어 (g_j)^m = [(g_j)^cx, (g_j)^cy, (g_j)^w, (g_j)^h]을 만듭니다. 그리고(g_j)^m과 Ground truth box의 [x, y, w, h]에 해당하는 값끼리 Smooth L1 loss를 계산, 하나로 합치면 L_loc를 얻을 수 있습니다.
그리고 L_conf는 confidence loss를 말하는데요, 각 위치에서 예측한 Bounding box의 class별 confidence score에 대한 loss를 구하면 됩니다.
마지막으로 α는 1로 설정했다고 합니다.
Choosing scales and aspect ratios for default boxes
SSD는 다양한 크기의 feature map에서 bounding box를 예측합니다. 서로 다른 CNN Layer에서 추출된 feature map은 서로 다른 receptive field를 가지고 있습니다. 같은 커널 사이즈를 가지고 있어도 커널이 감싸는 이미지 내 실제 영역이 다른 것이죠. 엄지 손가락으로 동전이 가려지고 지도 위 대한민국의 영역이 가려진다고 해서 동전의 영역 = 대한민국의 영역이 아니라는 것으로 비유하면 이해가 좀...쉬울려나요? 제가 비유를 잘 못합니다 ㅜㅜ
아무튼, 연속적으로 연결된 서로 다른 CNN에서 각 커널이 감싸는 영역은 scale면에서 차이가 나기 때문에 CNN들이 서로 다른 크기의 객체를 탐지하게끔 학습합니다.
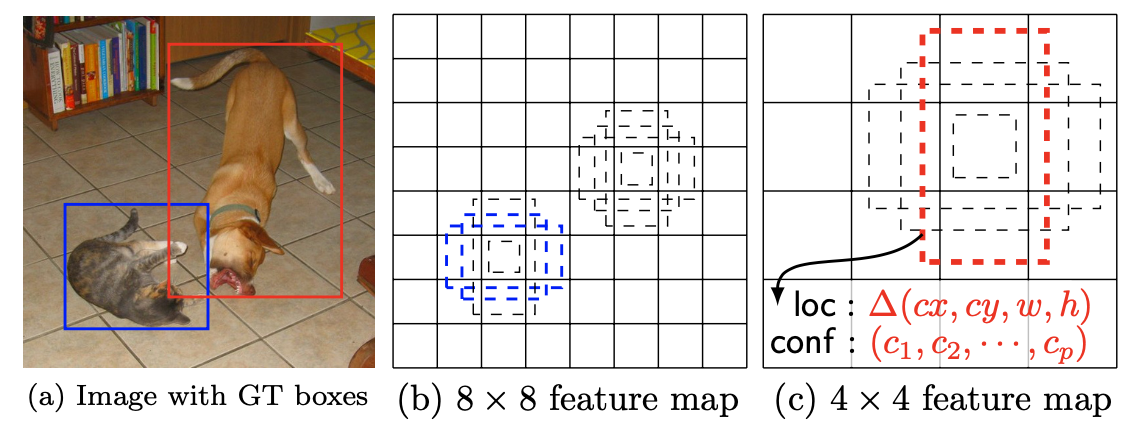
위 그림의 (b)와 (c)를 봅시다. 서로 크기가 다른 고양이와 개가 사진속에 있습니다. 크키가 작은 고양이는 CNN 연산을 적게 적용한 8 x 8 feature map, 다시 말해 구역 하나가 이미지 전체에서 차지하는 영역이 적은 feature map에서 객체를 검출하게끔 학습하고 크기가 큰 개는 CNN연산을 많이 적용해 한 구역당 이미지 전체에 차지하는 영역이 많은 4 x 4 feature map에서 검출하게끔 학습시킨다는 말이죠.
그러면 이를 어떻게 구현했을까요? 우선 각 특성맵에서 추출된 Bounding box의 w, h에 scale을 적용합니다. scale s_k에 대한 식은 다음과 같습니다.
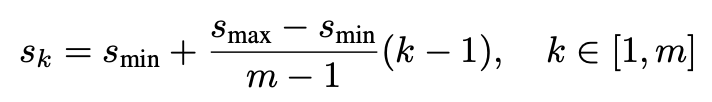
여기서 s_min = 0.2, s_max = 0.9입니다. 이렇게 해서 나온 s_k를 bounding box의 w, h에 곱하기 때문에 8 x 8 feature map에서 w=0.5, h=0.5로 나온 값과 4 x 4 feature map에서 w=0.5, h=0.5를 다르게 대할 수 있는 겁니다.
