안녕하세요. 밍기뉴와제제입니다.
2023년 첫 논문리뷰입니다. 월간 리뷰는 계속됩니다. 계속해서 월간 리뷰를 할 수 있기를 기원해봅니다.
이번에 리뷰할 논문은 EfficientFormer: Vision Transformers at MobileNet Speed입니다. Transformer가 유명세를 떨치며 다양한 분야에서 Transformer를 이용한 방식들이 제안되었는데요, 그 중 image classification 분야에서 Transformer를 기반으로 제작된 Vision Transformer, 줄여서 ViT라는 모델이 제안되었는데 성능이 좋아 꽤나 화제가 되었습니다.
그러나 이러한 ViT는 너무 많은 계산량과 메모리 등을 요구하기 때문에 모바일 기기같은 곳에서 돌리기가 힘들어 실사용 면에서 아쉬운 면이 있었는데요, 이러한 점을 이번에 리뷰할 EfficientFormer가 어느정도 해결합니다.
그럼 지금부터 논문 리뷰를 시작해보겠습니다.
1. Introduction
Transformer는 원래 자연어 처리를 위해 제안된 모델이었습니다. 그런데 누군가 Transformer로 이미지를 처리하는 방법을 생각했고 그 결과, ViT가 생겨났죠.
ViT는 CNN(Convolutional Neural Networks)과 비교했을 때 우수한 성능을 보여줬습니다. 그러나 CNN보다 속도가 느렸습니다. 그 이유를 간단히 정리하면
- Parameter가 많다.
- 입력으로 받는 Token의 길이에 제곱하는 시간 복잡도를 가지고 있다.(=O(n^2)다.)
가 되겠습니다. 이러한 요소들은 ViT를 연산 속도, 저장공간이 제한적인 모바일 혹은 웨어러블 기기에서 돌리는데 큰 제약을 주었습니다. 즉, ViT가 실생활에서 impractical한 것이죠.
그래서 이런 문제를 해결하기 위해 다양한 방식들이 제안되었습니다. Transforemr의 연산을 수행하는 새로운 구조를 제안하여 연산 복잡도를 줄이거나 pruning 등의 방식을 써 efficiency를 높이는 등의 방식들이 제안되었죠. 그 결과, computation-performance의 trade-off는 어느정도 해결할 수 있었습니다.
본질적 질문
앞서 말씀드렸듯 ViT의 연산 속도와 메모리 사용량을 줄이는 방식들이 제안되었습니다. 그러나,
'Can powerful vision transformers run at MobileNet speed and become a default option for edge applications?'
위 질문에 대한 답은 여전히 내놓지 못했다고 합니다. 위 질문은 'Transformer 기반 모델들의 applicability과 연관된 질문'이라고 저자가 말하였습니다.
기존 연구와 달리, 저자는 위 질문의 답변으로 다가갈 수 있는 연구를 수행하였습니다. 저자는 자신들의 연구가 다음의 contribution을 가지고 있다고 주장하였습니다.
-
첫 번째, latency analysis을 통해 ViT과 이를 기반으로 하는 모델들의 디자인 원칙(design principles)을 다시 살펴보았고 CoreML을 이용해 해당 모델들을 컴파일 후 아이폰12에서 돌려봄.
-
두 번째, 모델들의 분석 결과를 기반으로 비효율적인 디자인 요소와 비효율적인 연산이 있는 부분들을 파악 후 ViT를 위한 dimension-consistent design paradigm을 제안함.
-
세 번째, dimension-consistent design paradigm을 이용해 단순하지만 효율적인 latency-driven slimming 방식을 만들었고 이를 기반으로 EfficientFormer'들'을 제작함. EfficientFormer들은 실행 속도(inference speed)를 줄이는 것을 목표로 하는 모델임.
정리하자면, 저자는 ViT 등 Vision 분야에서 기존에 제안된 트랜스포머 모델들을 분석 후 작은 기기에서 빠른 속도로 돌릴 수 있는 EfficientFormer를 만들었습니다.
