안녕하세요. 밍기뉴와제제입니다. 이번에는 YOLOv2, YOLOv3를 간단히 리뷰해보도록 하겠습니다. YOLOv3는 YOLOv2를 개선시킨 버전이기 때문에 같이 리뷰해도 되겠다 싶어 같이 리뷰하기로 했습니다.
YOLO는 객체탐지를 위한 딥러닝 모델로 유명한 네트워크입니다. 네트워크 구조가 간단하고 속도가 빠르지만 정확도도 어느정도 보장해주기 때문이죠. 저도 최근 수행한 공탐지 프로그램을 만들 때 YOLOv3을 사용했는데 아주 만족스러운 성능을 보여줬습니다.
그러면 지금부터 논문 리뷰를 시작해보겠습니다.
YOLO?
YOLO는 'You Only Look Once'의 줄임말입니다. 말 그대로 '한 번만 봐도 뭐가 어딨는지 알 수 있는' 네트워크를 말하는 것이죠.
이름에 걸맞게 구조도 꽤나 단순합니다. YOLO의 맨처음 버전인 YOLOv1이 나올 때만 해도
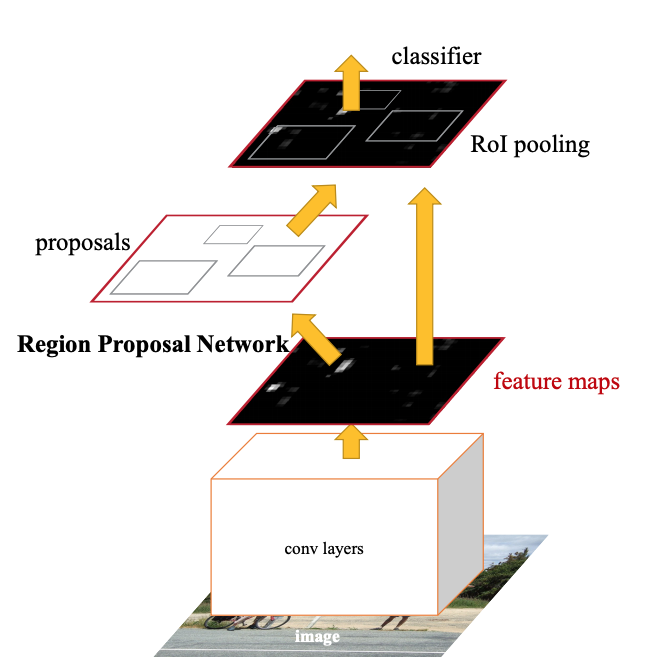
이렇게 두개의 네트워크를 가지고 객체탐지를 하는 2-stage detector가 성능과 속도면에서 가장 유용한 방식이었으나
YOLO는 기존에 있던 VGG16과 같이 하나의 네트워크에 이미지를 넣으면 바로 객체의 종류와 위치정보를 알 수 있는 1-stage detector 방식을 선택했습니다. 기존에도 이러한 방식이 있었으나 YOLOv1는 당시 성능이 가장 좋았던 Faster R-CNN보다 성능이 약간 부족하지만 실행속도가 무려 45FPS나 되어 준수한 성능으로도 실시간 객체탐지를 할 수 있다는 가능성을 보여줬습니다. 파격적인 네트워크였죠.
허나 YOLOv1은 전체 이미지를 7 x 7 = 49개의 구역으로 나눠 각 구역에서 한개의 객체만 탐지할 수 있다는 단점을 가지고 있었습니다. 즉, 한 구역에 두개의 객체가 있으면 하나만 탐지할 수 있다는 뜻이죠. 개선이 필요했습니다.
그래서 저자는 YOLO를 개선하기 위해 개선된 네트워크를 두 번 공개했으며 YOLO를 개선한 네트워크기 때문에 그 이름을 'YOLOv2', 'YOLOv3'으로 정했습니다.
YOLO v2
YOLOv1이 나오고 일년 뒤에 공개된 네트워크입니다. YOLOv2는 YOLOv1보다 parameter의 숫자가 많아졌습니다.
그리고 가장 큰 차이점이 뭐냐면 Fully Connected Layer 대신 anchor box를 사용한다는 것입니다. Faster R-CNN과 같은 방식을 사용하는 것이죠. YOLOv1은 '객체의 정확한 위치'를 예측해야 했는데 anchor box를 사용하면 '각 anchor box와 객체와의 차이값'을 예측하면 되기 때문에 네트워크가 해결해야될 문제의 난이도가 낮아집니다. 그러니 성능이 더 올라가겠죠. 이렇게 anchor box를 기준으로 위치를 구하기 때문에 탐지할 수 있는 객체의 개수도 YOLOv1에서 탐지할 수 있던 최대 개수인 49개보다 훨씬 많이 탐지할 수 있습니다. 논문에 의하면 YOLOv2는 1000개 이상의 객체를 탐지할 수 있다고 합니다.