그리고 Bounding box의 aspect ratio(직사각형의 가로세로 크기 비율)도 적용했습니다. 저자는 aspect ratio를 총 5개 사용했고 이를 ar = {1, 2, 3, 1/2, 1/3}에 저장했습니다. 만약 aspect ratio가 1이면(정사각형) Bounding box의 크기를 s'_k = root(s_k * s(k+1))배 늘린다고 하네요.
Bounding box의 중심좌표 x, y도 조정합니다. feature map의 사이즈가 |f_k|면 feature map에 있는 각 영역의 중심 좌표를 [(i + 0.5)/|f_k|, (j + 0.5)/|f_k|]로 설정한다고 합니다.
그럼 이제 정리를 해봅시다.
- feature map의 각 영역에서 Bounding box (x, y, w, h)를 구합니다.
- Bounding box가 추출된 feature map에 따라 w, h에 s_k를 곱하고 aspect ratio도 곱해 한 영역에서 얻은 Bounding box를 5개로 늘립니다.
- 그리고 컨볼루션 연산이 적용된 영역의 중심 좌표를 [(i + 0.5)/|f_k|, (j + 0.5)/|f_k|]로 설정합니다. 예측한 bounding box는 컨볼루션 연산이 적용된 영역의 offset이므로 이를 이용해 입력 이미지에 대한 Bounding box 8732개를 구합니다.
저자는 이러한 과정 덕분에 SSD가 'a diverse set of predictions, covering various input object sizes and shapes'를 가질 수 있다고 말했습니다.
Hard negative mining
SSD는 주로 matching되는 Bounding box를 가지고 loss를 계산했습니다. 허나 matching이 되지않는 negative Bounding box가 matching되는 positive Bounding box보다 압도적으로 많아 언제나 loss가 잘 계산되는게 아니었습니다. positive, negative training examples의 불균형을 가져온 것이라고 할 수 있겠습니다.
그래서 negative한 영역별로 검출된 Bounding box 중 가장 높은 confidence loss를 기록한 것을 선택해 loss계산에 사용합니다. 그러면 negative한 Bounding box와 positive한 Bounding box의 개수가 그나마 비슷해지겠죠? 저자는 이 비율을 최대 3:1까지 만들었습니다.
이렇게 negative한 Bounding box를 필터링하여 빠르게 가중치를 최적화하고 안정적인 학습을 할 수 있게 만들었다고 하네요.
Data augmentation
학습 성능을 높이기 위해 대표적으로 수행하는 작업입니다. 저자는 다음의 조건 중 하나를 만족하는 training image를 선발했습니다.
- 모든 이미지
- 랜덤한 몇 장의 이미지
- 객체와의 jaccard overlap이 최소 0.1 or 0.3 or 0.5 or 0.7 or 0.9인 이미지
셋 중 하나를 만족하는 이미지를 전체 이미지 중 10~100%만큼 선발합니다. 이 때 이미지의 가로세로 비(aspect ratio)도 고려하는데요, aspect ratio가 0.5 ~ 2인 이미지만 선발합니다.
이 기준에 따라 선발된 이미지들은 resize, flip, distort 등을 적용합니다.
Experimental Results
이제 SSD를 가지고 어떤 실험을 했고, 어떤 결과가 나왔는지 설명해 드리도록 하겠습니다.
Base network
우선 실험할 때 SSD를 어떻게 만들었는지 설명해 드리도록 하겠습니다. 저자는 ILSVRC CLS-LOC dataset(ImageNet dataset, https://image-net.org/challenges/LSVRC/)을 가지고 훈련시킨 VGG-16을 사용했고 VGG-16의 fc6, fc7을 CNN으로 변경, 다섯 번 째 pooling layer의 pooling size를 (2, 2) - s2에서 (3, 3) - s1으로 변경, a' trous algorithm을 적용, fc8와 drop out 레이어를 제거하여 SSD를 구현했습니다.