실험 결과, EfficientFormer는 기존에 제작된 모델들과 비교했을 때 Image Classification에서 빠른 속도와 높은 성능을 보여줬습니다. 그리고 EfficientFormer를 Backbone으로 하여 Image Detection, Segmentation를 할 때도 좋은 성능이 나왔다고 하네요.
답변
저자는 빠른 연산 속도와 높은 성능을 동시에 잡은 EfficientFormer를 만드는데 성공했습니다. 그렇기에 앞서 던진 질문에 다음과 같은 preliminary answer를 내놓을 수 있었습니다.
'ViTs can achieve ultra fast inference speed and wield powerful performance at the same time'
아직 실생활에 완벽히 돌릴 정도는 아니라 생각한거 같습니다. 그러나 이번 EfficientFormer를 기반으로 발전시키다보면 Transformer 기반의 모델을 휴대폰으로 돌려 유용하게 사용할 날이 오지 않을까요?
그러면 인터넷과 거대한 GPU서버가 없는 환경(오지, 가난한 지역 등)에서도 인공지능의 수혜를 받을 수 있지 않을까 생각됩니다.
많은 사람들이 기술적 혜택을 누릴 수 있는 연구, 제가 선호하는 연구입니다.
아무튼, 이렇게 Introduction이 끝났습니다. 다음 장을 이어서 해보겠습니다.
2.On-Device Latency Analysis of Vision Transformers
기존에 제안된 방식들은 서버 GPU에서 측정하는 처리량(1초에 이미지를 얼마나 처리하느냐?)과 연산 복잡도(MACs)를 줄이는 방향으로 접근을 하였습니다. 그러나 이는 실제 작동시키는 기기의 성능을 고려하지 않습니다.
즉, 저자의 목표인 '제한된 성능의 기기에서 ViT를 빨리 돌려보기'의 방향과 맞지 않는 것이죠.
그래서 저자는 아이폰12에서 다양한 모델들을 돌려보며 '어떤 요소가 속도 저하를 일으키는지' 확인하는 시간을 가졌고 결과는 다음과 같았습니다.
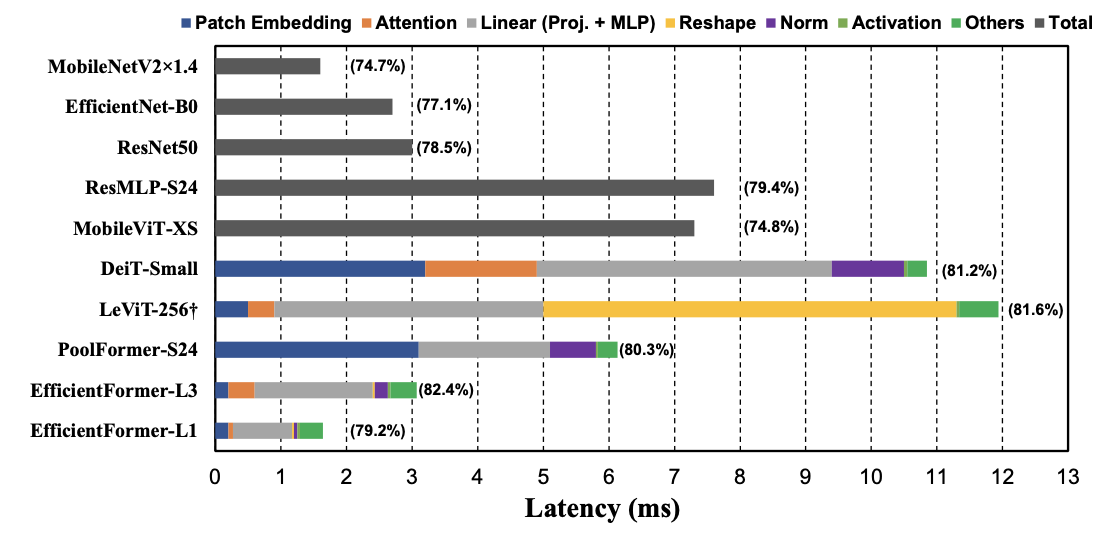
저기서 LeViT-256은 HardSwish를 사용하는데 이게 CoreML에서 잘 지원하지 않았다고 합니다. 그래서 HardSwish를 GeLU로 교체한 뒤 비교했다고 하네요.