그리고 입력받는 이미지의 해상도를 416 x 416으로 변경했습니다. 416 x 416을 입력 이미지로 받으면 제일 마지막에 추출되는 특성맵의 크기가 13 x 13이 되는데 이렇게 되면 정중앙에도 anchor box가 생겨 중심부의 객체도 잘 예측할 수 있습니다.
위치 예측 방식
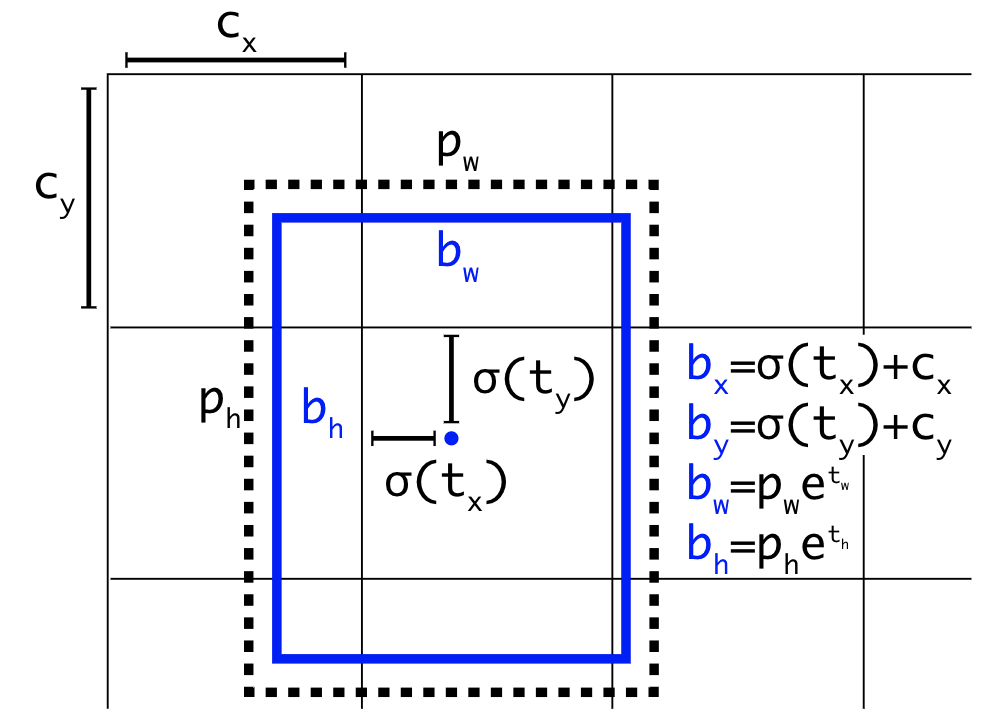
YOLOv2는 앞서 말씀드렸듯 anchor box를 이용해 객체 탐지를 수행한다고 말씀드렸습니다. YOLOv2는 YOLOv1의 '전 구역을 일정 크기의 구간(cell)로 나눈다'는 방식을 이용해 cell을 anchor box로 사용했습니다. 그림으로 나타내면 다음과 같습니다.

여기서 YOLOv2는 b_x, b_y, b_w, b_h를 예측합니다. anchor box와 실체 객체가 가지는 bbox와의 차이(offset)에 해당하는 값들이죠. 여기서 b는 'bounding box'의 약자입니다.
그리고 YOLOv2는 anchor box로 cell을 사용한다고 말씀드렸는데요, 식에 있는 (c_x, c_y)가 cell의 크기를 나타냅니다.
이러한 방식을 사용하며 얻는 이득은 앞서 말한 scale에서 오는 이점만 있는게 아닙니다. YOLOv1이 하나의 특성맵에서 객체탐지를 수행하기 때문에 탐지하는 객체의 크기에 제한이 있었는데 YOLOv2는 2개의 특성맵에서 객체탐지를 수행해 이를 해결했습니다. 26 x 26크기의 특성맵과 13 x 13크기의 특성맵에서 객체탐지를 수행하여 YOLOv1에서는 못찾던 작은 크기의 객체도 YOLOv2의 26 x 26 특성맵에서 찾을 수 있게 되었습니다. 2개의 scale을 가지는 특성맵을 사용하여 YOLOv1의 단점을 보충한 것이죠.
즉, CNN에서 특성 추출 작업을 수행하다가 [26 x 26], [13 x 13] 크기의 특성맵이 나오면 여기서 얻은 값을 그대로 객체탐지에 사용한다는 뜻입니다.
객체의 종류(Class)를 예측하는 방식은 YOLOv1이 사용하는 방식과 같습니다. YOLOv2는 bbox를 예측할 때 해당 bbox에 있을 객체가 어떤 클래스일지 클래스별 확률을 추출합니다. 그리고 여기에 bbox의 신뢰도(confidence score)를 곱하여 향후 최종적으로 사용할 bbox를 추출할 때 사용합니다.