그리고 SGD를 이용해 모델을 학습시켰고 이 때 학습률은 0.001, 모멘텀은 0.9, weight decay는 0.0005, 배치 사이즈는 32라고 합니다.
PASCAL VOC 2007
먼저 PASCAL VOC 2007을 사용해 학습시켰습니다. 성능은 다음과 같습니다.
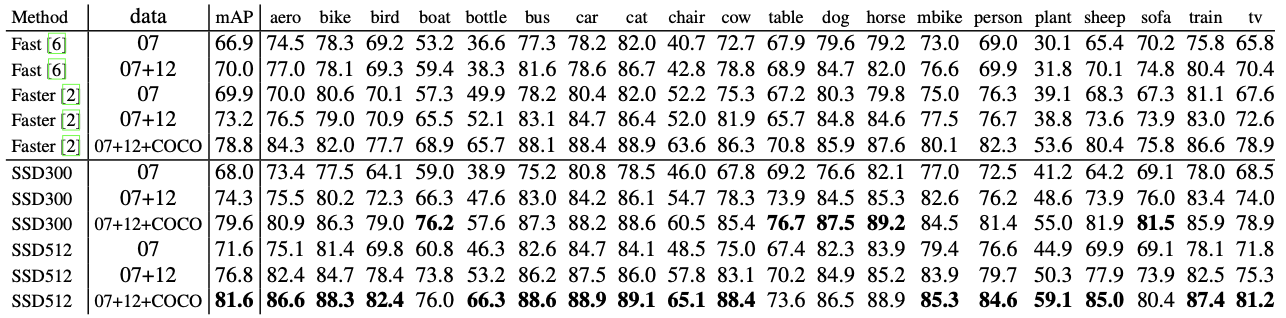
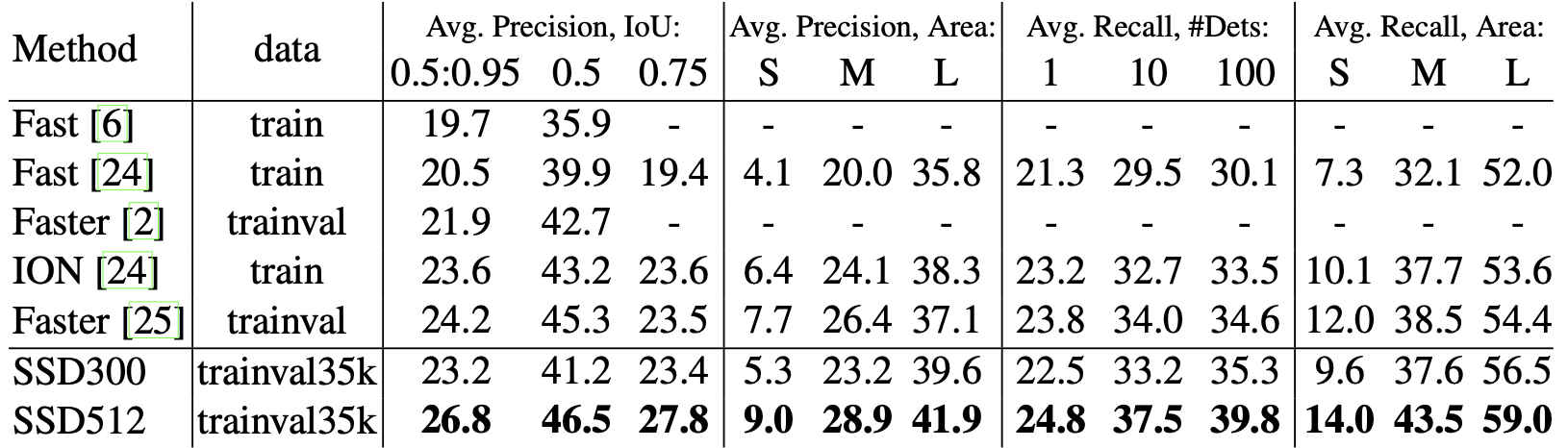
Fast R-CNN, Faster R-CNN, SSD300, SSD512의 성능을 비교한 표입니다. SSD300, SSD512는 입력 사이즈에서 차이가 납니다.(300 x 300, 500, 512 x 512)
SSD는 1-stage로 이미지에 있는 객체를 directly하게 탐지하는 걸 학습하기 때문에 낮은 localization error를 기록했으나 비슷한 종류의 카테고리(예를 들면 동물들)에 대한 성능은 낮게 나왔습니다. 이러한 이유로 여러가지 종류의 객체를 위한 위치를 공유하기 때문이라고 논문에 나와있습니다. 한 영역에서 얻어낸 Bounding box에서 동물에 대한 class 예측값이 다 비슷하게 나올 수 있는데 그런 경우를 말한게 아닌가 싶습니다.