그래프를 자세히 보시면 EfficientFormer가 밑에 있는걸 확인하실 수 있습니다. 짧은 연산속도를 보여주고 있죠.
분명 저자는 'To have a clear understanding of which operations and design choices slow down the inference of ViTs on edge devices'가 목표라고 했는데...분석 결과 보여주는 김에 '우리꺼 성능 좋지?'를 어필하려고 한건가 싶습니다.
아무튼, 분석 결과는 다음과 같았습니다. 이에 더해 저자는 해당 결과를 보며 3가지 깨우침?을 얻었습니다. 그 내용을 정리하면...
-
'Patch Embedding with large kernel and stride'는 모바일 기기에서 성능 저하의 원인이 된다 : 사람들은 'Patch Embedding에 필요한 연산량이 적다'는 믿음을 가지고 있었습니다. 그런데 저자들은 Patch Embedding, 정확히는 Patch Embedding을 위한 non-overlapping CNN이 가지는 거대한 kernel, stride로 인해 모바일 기기에서 실행 속도를 늦추는데 영향을 준다는 사실을 알아냈습니다. 저자는 거대한 kernel, stride 대신 [3x3사이즈의 kernel을 가지는 CNN + fast downsampling] 조합으로 Patch Embedding을 구현할 수 있다고 말했습니다.
-
Consistent feature dimension은 token mixer에 중요하며 MHSA(Multi head Self-Attention)은 속도 저하의 원인이 아니다. : 최근 연구들에서 ViT를 MLP 블록과 token mixer가 들어있는 Metaformer 구조로 확장하는 것을 제안하고 있습니다. 이 때 token mixer로 어떤 구조를 사용할지는 구체적으로 정해지지 않았는데요, 저자는 token mixer를 선택하는 것 ViT-based model을 설계할 때 필수라고 말했습니다. 저자는 token mixer로 pooling과 MHSA를 후보로 선정했으며 'pooling은 단순하며 효율적', 'MHSA는 성능이 더 좋음'이라는 결론을 얻을 수 있었다고 말했습니다. 이에 대한 더 자세한 비교 내용이 있긴 하나 논문을 직접 읽고 이해하시는게 더 좋을 것 같습니다.
그리고, 저자는 위의 비교 결과를 바탕으로 4차원 feature implementation과 3차원 MHSA가 들어있는 dimension-consistent network를 제안하였습니다. 설계하는 과정에서 reshape 연산은 제외했는데요, 이는 계산의 연산효율성이 낮아서 그런 것으로 알고 있습니다.
-
CONV-BN은 LN(GN)-Linear 구조보다 빠른 처리속도를 가지고 있으며 CONV-BN을 선택함으로써 오는 성능 하락은 감수할 수 있다. : 앞서 최근 연구들은 token merging과 MLP블록이 포함된 구조로 ViT-base model을 만든다고 말씀드렸고 그 중 token merging에 관해 잠시 얘기하였습니다. 이번에는 MLP블록에 관한 얘기가 나옵니다. MLP 블록은 보통 [LN(Layer Norm.) + 3D linear projection]과 [CONV 1x1 + BN(Batch Norm.)] 중 하나가 선택된다고 합니다. 이 중 후자의 구조가 속도면에서 더 좋은데요, 이유를 간단히 말하면 'BN은 속도 증가에 영향을 주고 LN(GN)은 속도 하락에 영향을 준다'가 될 수 있겠습니다. 그런데 CONV-BN 구조를 사용할 경우 성능이 상대적으로 안좋다고 합니다. 그래도 그 성능이 부족한 정도가 그렇게 심하지 않다고 하네요. 저자는 CONV-BN 구조를 EfficientFormer 구조에 사용할 수 있는 최대한으로 넣었다고 말하기도 했습니다.