네트워크의 구조
네트워크의 구조는 크게 변하지 않았습니다. 저자는 YOLOv1에서 하던 DarkNet을 더 개선한 Darknet-19를 Backbone 네트워크로 사용했는는데요, 구조는 다음과 같습니다.
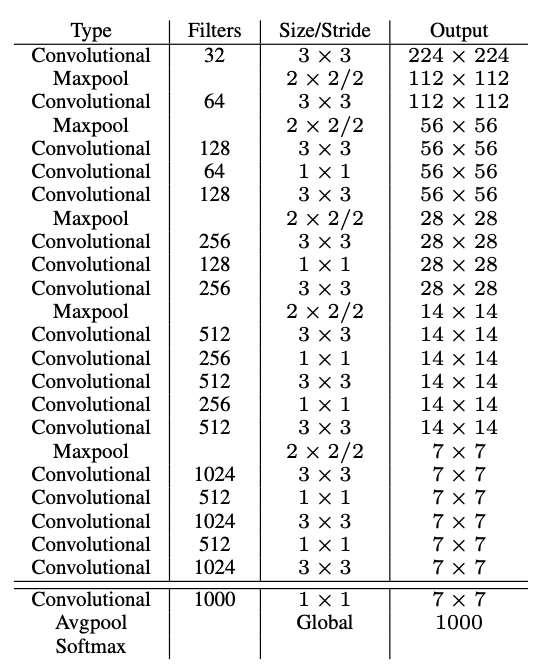
YOLOv2는 416 x 416 해상도의 이미지를 쓰는데 DarkNet-19는 224 x 224 해상도의 이미지를 받게끔 만들었습니다. 아마 ImageNet데이터셋에서 학습시키기 위해 그런게 아닌가 싶습니다.
손실 함수
손실 함수는 따로 언급하지 않았습니다. 그래서 구현코드를 찾아봤는데 음...자세한 식을 찾을 수가 없네요. 그래도 YOLOv1과 같은 저자가 만들었다는 점, YOLOv1을 개선한 모델이라는 점 등으로 봤을 때 YOLOv1이 사용한 함수와 거의 비슷한 함수를 사용한게 아닐까 싶습니다.
성능
그러면 이제 성능을 확인해봅시다.
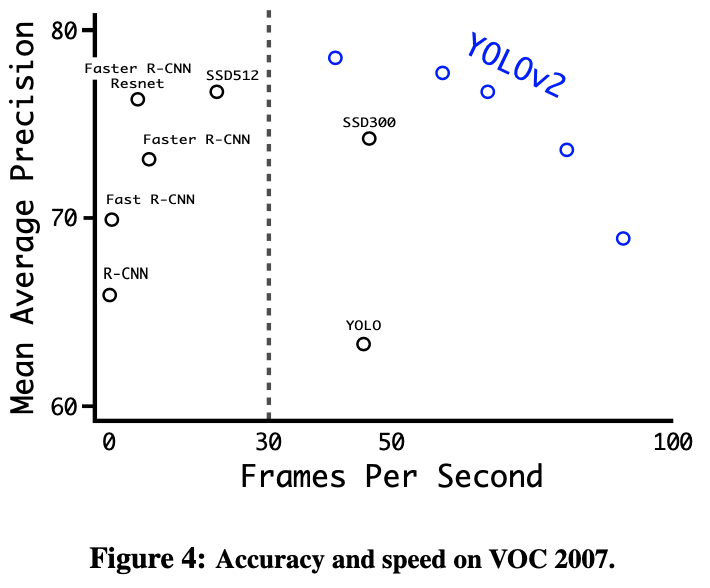
먼저 속도와 성능을 축으로 하는 좌표평면에서 그린 점입니다. 오른쪽 위에 있는 네트워크가 속도, 성능 모두 좋은 네트워크인 것이죠. 오른쪽 위에 YOLOv2가 여러개 있는 것으로 보아 우리는 YOLOv2가 성능이 좋은데 속도까지 빠른 네트워크라는 사실을 알 수 있습니다.
이를 표로 나타내면 다음과 같습니다.

최대 FPS를 91까지 달성할 수 있다는게 놀랍습니다. 여기에 더 나아가 PASCAL 2007 데이터셋에 있는 객체별 탐지 성능도 측정하였습니다.

당시 최고 성능을 보여주던 네트워크들과 비교했을 때 밀리지 않는 성능을 보여주는 것을 확인할 수 있습니다.
COCO dataset
COCO dataset으로도 성능을 측정하였습니다. 결과는 다음과 같습니다. SSD에서 사용한 표랑 같은 형식입니다.