다음 그림을 통해 SSD가 다양한 객체를 잘 검출할 수 있다는 사실을 쉽게 알 수 있습니다.

여기서 위 row에 있는 그래프는 흰색 영역이 옳게 예측한 비율, 나머지 색상은 틀리게 예측한 이유를 비율 별로 나타낸 겁니다. 아래 row에 있는 그래프를 통해 어떤 에러가 얼마나 발생했는지 확인할 수 있습니다. 그리고 빨간색 실선은 jaccard overlap이 0.5일 때 the change of recall with strong criteria를 나타내고 점선은 jaccard overlap이 0.1일 때 the change of recall with strong criteria를 나타냅니다.
또 눈여겨볼 부분은 객체 크기에 따른 탐지 성능입니다.
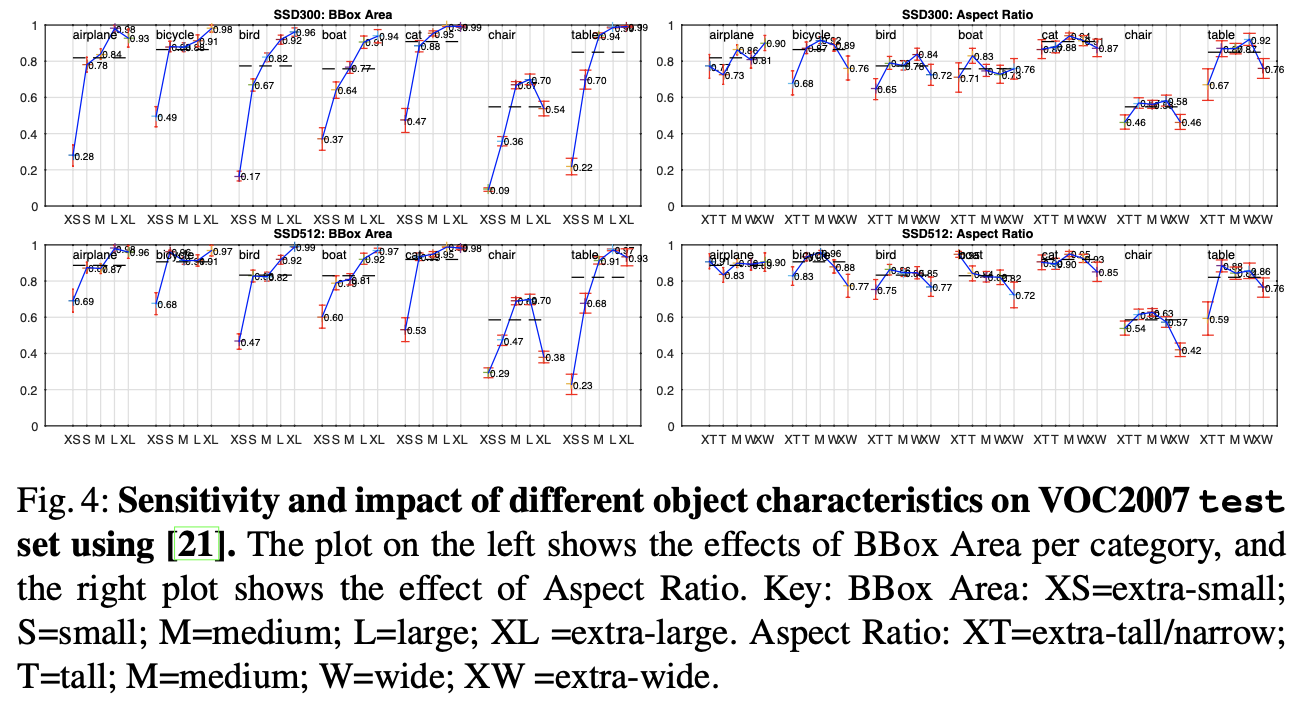
여기서 확인하실 수 있는데요, XS, S, M, L, XL은 객체의 크기를 나타내고 숫자는 성능을 나타내는 수치입니다. 객체별 크기에 따른 탐지 성능을 나타냈는데요, 대체로 객체가 클 수록 잘 탐지한다는 걸 확인하실 수 있습니다. 저자는 이러한 결과가 나온 이유로 특성이 많이 추출되어 구역당 이미지를 대표하는 영역이 가장 큰 very top layers에서 작은 객체들의 특성이 나타나지 않기 때문이라고 말했습니다. 당연한 결과라고 합니다.