-
nonlinearity 연산에 필요한 시간은 hardware와 compiler에 따라 다르다 : 여기서 nonlinearity 연산은 ReLU, GeLU 등 활성화 함수로 쓰는 애들을 말합니다. 얘들을 처리하는데 필요한 시간이 기기(hardware)와 기기에 인공지능 모델을 돌릴 수 있게 해주는 컴파일러에 따라 다르다는 것을 저자들은 알아냈습니다. 신기하네요. 허나 이말은 즉, 어떤 활성화 함수가 기기, 컴파일러에 잘 호환되는지 직접 돌려보며 알아내야 한다는 뜻이기도 합니다. 저자는 실험 결과 GeLU가 아이폰12와 잘 호환된다는 것을 알아내 EfficientFormer에 사용할 활성화 함수로 GeLU를 선택했다고 말했습니다.
3.Design of EfficientFormer
다음으로 저자가 제안한 EfficientFormer의 구조를 설명해드리도록 하겠습니다. 우선 모델의 구조를 그림으로 나타내면 다음과 같습니다.
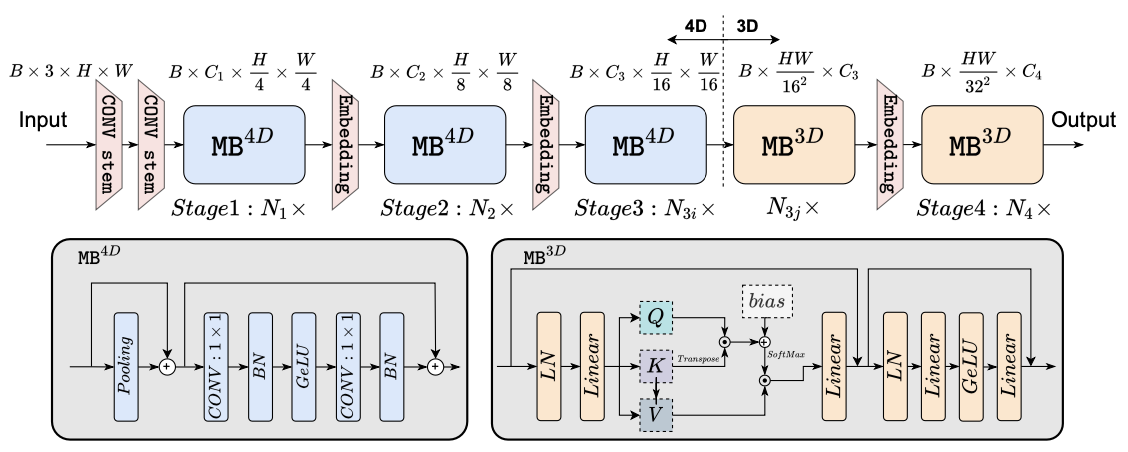
EfficientFormer는 위 그림과 같이 Patch Embedding(Embedding)과 meta trasnformer 블럭(MB)들로 구성되어 있습니다. 그러니 입력 이미지 X_0을 넣어서 출력값 y를 얻는 식은
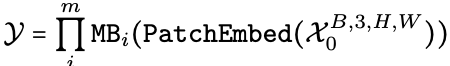
이렇게 나타낼 수 있겠습니다. 여기서 [H, W]는 이미지의 사이즈고 m은 EfficientFormer가 가지고 있는 MB의 개수입니다.
MB를 좀 더 자세히 살펴봅시다. MB는 처리하는 데이터의 차원에 따라 MB 3D, MB 4D로 나뉩니다. 3D 데이터를 처리하는 MB는 Transformer를 기반으로 만들어졌고 4D 데이터를 처리하는 MB는 CNN을 기반으로 만들어졌습니다.
앞서 저자는 'CONV-BN 구조를 EfficientFormer 구조에 사용할 수 있는 최대한으로 넣었다'고 말한 것을 기억하실겁니다. CNN기반으로 만든 블럭은 속도가 빠르나 성능이 낮으며 Transformer를 기반으로 만든 블럭은 속도가 느리자 성능이 높습니다.