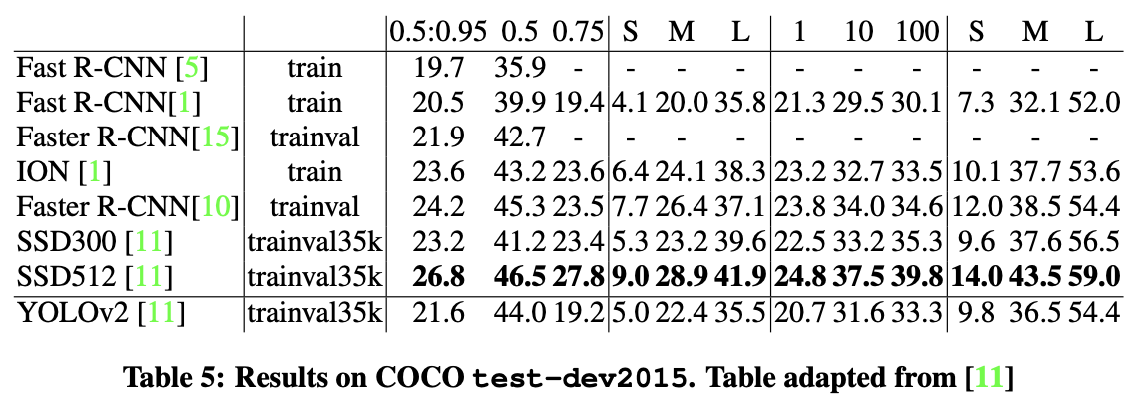
위 사진은 YOLOv2에는 나와있지 않던 측정 항목입니다. 즉, 저자는 COCO dataset을 가지고 네트워크들의 정확도와 recall을 측정한 것이죠.

위 표를 통해 우리는 YOLOv2의 성능이 좋다는 사실을 다시 한 번 확인할 수 있습니다.
정리 : YOLO에서 YOLOv2로
저자는 친절하게도 YOLO에서 YOLOv2로 변화하는 과정을 표로 정리했습니다.
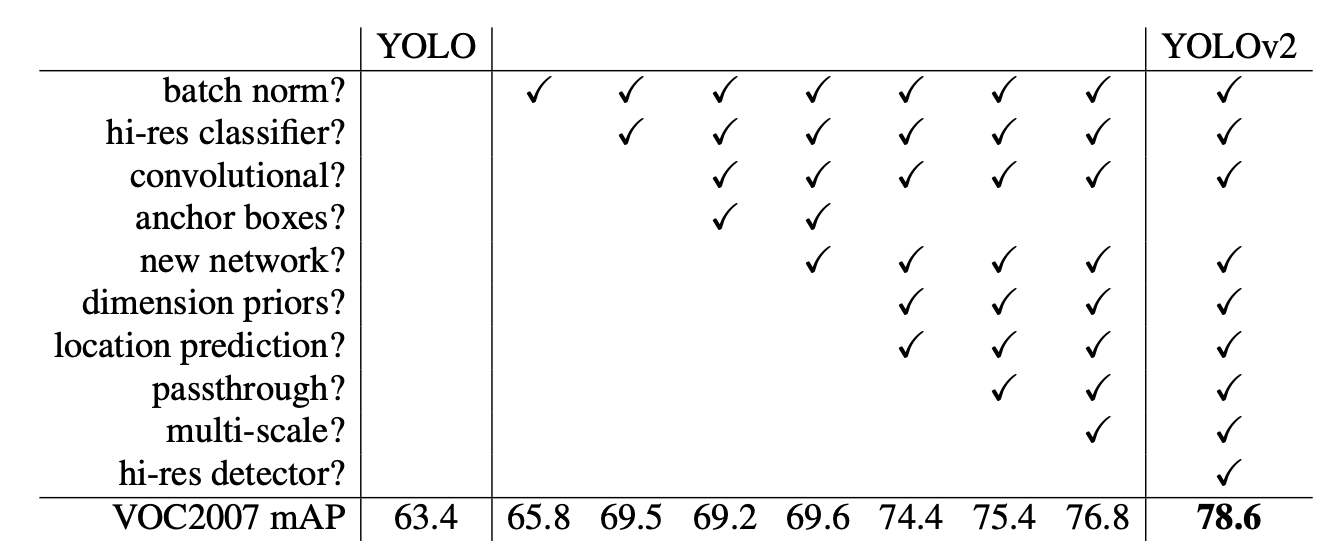
하나씩 적용하면서 성능이 향상하다 저자가 제안한 모든 것을 적용하자 YOLOv2로 진화한 것을 확인할 수 있습니다. 각 항목에 대한 자세한 설명은 논문에 나와있습니다.
YOLO9000?
YOLOv2의 원래 이름은 YOLO9000입니다. 여기서 9000은 YOLO가 탐지할 수 있는 객체의 종류입니다. 저자는 YOLO가 WorldTree라는 기법을 사용해 여러 종류의 데이터셋을 학습, COCO dataset과 ImageNet에 있는 9000개 클래스에 대한 데이터셋을 동시에 학습시켜 무려 9000개의 객체를 탐지할 수 있는 네트워크를 만들 수 있다고 말했습니다.