저자는 입력 이미지의 해상도를 300 x 300에서 512 x 512로 늘려 아무리 특성을 추출해도 작은 객체의 특성이 조금은 남아있게 만들었습니다. 그래서 SSD312보다 SSD500이 더 성능이 좋은 것이죠. 그래도 성능을 개선해야할 부분이 남아있긴 합니다.
그리고 다양한 aspect ratio를 가진 Bounding box를 사용했기에 탐지할 객체의 가로세로 비율에 상관없이 객체를 잘 탐지한다는 것도 확인할 수 있었습니다.
Model analysis
이제 SSD에 있는 요소들을 하나씩 제거하며 어떤 요소가 성능 향상에 얼마나 기여했는지 확인해봅시다. 우선 결과부터 보여드리면 다음과 같습니다.

이를 보며 하나씩 설명해 드리도록 하겠습니다.
Data augmentation is crucial.
SSD는 YOLO에서 수행한 것과 비슷한 방식으로 데이터 증강을 수행했습니다. 데이터 증강을 통해 학습용 데이터셋의 크기를 늘리니 mAP가 무려 8.8%나 증가했습니다.
More default box shapes is better.
SSD는 컨볼루션 연산을 적용할 위치에서 총 서로 다른 aspect ratio를 가진 6개의 Bounding box를 예측합니다. aspect ratio의 개수를 6개에서 4개로 줄이니 mAP가 0.6%만큼 감소했고 여기서 2개를 더 빼니까 2.1%이나 감소했습니다. 이를 통해 다양한 aspect ratio의 Bounding box를 사용해야 좋은 성능을 낼 수 있다는 사실을 알 수 있습니다.
Atrous is faster.
SSD는 a'trous algorithm을 적용했습니다. 이게 뭐냐면 해당 지역에 컨볼루션 연산을 수행할 때 커널을 한칸씩 띄워서 연산을 적용하는 것입니다. 그림으로 설명하면 다음과 같습니다.
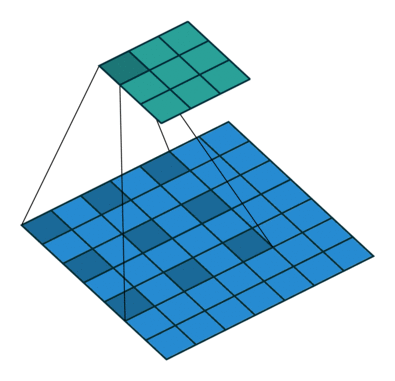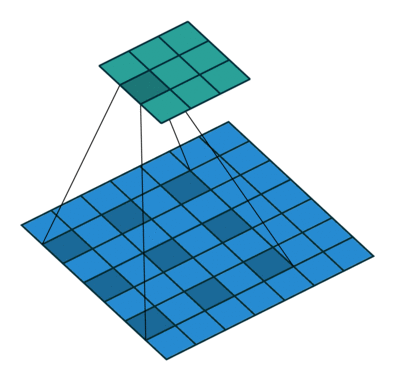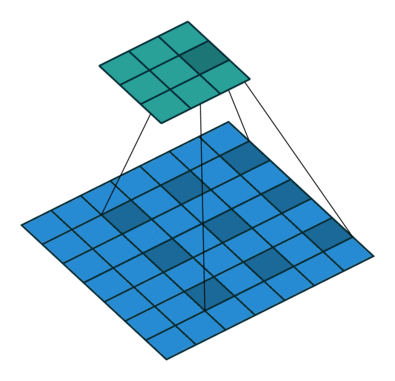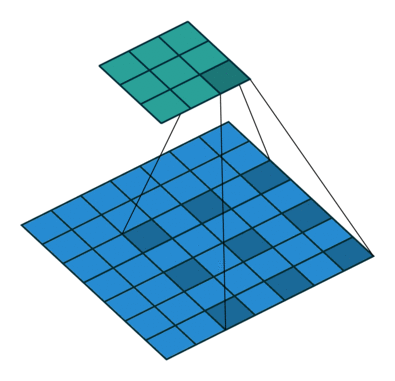
(출처 : https://eehoeskrap.tistory.com/431)
이렇게 간격을 두고 컨볼루션 연산을 수행하기 때문에 더 넓은 범위에서 특성을 추출할 수 있게 되죠. 즉, 같은 커널 사이즈를 사용해도 커널이 수용하는 영역이 넓은(receptive field가 더 넓어진) 효과를 낼 수 있습니다. a'trous convolution을 수행할 때는 pooling을 수행하지 않기 때문에 pooling으로 인한 정보의 손실도 없습니다. Object Detection같이 전체적인 Contextual Information이 중요한 분야에 적용하기 유리하다고 하네요.