그러니 이 둘의 비율을 어떻게 하느냐에 따라 성능과 속도가 달라질 것입니다. 실제로 저자는 두 MB블럭의 개수에 따라 다른 버전의 EfficientFormer를 제작했다고 말하고 있습니다.
마지막으로, MB에서 처리된 데이터는 Embedding과정을 거치며, 그 과정에서 token들이 특정 차원으로 embedding된 후 특정 길이로 downsampling됩니다.
3.1 Dimension-Consistent Design
조금 더 자세히 살펴봅시다. EfficientFormer는 dimension consistent design을 했다고 합니다. 이게 뭔가 싶어 봤더니 '4d featrue를 쭉 처리하다가 3d feature로 변환 후 쭉 처리하는 구조'를 dimension consistent design이라고 하네요.
저자는 3d feature로 데이터를 처리할 경우 효율성 부분에서 희생하지 않고 Multihead self-attention의 global modeling power를 사용할 수 있다고 말하기도 했습니다.
그러면 지금부터 EfficientFormer의 처리 과정을 좀 더 자세히 살펴보도록 하겠습니다.
먼저 입력된 데이터, 다시 말해 이미지는 두 개의 CONV Stem을 거칩니다. 저자는 두 개의 연속된 CONV Stem을 PatchEmed로 정의하였구요, 식은 다음과 같습니다.

(여기서 C_j는 j번 째 stage에서 feature가 가지는 channel의 개수를 말합니다.)
두 개의 CONV Stem을 거친 데이터는 앞서 말씀드린 (MB -> embedding)의 과정을 연속적으로 거칩니다. 그 중 먼저 거치는 MB 4D에서 진행되는 연산을 먼저 살펴봅시다. i번 째 feature를 i번 째 MB 4D에 넣어서 i + 1번 째 feature를 얻는 과정입니다.

(Conv_B,G는 Conv2d -> Batch norm. -> GeLU 순으로 연산이 진행된다는 뜻이구요, Conv_B는 Conv2d -> Batch norm. 순으로 연산이 진행된다는 뜻입니다.)
여기서 첫 번째 식은
이걸 말하구요, 두 번째 식은
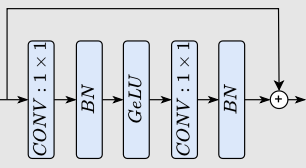
이걸 말합니다. 저자는 Conv2d 이후 Batch Norm.을 수행하기 때문에 pooling을 하기 전에 Batch norm. 등의 연산을 하지 않았다고 말했습니다.
이렇게 4차원 feature를 CNN기반 MB블럭으로 연산하다가 특정 시점에 3d feature로 변환 후 MB 3D에서 연산을 진행합니다. 다음 식은 3차원으로 변환된 feature를 처리하는 과정을 나타냅니다.
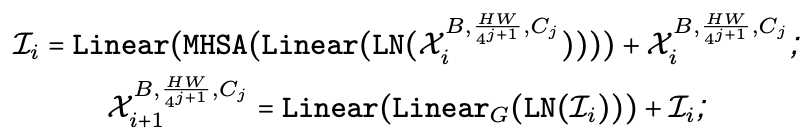
(Linear_G는 Linear->GeLU 순으로 연산이 진행된다는 뜻입니다.)
여기서 첫 번째 식은

이걸 나타내구요, 두 번째 식은
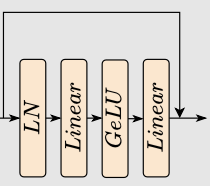
이걸 말합니다.
3.2 Latency Driven Slimming
지금까지 MB 3D, MB 4D 등 EfficientFormer를 구성하는 것들이 연산이 진행되는 과정을 알아봤습니다. 이번에는 그런 애들을 어떻게 조합해서 쓸 것인가를 설명하고자 합니다.
저자는 위의 EfficientFormer 구조와 같은 모델을 설계하기 위해 MB와 identity path로 구성된 MetaPatch(MP)를 정의했습니다. 다음과 같습니다.