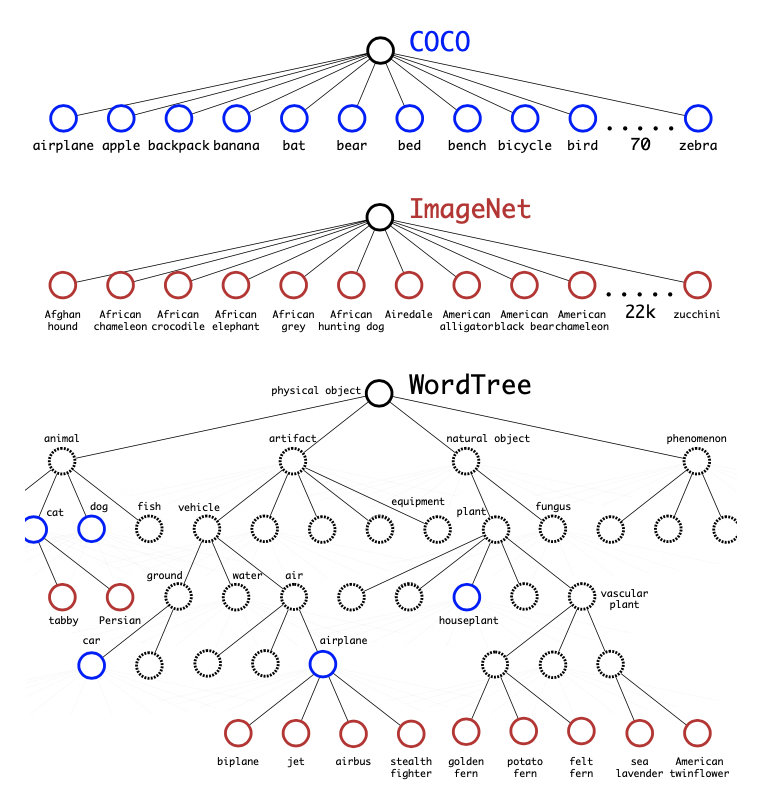
이런 식으로 데이터셋을 합치고
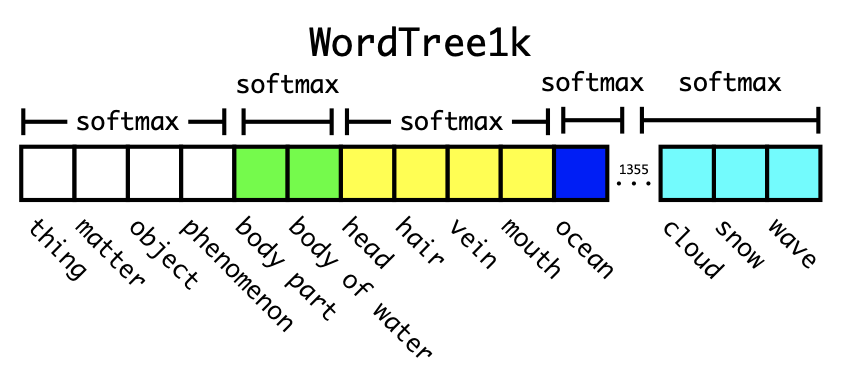
이런 식으로 객체별 확률을 구하는 것이죠. 서로 연관이 있는 것끼리만 softmax를 적용합니다. 이런 방식은 써본적도 거의 없고 본적도 거의 없어서 아직 제대로 받아들이지 못한 방식입니다. 정말 신기하다 생각되던 방식이었습니다.
그런데 이런 방식으로 만든 YOLO9000가 성능이 엄청 좋지는 않았나봅니다.

가장 성능이 좋지 않은 156개의 객체의 AP인데요, 저자 말로는 '새로운 객체'에 대한 정확도가 낮다고 말하였습니다.
그래도 달리 생각하면 나머지 8800여개의 클래스에 대한 정확도는 최소 61.7%를 넘어간다는 뜻입니다. 정말 대단합니다.
YOLOv3
다음으로 YOLOv3을 리뷰해보겠습니다. 저자가 'little design changes'라고 말할 정도로 크게 바뀐게 없어 함께 리뷰하기로 했습니다.
현재 제가 공 탐지 프로그램에 사용하고 있는 모델이며 아주 만족스러운 성능을 보여줍니다. 제가 사용한 구현코드의 링크는 이곳입니다.
3개의 Scale을 사용
가장 큰 변화가 아닌가 싶습니다. 저자는 3개의 특성맵을 가지고 객체 탐지를 수행하여 더 다양한 크기의 Bounding box를 탐지할 수 있게 되었습니다.
네트워크 구조 변화
YOLOv3에서도 새로운 네트워크를 가져왔습니다. 이번에 Backbone으로 사용한 네트워크의 이름은 DarkNet-53입니다. 53개의 Convolutional Layer들로 구성되었죠.