자세한 설명은 여기서 확인하실 수 있습니다.
아무튼, 저자는 기본적인 Convolution대신 a'trous convolution을 사용해 연산 속도를 늘렸습니다. 만약 기본적인 Convolution을 사용할 경우 연산 속도가 20% 느려졌다고 하네요.
Multiple output layers at different resolutions is better.
다양한 feature map에서 객체를 예측하는게 SSD의 큰 특징이라고 볼 수 있습니다. 과연 이렇게 객체를 예측하는게 실제로 성능 향상에 기여할까요? 실험 결과, 다음과 같았습니다.
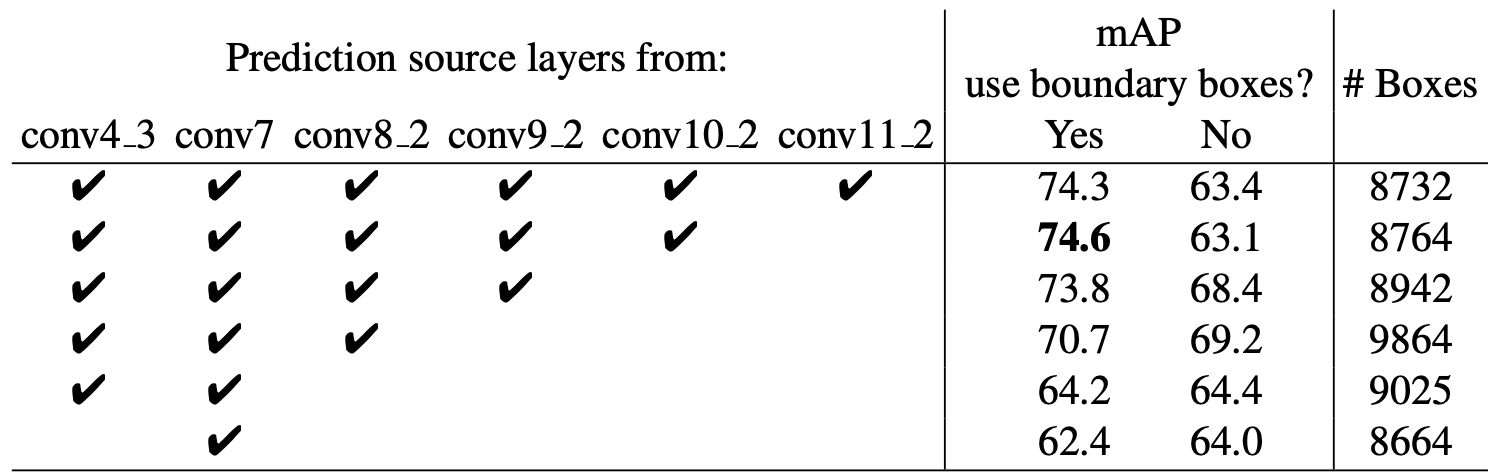
보시면 예측에 사용된 feature map이 많아질 수록 성능이 늘어난다는 사실을 확인하실 수 있습니다. 저자는 전체적인 box개수를 유지하면서 사용하는 feature map을 하나씩 줄였는데요, 항상 일정한 개수를 유지할 수 없었는지 Bounding box의 개수가 조금씩 다르다는 걸 확인하실 수 있습니다.