여기서 I는 identity path, j는 j번 째 stage, i는 i번 째 블럭을 나타냅니다.
앞서 보여드린 모델의 전체적인 구조를 보면 아시겠지만
저자는 Stage 3, 4에만 MB 3D가 있는 이유로 두 가지를 말했습니다.
- Multihead self-attention은 token의 길이에 연산량이 제곱으로 비례하는데 초기 단계(Stage 1, 2)의 경우 feature의 크기가 크기 때문에 많은 연산량이 필요하다.
- 초기 단계에서는 Conv로 low-level feature를 처리하고 마지막 단계에서 Multihead self-attention이 long-term dependencies를 처리한다는 통찰이 존재한다.
Searching Space
Searching Space이 뭔가 잠시 생각해봤는데, 모델을 설계할 때 사용하는 hyperparameter였습니다. Searching Space는 C_j(j번 째 stage의 width), N_j(j번 째 stage에 있는 MB의 개수), N(마지막 Stage에 있는 MB 3D의 개수)이 있다고 합니다.
Searching Algorithm
그러면 모델을 설계할 때 사용되는 C, N_j, N의 최적값을 어떻게 찾을까요? 저자는 한 번의 학습만 필요한 모델을 얻을 수 있는 a simple, fast yet effective gradient-based search algorithm을 제안했습니다. 해당 알고리즘은 다음의 3단계를 수행해야 합니다.
1단계 : supernet을 Gumbel Softmax sampling을 이용해 학습시킨다. 그러면 각 MP에 있는 MB의 importance score를 얻을 수 있습니다.
2단계 : 모델에 있는 MB 3D, MB 4D의 on-device latency를 수집 후 이들을 가지고 latency lookup table을 생성합니다.
3단계 : 2단계에서 얻은 table을 참고해 1단계에서 얻은 supernet에다 netwrok slimming을 적용합니다. 저자는 single-width supernet에다 gradual slimming을 수행해 메모리 사용 등을 피했다고 말합니다.
이 때, 각 stage의 importance score는 각 stage에 있는 MP의 importance score를 합친 값입니다. 그리고 저자는 다음 3가지 옵션을 가지는 action space도 정의했습니다.
- 가장 중요도가 낮은 MP가 가지는 I(identity path)를 선택
- 맨 처음 MB 3D를 제거
- 가장 중요도가 낮은 stage의 width를 1/16으로 줄임
위 3가지 action을 하나씩 수행 후 앞서 말씀드린 lookup table를 통해 latency를 계산합니다. 그리고 각 action별로 정확도가 떨어지는 정도를 계산한다고 합니다.
그러면 우리는 각 action 별로 per-latency accuracy drop(-%/ms)를 계산할 수 있을 것이며 이를 기반으로 실제로 수행할 action을 선택할 수 있을 것입니다.
이 과정은 목표하는 latency를 달성할 때까지 반복 수행합니다. 그러니까 정리하자면
[학습 -> 중요도 계산 -> (-%/ms)기반으로 action을 하나 선택하여 slimming 수행]을 원하는 속도가 나올 때까지 반복한다
고 볼 수 있겠습니다. 개인적으로 해당 부분을 제대로 이해하기가 어렵습니다.
그래서! 저자는 이를 설명하는 pseudo code를 다음과 같이 작성하였습니다.

음, 여전히 어렵긴 하지만 그래도 간결하게 설명되어 있습니다. 저렇게 for문을 연달아 쓴 pseudo code는 처음 보네요.
4 Experiments and Discussion
다음으로 실험과 EfficientFormer에 관한 Discussion을 설명드리고자 합니다. 저자는 Image Classification, Object Detection, Semantic Segmentation에서 EfficientFormer를 사용하였으며 이들을 통해 EfficientFormer가 낮은 연산량을 요구하는 것에 반해 높은 성능을 가졌음을 보여줬습니다. 하나씩 살펴보겠습니다.
저자는 A100에서 모델을 학습시켰습니다.
4.1 Image Classification
먼저 Image Classification입니다. 결과표는 다음과 같습니다.