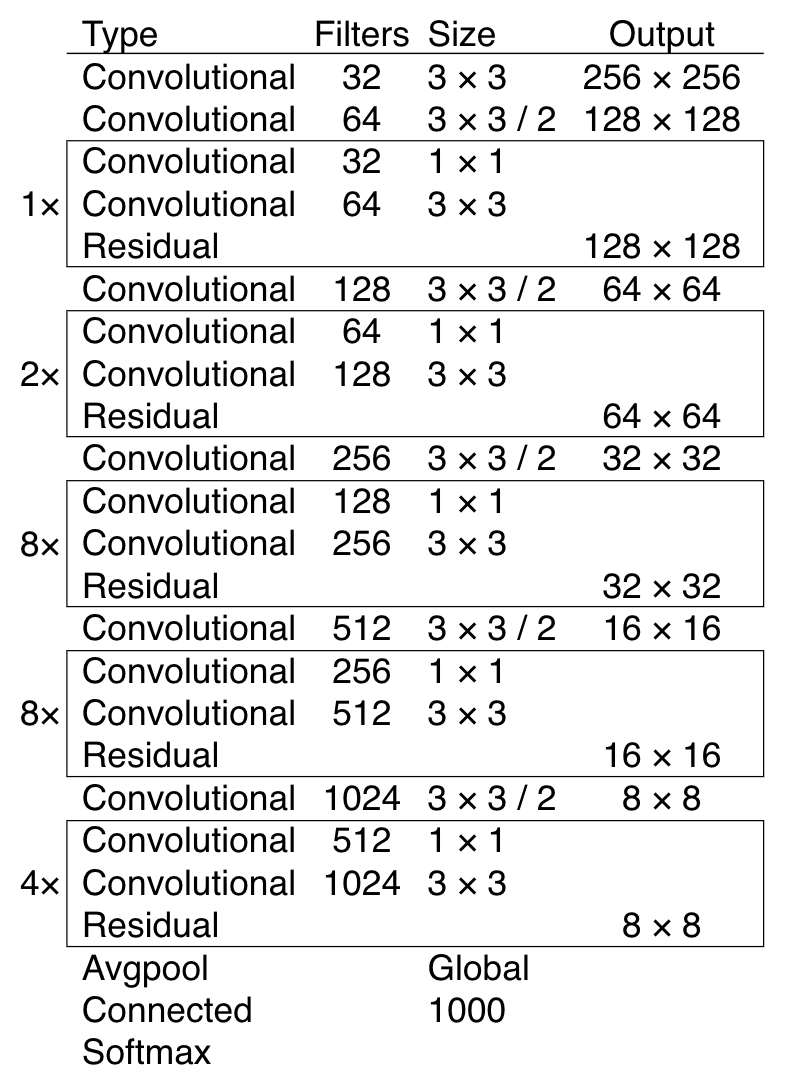
그리고 Backbone에 따른 YOLOv3의 성능 변화도 실험했는데요, 결과는 다음과 같습니다.
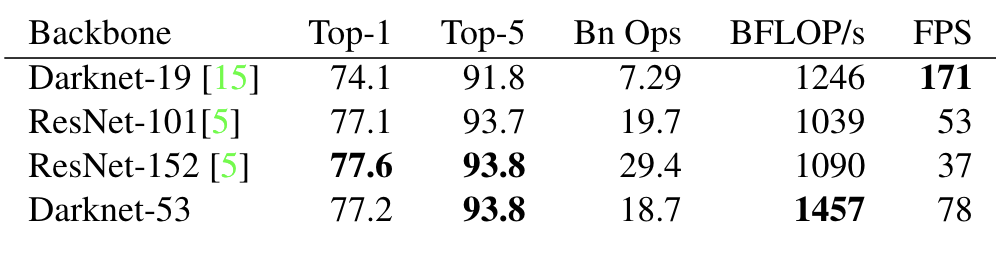
DarkNet이 성능, 속도 두가지 면에서 우수하다는 것을 알 수 있습니다.
객체 탐지 방법
YOLOv2와 같이 네트워크에서 특정 크기를 가진 특성맵이 나올 때마다 이를 가지고 객체 탐지를 수행합니다. 그래서 추가로 설명드릴 내용이 없네요. 실제로 YOLOv3 논문에서 객체 탐지 방식이라고 첨부한 figure가 YOLOv2의 것과 같습니다.
성능
이제 성능에 대해 말씀드리도록 하겠습니다. 논문 내용도 적어서 실험한 내용도 별로 없습니다.