여기서 boundary box는 이미지 경계를 둘러싼 box를 말하며 경계선을 포함한 box는 예측에 사용하지 않을 때 성능이 더 늘어났다는 것도 확인하실 수 있습니다.
저자는 이 결과표를 보여주며 SSD가 선택한 객체 예측 방식 덕분에 "다양한 해상도에서 객체를 예측했기에 낮은 해상도의 입력 이미지를 가지고도 Faster R-CNN만큼 성능이 좋다"고 말했습니다.
PASCAL VOC 2012
이제 Pascel VOC 2012로 학습하고 테스트한 결과를 설명해 드리도록 하겠습니다. 총 21503의 이미지로 이루어져있고 이 중 테스트용 이미지가 10991장입니다. 늘어난 데이터셋의 크기에 맞춰 훈련 횟수도 늘렸고 훈련을 마친 SSD300, SSD512의 결과는 다음과 같습니다.

PASCAL VOC 2007로 학습했을 때와 큰차이는 볼 수 없습니다. 역시나 "SSD512가 제일 성능이 좋았다!" 로 마무리됩니다.
COCO
COCO 데이터셋을 이용해 SSD300, SSD512를 학습시킨 결과는 어떨까요?
이번에는 조금 조정한 부분이 있습니다. SSD300의 경우 scale의 최소값인 s_min을 0.2에서 0.15로 낮추고 conv4_3에 있는 각 영역의 scale을 0.07로 조정했습니다. 그리고 SSD512는 객체 예측용으로 conv12_2를 추가했고 s_min을 0.1로, conv4_3의 scale을 0.04로 조정했습니다.
학습 후 측정한 성능은 다음과 같습니다.
이번에도 역시 SSD512가 제일 성능이 좋습니다.
Preliminary ILSVRC results
저자는 COCO에서 조금 수정한 SSD300를 ImageNet 데이터셋으로도 학습시켰습니다. Girshick, R., Donahue, J., Darrell, T., Malik, J.가 저술한 "Rich feature hierarchies for accurate object detection and semantic segmentation"에 있는 val2 set에서 성능을 평가해보니 43.4mAP가 나왔으며 저자는 이 결과를 통해 SSD가 학습시킬 데이터셋에 관계없이 항상 좋은 성능을 내는 모델이라는 걸 검증했다고 말했습니다.
Data Augmentation for Small Object Accuracy
보통 데이터 증강을 하면 이미지의 외곽을 잘라 객체의 크기를 늘리는 "zoom in" 작업을 수행합니다. 저자는 zoom in뿐만 아니라 이미지의 16배에 해당하는 빈 이미지를 이미지 데이터의 평균값으로 채워넣은 뒤 여기에 원래 이미지를 넣었습니다.
입력 이미지의 사이즈는 일정하기 때문에 이를 위해 전체 이미지 사이즈를 줄이기 때문에 결과적으로 객체의 크기가 16배나 줄어든게 된 것이죠. 저자는 이를 "zoom out"이라고 말했습니다. "zoom out"으로도 데이터 증강을 했으니 전체적인 데이터셋의 사이즈가 늘어났겠죠? 그래서 훈련 횟수를 2배 늘렸습니다.
zoom out의 효과는 확실했습니다. 성능 평가를 위해 사용한 모든 데이터셋에 zoom out을 구현 후 학습하고 측정해본 결과, zoom out을 하지 않았을 때보다 mAP가 2~3% 증가했습니다. small object에 대한 검출 능력이 증가했기 때문에 일어난 성능 향상인 것입니다. 이 결과를 통해 데이터 증강의 중요성을 알 수 있습니다.
데이터 증강 외에도 feature map을 가지고 Bounding box를 예측할 더 좋은 방법을 찾으면 SSD의 성능을 늘릴 수 있겠다고 말했으나 그건 이 논문에서 시도하지 않고 나중에 하기로 했다고 말했습니다.