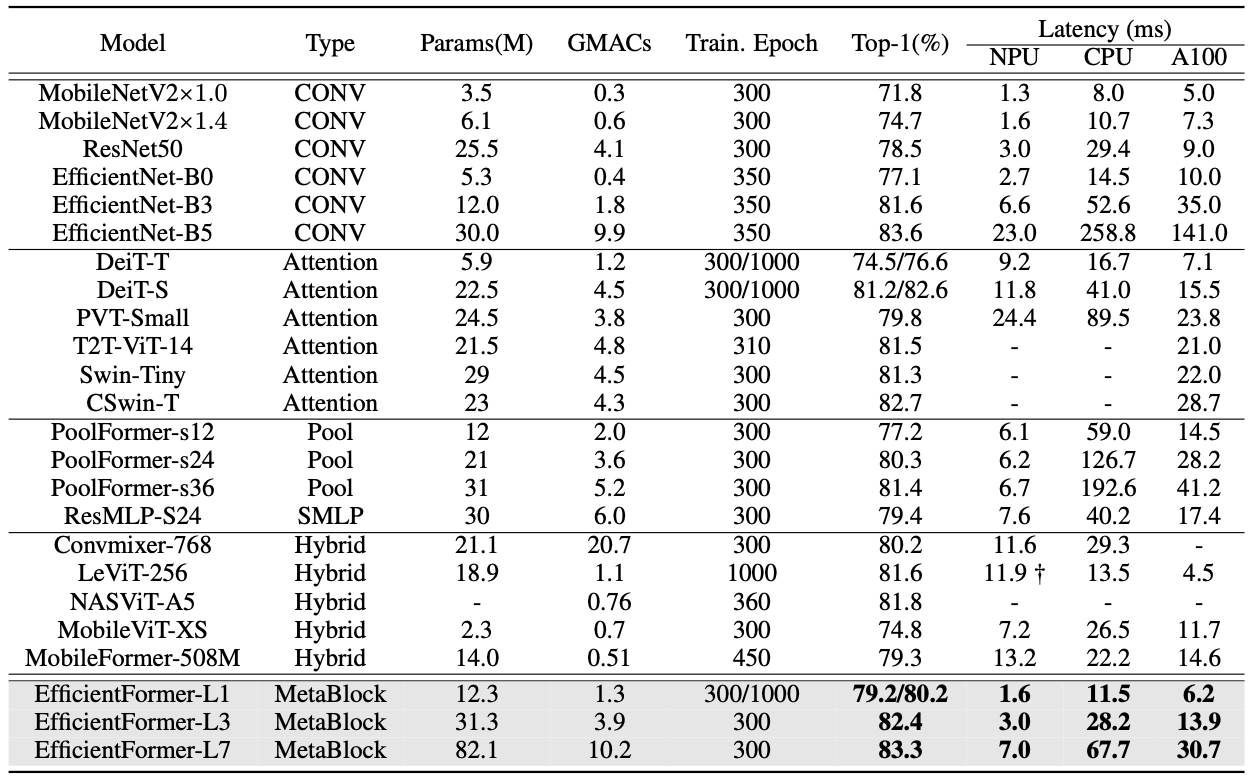
자신들의 모델이 Efficient함을 보여주기 위해 모델의 parameter, train epoch, latency 등의 항목이 표에 들어있는 것을 확인할 수 있습니다.
저자는 아이폰12(CPU, NPU)뿐만 아니라 GPU를 이용해서도 성능을 측정했습니다. CPU, NPU는 프레임 별 latency를 측정하고 GPU는 batch size(64)별 latency를 측정했다고 하네요.
표를 보시면 확인하실 수 있겠지만, EfficientFormer가 기존 방식들과 비교했을 때 [높은 정확도 + 낮은 latency]를 더 만족함을 알 수 있습니다.
한가지 아쉬운 점은 parameter 개수가 그만큼 많은 점이 있겠습니다. 그런데 이건 저장공간을 줄이는게 목표가 아니었기 때문에 오히려 '우리는 속도도 높이고 저장공간도 나름 사수했다'는 점으로 보여질 수 있겠네요.