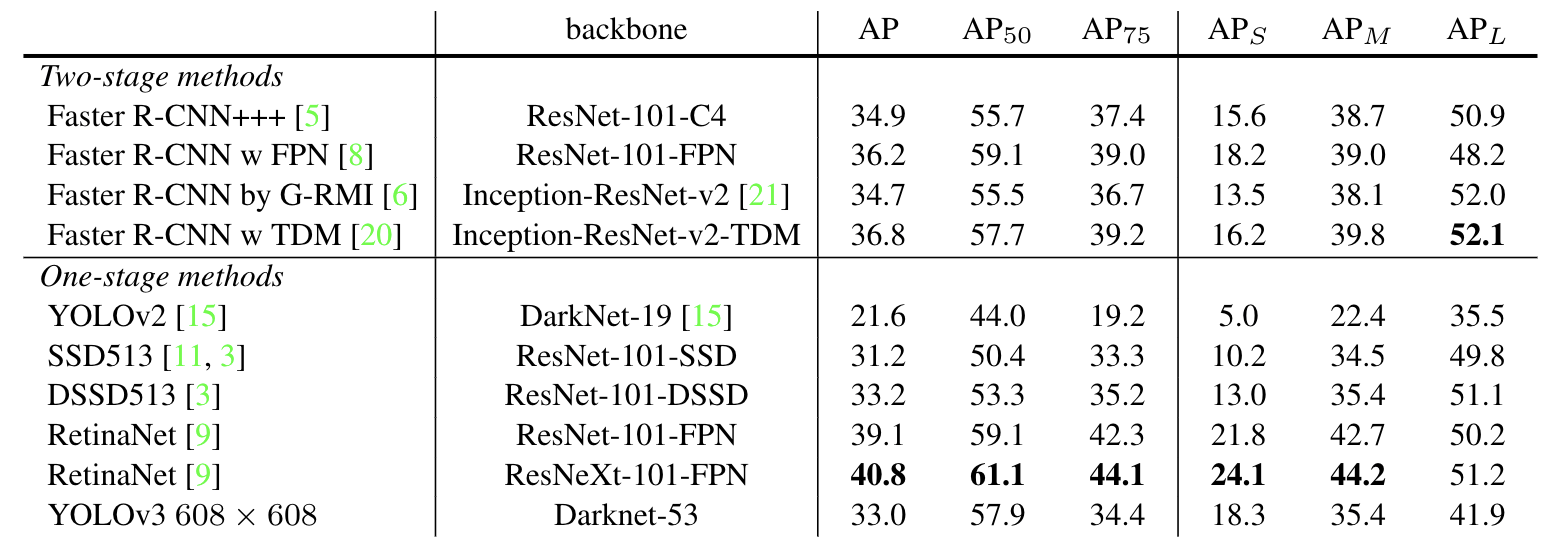
우선 첫번째 결과입니다. 음...성능이 별로 안좋죠? 표로 쓰기에는 좀 아쉬운 면이 많습니다.
그러나 다음의 추론시간 - 성능 그래프를 보시면 생각이 좀 달라지실듯 합니다.
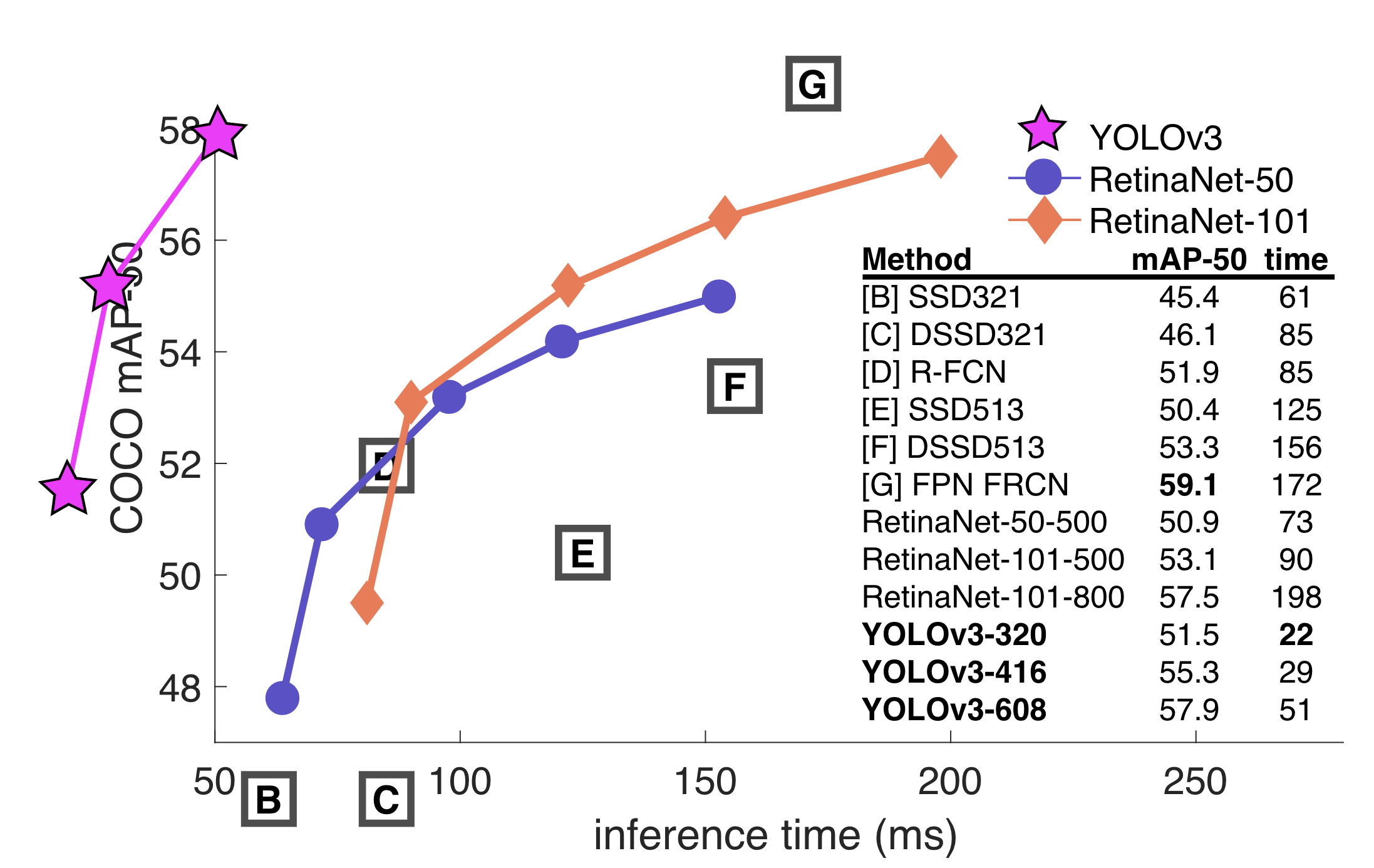
B, C, D, E, F, G가 들어있는 박스는 우측 SSD321, DSSD321...등을 가리킵니다.
다시 그래프를 봅시다. YOLOv3의 추론속도가 아주 빠릅니다. 그래프를 빠져나왔네요.
왜 저렇게 그린걸까요? 위 그래프는 저자가 그린게 아니라 Focal Loss 논문에 있는 그래프를 그대로 가져와 YOLOv3의 성능 그래프만 추가한 것입니다. 그래서 Focal Loss의 저자가 그래프를 그릴 때 최소 추론시간보다 정한 값보다 더 적은 시간이 걸린 YOLOv3가 그래프를 빠져나온 것입니다.
추론시간을 저렇게나 줄이고도 저런 성능이라니...정말 대단합니다.
개선이 필요한 점
저자는 YOLOv3을 만들면서 '개선이 필요하다'고 느낀 점들도 따로 정리했습니다.
- Anchor box x,y offset predictions : YOLOv3은 anchor box를 기준으로 객체를 둘러싼 bbox와의 offset을 예측하는 방식을 사용한다고 말씀드렸는데요, 이런 방식이 모델의 안정성을 떨어뜨려 모델이 100%의 성능을 보여줄 수 없게 만든다고 말했습니다.
- Linear x, y predictions instead of logistic : YOLO는 bbox의 좌표를 예측할 때 log를 사용하지 않고 오로지 linear한 식으로 만들어진 값을 사용합니다. 그래서 mAP가 상당히 떨어진다고 하네요.