Inference time
마지막으로 모델의 속도를 측정해봅시다. 객체 종류당 jaccard overlap을 0.45로 설정하고 SSD에 nms까지 적용해 이미지당 200개의 Bounding box를 예측하게 만든 뒤 PASCAL VOC 2007 데이터셋으로 SSD300으로 학습 시키고 속도를 측정해봤는데요, 측정 결과 이미지당 1.7msec이 걸렸습니다.
측정 기기의 성능은 Titan X and cuDNN v4 with Intel Xeon E5-2667v3@3.20GHz라고 하는데요, 와씨...부럽습니다.
저자는 SSD 외에도 여러가지 모델의 속도도 측정해봤고 결과를 다음과 같이 표로 정리했습니다.
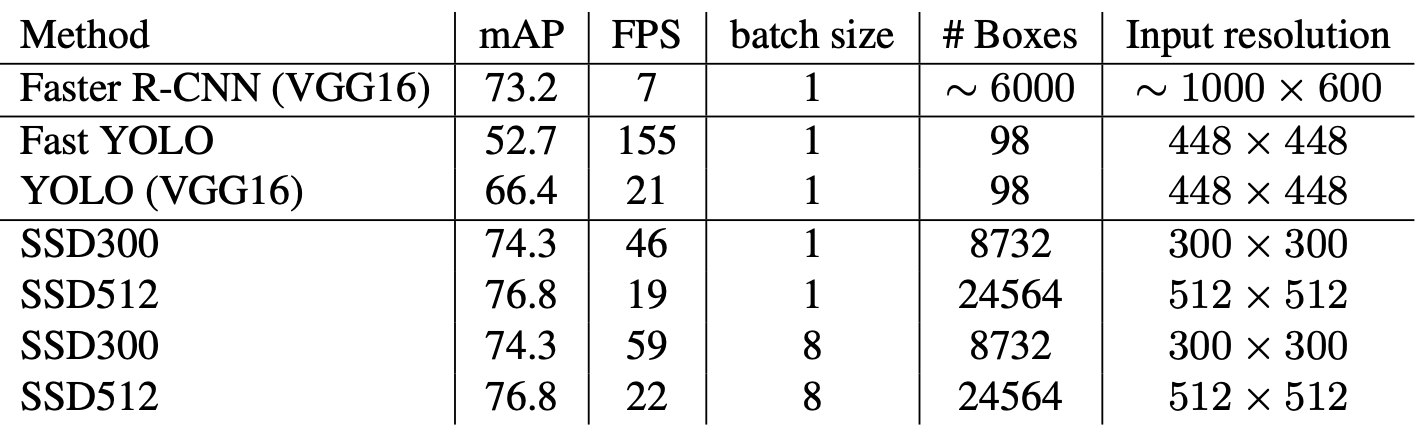
지금까지 빠르고 성능좋은 1-Stage Detector, SSD였습니다.
Conclusions
하고싶은 말이 많았나봅니다. Conclusion이 아주 깁니다. 대부분 앞에 말했던 내용을 정리해서 말한거긴 합니다.
저자는 SSD가 거대한 시스템에서 사용될 수 있을거라 믿고 있으며 RNN(Recurrent Neural Network)도 사용해 비디오 속 객체 탐지에서도 사용할 수 있을거라 말하며 논문이 끝납니다.
후기
하루만에 리뷰하는걸 목표로 하고 글을 썼는데 사흘이나 걸렸습니다. 해야할 일들을 자꾸 생기더군요😭
YOLO를 구현하고 얼마 안되어 읽은 논문이라 그런가 모든 부분을 YOLO와 비교하며 읽었습니다. SSD는 YOLO의 존재를 의식하고 만들어서 그런가 YOLO가 가진 단점을 대부분 개선하면서 장점까지 강화시킨 모델이라는 생각이 들었습니다.
신기한 점은 어떻게 특성 추출을 위한 컨볼루션 연산에 객체 예측을 위한 컨볼루션 연산까지 수행해 레이어의 개수가 YOLO보다 훨씬 많은데도 YOLO보다 더 빠르다는 점입니다. 그만큼 FCN이 느리다는 걸 다시 한 번 깨달았습니다.
다음 논문은 Object Detection말고 다른 task를 수행하는 모델을 리뷰할 계획입니다. 다음 논문에서 뵙겠습니다.