그리고 또 아쉬운 점을 꼽자면 EfficientFormer가 L1, L3, L7 순으로 parameter 개수는 점점 많아지고 그만큼 latency도 늘어나는데 반해 성능 향상은 미미하다는 것입니다. cost를 추가로 들인만큼의 성과가 안나왔다고 볼 수 있을까요? 성능 향상이 좀만 더 많이 이뤄졌다면 더 좋았을 것 같습니다.
4.2 EfficientFormer as Backbone
다음으로 Object Detection과 Semantic Segmentation입니다. 저자는 Object Detection의 대표적인 방식 중 하나이자 Semantic Segmentation을 task로 하는 Mask R-CNN의 Backbone을 바꿔가며 성능을 측정하였습니다. 해당 실험에서는 성능만 측정하고 속도는 측정하지 않았습니다. 결과표는 다음과 같습니다.

EfficientFormer를 backbone으로 했을 때 제일 성능이 좋다는 것을 알 수 있습니다. 그런데 성능만 확인하고 비교에 쓰인 기존 방식도 개수를 적게한 것을 보아 '이렇게도 쓰일 수 있더라'라고 어필하고자 해당 실험을 수행한게 아닌가 조심스래 예측해봅니다.
4.3 Discussion
EfficientFormer에 관한 Discussion을 하는 부분입니다. 저자는 기존에 최적화를 목표로 제안된 ViT-base model들이 실제로 연산량이 제한된 기기에서 돌릴 때 속도가 낮다는 점을 꼽으며 본인들의 방식을 제안하였습니다. 그렇게 제안된 EfficientFormer는 Image Classification에서 속도, 성능 두가지 토끼를 모두 잡았고 그 외의 task에서도 성능이 훌륭함을 증명하였죠.
Limitations
저자는 자신들이 제안한 EfficientFormer의 한계점으로 2가지를 꼽았습니다.
- EfficientFormer는 general-purposed를 목적으로 설계되었으나 모델을 돌리는 기기에 따라 실제 실행 속도가 다릅니다. 예를 들면, GeLU는 아이폰12에서 잘 돌아가지만 다른 기기에서는 잘 돌아가지 않을 수 있어 속도 저하가 일어날 수 있습니다.
- 저자가 제안한 slimming method는 단순하고 빠르지만 이를 이용해 최적의 모델을 얻으려면 [학습 -> 중요도 계산 -> (-%/ms)기반으로 action을 하나 선택하여 slimming 수행]을 수행하는데 필요한 cost를 고려하지 않고 계속해서 수행해야 합니다. searching에 필요한 cost의 상한선이 없는 것이죠.
5.Conclusion
마지막 결론 부분입니다. 저자가 EfficientFormer에 관해 간략한 정리를 하였고 향후 어떤 연구를 수행할지 소개하고 있습니다. EfficientFormer를 보다 연산량이 제한된 기기에서 빠르게 돌리는 방법을 연구할 것이라고 하네요.
여기까지 EfficientFormer였습니다. 어우...깁니다. 막판에 집중력이 급 떨어져서 호로록 마무리 지었는데 퀄리티 차이가 많이 나지 않을까 우려됩니다. 죄송합니다 ㅜㅜ
이번 달 리뷰를 하며 "대학원에 들어간 뒤로는 이런식으로 블로그에 포스팅은 못하겠구나" 싶은 생각이 들었습니다. 왜냐하면 이렇게 논문을 자세히 뜯어보는 작업을 논문 세미나에서 할 것이기 때문이죠.
그리고 너무 자세히 뜯어서 그런가 매번 글을 올릴 때마다 정신적 피로가 상당히 많습니다.
그래서! 다음 달 리뷰부터는 지금까지 읽었던 여러 논문들을 간단히 소개하는 방식으로 해볼까 합니다. 자세한 구상은 다음 달 리뷰에서 확인하실 수 있을 것입니다.
그러면 다음 달 리뷰글에서 뵙겠습니다.