- Focal loss : 저자는 YOLOv3에 Focal loss를 적용하려고 했습니다. 그러나 Focal loss를 적용하자 mAP가 2나 떨어졌습니다. 그런데 YOLOv3은 이미 Focal loss가 해결해야할 '데이터의 불균형으로 인해 특정 클래스에 대한 탐지 성능이 약한걸 식으로 해결하자'에 robust할 것이라 하네요.
- Dual IOU thresholds and truth assignment : YOLOv3는 Faster R-CNN과 같이 IoU에 따라 데이터셋에 있는 데이터를 'positive example', 'negative example'로 구분 후 학습에 사용했습니다. 허나 이런 방식은 YOLO에게 좋지 않은 결과를 가져왔다고 하네요.
리뷰 후기
2개의 논문을 간단히 리뷰해봤습니다. 제가 현재 사용중인 네트워크라 제가 이해했던 내용의 비중을 많이 두며 간단히 리뷰하려고 했는데 생각보다 간단하지도 않았고 그렇다고 기존에 했던 리뷰보다 자세하지도 않아서 조금 애매한 리뷰가 된게 아닌가 싶습니다. 아쉽네요.
YOLO는 지금도 계속해서 새로운 버전의 네트워크가 나오고 있습니다. YOLOv4부터는 새로운 저자가 발전시키고 있는 것으로 알고 있는데요, 현재 Object Detection 네트워크에서 꾸준히 높은 성능을 자랑하고 있는 것으로 알고 있습니다.
YOLO는 네트워크의 구조도 단순해서 구현코드가 굉장히 많기 때문에 접근하기도 상당히 쉬울 것이라 생각됩니다. Object Detection에 관심 있으신 분들에게 입문 네트워크로 제가 강력히 추천드리고 싶습니다.
이번 리뷰는 여기까지 쓰도록 하겠습니다. 다음 리뷰에서 뵙겠습니다.
